原创不易,求分享、求一键三连
资料地址:https://files.cnblogs.com/files/yexiaochai/%E4%BF%9D%E9%9A%9C.zip?t=1652146053
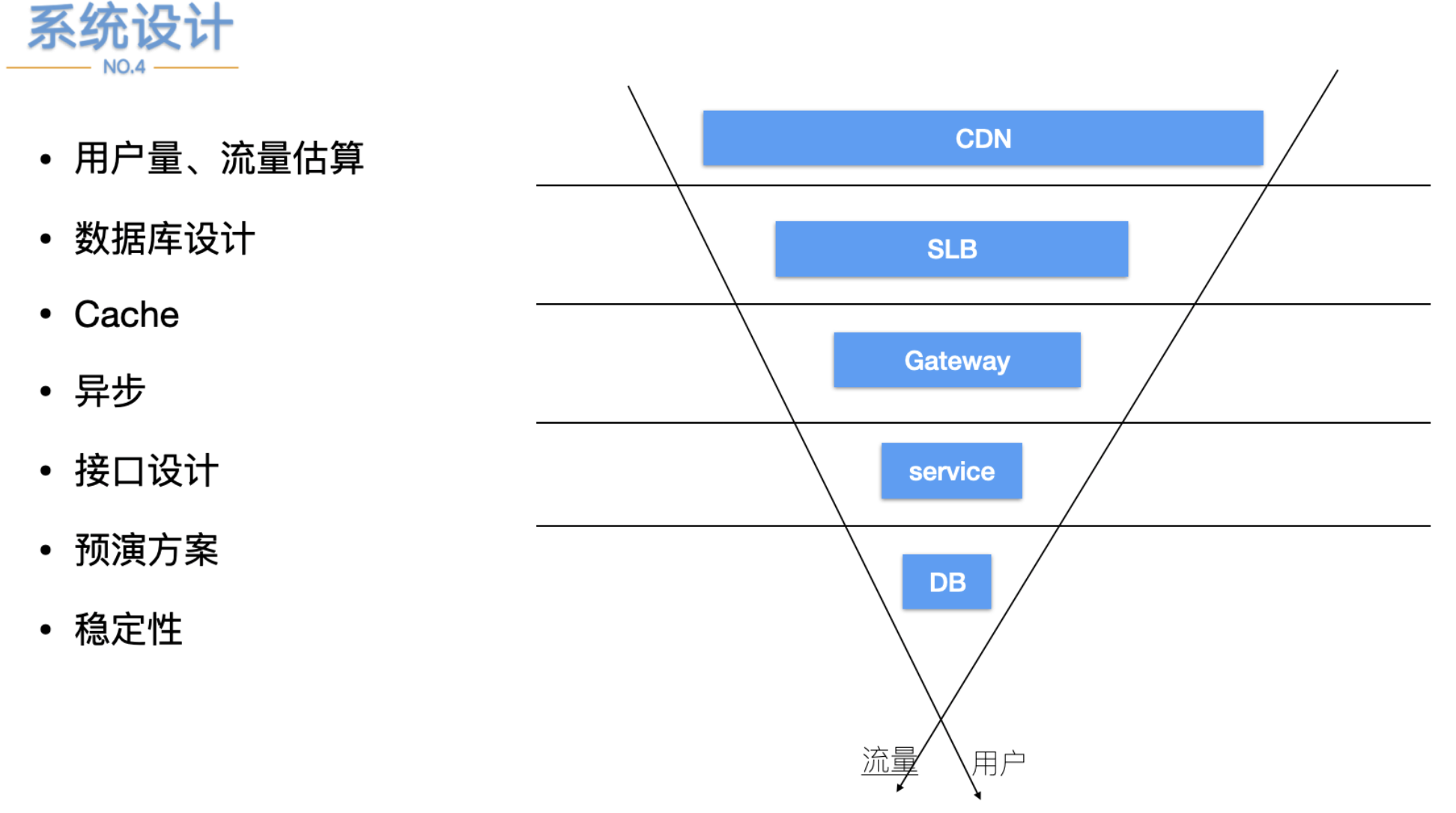
面对业务迅速增长复杂度会呈几何级增加,为了降低维护复杂度而引入了微服务,只要每个服务足够简单,那么维护成本也可以降低。
服务保障也是一个非常困难的事情,今天聊一聊系统稳定性方案。
方案设计层面- 业务逻辑正常是最基础的要求。
- 接口安全、数据安全(数据泄漏、数据遍历、越权访问)。
- 服务扩展性(服务是否可平滑扩容,能扩的最大范围是多少个节点)、是否存在单点。
- 数据库表结构设计、索引设计。
- 缓存更新机制、过期机制、是否存在单点热Key
- 消息系统设计、流转过程;投递速率、消费速率
- 定时任务运行方式、执行记录、失败处理、是否可以恢复
仅仅考虑前面的场景可能还是不够,所以继续进行系统稳定性的思考。
系统稳定性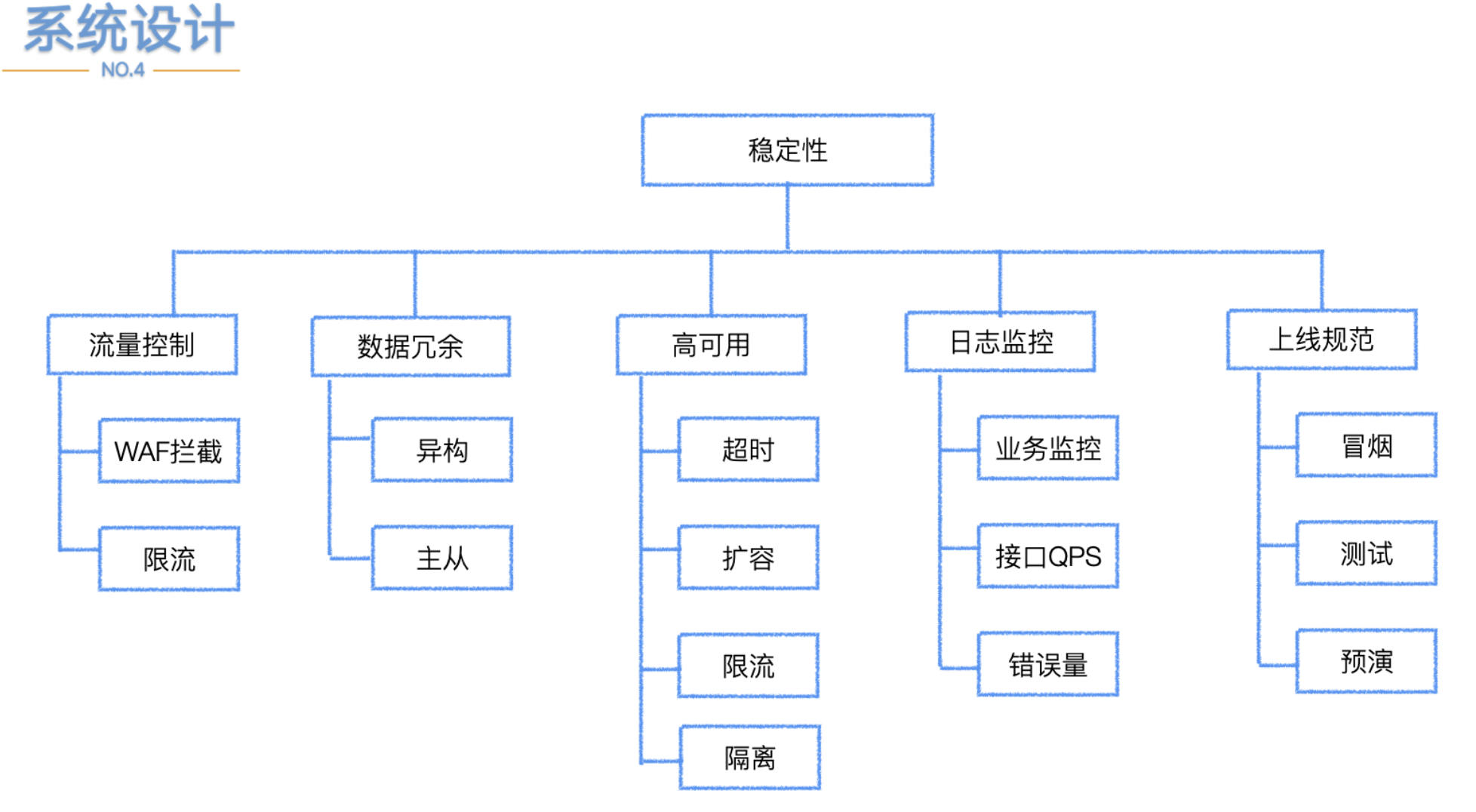 流量控制
流量控制
一般情况下越靠近下层资源的吞吐能力越弱,数据库吞吐能力有限,要尽量将流量拦截到上层尽快返回响应,让越下层的资源做正确和重要的事情,达到压榨系统的目的,所以上面看到的WAF拦截;限流基本都是放在网关或者离用户更近的一层。
 数据冗余
数据冗余
系统中最重要的是数据,保证数据不丢失至关重要,数据冗余是防止丢失最简单的方式。数据冗余备份方式很多种,从物理到逻辑的角度,备份可以分为以下几类:
- 物理冗余
- 只对数据库操作系统的物理文件(如数据文件、日志文件等)的备份
- 物理备份又可以分为冷备(在关闭数据库时进行的备份操作,能够较好地保证数据库的完整性)和热备(在数据库运行状态中进行操作,这种备份方法依赖于数据库的日志文件)
- 逻辑备份
从数据库的备份策略角度来看,备份又可分为全量备份、增量和冗余备份
- 全量备份
- 每次对数据进行完整的备份
- 可以备份整个数据库,包含用户表、系统表、索引、视图和存储过程等所有数
- 据库对象
但它需要花费更多的时间和空间,所以,做一次完全备份的周期要长些
- 增量冗余
只有那些在上次完全备份或者增量备份后被修改的文件才会被备份
- 差异冗余
- 备份那些自从上次完全备份之后被修改过的文件,即只备份数据库部分的内容
- 它比最初的完全备份小,因为只包含自上次完全备份以来所改变的数据库
- 它的优点是存储和恢复速度快
为了保证系统的高可用,在框架、基础建设层面需要做很多建设。
- 超时、重试、幂等
超时控制,可以让服务之间调用快速抛错。
如果单个请求耗时长会影响服务的性能。比如API接口设置2s超时API调用a服务用了1s,服务a调用服务b用了1s,那么现在已经超时了,如果还需要调用服务c,这个时候整体接口已经超时就不需要继续调用c服务,浪费时间和资源。
重试是保证一些服务可能偶尔服务抖动失效情况下,再重新发起一次,保证当前请求的准确性,重试需要有限制,不能无限循环,再则操作是否可以重试,是有支持幂等。
- 扩容
