铁道部新客票系统的设计(一)
铁道部新客票系统的设计(二)
铁道部新客票系统的设计(三)
在上一篇文章中 铁道部信客票系统设计(一) 里面,探讨了关于数据库层面的功能性需求以及非功能性的需求,在非功能性需求里面,一博主 提出了没有考虑到峰值的情况,这一点的确漏掉了,因为我们铁道部的特殊需求,在春运期间负载很大,平时可能一般,如果用考虑最大的情况,则回存在浪费的情况,如果考虑不足,就像网络订票一样,苦逼。就好比 铁道部春运的时候,发车量大,但是如果制造大量列车,平时就空闲了,也就很亏。机器的折旧很是块的。春运期间可以考虑紧急扩容来实现,所以从设计上可以保持这种扩展性。 扩容是一项工程,整体来说比较复杂。
上一篇博客发表后,也有博主和我探讨过一些问题,也让我了解到铁道部目前的状态。由于这个纯粹是技术上的分析,先不去考虑一些政治因素,毕竟这个比技术复杂多了
正题开始,原来打算这一篇里面介绍数据库表的设计,但是上一篇文章中还有很多细节问题,没有解决,这里面继续上一张,把数据这一层在慢慢完善
购票的业务流程
由于购票过程中是铁道部售票系统的主要功能也是核心业务逻辑,这里先从购票的业务流程开始,讨论购票业务流程中相关的数据库设计
简单的购票流程
终端-->查询余票-->选择车次-->确认座位-->选择张数-->支付-->出票
这里面重要的是两个环节 查询余票 和 支付过程
我们先模拟以下正常网络购票过程中数据库的操作,这里面先把问题简单化,假设用户只买始发站到终点站的数据
1 select * from 余票
2 insert into 车票
3 update 余票 -1
4 update 车票 set status='WAIT_PAY' where id = xxx
5 update 车票 set status='PAY' where id = xxx
电话订票类似,只不过订的票不会由于过期而取消,要么支付,要么退票
而在窗口、代售点买的票,支付方式只不过是现金,出票的时候自动支付。
其实无论从那个终端过来的请求,都会涉及到查询余票,创建车票,支付车票 过程,考虑一中简单的情况,就是用户只查询一次,就选择了自己要确定的车次,然后购票,去支付。那么一次购票请求,会至少 一次余票查询 一次余票更新,一次车票insert,两次车票update,这个还是最少的情况,实际铁道部的业务应该比这个复杂多了。由于查询余票是购票请求的入口,所有的购票请求都会优先查询余票库
余票库的设计
在第一篇文章中,余票库没有设计成为读写分离,主要是考虑的用户一定获取的是最实时信息,读写分离的话,读库和写库的数据有效性上面会有差异,比如我更新了一个数据,必须马上反映到余票上,否则用户看到一个过期的数据,对用户体验很不好。这个库的访问量超级大,而且还会涉及到热点数据的锁定,一旦同一条数据(比如我这次想买Z27硬卧)同时被大量用户请求,根据上面分析的,出票就要锁定余票表中Z27这一条记录,由于一次只允许一条用户请求能够获得锁,请求要必须尽快的处理,除了必要的原子操作,比如票数-1,产生购票表,其他的耗时操作就应该越少越好,尽量异步化操作,核心思想就是尽快的释放锁,否则请求排队的线程越来越多,导致数据库所有数据库的连接资源被耗尽,系统会变的很慢。
整理以下:在设计余票库的时候,在性能上提升,可以从下面几个方面去考虑
1 尽量减少没有必要的查询,减少数据库的资源消耗
2 锁的粒度越小越好
3 订票事务处理越短越好,消耗的业务逻辑处理越快越好,争取最大的异步处理。
接下来就是考虑如何通过上述思想,找出具体的设计方案
1 减少对数据库的查询一般情况下,先会查询某日余票信息,接下来就是根据查询出来的信息,选择车次,席位。然后张数,然后订票成功。
首先,假设我们把余票信息缓存,应用先查询缓存,如果有票,用户选择车次和席位,这样会减少一次数据库的查询。
