微软于2010年12月21日发布了分布式并行计算基础平台——Dryad测试版,成为谷歌MapReduce分布式数据计算平台的竞争对手。它可以使开发人员能够在Windows或者.Net平台上编写大规模的并行应用程序模型,并能够在单机上所编写的程序很轻易的运行在分布式并行计算平台上,程序员可以利用数据中心的服务器集群对数据进行并行处理,当程序开发人员在操作数千台机器时,而无需关心分布式并行处理系统方面的细节。本文将重点讲述微软最新Dryad平台方面的功能原理以及应用。
Dryad平台也是构建微软云计算基础设施重要核心技术之一。要使云计算真正的“落地”主要面临两个重要问题:如何构建与应用程序来紧密结合的大规模底层基础设施?目前构建分布式平台的基础设施主要包括Dryad、Dynamo和MapReduce等框架。
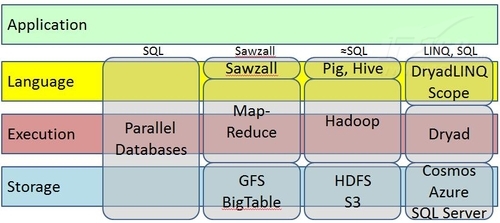
图1 数据并行计算
另一个问题就是如何通过构建新型的云计算应用程序,能够在网络上提供更加丰富的用户体验?Yahoo扩展了MapReduce并提出了MapReduceMerge框架,并可以应用到多核处理器上。HP则将注意力关注于分布式共享内存的使用上,而不同于MapReduce编程方面。IBM主要使用Linux系统映像以及Hadoop软件(Google File System以及MapReduce的开源实现)。微软则自主研发了Dryad和DryadLINQ,并可以用于辅助C#开发人员在计算机集群或数据中心里分布式并行处理大规模的数据,从而在程序执行性能与效率上提高数倍。
Dryad概述Dryad和DryadLINQ是微软硅谷研究院创建的研究项目,主要用来提供一个分布式并行计算平台,DryadLINQ提供一种高级语言接口,使普通程序员可以轻易进行大规模的分布式计算,它结合了微软Dryad和LINQ两种关键技术,被用于在该平台上构建应用。Dryad与微软体系结构中的位置关系,如图2所示。
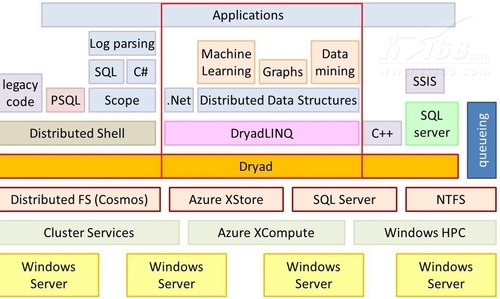
图2 Dryad与微软体系结构的关系
Dryad同MapReduce一样,它不仅仅是一种编程模型,同时也是一种高效的任务调度模型。Dryad这种编程模型并不仅适用于云计算,在多核和多处理器以及异构机群上同样有良好的性能。
我们知道在Visual Studio 2010 C++有一套并行计算编程框架,支持常用的协同任务调度和硬件资源(例如CPU和内存等)管理,通过Work stealing算法可以充分利用细颗粒度并行的优势,来保证空闲的线程依照一定的策略建模,从所有线程队列中“偷取”任务执行,所以能够让任务和数据粒度并行。如果一个耗时的任务只被粗略分割成四个子任务并发执行,即使是在四核心CPU的计算机上运行也无法做到实时动态的负载均衡,可能发生三个子任务很早就完成了,而另一个任务还在一个核上是等待状态。
Dryad与上述并行框架相似,同样可以对计算机和它们的CPU进行调度,不同的是Dryad被设计为伸缩于各种规模的集群计算平台,无论是单台多核计算机还是到由多台计算机组成的集群,甚至拥有数千台计算机的数据中心,可以从任务队列中创建的策略建模来实现分布式并行计算的编程框架。
Dryad系统架构(Dryad architecture)Dryad系统的总体的构建用来支持有向无环图(Directed Acycline Graph,DAG)类型数据流的并行程序。Dryad的整体框架根据程序的要求完成调度工作,自动完成任务在各个节点上的运行。在Dryad平台上,每个Dryad工作或并行计算过程被表示为一个有向无环图。图中的每个节点表示一个要执行的程序,节点之间的边表示数据通道中数据的传输方式,其可能是文件、TCP Pipe、共享内存等,为了支持数据类型需要针对每个类型有序列化代码。
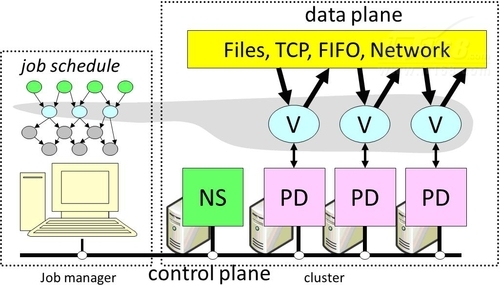
图3 Dryad系统结构
如图3所示,当用户使用Dryad平台时,首先是需要在任务管理(JM)节点上建立自己的任务。每一个任务由一些处理过程以及在这些处理过程数据传递组成。任务管理器(JM)获取无环图之后,便会在程序的输入通道准备,当有可用机器的时候便对它进行调度。JM从命名服务器(NS)那里获得一个可用的计算机列表,并通过一个维护进程(PD)来调度这个程序。
系统组件:
- 任务管理器(Job Manager,JM):每个Job的执行被一个Job Manager控制,该组件负责实例化这个Job的工作图;在计算机群上调度节点的执行;监控各个节点的执行情况并收集一些信息;通过重新执行来提供容错;根据用户配置的策略动态地调整工作图;
- 计算机群(Cluster):用于执行工作图中的节点;
- 命名服务器(Name Server,NS):负责维护Cluster中各个机器的信息;
- 维护进程(PDaemon,PD):进程监管与调度工作。
从总体来看,传统的Linux/Unix管道是一维管道,每个节点在管道中是单个的程序。而Dryad的执行过程就可以看做是一个二维的管道流的处理过程。其中,每个节点可以具有多个程序的执行,通过这种算法可以同时处理大规模数据。
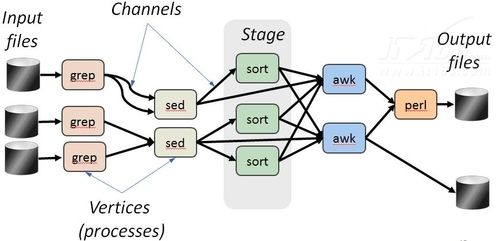
图4 Dryad任务结构
如图4所示,我们可以看到,在每个节点进程(Vertices Processes)上都有一个处理程序在运行,并且通过数据管道(Channels)的方式在它们之间传送数据。二维的Dryad管道模型定义了一系列的操作,可以用来动态的建立并且改变这个有向无环图。这些操作包括建立新的节点,在节点之间加入边,合并两个图以及对任务的输入和输出进行处理等。
与微软Dryad相似,MapReduce编程模型可用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(化简)”,它们的主要思想都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。MapReduce映射处理结构,如图5所示。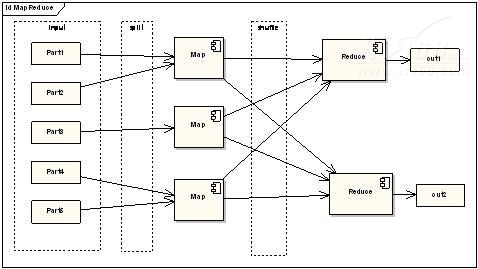
▲图5 MapReduce映射处理结构
从上图可以看出,MapReduce极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。当前的软件实现是指定一个 Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。微软Dryad与谷歌的MapReduc映射原理相似,但不同的是通过DryadLINQ来实现分布式程序编程设计。
Dryad模型算法应用(Computational model)DryadLINQ可以根据程序员给出的LINQ查询生成可以在Dryad引擎上执行的分布式策略算法建模(运算规则),并负责任务的自动并行处理及数据传递时所需要的序列化等操作。此外,它还提供了一系列易于使用的高级特性,如强类型数据,Visual Studio集成调试,以及丰富的任务优化策略(规则)算法等等。这种模型策略开发框架也比较适合采用领域驱动开发设计(DDD)来构建“云”平台应用,并能够较容易的做到自动化分布式计算。
- 并行算法分治策略。
Y=(A+B(C+DEF))+G,串行计算需要6步。利用结合律和交换律,该式变为Y1=Y2+(分裂为两个问题),其中Y1=A+G,Y2=B (C+DEF),在两台处理机的系统上只需5步并行计算。在用分配率,Y=(A+B(C+DEF))+G可变为Y=Y3+Y4,其中Y3=A+G+BC,Y4=BDEF,在两台处理机的系统上并行计算只需4步。如四台处理机的系统,并行计算可进一步减少为3步。两台处理机下的运算分解树和四台处理机下的运算分解树,如图6所示。
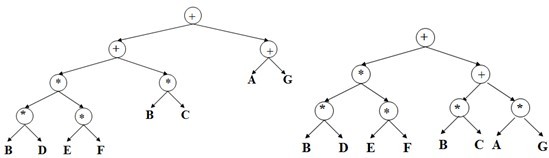
图6 DGA运算分解树
从上面分析我们可以看到,通过并行算法策略建模,可以有效的控制数据的颗粒度,当程序运行在Dryad分布式并行平台时候,可最大化的提高分布式并行运算效率。
- 分布式并行策略
我们经常会遇到所开发的网站/系统,无法承载大规模用户并发访问的问题。解决该问题的传统方法是使用数据库,通过数据库所提供的访问操作接口来保证处理复杂的查询能力。当访问量增大,单数据库处理不过来时便增加数据库服务器。如果增加了3台服务器,再把用户分成了三类(关注:策略建模、颗粒度和映射):A(学生),B(老师),C(程序员)。每次访问的时候,Dryad会先查看用户属于哪一类,然后直接访问存储那类用户数据的数据库,可能处理能力增加了三倍。这时我们已经实现了一个分布式的存储引擎过程,而Dryad与Dynamo具有相似的功能。
我们可以通过Dryad分布式平台来解决云存储扩容困难问题。如果这3台服务器也承载不了更大的数据要求时,需要增加到5台服务器,那必须更改分类方法把用户分成5类,然后重新迁移已经存在的数据,这时候就需要非常大的迁移工作,这种方法显然不可取。另外,当群集服务器进行分布式计算运行的时候,每个资源节点处理能力可能有所不同(例如不同硬件配置的服务器等等),如果只是简单的把机器直接分布上去,性能高的机器得不到充分利用,性能低的机器处理不过来。