扩容策略可以分为两种,一种是对单机整体扩容,也就是机器内部包含CPU、内存、存储设备等;另一种增加机器,对于服务的扩容一定要慎重,需要考虑到扩容之后下游的资源是否能够支撑。
比如mysql服务器链接只有2000个,当前集群已经使用的差不多了,服务数量增加之后会导致链接不够用;业务更容易出问题。微服务k8s容器化之后,我们自研的发布系统上可以进行轻松的扩容。
- 限流、熔断、降级
举个业务降级的例子,定时送道具打积分榜单,榜单计算支持的QPS可能是1w,道具分多种档次,其中有一种薅羊毛的道具1积分,花钱的几十到几万积分不等,可能有刷子囤积了几亿的羊毛道具等待打榜时候使用程序投递影响活动的体验;
如果有大量羊毛道具并且超过榜单计算的QPS,此时就降级把羊毛道具剔除掉,只算花钱的,毕竟1积分对榜单影响小(业务定夺)。
- 隔离
顾名思义,按照一定的原则进行划分,进行单独维护。
服务隔离:将系统按照业务特性分成不同的服务模块,各个模块之间相对独立,无强依赖,某些模块出现故障不至于全部不可用。
动态接口和静态接口隔离,比如:一个接口里面有用户自己特定的一些数据,也包含了所有用户看到都是一样的数据,那么就可以把这部分拆分成两个接口;大家看到统一数据的接口可以加统一缓存或者上CDN;不拆分是无法上CDN的;
数据库分库分表等;隔离之后尽量保证不可越界、不可共享防止隔离失效。
业务保障的基础(监控&告警)怎样衡量业务系统是否表现正常?是应用在线上跑着进程还在没有宕机,这可能是一个先决条件,有的程序虽然还在跑着,但是已经不能提供服务了,能体现服务的正常需要看流量,流量是看不见的,只有通过日志监控体现。
监控需要监控哪些呢,基础资源监控-基础的资源是否出现问题了?
