本帖先探讨 IT 人的职涯规划,再回到技术面,研究 T-SQL 的 UNION、EXISTS、EXCEPT、INTERSECT 运算符。
之前有园友提到:「DBA 了解业务是非常必要的」,确实如此。不管您担任的是 IT 的哪种职务,都应深入了解所任职公司的业务和流程,结合既有的 IT 专长,发展出自己在公司的「不可替代性」,甚至去思考老板、公司的好高高层们,想要的是什么? 若您是担任 MIS 或 DBA,每天辛勤努力修机器、备份数据库、维护网络状态、研究最新的前台和 .NET 技术,却无法让老板了解你每天在忙什么,则你的地位,可能远不如一位很懂业务和流程的人,虽然他只会写些 SQL 句子,却能每天产出老板和主管想看的报表,老板不能没有他,他也就创造了自己的不可替代性。 当然做项目的软件公司,和一般产业的信息部门又有所不同,这里只是举例。
那么该学什么技术最保值呢?有没有什么 IT 技术像会计学一样,学一套就能吃一辈子?前台 UI 技术日新月异、层出不穷,感觉自己再也跟不上年轻人熬夜学 ASP.NET 4,5,6,7,8 ...、Silverlight 5,6,7,8,9 ...? 若要论技术的保值性,将 SQL 和数据库学到精通,或许是不错的选择。除了技术变化性比较小 (至少不会像某些技术会忽然推翻旧版本),往上钻研可研究 BI、OLAP、Data Mining、报表、当顾问,往下钻研可深入学 SQL 语句、软件项目开发、备份还原和监控,横向钻研可学习操作系统、Storage、性能优化 .... 等等,至少就技术的「保值性」而言,学一套能「撑」较久,甚至大半辈子,也较有机会接触公司的核心业务和流程 (把公司的业务逻辑都写进存储过程里,公司从此不能没有你)。
当然这里只是举例,并非鼓吹大家都该往此方向投入学习,就像有人说程序员最后都要升级 SA、PM,但这应视个人性格、兴趣、所在的产业而论,并没有标准的答案。但话说回来,要精通 SQL 的撰写也非易事,其为易学难精的功夫,如笔者以前曾经转贴的一篇陈年好文「程序员真情忏悔录」也曾提到这些特性:
做应用软件的人真的没价值吗?有些靠应用软件赚了不少钱的朋友开始偷笑了。软件必须加上专业知识,才能够发挥价值;换句话说,如果您真的「只会写代码」,却没有配合各种领域的专业知识 ,「编程」这项技能本身根本毫无价值可言。
就很像你的计算机装了浏览器,但却没有对外联机的网络一样。如果没有网络本身,浏览器一点价值也没有,更不需要一家公司大费周章地利用平台优势去整倒另外一家公司 。
-你老觉得真正的高手应该精通各门各派的技术 (?),如果你会 XML,他不会,你就觉得你比他厉害。你觉得他的履历上写的技能太少,证照太少,所以你认为你比他优秀?
有人认为写 Java 程序应该善用工具,用 UltraEdit 根本是重新造轮子的行为,所以一开始就学 JBuilder (或 Visual Studio) 的使用者,其实他用 JBuilder 写了老半天 GUI 程序,哪天回头叫他用文本编辑器写个简单的 Frame + Button 他却写不出来,因为他从没弄懂过 Java 的事件处理模型。他只会不断地:选择组件 -> 放在容器里 -> 调整位置和大小 -> 调整属性 -> 按两下 -> 填写事件处理函数,成为一个名副其实的「代码女工」。
有人觉得他精通各家厂商的数据库,所以看不起那些只会下 SQL 命令或是只会写 stored procedure 的人,因为他可是精通 ODBC、JDBC、ADO、ADO.NET 各种程序的写法。问题是,一个精通 SQL 的专家,和只会写 SQL 语句的人,在数据库表格交互参考、数据量很大的时候,要从中取出我们需要的内容,所下的 SQL 指令在效率上,是几秒钟和几个小时的差别。
SQL 也是个专门学问,要能够巧妙地操作它,必须下非常多功夫做研究,而且一研究可能就是十几年。如果贵公司的项目老是苦于数据库访问的性能不佳,你猜老板会花钱找一个有能力彻底改善所有 SQL 语句中性能问题的稀有专家,还是再找一个号称他什么都会,结果一点用场也派不上的「数据库女工」? 我们常常看到某人列出他的履历,好像会很多就是很厉害。但是当我们完全深入一项技术时 (喔,我是说你真正下过苦功的时候),通常我们会越来越感觉到自己的渺小。
说偏了,回归技术面,以下才是本帖的主题。
