- 一、数据源
- 二、数据读取
- 三、数据概览
- 四、数据清洗
- 五、可视化分析
- 5.1 相关性分析(Correlation)
- 5.2 饼图(Pie)
- 5.3 箱形图(Boxplot)
- 5.4 词云图(wordcloud)
- 六、同步讲解视频
之前,我分享过一期爬虫,用python爬取Top100排行榜:
最终数据结果,是这样的:
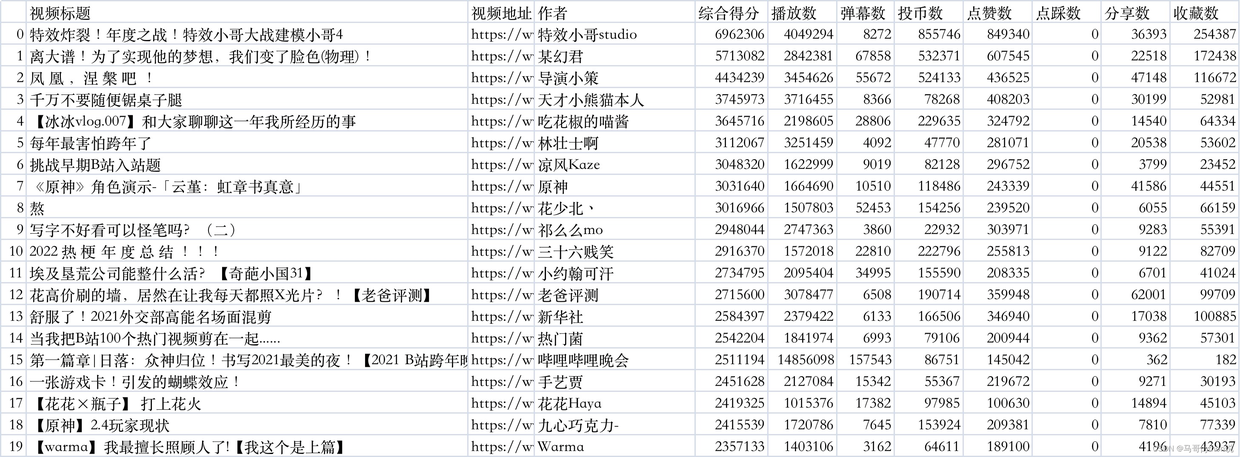
在此数据基础上,做python可视化分析。
二、数据读取首先,读取数据源:
# 读取csv数据
df = pd.read_csv(csv)
用shape查看数据形状:
# 查看数据形状
df.shape
用head查看前n行:
# 查看前5行
df.head(5)
用info查看列信息:
# 查看列信息
df.info()
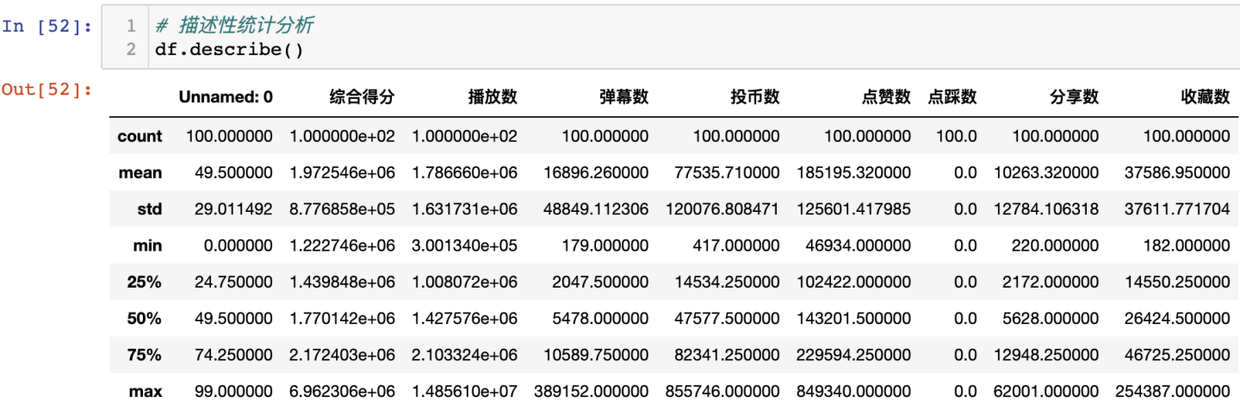
用describe查看统计性分析:
# 描述性统计分析
df.describe()