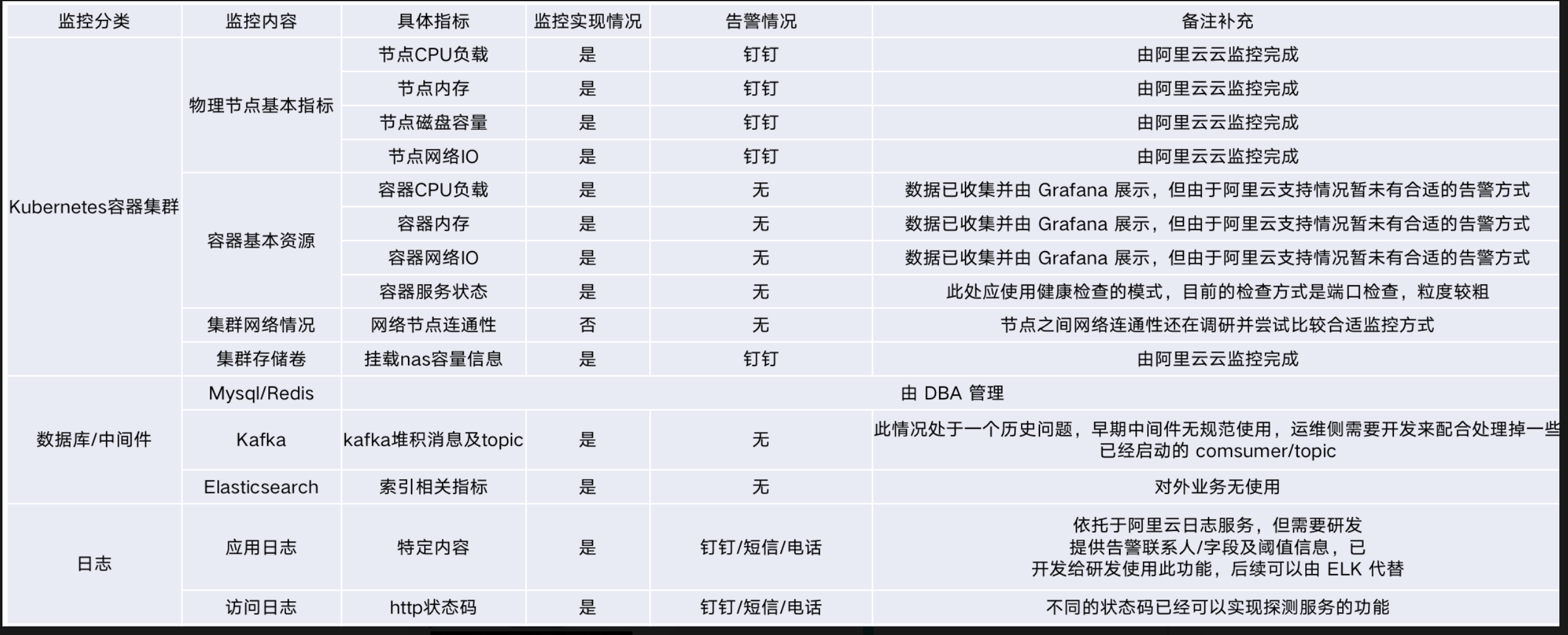
单服务监控-某个服务是不是指标是否出现异常了?