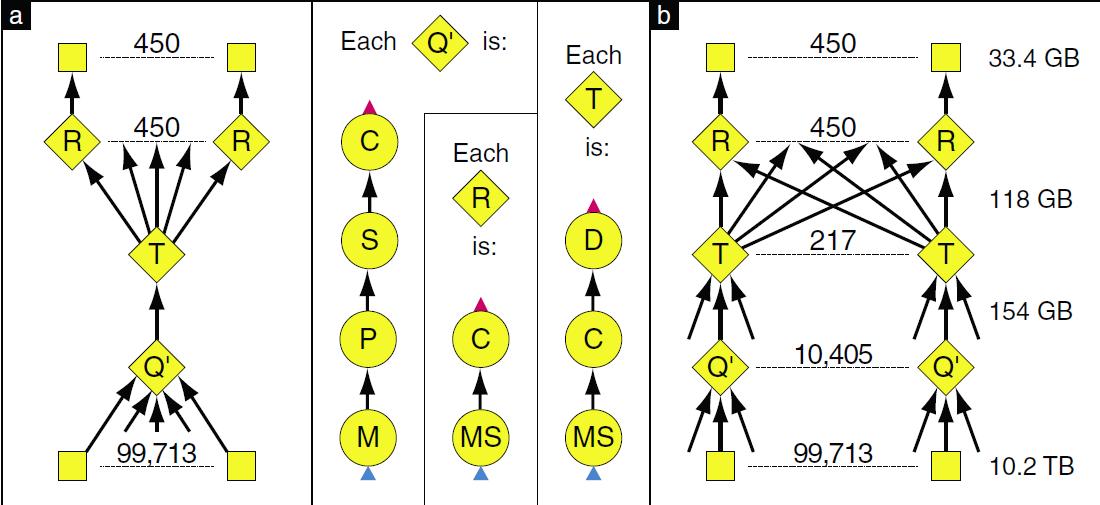
图7 通过Dryad DAG排列的节点(程序)扩展性能
- P parses lines(解析线)
- D hash distribute(哈希分布)
- S quicksort(快速排序)
- C count occurrences(事件计算)
- MS merge sort(合并分类)
- M non-deterministic merge(未确定合并)
Dryad解决此问题的方法是采用虚节点。把上面的A B C三类等用户都想象成一个逻辑上的节点。一台真实的物理节点可能会包含一个或者几个虚节点(逻辑节点),看机器的性能而定。我们可以把那任务程序分成Q等份(每一个等份就是一个虚节点),这个Q要远大于我们的资源数。现在假设我们有S个资源,那么每个资源就承担Q/S个等份。 当一个资源节点离开系统的时候,它所负责的等份要重新均分到其他资源节点上,一个新节点加入的时候,要从其他的节点“偷取”到一定数额的等份。
在这个策略建模算法下,当一个节点离开系统的时候,虽然需要影响到很多节点,但是迁移的数据总量只是离开那个节点的数据量。同样,一个新节点的加入,迁移的数据总量也只是一个新节点的数据量。之所以有这个效果是因为Q的存在,使得增加和减少机器的时候不需要对已有的数据做重新哈希(D)。这个策略的要求是Q>>S(存储备份上,假设每个数据存储N个备份则要满足Q>>S*N)。如果业务快速发展,使得不断的增加主机,从而导致Q不再满足Q>>S,那么这个策略将重新变化。
通过上述的论述,我们可以看到Dryad通过一个有向无环图的策略建模算法,提供给用户一个比较清晰的编程框架。在这个编程框架下,用户需要将自己的应用程序表达为有向无环图的形式,节点程序则编写为串行程序的形式,而后用Dryad方法将程序组织起来。用户不需要考虑分布式系统中关于节点的选择,节点与通信的出错处理手段都简单明确,内建在Dryad框架内部,满足了分布式程序的可扩展性、可靠性和性能的要求。
使用DryadLINQ通过使用DryadLINQ编程,使普通的程序员编写大型数据并行程序能够轻易的运行在大型计算机集群里。DryadLINQ开发的程序是一组顺序的LINQ代码,它们可以针对数据集做任何无副作用的操作,编译器会自动将其中数据并行的部分翻译成并行执行的计划,并交由底层的Dryad平台完成计算,从而生成每个节点要执行的代码和静态数据,并为所需要传输的数据类型生成序列化代码。
DryadLINQ使用和LINQ相同的编程模型,并扩展了少量操作符和数据类型以适用于数据并行的分布式计算。并从两方面扩展了以前的计算模型(SQL、MapReduce、Dryad等):它是基于.NET强类型对象的、表达力更强的数据模型和支持通用的命令式和声明式编程(混合编程),从而延续了LINQ代码即数据(treat code as data)的特性。
