数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
每个数据库都有一个或多个不同的 API 用于创建,访问,管理,搜索和复制所保存的数据。
我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。
所以,现在我们使用关系型数据库管理系统(RDBMS)来存储和管理大数据量。
所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
RDBMS 即关系数据库管理系统(Relational Database Management System)的特点:
1.数据以表格的形式出现
2.每行为各种记录名称
3.每列为记录名称所对应的数据域
4.许多的行和列组成一张表单
5.若干的表单组成database
1.2 常见的数据库关系型数据库:Oracle,MySQL,DB2(IBM),SQL Server(.net项目),PostgreSQL。。。。。
非关系型数据库(NOSql):Redis,Hbase,mogodb。。。。。。
2、数据库表的范式关系型数据库都是使用数据表存储数据的。
为了更好的处理和存储数据,我们设定了数据表的设计方式,这个方式就是数据表的设计范式。“折中”。
2.1 范式上面的表中有学生的信息,但是学院专业这一栏是可以分割的。这一栏包含了两个信息。这样的表不满足第一范式。
第一范式:所谓第一范式(1NF)所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。即实体中的某个属性有多个值时,必须拆分为不同的属性。
简而言之,第一范式就是无重复的域。
第二范式是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
第二范式(2NF)要求数据库表中的每个实例或记录必须可以被唯一地区分。选取一个能区分每个实体的属性或属性组,作为实体的唯一标识。
不满足第二范式的:
有两个张三,无法区分
增加班级列,让姓名和班级作为主键:
第三范式(3NF)要求一个关系中不包含已在其它关系已包含的非主关键字信息</u>。
一张表只描述一件事。
上面的表就不满足第三方式,存在大量的学院信息和专业信息的重复现象。
将上面的表进行拆分。
学生表:
学院表:
专业表:
面试题:什么是数据的三大范式?
答案:第一范式,第二范式和第三范式。
数据库一共有6个范式。
BC范式、第四范式、第五范式。
3、MySQL简介 3.1.什么是MySQL
与其他的大型数据库例如 Oracle、DB2、SQL Server等相比,MySQL [1] 自有它的不足之处,但是这丝毫也没有减少它受欢迎的程度。对于一般的个人使用者和中小型企业来说,MySQL提供的功能已经绰绰有余,而且由于 MySQL是开放源码软件,因此可以大大降低总体拥有成本。
Linux作为操作系统,Apache 或Nginx作为 Web 服务器,MySQL 作为数据库,JAVA/PHP/Perl/Python作为服务器端脚本解释器。由于这四个软件都是免费或开放源码软件(FLOSS),因此使用这种方式不用花一分钱(除开人工成本)就可以建立起一个稳定、免费的网站系统。
数据库是如何存储数据?
所有的数据库都是将数据按照自己的方式以文件的形式存储在磁盘
所有的关系型数据库,对于数据的增删改查,操作都是一样的。
3.2.MySQL的安装和连接连接MySQL:
打开命令窗口
> mysql -uroot -p 回车 输入密码
当然也可以使用MySQL的一个连接工具:Navicat Premium
3.3MySQL中的数据的数据类型 数值类型MySQL支持所有标准SQL数值数据类型。
这些类型包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL和NUMERIC),以及近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION)。
关键字INT是INTEGER的同义词,关键字DEC是DECIMAL的同义词。
BIT数据类型保存位字段值,并且支持MyISAM、MEMORY、InnoDB和BDB表。
作为SQL标准的扩展,MySQL也支持整数类型TINYINT、MEDIUMINT和BIGINT。下面的表显示了需要的每个整数类型的存储和范围。
日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。
TIMESTAMP类型有专有的自动更新特性,将在后面描述。
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
要知道的数据类型:
int/integer , decimal(小数值), bigint(极大整数值) ,
char , varchar, text
date(YYYY-MM-DD日期值),time(HH:MM:SS时间值或持续时间),datetime(YYYY-MM-DD HH:MM:SS混合日期和时间值),timestamp(YYYYMMDD HHMMSS 混合日期和时间值,时间戳)
4、数据表分析和设计
数据库设计:
在上面的报表中有四个实体:学生,班级,学科,成绩
准备四张数据表(一张表描述一件事)。
班级表: class_info
学生表:student
课程表:course
成绩表:score
创建数据库:
create database 数据库名称 ;
在编辑工具中写好sql语句,右键运行,或者点击上面的运行按钮。
双击student数据库打开。
在编辑工具中指定当前使用的数据库:
语法:
CREATE TABLE 表名(
列名 类型 [约束...],
列名 类型 [约束],
...