QPS(GRPC、http)、耗时、接口错误码、错误率监控、上下游依赖监控(DB、缓存、上游依赖服务、下游支持服务)
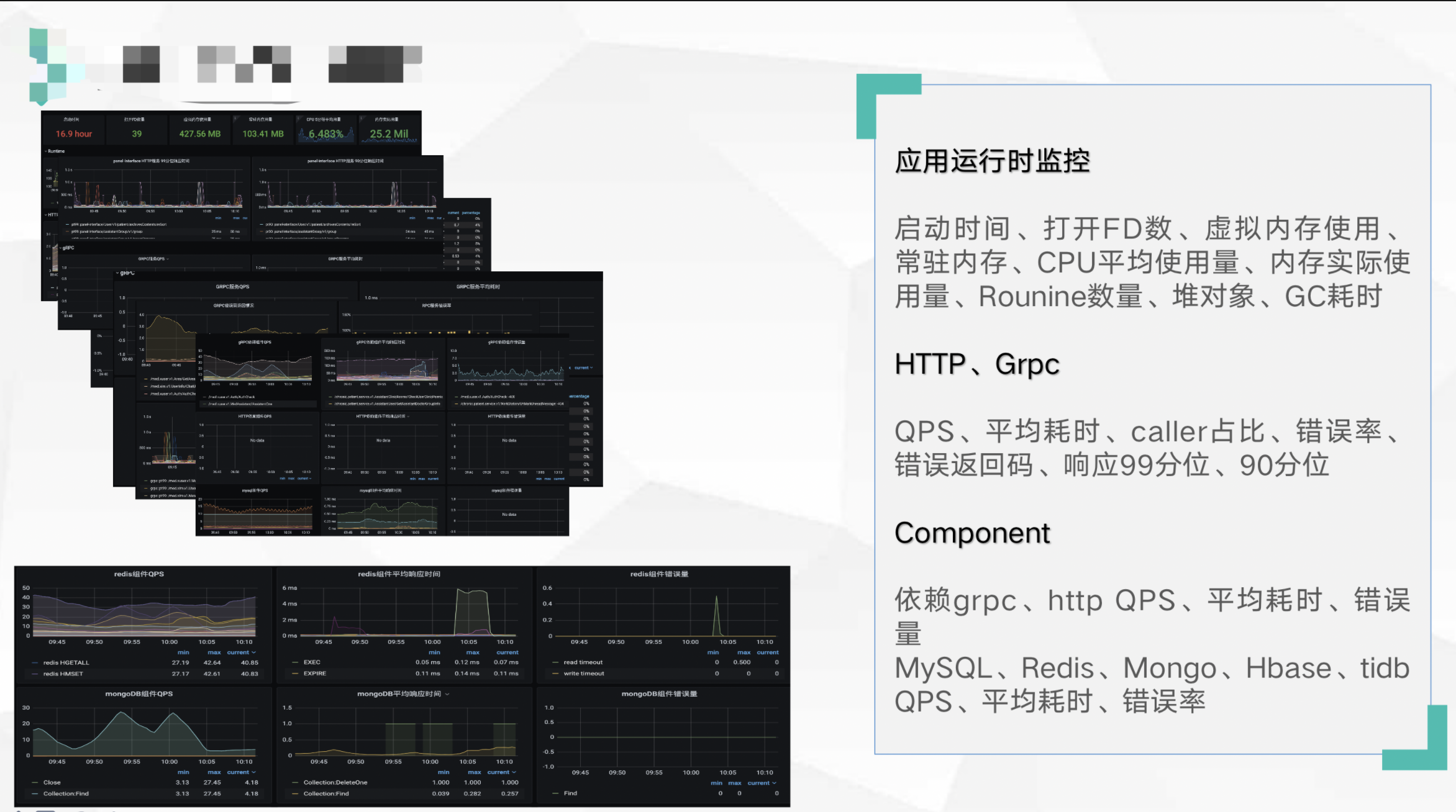
微服务调用链路监控-调用链路到某个服务是否异常了?
