从前,有个女生宿舍,住着小A、小B、尤娜和我4个人。有天,小A不小心把小B的床板坐塌了。小B非常生气,当场和小A翻脸。不论人缘最好的尤娜怎么中间调解都不管用。一直到毕业,小A和小B再没有说过一句话。
后来,小A、小B和尤娜都成了公司老板,只有我一事无成。小A公司需要使用小B公司的系统,小A还记着当年的事情,没敢直接找小B,就找尤娜商量。尤娜就找到小B诉说原委。有生意小B自然是愿意做的,但是想到关系这么僵了,还是放不下身段。尤娜叹了口气:“这样吧,我们公司做一个系统,你俩都来接我吧。”
于是,尤娜成立了一个以自己名字命名的项目,看着我实在找不到工作,就让我自学编程,给她做开发。于是尤娜初版就这样上线了。架构是这样的:
我还只是个菜鸟,所以我的做法只是把B的http接口包装了一下,其他什么也没有做。上线之后,我发现A的调用请求一天有几个时间调用量特别大,小B公司的老师说:“扛不住了,不要把流量直接透传过来呀!”
我通过自己的学习调查,发现可以使用消息中间件做个缓冲。当A请求过来,我先把请求放到消息队列里,然后再自己消费后转发请求给B。因为消费是匀速的,就起到了削峰填谷的作用。
但是这样,我怎么把返回结果再返回给A呢?聪明如我怎么会想不到办法,我把B返回的结果记录到数据库中。当A的请求发送到消息中间件后就循环去数据库里取结果,取到就返回这个结果给A。完美!
于是我跟尤娜商量了这个想法,尤娜是我的好姐妹,我的想法她马上表示支持,让我放手去做,资源呀什么都不是问题。
我按照网上找到的《项目中怎样做技术选型》的文章,结合目前的特点,优缺点比较之后,消息中间件使用kafka,数据库使用mysql。经过自己的努力,尤娜第二版上线啦。架构是这样的:
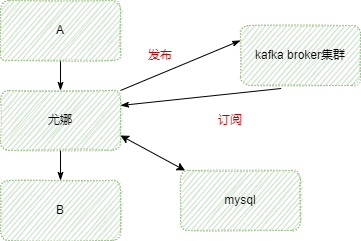
kafka集群的内部架构,我是参考《Kafka生产端实际项目中的使用分析》这篇文章,使用zookeeper做分布式协调。上线不久后,意想不到的事情发生了:kafka broker集群挂了。不管三七二十一先重启再说。
重启之后,尤娜消费端没有恢复,每隔3ms报一个warn日志:
Auto offset commit failed for group XXX:
Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member.
This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms,
which typically implies that the poll loop is spending too much time message processing.
我根据auto offset commit failed(自动提交offset失败了)这个信息在网上搜索了一下。通过之前的学习我知道:kafka的数据更新消费都是通过在zookeeper中标记一个偏移量(offset)来记录每个分区的消费位置,所以一旦offset更新失败,会出现重复消费数据的问题。
最终我分总结出:kafka消费者在处理消息时,在指定时间内(session.time.out)没有处理完。kafka消费要在消息处理完之后,自己提交当前的offset给kafka集群。而这时候已经超时断开连接了,导致自动提交offset失败。因此就会像日志中所说的发生rebalanced(重平衡即重新分配partition给客户端),而之前提交的offset已经失败了,所以重新分配的客户端又会消费之前的数据,接着consumer重新消费,又出现了消费超时,无限循环下去。
出现这个原因是因为我客户端使用时就是使用了spring-kafka,只用了一个@KafkaListener,没有修改任何默认配置。而默认enable.auto.commit设置成true,可以改为false,不采用自动提交方式。所谓不自动提交实际上是消费端收到消息不先处理而是先提交offset再处理。
这种解决方案,万一提交了offset之后消费失败了不会再次处理。这样次数多了向A不好交代呀。还是先不改了。我决定先修改session.time.out时间设置长一些,重启解决问题。
目前服务已经恢复了正常,作为菜鸟新人解决了问题觉得好激动。但是实际上细想还有好多问题没有弄明白,比如:kafka broker集群为什么挂了?太晚了,先睡觉再说。
突然想起那时候在宿舍我们四个一起读《飘》的情景,特别喜欢里面那句名言:无论如何,明天又是新的一天!
后记:
尤娜系统的第一次飞行中换引擎的架构垂直拆分改造
四种常用的微服务架构拆分方式