列名 类型 [约束]
);
创建班级表:
-- 创建班级表 --
CREATE TABLE class_info(
class_id bigint not null primary key,
class_name varchar(100) not null,
class_desc varchar(200)
);
class_id是这个表的主键。 主键的意思是这一列数据是不能重复,也不能为空。使用这一列唯一标识这一行数据。 类似于我们的身份证号码。
not null 的意思是这一列数据不能为空。
primary key 表示这一列是主键
bigint和int都是不需要指明长度
varchar(100) 这里的100表示这一列内容的最大长度。
实例:创建数据表
-- 创建班级表 --
CREATE TABLE class_info(
class_id bigint not null primary key,
class_name varchar(100) not null,
class_desc varchar(200)
);
-- 学生表 --
create table student(
stu_no varchar(20) not null primary key,
stu_name varchar(100) not null,
stu_birth date,
stu_gender int default '1',
stu_tel char(11),
class_id bigint
);
-- 课程表 --
create table course(
cid int not null primary key,
cname varchar(200) not null
);
-- 成绩表 --
create table score(
cid int not null ,
stu_no varchar(20) not null ,
score int
);
5.2.修改表、删除表
-
增加字段语法:
Alter table 表名称 add(列名1 类型 [DEFAULT 默认值],列名1 类型 [DEFAULT 默认值]...)
为学生表添加一个邮箱,类型为varchar
alter table student add email varchar(50) ;
-
修改字段语法:
ALTER TABLE 表名称 MODIFY(列名1 类型 [DEFAULT 默认值],列名1 类型 [DEFAULT 默认值]...)
修改一列数据类型
alter table student MODIFY stuName varchar(200)
-
修改字段名语法:(这个是Oracle的语法,MySQL不支持)
ALTER TABLE 表名称 RENAME COLUMN 原列名 TO 新列名
语句: 大部分的数据库都不支持修改列名的操作,所以不建议使用
ALTER TABLE T_OWNERS RENAME COLUMN OUTDATE TO EXITDATE
-
删除字段名
--删除一个字段
ALTER TABLE 表名称 DROP 列名
--删除多个字段
ALTER TABLE 表名称 DROP (列名1,列名2...)
案例:
--删除字段 alter table student drop email
-
删除表
语法:
DROP TABLE 表名称
-
给成绩表添加联合主键
alter table score add constraint pk_cid_stu_no primary key(cid,stu_no)
6、主外键关系
6.1主键
一张表中唯一确定一行记录的列称之为主键。主键又称为主键约束。
6.1.1给一张已经创建好的表添加主键语法:主键是不能为空,不能重复的。
一个表中最多只能有一个主键。
主键可以由多个列组成。 多列组成的称之为联合主键。
ALTER TABLE 表名 ADD CONSTRAINT 约束名称(PK_XXX) PRIMARY KEY(列名)
将课程表的课程编号设置为主键
alter table course add constraint pk_cid primary key(cid)
如果是多列联合作为主键。这种主键就称之为联合主键。 语法:
ALTER TABLE 表名 ADD CONSTRAINT 约束名称(PK_XXX) PRIMARY KEY(列名1,列名2,列名....)
给成绩表添加联合主键:
alter table score add constraint pk_stuNo_cid primary key(stuNo,cid);6.1.2 在创建表的同时设置主键
语法1:
CREATE TABLE TABLE_NAME( TID NUMBER PRIMARY KEY, -- 直接将TID这一列设置为主键,这里的主键名称会自动生成 -- ...... );
语法2:
CREATE TABLE TABLE_NAME( TID NUMBER NOT NULL, TNAME VARCHAR2(20) NOT NULL, ...... ADD CONSTRAINT PK_TID_TNAME PRIMARY KEY(TID,TNAME)-- 添加联合主键 -- );6.2 外键
如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外键。
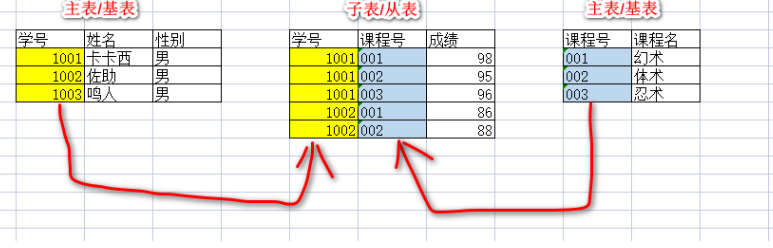
成绩表中的学号就是外键,成绩表中的学号都是来自于学生信息表。
学生信息表一般称之为主表(基表),成绩表称之为子表(从表)。
6.2.1给已经创建好的表添外键从表中的学号为外键,外键的列中的数据全部来自于主表。
外键有的数据,主表肯定有,主表有的数据外键不一定有。
外键引用的列是不能为null的。
外键的引用的列必须是唯一的。
外键引用的列不一定是主键。
语法:
ALTER TABLE TABLE_NAME ADD CONSTRAINT 外键名称(FK_XXX) FOREIGN KEY(列名) REFERENCES TABLE_NAME1(列名)
我们当前的四张表表中,学生表的班级编号就是来自于班级表。
我们给学生表的班级编号添加一个外键
alter table student add constraint fk_class_id foreign key(class_id) references class_info(class_id)
外键就约束了学生表中添加数据的时候,不能随意的添加班级编号,班级编号必须在班级表中存在。
6.2.2 创建表的同时添加外键根添加主键的语法是一样的。
案例:创建成绩表的时候直接添加外键
create table score(
stuNo varchar(20) not null ,
cid char(3) not null references course(cid), -- 添加外键随机生产一个外键名称 --
score int default '0',
add constraint fk_stuNo foreign key(stuNo) references student(stuNo) -- 添加外键 --
);
7、数据增删改
7.1插入数据
语法:
INSERT INTO 表名[(列名1,列名2,...)]VALUES(值1,值2,...)