查看是否存在空值:
# 查看空值
df.isna().any()
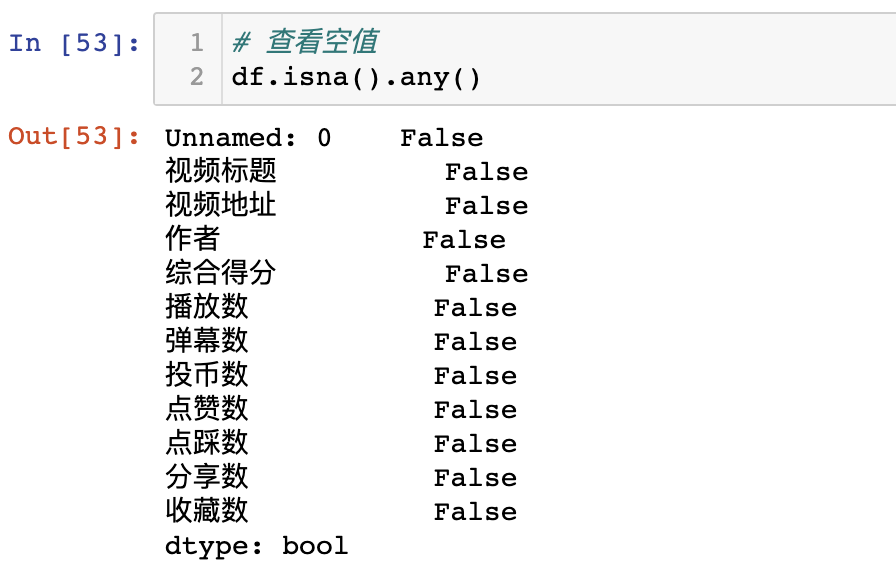
每列都是False,没有空值。
查看是否存在重复值:
#查看重复值
df.duplicated().any()

False代表没有重复值。
上面我们看到,点踩数都是0,没有分析意义,所以,用drop删除此列:
# 删除没用的列
df.drop('点踩数', axis=1, inplace=True)
删除之后,查看删除结果:

没有点踩数了。
数据中,有播放数、弹幕数、投币数、点赞数、分享数、收藏数等众多数据指标。
我想分析出,这些指标中,谁和综合得分的关系最大,决定性最高。
直接采用pandas自带的corr函数,得出相关性(spearman相关)矩阵:
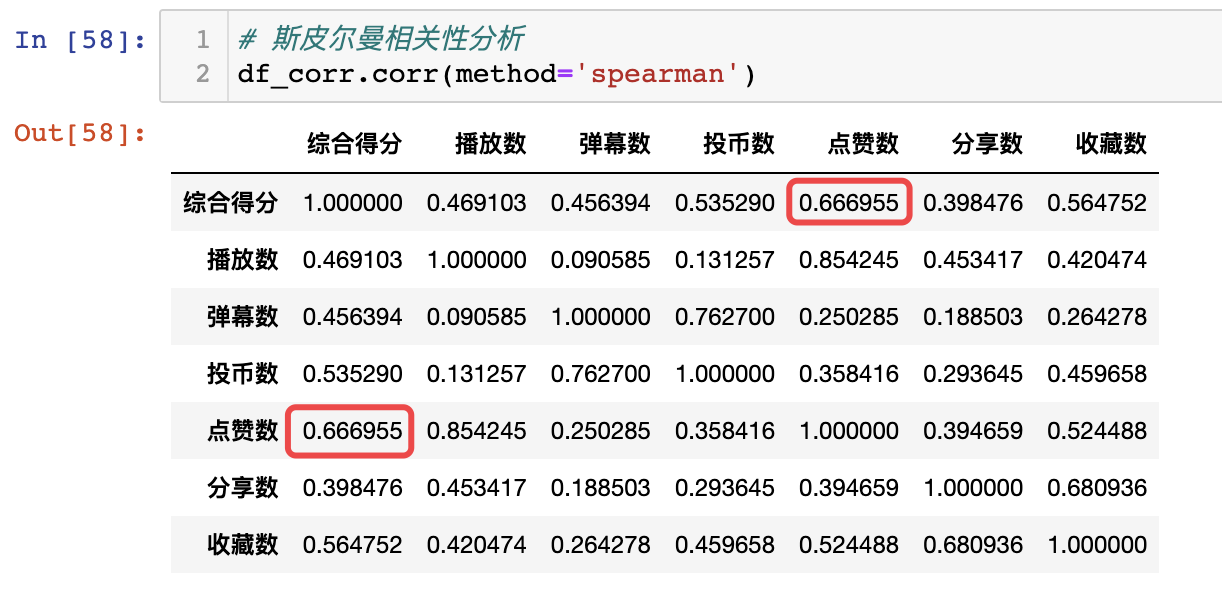
可以看出,点赞数和综合得分的相关性最高,达到了0.66。
根据此分析结论,进一步画出点赞数和综合得分的分布散点图,验证此结论的正确性。
