发表时间及刊物/会议:2022 CVPR
发表单位:西安电子科技大学, 香港中文大学,重庆邮电大学
在大部分半监督学习方法中,一般而言,只有部分置信度高于提前设置的阈值的无标签数据被利用。由此说明,大部分半监督方法没有充分利用已有数据进行训练。
论文创新点设置了Adaptive Confidence Margin(自适应阈值)根据训练规律动态调整阈值,充分利用所有的无标签数据。
网络结构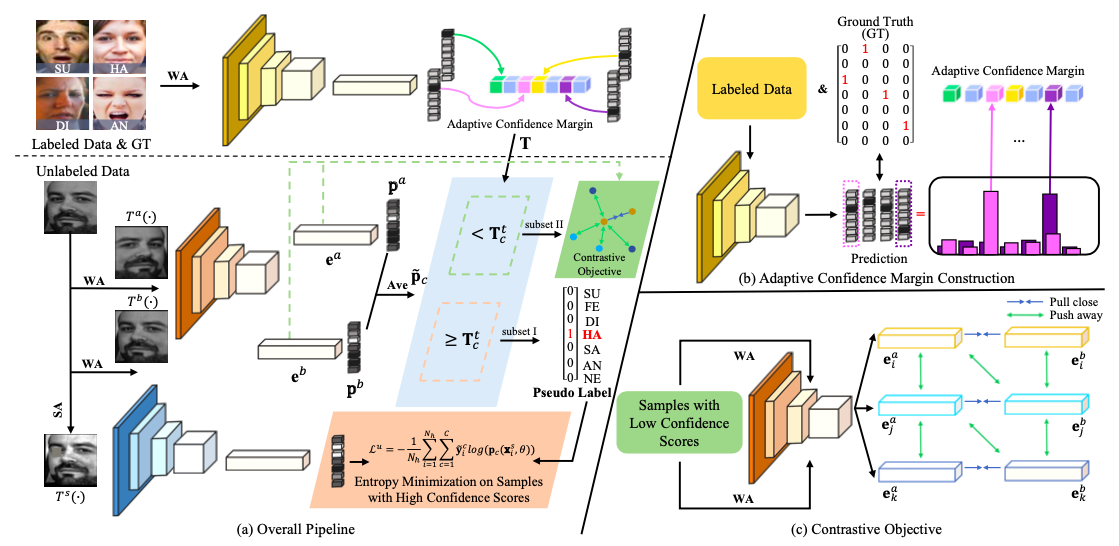
具体的训练步骤如下:
初始基本设定:
- 设置初始阈值,本文中,对于每个类别,阈值初始值为0.8。
- 本模型借鉴Mean Teacher的思想,引入老师模型(ema_model)。
- 训练时有标签和无标签数据按1:1的比例输入网络
- 模型backbone采用resent18,输出最后一层类别概率分布以及倒数第二层512维特征向量。
学生网络:
对于有标签数据:
有标签图片经过弱数据增强(WA)后进入模型,输出结果和真值对比,利用交叉熵函数作为损失函数,计算有标签损失\(L^s_{CE}\)。
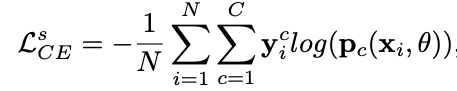
对于无标签数据:
无标签图片复制三份(a图, b图, c图),其中两份(a图,b图)经过弱数据增强(WA)后输入模型,再将输出的两个概率分布平均后得到最终的概率分布。记所得概率分布中的最大概率为\(f_{max}\),对应类别记作\(c\)。