缓存有两种方式,一种是应用局部缓存,每个渠道缓存票务数据,这里涉及到数据的更新以及各个缓存之间的同步,不及时,暂时不考虑。
另外一个种是分布式缓存,建立缓存服务器(这里面说的缓存都是指内存缓存),数据库只需要和缓存服务器之间保持同步,但是这样一来,如果会员想获取最新的数据,缓存服务器也需要保持很频繁的更新,相当于要保持缓存和余票数据的同步。这个成本也是非常高。还有一个折中方案,就是缓存不缓存票数,而是缓存有票无票信息,每次用户查询票数的时候,先查缓存信息,看看是否有票,如果有票,就查询数据查询具体的票数,如果无票,就不需要进行查询了,这样减少了数据库的查询。同时缓存的更新也少了很多,只需要在票数等于0的时候,更新以下缓存数据。假设票在一分钟之内卖掉,相当于只需要承受一分钟的查询请求。
当缓存替代数据库作为主要查询请求处理者的时候,缓存成为整个系统的瓶颈。
2 减少锁的粒度当旅客选择一张票的时候,我需要锁定一条记录,避免同时更新,造成重复出票(这里说以下,我记得大学的时候,我从武汉买回家的票,铁道部一个座位卖出三张表,而且是大面积情况,相当于一个车厢人数比平时多了三倍,当初我以为是假票,现在看来,可能是重复出票了)。还是拿Z27距离,假设我要买20120931日期票,我必须要选择一个座位,那么设计的时候,就可以 按照日期,车次,席位类型 三者确定一条记录,然后锁定它。而不是值根据车次 + 日期,这样在你买坐票的时候,买卧铺的旅客就不会受到影响。(PS:实际铁道部售票会远远这个模型简单,因为涉及到始发站,停靠站,终点到,假设一个车次停靠 S1->S2-S3,那么旅客买S1->S2 和 旅客买S2->S3 就不会收到影响,我们先简化模型,这里只是先提出设计的思想)
3 减少订票处理事务时间在整个订票业务流程中,发邮件,发短信,计算各个站点的余票信息等比较等耗时业务操作,完全异步化处理。只需要找出关键的流程,如果需要保持一个事务,那么通过异步确保的方式进行。这个是技术层面的东西,后面在介绍。
存在的问题
通过分析,我们给出了一个最简单的订票数据库这一层的解决方案,再仔细分析其中存在的问题
1 余票查询的维度并不是 车次 + 日期 + 席位类型,应该还有始发站-->终点站因素,必须有一个非常快的算法,判断是否有票,然后告知应用。
2 缓存是系统中的单点,一旦缓存故障,数据库估计承受不了
3 数据库上次我说的只需要分成一个库(因为上一章节建立数据库备份机制,故这里面不存在单点),这里面可能存在性能,这里需要进行压力测试,模拟测试。看看容量上线。为了继续进行设计,我们假设即使在缓存存在的情况,数据库没有办法处理当前的数据,主要是为了应付春运。
这里先解决余票库分库的问题,分库考虑的原则在上一篇文章分析过,但是由于这个库的数据量不大,只是访问会比较频繁,我们竟可能减少用户的访问为主要考虑因素,铁路购票有其特殊的因素,比如春节的时候从上海买去成都的票非常紧张,查询量也是最大,但是相反,这段期间买成都去上海的票的人就会比较少,查询量比较少。而春节过后上班也就相反。这个思路也就是说按照站站来分,也可以按照铁路局卖的票来分。我们的思路就是尽量各个库的访问量均匀。不过也存在一个问题,就是分库的扩展性比较差,一旦扩容,就要做改动。
在谈缓存的问题,一台缓存服务器不够,可以部署缓存集群。至于是不是一台缓存服务器存放所有的数据,还是要看数据的多少,尽可能的所有数据都缓存在一台服务器上面。缓存的数据维度为 预售期、车次 、席位、始发站、终点站 、是否有票 ,按照道理,应该可以缓存所有的数据,不过这个也要看缓存的实现支持最大的内存数量。比如java实现的缓存 在32位机器上面 只能支持差不多2G的缓存空间。这里面假设一台缓存服务器能够实现所有预售期车票数据的缓存,那么这里面只需要的就是在余票数据更新的时候更新所有集群的缓存数据。

上面一幅图只是简单的演示了基本的架构模型。