用户端监控-用户体验端是否出现异常了?
 上线规范-预演
上线规范-预演
预演是非常重要的环节,很多bug都可以在预演环节被干掉,这里不是因为测试同学不努力,不能把那些BUG过掉,是因为:
- 预演环境有真实的庞大数据
- 预演环境的能还原真实的QPS,会覆盖掉很多边界场景
- 有些测试必须在生产环境进行
- 预演需要做方案,不能引起线上脏数据
有了这些东西就可以进行预演了,然后这里有一个最大原则:预演请务必尽可能还原真实场景,包括时间点的设置!
那些之前重点关注的问题,很多重要的事情需要扣细节,扣的越多思考越细能考虑到整个事情的所拥有的发展方向,提前堵上错误的路径。
- 广播到端上刷接口
之前工作中遇到一个广播的场景,是服务端会推送给web端一个命令消息,web收到消息之后需要向服务端发起一个http请求获取数据,由于命令推送是同一个,根据不同的用户获取的http响应不一样,并且http接口数量也比较大,前期用户不多的情况下http接口的QPS比较低还能接收,逐渐业务增长后,http接口内部实现使用缓存能优化。
当服务端已经无法优化之后,简单粗暴的,进行推送之后,web收到命令消息之后,0-5分钟内打散请求服务端也能抗一段时间,量持续增长,到0-5分钟即使打散量还是很大,给对应的http接口限流,用户会反馈为什么我没收到消息。
这种逻辑面对大量用户在线确实比较难搞,后面将接口返回的数据进行拆分(动态和静态)静态数据加CDN并在界面上提前下发,动态数据压缩走广播,去掉广播刷接口的逻辑。
- 无用请求抢占带宽
带宽也是资源,之前遇到过一个事故,前端获取一个接口数据如果没有获取成功,则会再进行api请求拉取一次,没有做重试退出操作,导致这个接口的流量很大基本上打满了某个服务的所有资源,进而急剧恶化其他请求都无法请求到后端服务。