执行INSERT后一定要再执行 commit 提交事务
给课程标题添加数据:
-- 给课程表添加数据 --
insert into course(cid,cname) values('001','忍术');
insert into course(cid,cname) values('002','幻术');
insert into course(cname,cid) values('体术','003');
commit;
给学生表添加几条数据:
-- 常规操作(window表名和列名不区分大小写,Linux下默认是区分大小写) --
-- 表名后的列名是没有顺序要求的,但是values里面的数据要和前面的列名顺序一致 --
insert into student(stu_no,stu_name,stu_birth,stu_gender,stu_tel,class_id) values('1001','梅超风','1997-09-08',2,'13513513535',1);
insert into student(stu_no,stu_name,stu_birth,stu_gender,stu_tel,class_id) values('1002','程旋风','1996-10-08',1,'13513513536',1);
-- 如果values后面的数据和数据表的列名顺序完全一致,可以省略表名后的列名(不推荐) --
insert into student values('1003','陆乘风','1995-06-25',1,'13813813838',2);
-- 如果要使用某一列的默认值,可以使用defaule或者,不写 --
insert into student(stu_no,stu_name,stu_birth,stu_gender,stu_tel,class_id)
values('1004','欧阳锋','1990-10-08',default,'13513513537',2);
insert into student(stuNo,stuName,stuBirth,stuTel)
values('1005','黄家驹','1999-11-09','13513513538');
-- 某一列可以为空,如果不写,则默认为null --
insert into student(stu_no,stu_name,stu_birth,stu_gender,class_id)
values('1006','时迁','1999-11-09',1,2);
①如果添加的数据和默认的列的顺序一致,并且所有的列都添加了数据,则可以不写表名后面的列名。
②如果一个列是not null,则在添加数据的时候,必须给该列添加数据。
③如果一个列可以为空,并且不想添加数据, 则不要写列名和数据列,一定要确保表名后面的列名和values后面的数据个数和类型一致。
④SQL中没有双引号,只有单引号,所有的字符,字符串,日期基本都是使用单引号。数字不用引号。
⑤一个表如果有外键关系,则必须保证外键关系成立。
⑥确保主键的约束成立。
几个错误的案例:
-- not null 的列必须加入数据 --
insert into student(stuNo,,stuBirth,stuGender)
values('1006','1999-11-09',1);
-- 出错: Field 'stuName' doesn't have a default value
-- 违反 主键约束 主键重复--
insert into student(stuNo,stuName,stuBirth,stuGender)
values('1006','王大锤','1999-11-09',1);
-- 出错 : Duplicate entry '1006' for key 'PRIMARY'
-- 违反外键约束 --
-- 准备 --
insert into course(cid, cname) values('001','java')
-- 给成绩表添加成绩 --
insert into score(stuNo,cid,score) values('1009','001',100)
-- 出错:Cannot add or update a child row: a foreign key constraint fails (`student`.`score`, CONSTRAINT `fk_stuNo` FOREIGN KEY (`stuNo`) REFERENCES `student` (`stuNo`))
7.2修改和删除数据
1 修改数据
语法:
UPDATE 表名 SET 列名1=值1,列名2=值2,....WHERE 修改条件;
需求:
-- 将所有人的性别全部修改为0 -- update student set stu_gender = 0; -- 修改所有名字后面有”风“的性别为1 -- update student set stu_gender = 1 where stu_name like '%风' -- 同时修改多列 -- update student set stu_name = '司马迁',stu_gender = 1 where stu_no = '1006'
set 后面可以同时修改多个列,分别使用“,”隔开。如果没有条件就是修改表中的所有数据。
tips:使用update的时候,一定要考虑条件
2 删除数据
语法:
DELETE FROM 表名 WHERE 删除条件;
执行DELETE后一定要再执行commit提交事务
需求:删除所有学生信息
delete from student
delete 删除数据时,如果不添加条件会删除整张表的数据。
删除没有手机号码的学生的信息
delete from student where stu_tel is null
删除数据的时候,要考虑外键关系,要先删除子表数据,再删除主表数据:
-- 准备 --
insert into score(stuNo,cid,score) values('1006','001',100);
-- 删除学号为 1006的学生信息 --
delete from student where stu_no = '1006'
-- 错误:Cannot delete or update a parent row: a foreign key constraint fails (`student`.`score`, CONSTRAINT `fk_stuNo` FOREIGN KEY (`stuNo`) REFERENCES `student` (`stuNo`))
-- : 要先删除成绩信息,再删除学生信息
语法2:
TRUNCATE TABLE 表名称
删除整张表中的数据。 只能删除整张表。
面试题:
比较truncate与delete实现数据删除?