而余票的计算则是里面最为复杂的了,因为新增了两个维度,就是始发站->到达站。这个问题比较复杂,先暂时放到下一篇文章区分析。
继续分析,发现上面的分析中,貌似还少了一个比较重要的因素,那就是渠道因素,我们知道,订票有窗口渠道,代理售票口,网站,电话等等。假如每个渠道售出的票都是公平的,那么肯定不合乎道理的,那互联网可能就是比较占优势的(如果系统设计的足够好的话),对于辛苦排队的人来说,相当不公平。这里面有两种解决方案
1 可以设计为每个渠道进行配额,比如网络订票 ,我给总票数的多少,每个代理点,我给的票数是多少等等。如果把这些因素在加入到余票信息中,会变的非常复杂,也不好扩展,毕竟这个是属于经常变化的。设计的一个原则分离不变和易变。如果不变的和易变柔和在一起,系统的扩展性就回很弱。
2 可以按照请求排队,按照渠道优先级进行分配,这样在大多数请求排队的情况下,有一些请求就回被饿死,也就是部分渠道根本买不到票,因为请求会被饿死。
如果要我选择两种方案的,我会选择第一种,因为可以在不同时刻进行放票,这样可以分散请求。来自互联网10点放票,窗口的8点放票,代理点9点。自然把流量就分开了。渠道配额管理这一块我觉得将会是最复杂的一个系统,涉及到利益太多。余票库这里面我想设计的简单一点,不想把复杂的渠道,配额管理引入进来,尽量放在外围系统中控制。
评论回复:
1 有一些用户说这样的系统用到锁就死定了,这个说法不太准确。首先,在核心票数处理的情况下,必须要保持数据一致性,处理票数减一的情况必须使用锁,所以考虑的是尽量减少锁的范围和锁超时的时间。因为一旦多出票了,会给旅客带来严重的问题,一个座位两张票。其次,在保证数据一致性的情况下要最大程度的保证用户体验和性能
2 使用NoSql其实有一定的适用范围。这个是看架构权衡的问题。我有限要保证的是数据一致性,然后才是性能。NoSql对数据的一致性要求并不太严格。可以作为缓存集群的替代品。由于我个人做金融系统的,对oracle比较偏爱,可能做互联网sns类产品的,对NoSql比较偏爱。但是两个问题领域不一样,要有取舍。
3 由于大部分请求都会在缓存层处理掉,不会直接进入进入请求到数据库,至于锁定数据库的情况,会更少。这个情况下,可以按照秒杀的实现方式。这一点可以专门放一篇来讲。
4 对于窗口售票部分,肯定考虑过了。如果网站做的好的,网站的请求量肯定是最大的。你可以想象一下售票点的终端系统,全国能够有多少W?网络客户端有多少W 几千万应该有了吧,几个终端的数量级。而且终端的话,只有一个人在串行操作,不会无聊到刷浏览器。而IE是个人的,刷死你。还有这个是关于数据库这一层的设计,还有到整体业务架构层的设计,无论售票窗口,互联网等渠道,最终都是要进入到数据库这一层。
5 分库分表要了解背后原因以及策略。
其实只需要12行代码 就可以搞定12306:
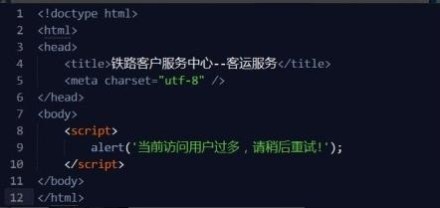
今天先写到这里,发现在这上面思考的比较多了,后面再持续分析吧。还要继续开发我的ios app,写文章有点超时了。
ps:发现无法在mac笔记本上添加图片,是不是一个bug,明天在上传吧。
作者:猫叔玩流量
14年互联网技术、产品、运营经验,前支付宝技术专家,互金创业公司CTO,大令保事业部总经理。
在互金领域有比较强的产品以及运营经验,尤其擅长用户增长、转化、运营上的经验,兼具技术、产品、运营思维。
目前是云猫增长实验室 创始人
云猫增长实验室是一家致力于帮助中小企业主、个人品牌提升流量运营能力的增长团队。
团队成员来自阿里等国内知名互联网公司,曾在互联网金融、互联网保险、企业级SaaS等项目中负责用户增长,团队管理的工作,拥有丰富的一线流量增长经验与实操手段。
欢迎关注我们,用技术驱动增长

B站专栏:云猫增长实验室
本人版权归作者和自由互联所有,欢迎转载,转载请注明出处