之前处理的方式是在网关层面限制改接口的流量,部分正常的业务可以打到服务节点上,但是网关层量还是一直升高,最后将改接口直接挂到CDN上,不让回源到服务,但当时CDN缓存的是404响应,事后想想直接把响应结果缓存到CDN,不是所有客户端都正常了。
- 日志打印不规范
无法及时发现线上问题,请不要乱打日志,可能这个行为是给别人埋坑,info日志能看出业务在正常运行,error日志能看出系统哪些业务出错了。
紧急故障处理线上故障总会出现的,我们出现故障如何紧急处理(参见:毛老师 SRE PPT)
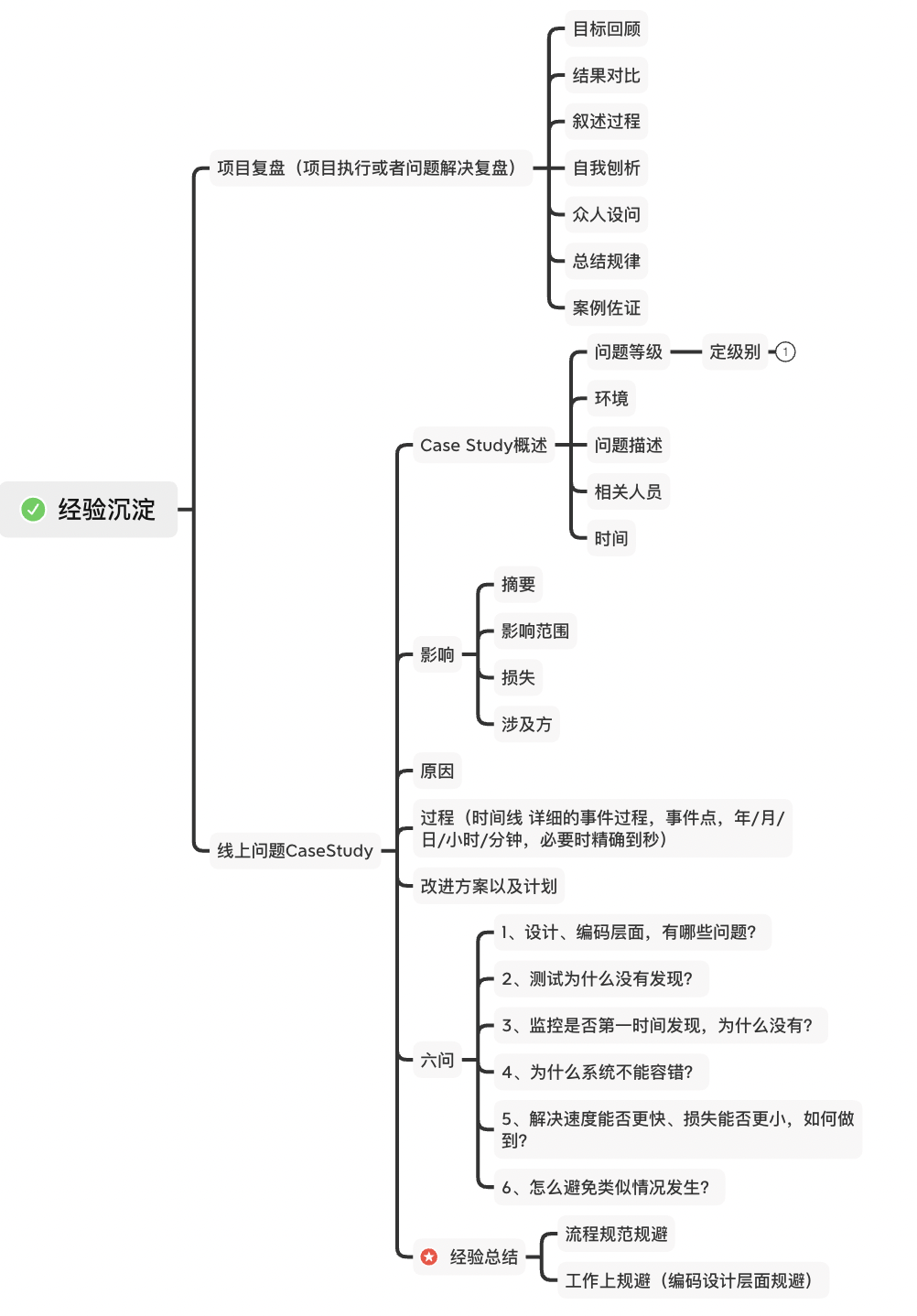
 经验沉淀
经验沉淀
复盘本质就做两件事情① 评价结果 ② 总结过程经验教训。具体来说:
- 复盘要紧密围绕事情结果来讨论。
- 事情结果的好坏,取决于是否达成预定目标。
- 因此,任何事在启动前必须有明确可衡量的目标。
- 对于目标实现有贡献的,称之为经验;对于目标实现有阻碍影响的,称之为教训。
- 经验、教训要能传承并指导后续的行动。
引用:
https://cloud.tencent.com/developer/article/1666384
https://mp.weixin.qq.com/s/Rx_XuMLeor_M9EuQcYq23w
https://zhuanlan.zhihu.com/p/61363959
https://github.com/alibaba/Sentinel/wiki/%E7%B3%BB%E7%BB%9F%E8%87%AA%E9%80%82%E5%BA%94%E9%99%90%E6%B5%81
好了,今天的分享就到这,喜欢的同学可以四连支持:

想要更多交流可以加微信群:

