哈希表(Hash Table)是一种根据关键字直接访问内存存储位置的数据结构。通过哈希表,数据元素的存放位置和数据元素的关键字之间建立起某种对应关系,建立这种对应关系的函数称为哈希函数(如图)。
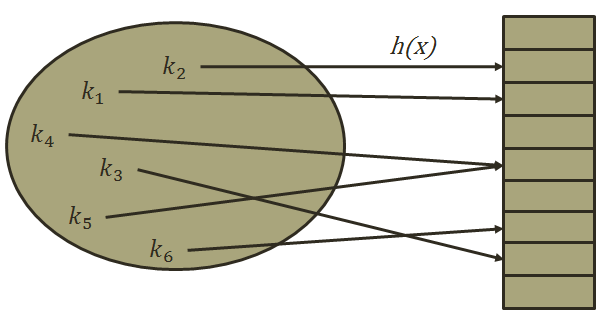
哈希表的构造方法是:假设要存储的数据元素个数为n,设置一个长度为m(m≥n)的连续存储单元,分别以每个数据元素的关键字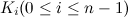 为自变量,通过哈希函数
为自变量,通过哈希函数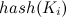 ,把
,把 映射为内存单元的某个地址,并将该数据元素存储在该内存单元中。
映射为内存单元的某个地址,并将该数据元素存储在该内存单元中。
从数学的角度来看,哈希函数实际上是关键字到内存单元的映射,因此我们希望通过哈希函数通过尽量简单的运算使得通过哈希函数计算出的哈希地址尽量均匀地被映射到一系列的内存单元中。构造哈希函数有三个要点:第一,运算过程要尽量简单高效,以提高哈希表的插入和检索效率;第二,哈希函数应该具有较好的散列性,以降低哈希冲突的概率;第三,哈希函数应具有较大的压缩性,以节省内存。一般有以下几种常见的方法:
- 直接定址法,该方法是曲关键字的某个线性函数值为哈希地址。可以简单的表示为:
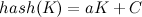 ,优点是不会产生冲突,但缺点空间复杂度可能会很高,适用于元素较少的情况下;
,优点是不会产生冲突,但缺点空间复杂度可能会很高,适用于元素较少的情况下; - 除留余数法,它是用数据元素关键字除以某个常数所得的余数作为哈希地址,该方法计算简单,适用范围广,是最经常使用的一种哈希函数,可以表示为:
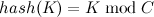 ,该方法的关键是常数的选取,一般要求是接近或等于哈希表本身的长度,理论研究表明,该常数取素数时效果最好。
,该方法的关键是常数的选取,一般要求是接近或等于哈希表本身的长度,理论研究表明,该常数取素数时效果最好。 - 数字分析法:该方法是取数据元素关键字中某些取值较均匀的数字位来作为哈希地址的方法,这样可以尽量避免冲突,但是该方法只适合于所有关键字已知的情况。对于想要设计出更加通用的哈希表并不适用。
在构造哈希表时,存在这样的问题,对于两个不同的关键字,通过我们的哈希函数计算哈希地址时却得到了相同的哈希地址,我们将这种现象称为哈希冲突(如图):
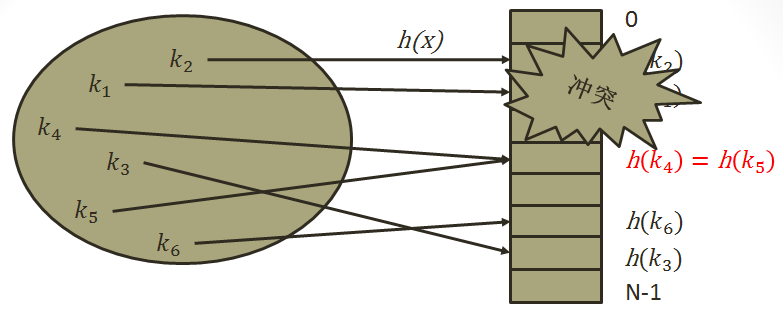
哈希冲突主要与两个因素相关:第一,填装因子,所谓的填装因子是指哈希表中已存入的数据元素个数与哈希地址空间大小的比值,即α=n/m,α越小,冲突的可能性就越小,相反则冲突可能性越大;但是α越小,哈希表的存储空间利用率也就很低,α越大,存储空间的利用率也就越高,为了兼顾哈希冲突和存储空间利用率,通常将α控制在0.6-0.9之间,而.NET中的Hashtable则直接将α的最大值定义为0.72(注:虽然微软官方MSDN中声明Hashtable默认填装因子为1.0,事实上所有的填装因子都为0.72的倍数);第二,与所用的哈希函数有关,如果哈希函数选择得当,就可以使哈希地址尽可能的均匀分布在哈希地址空间上,从而减少冲突的产生,但一个良好的哈希函数的得来很大程度上取决于大量的实践,不过幸好前人已经总结实践了很多高效的哈希函数,可以参考园子里大牛Lucifer的文章:数据结构 : Hash Table [I]。
哈希冲突通常是很难避免的,解决哈希冲突有很多种方法,通常分为两大类:
- 开放定址法,它是一类以发生哈希冲突的哈希地址为自变量,通过某种哈希函数得到一个新的空闲内存单元地址的方法(如图),开放定址法的哈希冲突函数通常是一组;

- 链表法,当未发生冲突时,则直接存放该数据元素;当冲突产生时,把产生冲突的数据元素另外存放在单链表中。
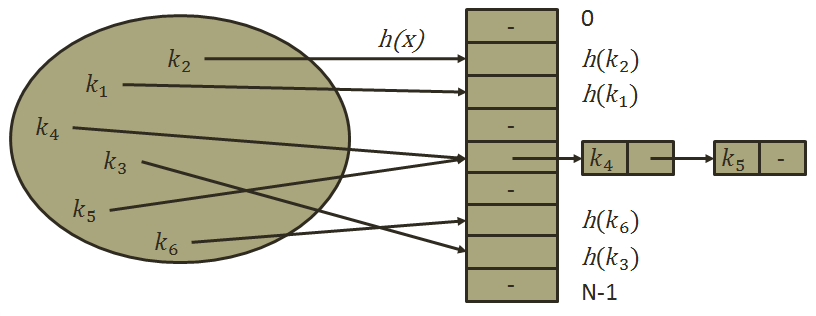
.NET中实现了哈希表的类分别是Hashtable和Dictionary<TKey, TValue>,Hashtable由包含集合元素的存储桶组成,存储桶是Hashtable中各元素的虚拟子组,与大多数集合中进行的搜索相比,存储桶可使搜索更为便捷。Dictionary则是泛型版本的哈希表,与Hashtable的功能相同,对于值类型,特定类型(不包括Object)的性能优先于Hashtable,这是因为Hashtable的元素属于Object类型,所以在存储或者检索类型时通常发生装箱和拆箱操作;除此之外,虽然微软宣称Hashtable是线程安全的,可以允许多个读线程或一个写线程访问,但是事实是它也并非线程安全,在.NET Framework 2.0新引入的Dictionary仍旧为解决这个问题,其中限于公共静态方法是线程安全的,因此可以说Dictionary是非线程安全的,而且对整个集合的枚举过程对二者而言都不是线程安全的,因为当出现枚举与写访问互相争用这种情况发生时,则必须在整个枚举过程中对整个集合加锁。如果我们在使用.NET Framework 4.0以上版本,我们可以使用线程安全的ConcurrentDictionary;另一个比较重要的区别在于,虽然它们都实现了哈希表,但是二者却使用了完全不同的哈希冲突解决方法,Hashtable解决冲突的方式是开放定址法,而Dictionary则采用了链表法。
Hashtable的实现原理Hashtable类中哈希函数的定义可以用如下递推公式来表示:

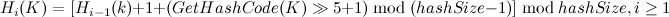
通过简单的数学推导就可以得出其通项式公式即Hashtable的哈希函数簇为:

因此我们就拥有了一系列的哈希函数: ,当我们向哈希表中增加元素时,则依次尝试使用这些哈希函数,直到找到相应的空闲内存单元地址为止,这种方式称为二度哈希。
,当我们向哈希表中增加元素时,则依次尝试使用这些哈希函数,直到找到相应的空闲内存单元地址为止,这种方式称为二度哈希。
在Hashtable类中,包含元素的存储桶被定义在结构体bucket中:
1 private struct bucket 2 { 3 public object key; 4 public object val; 5 public int hash_coll; 6 }
其中前两个字段很容易理解,分别代表了哈希表中的关键字和值,对于第三个字段hash_coll,实际上保存了两种信息:关键字的哈希码和是否冲突,coll为collision(冲突)的缩写,该字段为32位整型类型,最高位为符号位,当最高位为0时,表示该数为正数,表示未发生冲突,为1时为负数,表示发生了冲突,剩下的其他位则用于保存哈希码。
下面我们来看一个简单的哈希表元素增删过程,使得我们对于哈希表的具体工作方式有一个更直观的了解,当我们未指定具体Hashtable容量大小时,来进行一组数据的插入操作,此时Hashtable类会自动初始化其容量为默认最小值3。
- 插入元素[20, “elem1”],根据Hashtable类哈希函数通项式,所以其哈希代码的值为
 ,此时为第一次插入数据,因此不存在冲突,直接寻址到bucket[2],由于不存在冲突,因此hash_coll的值即为其key的哈希代码,存储结构如下图:
,此时为第一次插入数据,因此不存在冲突,直接寻址到bucket[2],由于不存在冲突,因此hash_coll的值即为其key的哈希代码,存储结构如下图: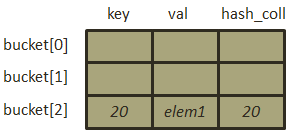
- 插入元素[33, “elem2”],同理
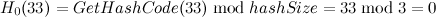 ,此时仍然不存在冲突,存储结构如下:
,此时仍然不存在冲突,存储结构如下:
- 插入元素[40, “elem3”],此时的哈希表进行扩容,为什么会在此时扩容呢,哈希表的填装因子为2/3=0.66并未超过0.72,在.NET中,微软对填装因子进行了换算,通过填装因子与哈希表大小的乘积取整获得哈希表的最佳填装量即:3×0.72=2。扩容后的哈希表大小为原表容量大小的2倍后的质数,在本例中再次扩容后哈希表大小为7。进行扩容之后,原哈希表的已经存储的元素必须按照新的哈希表的哈希函数(其实哈希函数本身没有发生变动,发生变动的是哈希表的长度)进行计算,重新寻址,扩容后的哈希表如下:
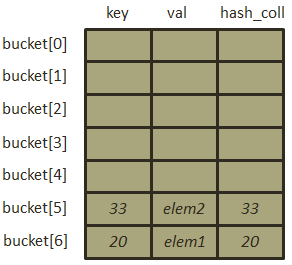
完成扩容过程后才会对[40, “elem3”]进行插入操作, ,现在我们发现冲突产生了,因为此时bucket[5]的位置已经有元素了,此时进行二度哈希:
,现在我们发现冲突产生了,因为此时bucket[5]的位置已经有元素了,此时进行二度哈希: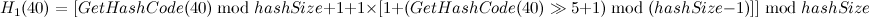

此时哈希表中位置为1的空间仍旧处于空闲状态,因此进行插入操作,在将元素插入之前,由于bucket[5]出现了冲突,因此需要对其进行标记,将hash_coll的最高位置为1,表示其出现了冲突,所以完成插入后哈希表结构如下图: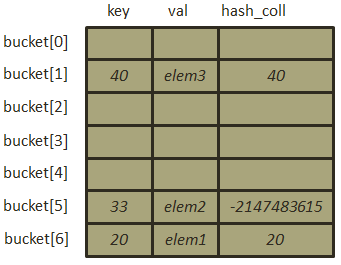
- 插入元素[55, “elem4”],同理,
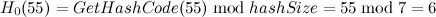 ,产生冲突,进行二度哈希:
,产生冲突,进行二度哈希: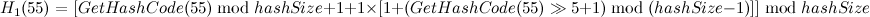
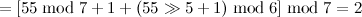 ,完成插入后哈希表的存储结构为:
,完成插入后哈希表的存储结构为:
- 删除元素[20, “elem1”],在删除元素时,同样需要根据哈希函数来进行寻址,如果有冲突,则进行二度哈希,但是值得注意的一点是,删除冲突标记元素(即元素的hash_coll值为负数)和非冲突标记元素是有差别的,在删除非冲突标记元素时,则直接将要删除的元素的键和值修改为null并将hash_coll置0即可,但是在删除冲突标记元素时,需将hash_coll的hash部分(即0-30位)置0以及将元素的值置为null,还需将该元素的键指向整个哈希表,之所以这样做是因为当索引为0的元素也出现冲突时,将无法判断该位置是一个空位还是非空位,那么再次进行插入时很可能将索引为0处的元素覆盖。删除[20, “elem1”]后的结构为:

从.NET Framework 2.0开始,随着泛型的引入,类库提供一个新的命名空间System.Collection.Generic,并且在该命名空间下新增了Dictionary等泛型类。
Dictionary的哈希函数就相对简单,就是简单的除留余数法,对于冲突解决,Dictionary则采用了链表法,但是此时buckets数组已经退化为专门用于存储元素的位置(下标)的整型数组,包含元素的数据结构被定义为结构体Entry,通过一个Entry类型的数组entries专门用于存储元素,Entry的定义如下:
1 private struct Entry 2 { 3 public int hashCode; 4 public int next; 5 public TKey key; 6 public TValue value; 7 }
其中的next字段表示数组链表的下一个元素的下标,一个关于数据存储结构的简单图示如下:
我们用同样的方式来看看Dictionary插入和删除元素的简单过程:
- 插入元素[20, “elem1”],跟Hashtable类似,Dictionary初始化容量也为3(如果未指定初始化容量),Dictionary的哈希函数就非常简单了,除留余数法直接获取其哈希地址,
 ,那么此时在entries[0]直接保存下元素的键值以及哈希码,并将此时元素在entries数组中的索引赋值给buckets[2],如下图:
,那么此时在entries[0]直接保存下元素的键值以及哈希码,并将此时元素在entries数组中的索引赋值给buckets[2],如下图: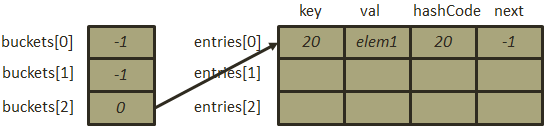
- 插入元素[33, “elem2”],其哈希地址为:
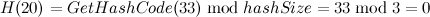 ,插入后存储结构如下:
,插入后存储结构如下:
- 插入元素[40, “elem3”],计算后的哈希地址为
 ,刚好未发生冲突,由于不受填装因子(此时填装因子为1)的约束,此时无须扩容,插入该元素后的存储结构为:
,刚好未发生冲突,由于不受填装因子(此时填装因子为1)的约束,此时无须扩容,插入该元素后的存储结构为: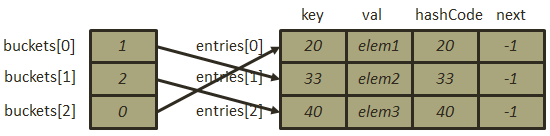
- 插入元素[55, “elem4”],此时Dictionary的容量已满,必须进行扩容操作,Dictionary的扩容和Hashtable的扩容策略一致,扩容后的Dictionary的容量大小为原Dictionary容量大小2倍后的质数即也为7,然后根据扩容后的Dictionary重新寻址,这意味着部分数据可能会引起冲突从而导致已有的链表会被打乱重新组织;Dictionary首先会将扩容前Dictionary中的entries中的元素全部复制到新的entries中,紧接着进行重新寻址,对于第一个元素[20, “elem1”],新的哈希地址为:
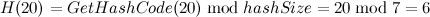 ,于是buckets[6]的值被修改为0(即元素[20, “elem1”]在entries中的索引),同理对于33:
,于是buckets[6]的值被修改为0(即元素[20, “elem1”]在entries中的索引),同理对于33: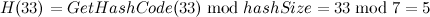 ,所以,buckets[5]=1,最后处理40,
,所以,buckets[5]=1,最后处理40,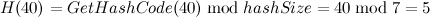 ,此时发生冲突,在通过链表法处理冲突时,Dictionary首先将新元素的next指向冲突位置的元素索引buckets[5],然后再将buckets[5]指向新的元素,此时一条只有两个元素的基于数组的链表形成,因此扩容之后的存储结构如下图:
,此时发生冲突,在通过链表法处理冲突时,Dictionary首先将新元素的next指向冲突位置的元素索引buckets[5],然后再将buckets[5]指向新的元素,此时一条只有两个元素的基于数组的链表形成,因此扩容之后的存储结构如下图: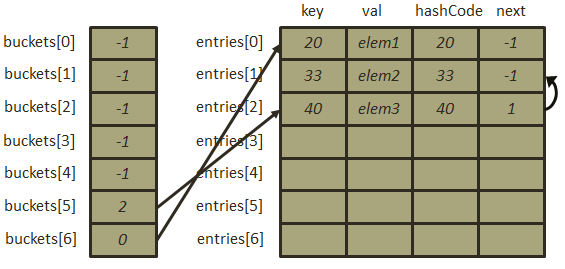
在这里可以看出无论是Dictionary还是Hashtable,扩容带来的性能损耗代价都是相当昂贵的,因此我们最好能够预估出哈希表中最后容纳元素的总数,在哈希表初始化时就对其进行内存分配,从而避免不必要的扩容带来的性能损耗;
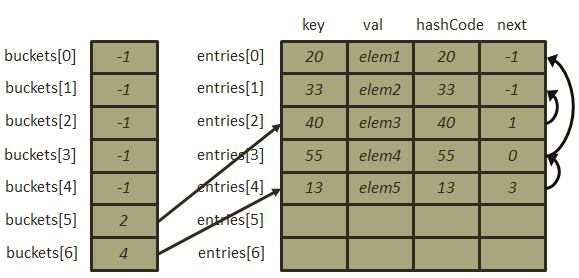
此时再插入元素[55, “elem4”],计算其哈希地址: ,再次发生冲突,那么按照刚刚的冲突解决办法,插入该元素之后的存储结构为:
,再次发生冲突,那么按照刚刚的冲突解决办法,插入该元素之后的存储结构为: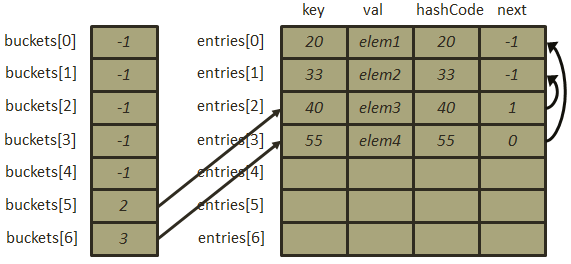
- 最后插入元素[13, “elem5”],
 ,再次冲突发生,那么插入该元素之后的结构图如下:
,再次冲突发生,那么插入该元素之后的结构图如下:
- 删除元素对于Dictionary来说就很简单了,如果在非冲突链上删除元素,非常简单,通过哈希算法寻址找到对应的元素删除并将buckets中对应的元素值修改为-1,如果在冲突链上删除元素,那么就是一个简单的删除链表元素的操作,在这里就留给读者去思考。
- 陈皓 - 可视化的数据结构和算法
- 张逸 - 考察数据结构——第二部分:队列、堆栈和哈希表[译]
- abatei - C#与数据结构--哈希表(HASHTABLE)
- 维基百科 – 散列表
- Angel Lucifer - 数据结构 : Hash Table [I]