-
delete删除的数据可以rollback,delete删除可能产生碎片,并且不释放空间
-
truncate是先摧毁表结构,再重构表结构
-
先把数据表干掉
-
创建一个新的数据表
-
无法rollback
-
准备数据:
insert into course(cid,cname) values('002','LOL');
insert into score(stuNo,cid,score) values('1001','001',85);
单表查询的sql语句:
select 列名 from 表名 where 查询条件8.1查询所有数据
group by 分组条件 having 分组后的条件 order by 排序条件 [limit ]分页使用的
语法:
select * from 表名 -- 这里的*表示所有列 -- select * from student; -- 查询的结构就是一张虚表 --8.2 查询部分列
语法:
select 列名,列名 from 表名 select stuNo,stuName from student;8.3查询部分行
语法:
select * from student where xxxxxx8.3.1 关系运算和逻辑运算符
案例:
-- 查询课程号 001 的成绩信息-- select * from score where cid = '001' -- 查询课程号不是 001 程序 -- select * from score where cid <> '001' select * from score where cid != '001' -- 查询课程号 001 的,并且成绩在80以上的学生学号 -- select stuNo from score where cid = '001' and score >= 80
对照表:
[1] is null和is not null
tips:判断某一列是否为null,要使用 is null, 而不是 = null
-- 查询手机号码为 null 学生信息 -- select * from student where stuTel is null; -- 查询手机号码不为 null 学生信息 -- select * from student where stuTel is not null;
[2]like
语法:
select * from 表名 where xxx like '%_哈哈';
% 表示任意多个任意字符
_ 表示一个字符
-- 查询姓梅的学员 -- select * from student where stuName like '梅%'; -- 查询名字中有”风“ -- select * from student where stuName like '%风%'; -- 查询复姓”欧阳“,名字只有一个字的 -- select * from student where stuName like '欧阳_';
[3]not like
和like相反
select * from student where stu_name not like '梅%'
范围查询
需求:查询成绩在70~80之间的成绩信息
使用ADN链接条件
select * from score where 80 > score and score >= 70
使用between关键字
-- between是闭区间 --
select * from score where score between 70 and 80
算数运算符BETWEEN关键字表示两个范围之间。 包含了范围的两端的值。
ADN链接的两个值必须是前面是小的,后面是大的。
这里的算数运算符就是传统的 加减乘“除”。
算数运算符可以使用在select,where和having字句中。
需求:查询所有的成绩,并且给所有的成绩添加5分显示。
select cid,stu_no,score+5 from score
这里是修改了查询的结果,并没有修改物理数据库表的数据。
需求:查询所有分数是偶数的成绩信息
-- MySQL可以 --
select * from score where score % 2 = 0
-- 标准写法 --
select * from score where mod(score,2) = 0
需求:查询所有的成绩信息,并且给所有的成绩除以2再显示
-- MySQL --
select cid,stu_no,score/2 from score
去重
需求:查询有考过85分以上的学生的学号
在select字句中使用distinct去掉重复的数据。
select DISTINCT stu_no from score where score > 85
排序
默认情况下,我们的查询的数据都是按照主键的(字典顺序)升序进行排序的。
如果是联合主键,也是按照主键的顺序,先排第一个,再排第二个:
我们可以通过ORDER BY 指定排序的列和方式
语法:
SELECT XXXX FORM XXX WHERE xx ORDER BY 列名 [ASC|DESC]
ORDER BY 后面是排序的列。
ASC表示升序排序,这个默认的,可以不写。
DESC表示降序排序,如果要使用降序排序,必须要写DESC
需求:查询所有课程为001的程序,按照成绩的升序排序
select * from score where cid = '001' order by score asc
再按照降序排序
select * from score where cid ='003' order by score desc
按照多列排序。
需求:查询所有成绩,按照成绩的升序排序,如果成绩一致,再按照课程号升序排序
select * from score order by score,cid
查询所有成绩,按照成绩的降序排序,如果成绩一致,再按照课程号降序排序,课程号如果一致,则按照学号的降序排序
select * from score order by score desc,cid desc
1.6别名
在查询过程中我们的表名或者列名都是可以使用别名的。
需求:查询每本图书的所有信息和利润
select b.isbn,b.title ,(price - cost) from g_book b
别名的使用:
select b.isbn 图书编号,b.title 标题 ,(price - cost) '利润' from g_book b
标准的别名的语法: 其中as是可以省略,所以常见的都是不写。
select 列名 as 别名,列名 as 别名..... from 表名
除过给列添加别名之外,还可以给表添加别名。
-- 查询成本在10块以上的图书 --
select isbn,title,cost from g_book as b where b.cost > 10
表的别名在多表查询时才有实际的意义,暂时看不出来意义。
1.7集合函数数据库的函数,就是说在数据库内部已经定义好的一段可重复执行的程序(方法)
1.7.1 COUNT函数计数用的函数。
语法:
select count(列名) from 表名....
这里的列名一般使用*.
需求:统计所有学生的数量
select count(*) from student
查询结果只有一行一列。
count函数中的列可以写某一个列,也可以写 “*”,也可以写 1
也可以使用数字
select count(1) from student
如果指定了列,但是者列中存在null。
select count(stu_tel) from student
为 null的数据是不统计进去的。一旦使用类聚合(统计)函数,select字句中的列名不能随意写。
select字句后如果出现聚合函数, 则只能和分组的列一起显示,否在在Oracle会有错误。
在目前的情况下,只能出现聚合函数,不能出现其他的列。
MySQL中不报错,但是显示的结果是不正确(不合理):
分析:
1.7.2 求和函数 sumCOUNT(*)查询出来的结果是一行一列的。 但是 stuName有6个,6个stuName和一行一列的统计结果无法在同一行显示。所以无法查询。
需求:计算课程号为001的总分
select sum(score) from score where cid = '001'
两个聚合函数可以一起使用
select sum(score),count(*) from score where cid = '002'
tips:sum()函数中的列只能有一个,就是要求和的列。
1.7.3 求平均值函数 avg需求:计算学号为1001的学生的平均分
select avg(score) from score where stuNo ='1001'
select avg(score) 平均分,sum(score) 总分 from score where stuNo ='1001'
1.7.4 统计最大值 max
需求:计算所有成绩的最高分
select max(score) from score
1.7.5 统计最小值 min
需求:计算所有成绩最小值
select min(score) from score
1.8 分组查询
1.8.1 按照一列分组
数据库通过GROUP BY 进行分组统计
语法:
SELECT ... FORM ... WHERE ... GROUP BY 要分组的列(要合并的列)
数据库会自动将要分组的列中相同的数据合并。
SQL实现:
select avg(score) from score group by cid
上面的数据显示只有一列。
其实在分组之后,我们可以在select字句写group by后面的列。
看案例:
select cid,avg(score) from score group by cid
tips: 如果出现了分组,则select字句后只能出现聚合函数(分组函数)和group by后面的列。
我们分组的目的是计算平均分,所以肯定要使用聚合函数:
select stuNo,cid,avg(score) from score group by stuNo
这里的CID是不合理的,其他数据库直接报错。
我们会发现,stuNo和平均分是一一对应的,是合理的。
如果出现了group by分组,则select字句后可以出现的列只有聚合函数和group by 后面的列。
查询每门可的平均分:
select cid,avg(score) from score group by cid;
1.8.2按照多列分组
需求:查询每个城市的发送订单的数量,要求显示省份和城市
SELECT deliverProvince,deliverCity,count(*)
FROM g_order
GROUP BY deliverProvince,deliverCity
如果是按照多列分组,则将多列使用","隔开写在group by 后面。
分组的列都可以写在select字句后面。
1.8.3 分组查询之后的筛选需求:查询平均分在72分以上的学员的编号
先统计平均分,再进行筛选
这里使用HAVING关键字。 类似于where,主要用于给分组后的结果进行筛选
select stu_no,avg(score) from score group by stu_no having avg(score) >= 72
HAVING和WHERE一样可以使用各种运算符。 而且HAVING可以使用集合函数。
面试题:WHERE 和 HAVING有什么区别?
3、几个特殊的条件 3.1使用in关键在进行罗列查询需求:查询学号为1001,1005,1012,1004的学员的信息
-- 使用or连接的写法 --
select * from student
where stuNo = '1001' or stuNo = '1005' or stuNo = '1004' or stuNo = '1008'
-- 使用in关键字进行罗列 --
select * from student
where stuNo in ('1001','1002','1008','1004');
3.2使用 any 或者 allin 或者not in后面是一个数值的罗列,可以是任何类型。
罗列的数值不一定必须是查询的目标数据表中的数据。
MySQL中无法使用
-- 查询使用量大于70000的 --
-- 大于罗列值的任何一个 --
select * from t_account where usenum > any (70000,80000,100000)
-- 大于罗列数值的所有的 --
select * from t_account where usenum > all (70000,80000,100000)
连接查询
传统内连接
需求:查询所有帅哥的信息
select * from boys
需求:查询所有的帅哥的信息以及他们的女朋友的名字
直接在from后面写两张表
select * from boys,beauty
boy表中的每一条数据都会和beauty表中的每一条数据都对应起来。
这个结果就是 “笛卡尔积” 全连接得到结果:“笛卡尔积”
如果不想产生笛卡尔积,就要添加查询的条件(连接条件)
select b.id,b.boyname,be.name
from boys b,beauty be
where b.id = be.boyfriend_id
order by b.id
这张虚拟表的数据来自于两张表。
传统连接查询的语法:
SELECT 列名
FROM 表名1,表名2,....
WHERE 连接条件和查询条件。。。
让每个人对应别人的女朋友:
select boys.*,beauty.name from boys,beauty where boys.id <> beauty.boyfriend_id order by boys.id;
tips:链接条件不一定必须是外键相等的链接。
如果连接条件就是外键相等的情况,我们会发现无法对应的数据是不会显示的。??
select b.id,b.boyname,be.name
from boys b,beauty be
where b.id = be.boyfriend_id
order by b.id
这个查询结果是不会有“卡卡西”的,因为他没有女朋友。
一个案例:
-- 查询所有的同学的学号,名字,和考试成绩 --
select student.stu_no,stu_name,score from student,score where student.stu_no = score.stu_no
三表的连接查询:
需求:查询所有同学的姓名,成绩和课程名称
select st.stuName,c.cname,sc.score
from student st,score sc,course c
where sc.stuNo = st.stuNo and c.cid = sc.cid
注意的问题:
-
如果是按照外键连接,则理论上有n张表,则至少有n-1个连接条件。
-
在列中,如果一列存在于多张数据表,则一定要使用表名.列名注明。
你在写多表连接的时候,无论几张表,都可以按照下面的步骤完成:
-
根据需求,明确要使用表。
-
在from后面罗列这些数据表。
-
在where后面,罗列他们的外键条件。
-
在select后面写上要显示的列
需求:请查询“张三”都买了哪些书?
select g_book.*
from g_customer,g_book,g_order,g_orderitem
where g_customer.customerId = g_order.customer_id and g_order.orderId = g_orderitem.orderId
and g_orderitem.isbn = g_book.isbn and g_customer.customerName='张三'
标准内连接查询
语法:
select 列名
from 表1 [inner] join 表2 on 连接条件
inner join 表3 on 连接条件
.....
where 查询条件
案例1:
查询东方不败的CP值和他女朋友的信息
select b.usercp , be.* from boys b join beauty be on b.id = be.boyfriend_id where b.boyname='东方不败'
案例2:
需求:查询所有同学的学号,姓名,课程名,成绩和班级名称
select st.stu_no,stu_name,cname,score,class_name
from student st join score sc on st.stu_no = sc.stu_no
join course c on c.cid = sc.cid
join class_info ci on ci.class_id = st.class_id
外连接
问题:查询所有的boys和他们的女朋友的信息
select * from boys join beauty where boys.id = beauty.boyfriend_id
上面的写法扣除一半分。因为这个内连接是无法查询没有女朋友的boys的。
内连接只查询完全符合连接条件的数据。
外连接可以做到即使没有与之对应的数据, 依然会显示。
语法:
selec .. from
表1 left [out] join 表2 on 连接条件
....
左外连接的特点就是,左边表中的数据要全部显示,右边表如果有与之对应的记录就正常显示,如果没有与之对应的记录就显示null。
案例:
select * from boys left join beauty where boys.id = beauty.boyfriend_id

连接统计:
需求:请统计每个小伙子的女朋友个数,要求显示小伙子的名字
select boyfriend_id,count(*) from beauty group by boyfriend_id
select boyfriend_id,boyname,count(*) from boys b ,beauty be
where b.id = be.boyfriend_id
group by be.boyfriend_id,boyname
-- 最终结果 --
select boyfriend_id,boyname,count(be.id) from boys b left join beauty be
on b.id = be.boyfriend_id
group by be.boyfriend_id,boyname
右外连接, 把left join 修改为right join, 意思就是右边的表全部显示,左边有与之对应的数据就显示,没有就显示null。
面试题:内连接和外连接有啥区别?
内连接时,返回查询结果集合中的仅是符合查询条件( WHERE 搜索条件或 HAVING条件)和连接条件的行。
而采用外连接时,它返回到查询结果集合中的不仅包含符合连接条件的行,而且还包括左表(左外连接时)、右表(右外连接时)或两个边接表(全外连接)中的所有数据行。
4、数据表的5大约束为了保证数据的完整性(准确的数据),每个不同的数据库中都有各自的约束。
所谓数据约束就是给数据表的某些列添加的一些数据的要求。
[1]主键约束
所谓主键约束,就是将某一列设置为主键。
非空,唯一,每张表中只能有一个主键。
[2]非空约束 not null
[3]唯一约束 unique
面试题:唯一约束和主键有什么区别?
相同:它们都属于实体完整性约束.
不同点:
(1) 唯一性约束所在的列允许空值,但是主键约束所在的列不允许空值。
(2) 可以把唯一性约束放在一个或者多个列上,这些列或列的组合必须有唯一的。但是,唯一性约束所在的列并不是表的主键列。
(3) 唯一性约束强制在指定的列上创建一个唯一性索引。在默认情况下,创建唯一性的非聚簇索引,但是,也可以指定所创建的索引是聚簇索引。
(4)建立主键的目的是让外键来引用.
(5)一个表最多只有一个主键,但可以有很多唯一键
[4]检查约束(check约束) MySQL不支持
create table tbl_student(
stuNo varchar2(20) not null primary key, -- 主键约束 --
stuName varchar2(300) not null unique, -- 唯一约束 --
stuTel varchar2(11) not null check(length(stuTel) = 11) --检查约束--
)
-- 我们也可以在创建表之后添加唯一约束 --
alter table constraint uq_stuTel unique(stuTel);
添加数据:
insert into student(stuNo,stuName,stuTel) values('G001','卡卡西','13813813838');
-- 违反主键约束 --
insert into student(stuName,stuTel) values('卡卡西','13813813838');
insert into student(stuNo,stuName,stuTel) values('G001','卡卡东','13813813838');
-- 违反唯一约束 --
insert into student(stuNo,stuName,stuTel) values('G002','卡卡西','13813813838');
--违反检查约束--
insert into student(stuNo,stuName,stuTel) values('G002','佐助','1381381383');
[5]外键约束
所谓外键约束,就是如果添加了外键,则外键的列中的数据,必须在主表中已经存在。
[6]默认值约束
在创建表的时候设置defaulte值。 (不同的数据库,语法会略有不同)
如果不给这一列添加数据,就会自动使用默认值。也可以指定要求使用默认值。
-- 不给默认值列添加数据 --
insert into student(stu_no,stu_name,stu_birth,stu_tel,class_id)
values(.......)