如果\(f_{max}\)大于此类别\(c\)对应阈值,则将\(c\)作为此类别的真实标签,并将此类数据归为子集I(含“真实标签”);否则,将此类数据归为子集II(无真实标签)。
如果此图片属于子集I,则将c图经过强数据增强(SA)后送入网络,和标签\(c\)计算交叉熵损失\(L^u\)。
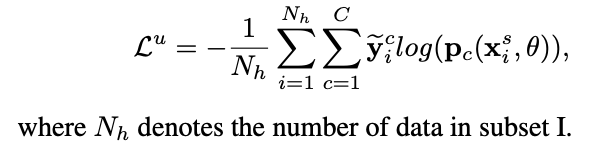
若此图片属于子集II,则\(L^u=0\)。并拼接a图,b图输入模型后得到的两个512特征向量,首先根据公式8 计算两个特征向量的相似度,再根据公式9计算SupConLoss \(L^c\) (具体计算方法见论文Supervised Contrastive Learning)。


总损失函数为:
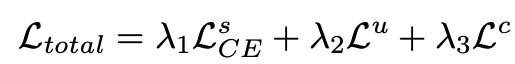
实验中\(\lambda_1 = 0.5,\lambda_2=1,\lambda_3=0.1\)。
老师网络
学生模型根据损失函数更新模型参数后,老师网络在学生网络的基础上使用指数平均移动的方式更新参数。之后,将有标签数据输入老师网络,得到概率分布。
对于一个batch的数据,记最大概率对应标签类别和真实类别相同的图片为集合\(N_{st}\),记\(N^c_{st}\)为最大概率对应标签类别和真实类别相同,且真实类别为\(c\)的图片张数,记\(s_i\)为最大概率, \(\hat{y_i}\)为预测类别,按照以下公式计算一个类别的平均最大概率,记为\(T_c\)。
之后,考虑到置信值会随着epoch数逐步提高,再根据以下公式计算当前epoch各个类别的阈值。

至此,一个iteration结束。
实验表1 固定阈值和我们方法的比较,在RAF-DB, SFEW数据集上的结果,其中FT 表示使用FixMatch方法时取固定阈值的具体值,
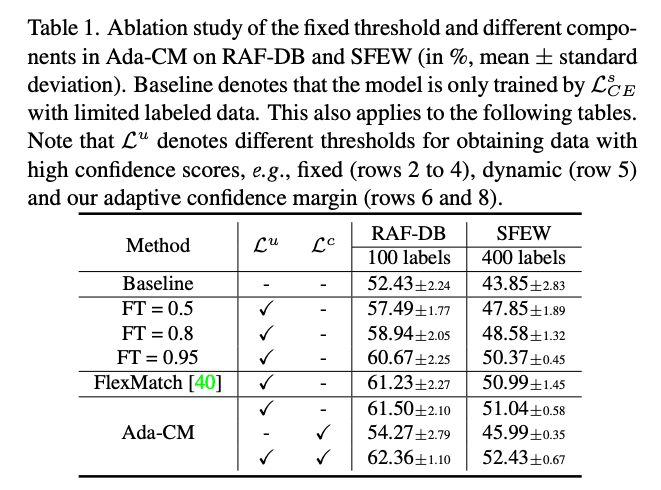
表2 RAF-DB, SFEW 和AffectNet三个数据集上我们的方法和其他优秀的半监督方法对比
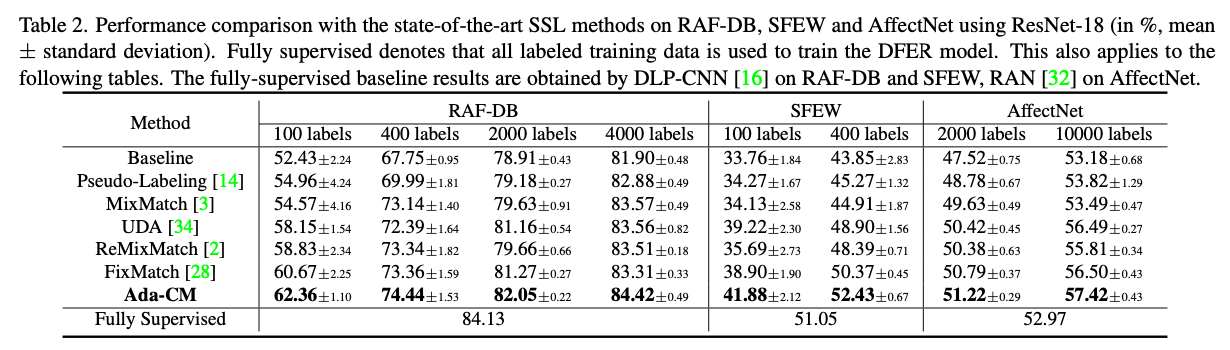
图3 自适应阈值调整方法,公式5中关于两个参数的值的消融实验
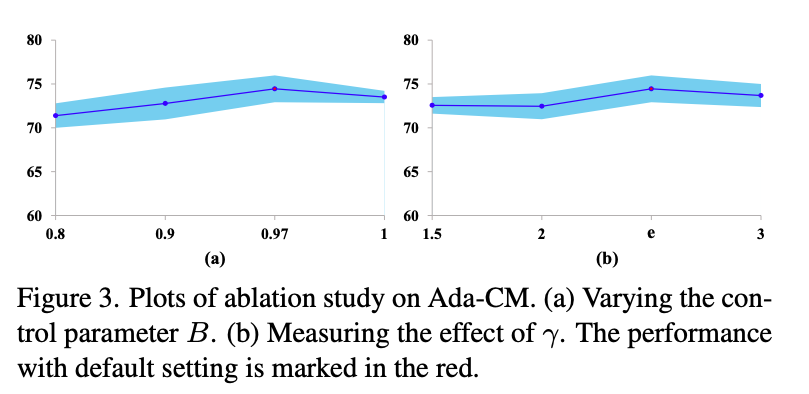
表3 使用WideResNet-28-2作为backbone在RAFDB上实验结果
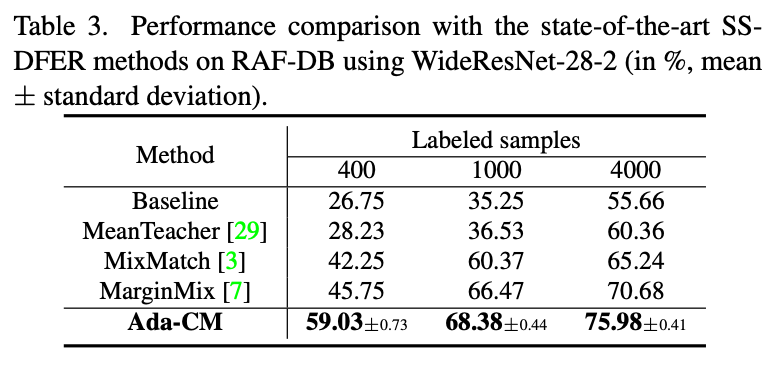
图4 使用2D t-SNE 可视化方法可视化得到的特征,从图中可以看出,我们的方法对各类表情提取特征的效果最好(不同类别的特征重合度最小)。

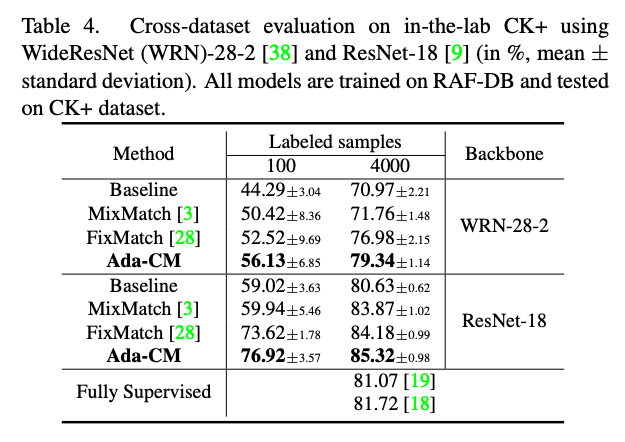
表4 各个不同类别的数据集交叉验证结果。以下结果为在RAF-DB上训练,CK+数据集上进行测试所得结果