-------------------------------------------------
本帖的示例下载:
https://files.cnblogs.com/WizardWu/111001.zip
SQL Server 2008 R2 的 AdventureWorks 数据库下载:
http://msftdbprodsamples.codeplex.com/releases/view/55926
http://msftdbprodsamples.codeplex.com/
---------------------------------------------------
The EXISTS Operator
EXISTS 可称之为运算符,有些书称它为关键词。 EXISTS 和 IN 关键词很类似,但仍有些不同,EXISTS 使用时不会返回数据,而是返回简单的 TRUE / FALSE。如下示例 [1],即使子查询返回 NULL,用 EXISTS 也会得到 TRUE:
USE AdventureWorks2008 ;
GO
SELECT DepartmentID, Name
FROM HumanResources.Department
WHERE EXISTS (SELECT NULL)
EXISTS 和 IN 在很多情况下可查到相同的结果 [1],两个关键词的用途有些类似,因此网络上常有些 EXISTS 和 IN 谁效率较好的讨论串 [2],此处不再赘述。 以下我们改探讨 EXISTS 和 JOIN 的比较,下方是书上的两个示例 [7],两者的执行结果相同,第一个示例是 EXISTS 搭配「嵌套查询 (nested query)」,第二个示例语法看起来较简洁,是传统大家习惯用的 join 写法:
SELECT e.BusinessEntityID, FirstName, LastName
FROM HumanResources.Employee e
JOIN Person.Person pp
ON e.BusinessEntityID = pp.BusinessEntityID
WHERE EXISTS
(SELECT BusinessEntityID
FROM HumanResources.JobCandidate jc
WHERE e.BusinessEntityID = jc.BusinessEntityID);
SELECT e.BusinessEntityID, FirstName, LastName
FROM HumanResources.Employee e
JOIN Person.Person pp
ON e.BusinessEntityID = pp.BusinessEntityID
JOIN HumanResources.JobCandidate jc
ON e.BusinessEntityID = jc.BusinessEntityID;
两个示例虽然结果相同,但 EXISTS 的性能会较好 (书上说的) [7]。 当我们使用 EXISTS 关键词时,SQL Server 不会用 full row-by-row join,而是在记录当中搜寻,当它找到第一个符合条件的记录时,就会立即停止后续搜寻的动作,并标示为 TRUE,表示不需要再往下找了;反观 inner join 则不会有此种标示的动作。
此外,NOT EXISTS 也有此种标示的功能。当 NOT EXISTS 找到符合条件的数据时,同样也会标示,但标示为 FALSE,表示不需要再往下找了。
除了此一性能差别外,EXISTS 和 join-based 在查询时,各方面并无二致。
Using EXISTS in Other Ways
有时您会看到有些人执行 CREATE 前,会加一些古怪的语句,如下:
IF EXISTS (SELECT * FROM sysobjects WHERE id =
object_id(N'[Sales].[SalesOrderHeader]') AND OBJECTPROPERTY(id,N'IsUserTable') = 1)
DROP TABLE [Sales].[SalesOrderHeader]
GO
CREATE TABLE [Sales].[SalesOrderHeader] (
...
...
他们使用 sys.objects、sys.databases,或 INFORMATION_SCHEMA 检视 (view),目的都一样,想在执行 CREATE 前先看看某个对象是否已存在。 但同样是用 EXISTS 做事先的判断,我有更好的写法,请参考以下创建数据库的示例:
USE master
GO
IF NOT EXISTS (SELECT 'True' FROM sys.databases WHERE name = 'DBCreateTest')
BEGIN
CREATE DATABASE DBCreateTest
END
ELSE
BEGIN
PRINT '此数据库已经存在。跳过了 CREATE DATABASE 语句'
END
GO
第一次执行此语句时,若没有 DBCreateTest 数据库,则创建它;第二次执行时,由于该数据库已存在,因此会印出自定义的提示信息。 因此,仅用一点小技巧,可避免掉不必要的 DROP 动作被执行,这会让您公司的产品在被安装时更有效率。
EXISTS 是很方便的关键词,有时可让查询语句执行得更有效率,有时则可简化 SQL 语句。
The INTERSECT and EXCEPT Operators
接下来介绍的 INTERSECT 和 EXCEPT 关键词,在 SQL Server 和其他厂牌数据库多半都支持。 INTERSECT 和 EXCEPT 在处理两个 result set 时,和 UNION 关键词很类似。 在 MSDN、TechNet 上虽然有对这两个关键词作解释 [3], [6],但半机器的翻译有些不易理解,建议参考下列取自书上的图文示例 [7],可让人一目了然:
- UNION: 将多个「结果集 (result set)」的「行 (row)」合并,作为单个结果集返回,并移除重复的行。若有重复的行,只留下一个。
- UNION ALL: 将多个「结果集 (result set)」所有的行合并,不论是否有重复的行。
- EXCEPT: 提取只在 EXCEPT 左侧存在,但右侧不存在的行,参考下图 1。用更口语化的说法:「只给我 A 里才有,但 B 里没有的行」。
- INTERSECT: 只提取两个结果集里,都存在的行。 INTERSECT 很类似 inner join,但 INTERSECT 并不会对特定的「列 (column)」去做处理。
由于上述关键词,不会对特定的「列」去做处理,因此在使用上必须符合某些原则 [3],例如:所有查询中的列数和列的顺序必须相同、数据类型必须兼容。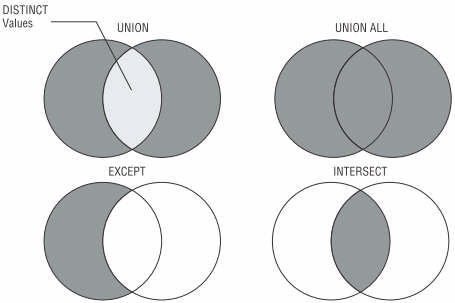
图 1 UNION 中若有重复的行,会被移除,只留下一个
在看本文最后的完整比较示例前,我们先了解 EXCEPT 和 INTERSECT 的基本语法。
EXCEPT
EXCEPT 用法如下,简单易懂:
<table or tabular result>
EXCEPT
<table or tabular result with same number of columns and type as top query>
同样的查询需求,我们改用 NOT EXISTS 的写法,也能得到和 EXCEPT 写法相同的结果,用法如下 [1], [7]。 本文最后会有完整的示例。
WHERE NOT EXISTS
(SELECT 1
FROM <table or result with same number of columns and type as top query>
WHERE <base query first column> = <comparison table first column> [, ...])
INTERSECT
至于 INTERSECT 的语法也一样简单易懂,用法和 EXCEPT、UNION 也都类似,如下:
<table or tabular result>
INTERSECT
<table or tabular result with same number of columns and type as top query>
同样的查询需求,我们改用 EXISTS 的写法,也能得到和 INTERSECT 写法相同的结果,用法如下 [1], [7]。 本文最后会有完整的示例。
<base query>
WHERE EXISTS
(SELECT 1
FROM <table or result with same number of columns and type as top query>
WHERE <base query first column> = <comparison table first column> [, ...])
此外,INTERSECT 和 EXCEPT 可同时混搭使用,但 INTERSECT 运算符会优先于 EXCEPT [6]:
SELECT * FROM TableAEXCEPT
SELECT * FROM TableB
INTERSECT
SELECT * FROM TableC
以下的示例,我们将演示本帖前述的所有内容,先看 EXCEPT、INTERSECT 的示例,再看与他们俩对等的 NOT EXISTS、EXISTS 写法示例 (不同写法,但会返回相同的结果集)。
 完整示例
1 -- Create our test tables and populate them with a few relevant rows
完整示例
1 -- Create our test tables and populate them with a few relevant rows
2 CREATE TABLE UnionTest1
3 (
4 idcol int IDENTITY,
5 col2 char(3),
6 );
7
8 CREATE TABLE UnionTest2
9 (
10 idcol int IDENTITY,
11 col4 char(3),
12 );
13
14 INSERT INTO UnionTest1 VALUES ('AAA'),('BBB'),('CCC');
15 INSERT INTO UnionTest2 VALUES ('CCC'),('DDD'),('EEE');
16
17
18 PRINT '测试 1, Source and content of both tables:';
19
20 SELECT 1 AS SourceTable, col2 AS Value FROM UnionTest1
21 UNION ALL
22 SELECT 2, col4 FROM UnionTest2;
23
24
25 PRINT '测试 2, Results with classic UNION';
26
27 SELECT col2 FROM UnionTest1
28 UNION
29 SELECT col4 FROM UnionTest2;
30
31
32 PRINT '测试 3-1, Results with EXCEPT';
33
34 SELECT col2 FROM UnionTest1
35 EXCEPT
36 SELECT col4 FROM UnionTest2;
37
38
39 PRINT '测试 3-2, Equivilent of EXCEPT but using NOT EXISTS';
40
41 SELECT col2 FROM UnionTest1 ut1
42 WHERE NOT EXISTS
43 (SELECT col4 FROM UnionTest2 WHERE col4 = ut1.col2);
44
45
46 PRINT '测试 4-1, Results with INTERSECT';
47
48 SELECT col2 FROM UnionTest1
49 INTERSECT
50 SELECT col4 FROM UnionTest2;
51
52
53 PRINT '测试 4-2, Equivilent of INTERSECT but using EXISTS';
54
55 SELECT col2 FROM UnionTest1 ut1
56 WHERE EXISTS
57 (SELECT col4 FROM UnionTest2 WHERE col4 = ut1.col2);
58
59
60 PRINT '测试 5, INTERSECT 运算符优先于 EXCEPT';
61 SELECT col2 FROM UnionTest1
62 EXCEPT
63 SELECT col2 FROM UnionTest1
64 INTERSECT
65 SELECT col4 FROM UnionTest2;
66
67
68 -- Clean up after ourselves
69 DROP TABLE UnionTest1;
70 DROP TABLE UnionTest2;
如您所见,测试 3-1、3-2 的结果相同,测试 4-1、4-2 的结果也相同,但 SQL Server 的「评估的执行计划」很不同,且 EXCEPT / INTERSECT 的「查询开销」会比 NOT EXISTS / EXISTS 大很多,如同上例中,测试 3-1 比 3-2 的性能差,测试 4-1 比 4-2 性能差。而且经我测试 (书籍作者 [7]),大多数的情形,用 EXISTS 的写法,性能都比 EXCEPT / INTERSECT 要好。
虽然如此,但我们不该完全舍弃 EXCEPT / INTERSECT 的使用,因为他们的语法简洁、容易阅读。因此在您的 SQL 语句中,除非两种写法的性能差距很大,不然我仍建议使用 EXCEPT / INTERSECT 写法,以便项目后续的维护。若论 EXISTS 和 EXCEPT / INTERSECT 哪一种写法较好,则属见仁见智的问题,端视您的数据量、执行环境、实测两种写法的效率差距,来决定要用哪一种写法。
参考文档:
[1] EXISTS (Transact-SQL)
http://msdn.microsoft.com/zh-cn/library/ms188336.aspx
[2] SQL 中 IN 和 EXISTS 用法的区别?
http://topic.csdn.net/u/20090715/10/ec21e6cc-7265-4c44-a35c-8a0003e73978.html
[3] EXCEPT 和 INTERSECT (Transact-SQL)
http://msdn.microsoft.com/zh-cn/library/ms188055.aspx
[4] UNION (Transact-SQL)
http://msdn.microsoft.com/zh-cn/library/ms180026.aspx
[5] 与其他 Transact-SQL 语句一起使用 UNION、EXCEPT 和 INTERSECT
http://msdn.microsoft.com/zh-cn/library/ms191523.aspx
[6] 使用 EXCEPT 和 INTERSECT 执行半联接操作
http://msdn.microsoft.com/zh-cn/library/ms191255.aspx
参考书籍:
[7] Professional Microsoft SQL Server 2008 Programming, Chapter 3
http://www.wrox.com/WileyCDA/WroxTitle/Professional-Microsoft-SQL-Server-2008-Programming.productCd-0470257024.html
http://www.ppurl.com/pdfpreview/?skey=AQQHNgokAXRXMVA7UAxQP1Z0XTkJYwBtB2ZUZQI6UzQ%3D&page=0
相关文章:
[8] 探讨 .NET 4 新增的 SortedSet 类 (.NET 平台的 EXCEPT、INTERSECT)
http://www.cnblogs.com/WizardWu/archive/2010/06/17/1759297.html