-- 指定要求使用默认值 --
insert into student(stu_no,stu_name,stu_birth,stu_tel,stu_gender,class_id)
values('1012','迈特凯','1995-5-6','15815815838',default,1)
实体关系和表关系
实体关系是说:
情况1:班级对学生 典型 1 对多。
在多的一方有外键指向1的一方。学生表中有班级编号。
情况2:身份证信息对应人员信息 典型 1对 1。
无论从哪方有一个指向另外一方的外键即可。
情况3:学生信息 对 课程信息 典型 多对多关系。
多对多关系,要表达两个实体的关系,是需要第三张数据表。
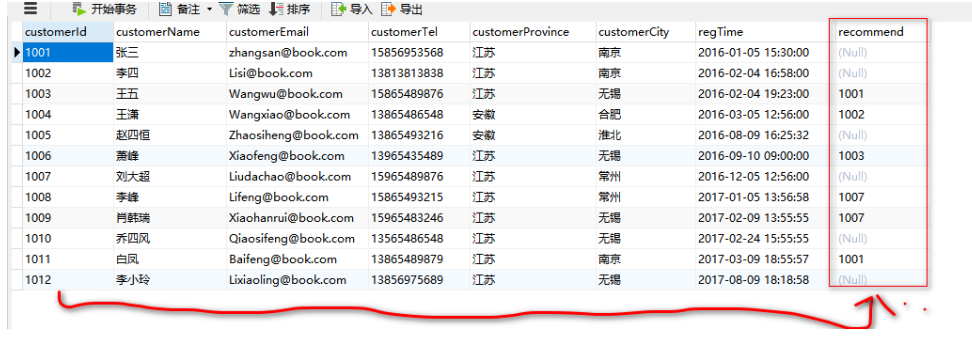
查询"张三"推荐了那些人 [自我连接]
select c1.* from g_customer c1 join g_customer c2 on c1.recommend = c2.customerId
where c2.customerName = '张三'
所谓子查询其实就是在查询内部有一个完整的其他查询。
比如:在where字句或者having字句中 有一个完整的查询,我们将内部查询的结果做为判断条件,这种内部的查询就是条件子查询。 在FROM字句后面使用一个完整的查询查询一个虚拟表,我们再虚拟表上继续查询,这种子查询就是虚拟表子查询。
tip:在实际开发中,可以不使用子查询的情况下尽量不要使用,特别是复杂的子查询。表数量有限的情况下,尽量使用连接查询。
所有的条件子查询查询的结果都必须是单列的。
2.4.1单行子查询所谓单行子查询就是,子查询查询出来的结果只有一行。
需求: 查询东方不败的女朋友的信息
连接查询实现:
select be.* from boys b join beauty be on b.id = be.boyfriend_id where b.boyname='东方不败'
子查询:
select * from beauty where boyfriend_id = (select id from boys where boyname='东方不败')
条件子查询查询的是单行单列的数据,可以使用的运算符: =、>、>=、<、<=、<>
案例:查询usercp值大于张无忌的所有的小伙子
select * from boys where usercp > (select usercp from boys where boyname='张无忌')
2.4.2多行子查询
需求:查询CP值在500以上的小伙子们的女朋友的信息。
select * from beauty where boyfriend_id in (select id from boys where usercp >= 500)
上面的例子中子查询返回的时单列多行的数据,这种情况下只能使用:in 、not in
笔试题:
给了一个使用in的条件子查询,要求优化这个sql语句。优化思路就是将使用in的子查询语句修改为exists
2.4.3 exists关键字
需求:使用exists查询CP值在500以上的小伙子们的女朋友的信息。
使用exists实现:
select * from beauty be where exists (select id from boys b where usercp >= 500 and b.id = be.boyfriend_id)
同样有 not exists。
笔试题:优化sql,将in关键字修改为exists。
外面查询的where条件转移到里面。 将in修改为exist。

案例:
需求:使用子查询(in和exists)查询清华大学出版社和机械工业出版社出版的所有图书信息?
-- in --
select * from g_book where pid in(select pid from g_pubsher where pname='清华大学出版社' or pname='机械工业出版社')
-- exists --
select b.*
from
g_book b where
exists
(select * from g_pubsher p
where
( p.pname='清华大学出版社' or p.pname='机械工业出版社') and b.pid = p.pid)
2.5虚拟表子查询
所谓虚拟表子查询,我们将子查询的结果作为一张数据表继续查询。
案例:
select title,pname from
(select b.*,p.pname from g_book b join g_pubsher p on b.pid = p.pid) d
虚拟表也可以和其他的数据表进行连接查询。
需求:查询每门课考试成绩最高的学生的信息,要求显示这个学生的信息以及它的成绩和课程名。
实现思路:
-- 查询每门课最高成绩的学员的学号 --
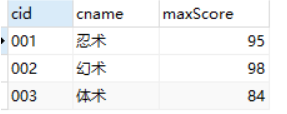
-- 查询每门课的最高分以及课程编号和课程名称 --
select c.cid,c.cname,max(sc.score) maxScore
from course c,score sc
where c.cid = sc.cid
GROUP BY c.cid,c.cname
根据上面的信息继续查找学员的信息。
-- 将上面查询的虚拟表,作为一张数据表和成绩表再次连接查询 --
select score.stu_no,d.* from score join
(select c.cid,c.cname,max(sc.score) maxScore
from course c,score sc
where c.cid = sc.cid
GROUP BY c.cid,c.cname) d on score.cid = d.cid and score.score = d.maxScore
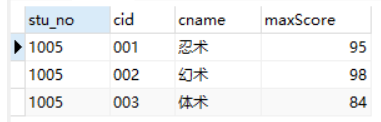
完善上面的需求:
select student.*,score.*,d.* from score join student on student.stu_no = score.stu_no
join
(select c.cid,c.cname,max(sc.score) maxScore
from course c,score sc
where c.cid = sc.cid
GROUP BY c.cid,c.cname) d on score.cid = d.cid and score.score = d.maxScore

-- 查询每个图书种类中成本最高的图书信息以它的类别信息 --
-- 寻找子查询 --
select category_id,max(cost) from g_book group by category_id
-- 使用子查询实现结果 --
select b.*,c.*
FROM g_book b join g_category c on b.category_id = c.cid
join
(select category_id cid,max(cost) maxCost from g_book group by category_id) d
on c.cid = d.cid and b.cost = d.maxCost
2.6分页查询
分页查询的思路:
将所有的数据排序。第一页就是前面的pageNum条数据。第二页就是接下来的pageNum条。
假如数据如下:
1,2,3,4,5,6,7,8.........
每页三条
第一页:123, 第二页:456 第三页:789 。。。。。
第一页是1~3 第二页 4~6 第三页是7~9 。。。。。
我们使用between关键字查询 betwen start and end。 只要知道start和end就可以查询了。
start = (page-1)* pageSize ;
在MySQL提供了一个关键字limit,可以指定查询前几条,或者从某一条开始查询前几条。
limit关键字的语法(limit都是在一个完整的sql语句的最后面)
select 。。。from 。。。where。。。 limit [start,]size
start : 表示开始查询的位置,默认从0开始。可以不写。
seiz:查询的条数。
-- 查询图书前三本 --
select * from g_book limit 3
分页查询:每页三条
-- 查询第一页 --
select * from g_book limit 0,3;
-- 查询第二页 --
select * from g_book limit 3,3;
-- 第三页 --
select * from g_book limit 6,3;
-- 第四页 --
select * from g_book limit 9,3;
-- 第五页 --
select * from g_book limit 12,3;
3、MySQL中的自增列
自增列:在数据表中,整型(int,bigint)的列,在不赋值的情况下,会自动从1开始增长。可以增长到整型的最大值。 自增列的值不能重复,不能后退。 所以往往会使用自增列作为主键。
SQL Server和MySQL都是在创建表的时候,可以指定自增列的。
Oracle和DB2没有自增列。提供了一个序列来解决自增列的问题。
MySQL中自增列的创建方式:
通过auto_increment指定某一列是自增列
create table user(
userid int not null primary key auto_increment,
username varchar(50)
)
自增列在添加数据的时候,可以不添加数据,它会默认自增。(MySQL)
insert into user(username) values('鸣人1');
insert into user(username) values('鸣人2');
insert into user(username) values('鸣人3');
insert into user(username) values('鸣人4');
insert into user(username) values('鸣人5');
查询:
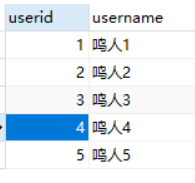
MySQL中的自增列,也可以指定值:
insert into user(userid,username) values(6,'鸣人6');
当然,自增列是不能重复的。
自增列的数据,一旦不删除,不能重复出现:
delete from user where userid= 6;
insert into user(username) values('鸣人6');
id为6的被删除之后,不会重复出现
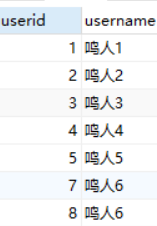
如果我们强行指定userid为6,再次加入,是可以添加的。(SQLServer中的自增列是做不到的)
如果我们在添加的时候,指定了自增列的值,并且跳过了一部分自增列的值,情况如下:
insert into user(userid,username) values(12,'鸣人12');
insert into user(username) values('鸣人13');

MySQL中的自增列如果我们手动插入了最大值,自增就是找到当前列中最大值,然后+1。如果我们没有手动指定值,则它自己会记录之前的最大值,哪怕最大值已经被删除,依然会在最大值上+1。
面试题:
问题:如果MySQL数据表中的自增列达到最大值的时候,应该怎么处理?
int:21亿
bigint: 很大的一个值。
MySQL官方给出,单表数据量5000000。
如果是频繁的消耗自增列,并且自增列不是主键,可以考虑从1重新开始。
[1]考虑不使用自增列。(UUID)
[2]定期整理自增列。尽量让自增列连续。
[3]通过应用程序指定自增列的值。(可能会降低效率)