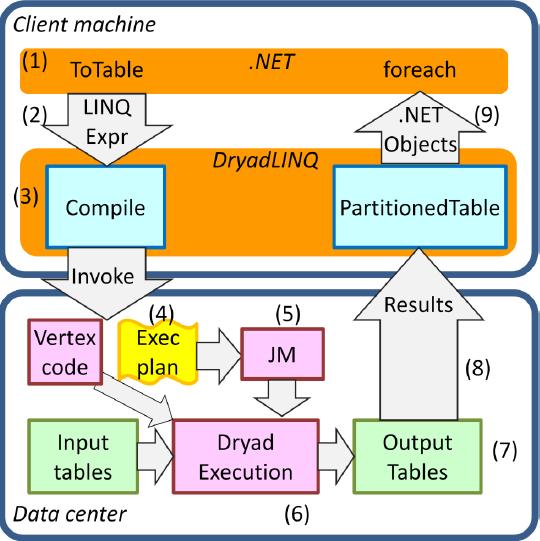
图8 DryadLINQ系统架构
如图8所示,LINQ本身是.NET引入的一组编程结构,它用于像操作数据库中的表一样来操作内存中的数据集合。DryadLINQ提供的是一种通用的开发/运行支持,而不包含任何与实际业务、算法相关的逻辑,Dryad和DryadLINQ都提供有API。DryadLINQ使用动态的代码生成器,将DryadLINQ表达式编译成.NET字节码。这些编译后的字节码会根据调度执行的需要,被传输到执行它的机器上去。字节码中包含两类代码:完成某个子表达式计算的代码和完成输入输出序列化的代码。
DryadLINQ表达式代码示例片段如下:
Collection<T> collection;
bool IsLegal(Key k);
string Hash(Key);
var results = from c in collection
where IsLegal(c.key)
select new { Hash(c.key), c.value};
这种表达式并不会被立刻计算,而是等到需要其结果的时候才进行计算。DryadLINQ设计的核心是在分布式执行层采用了一种完全函数式的、声明式的表述,用于表达数据并行计算中的计算。这种设计使得我们可以对计算进行复杂的重写和优化,类似于传统的并行数据库。从而解决了传统分布式数据库SQL语句功能受限与类型系统受限问题,以及MapReduce模型中的计算模型受限和没有系统级的自动优化等问题。
另外,在MapReduce编程方式下,应用程序编写人员需要关注与自己的应用逻辑如何使用Map函数以及Reduce函数进行表达。在Dryad编程模式中,应用程序的大规模数据处理被分解为多个步骤,并构成有向无环图形式的任务组织,由执行引擎去执行。这两种模式都提供了简单明了的编程方式,使得应用程序开发人员能够很好的驾驭云计算处理平台,对大规模数据进行处理。Dryad的编程方式可适应的应用也更加广泛,通过DryadLinq所提供的高级语言接口,使应用程序员可以快速进行大规模的分布式计算应用程序的编写。
Dryad技术的应用虚拟化(Virtualization)是云计算的基石。也就是说企业实现私有云的第一步就是服务器基础架构进行虚拟化。基础设施虚拟化之后,接下来就是要将现有应用迁移到虚拟环境中。云计算最重要的概念之一就是可伸缩性,实现它的关键则是虚拟化、虚拟化就是在一台共享计算机上聚集多个操作系统和应用程序,以便更好地利用服务器。当一个服务器负载超荷时,可以将其中一个操作系统的一个实例(以及它的应用程序)迁移到一个新的、不相对闲置的服务器上。
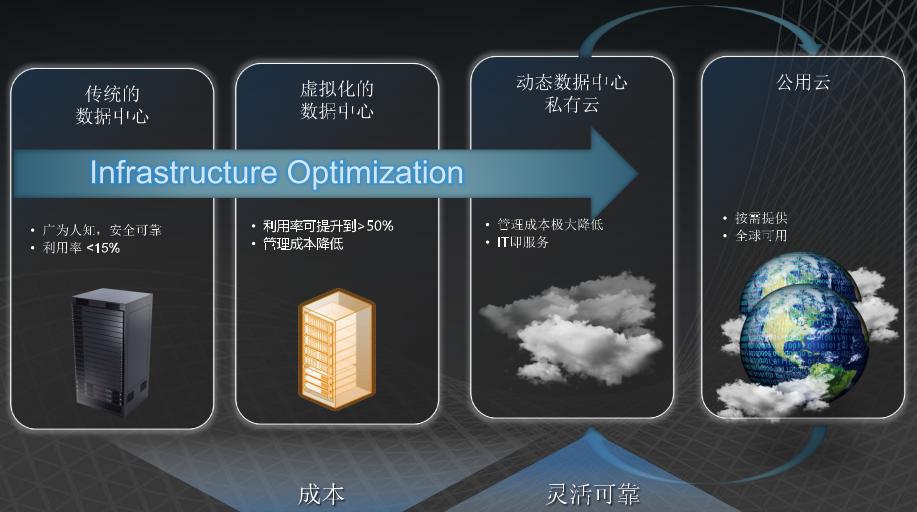
图9 实现云计算步骤
Dryad结合Hyper-V(Windows Server 2008的一个关键组成部分)虚拟化技术,可以实现TB级别的数据的在线迁移。中小型企业也可以针对企业内部小型群集服务器进行分布式应用系统编程,以及制定私有云开发与应用解决方案等设计。Windows Azure是微软公有云最佳解决方案,但是目前由于各种原因为时过早。使用现有Windows第三方产品实现私有云,花费成本却很大。然而Dryad技术却给我们带来了不错的折中的选择,当我们基于Windows Server平台运行应用系统或者网站时,便可以基于Dryad分布式架构来开发与设计实现。当公有云时机成熟和各种条件完备时,系统很轻易的升级到公有云,企业而无需花费太多成本。
写在最后通过以上介绍,我们已经了解到Dryad是实现构建微软云计算基础设施重要核心技术之一。云计算可以看成是网络计算与虚拟化技术的结合。利用网络的分布式计算能力将各种IT资源筑成一个资源池,然后结合成熟的存储虚拟化和服务虚拟化技术,让用户实时透明地监控和调配资源。
我们也体会到Dryad的诸多优点,如DryadLINQ具有声明式编程并将操作的对象封装为.NET类方便数据操作、自动并行化、Visual Studio IDE和.Net类库集成、自动序列化和任务图的优化(静态和动态(主要通过Dryad API实现))、对Join进行了优化,得到了比BigTable+MapReduee更快的Join速率和更易用的数据操作方式等。不过,Dryad和DryadLINQ也同样具有局限性。它更适用于批处理任务,而不适用于需要快速响应的任务;这个数据模型更适用于处理流式访问,而不是随机访问。虽然目前Dryad还是测试阶段尚未大规模普及,但是微软已经在AdCenter的生产系统中使用Dryad。
与 MapReduce不同的是DryadLINQ使用的是.NET的LINQ查询语言模型,并且Dryad是针对运行Windows HPC Server的计算机集群设计,而非兼顾Linux,而目前Apache的Hadoop环境只支持Linux。目前而言,高性能计算市场被Linux所占领,但是笔者相信Dryad平台在将来一定具有很广泛的发展前景,尤其对.NET开发人员来说也是一次很重要的技术革新机遇。
为程序员杂志(2011.2月刊)、It168辑文:
http://tech.it168.com/a2011/0318/1167/000001167839.shtml
http://tech.it168.com/a2011/0314/1165/000001165776.shtml
http://tech.it168.com/a2011/0325/1170/000001170601_all.shtml
http://tech.it168.com/a2011/0327/1170/000001170853_all.shtml
———————————————————————
任何美好的事物只有触动了人们的心灵才变的美好;
孤独的时候看看天空里的雨,其实流泪的不只是你。
人生只有走出来的美丽,没有等出来的辉煌!
———————————————————————
![]()