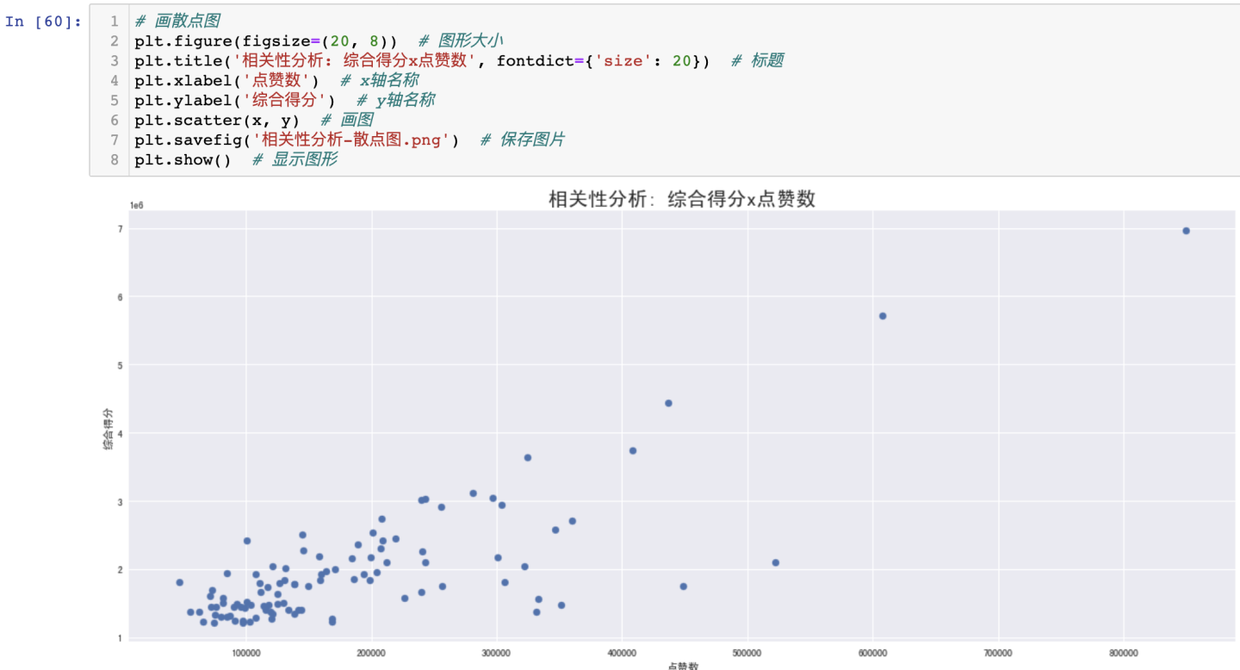
得出结论:随着点赞数增多,综合得分呈明显上升趋势,进一步得出,二者存在正相关的关系。
综合得分划分分布区间,绘制出分布饼图。
首先,划分数据区间:
# 设置分段
bins = [1000000, 1500000,2000000, 2500000, 3000000, 10000000]
# 设置标签
labels = [
'100w-150w',
'150w-200w',
'200w-250w',
'250w-300w',
'300w-1000w'
]
# 按分段离散化数据
segments = pd.cut(score_list, bins, labels=labels) # 按分段切割数据
counts = pd.value_counts(segments, sort=False).values.tolist() # 统计个数
至于区间怎么划分,可以按照对数据的大致理解,和最终可视化呈现的效果,微调划分区间。
绘制饼图:
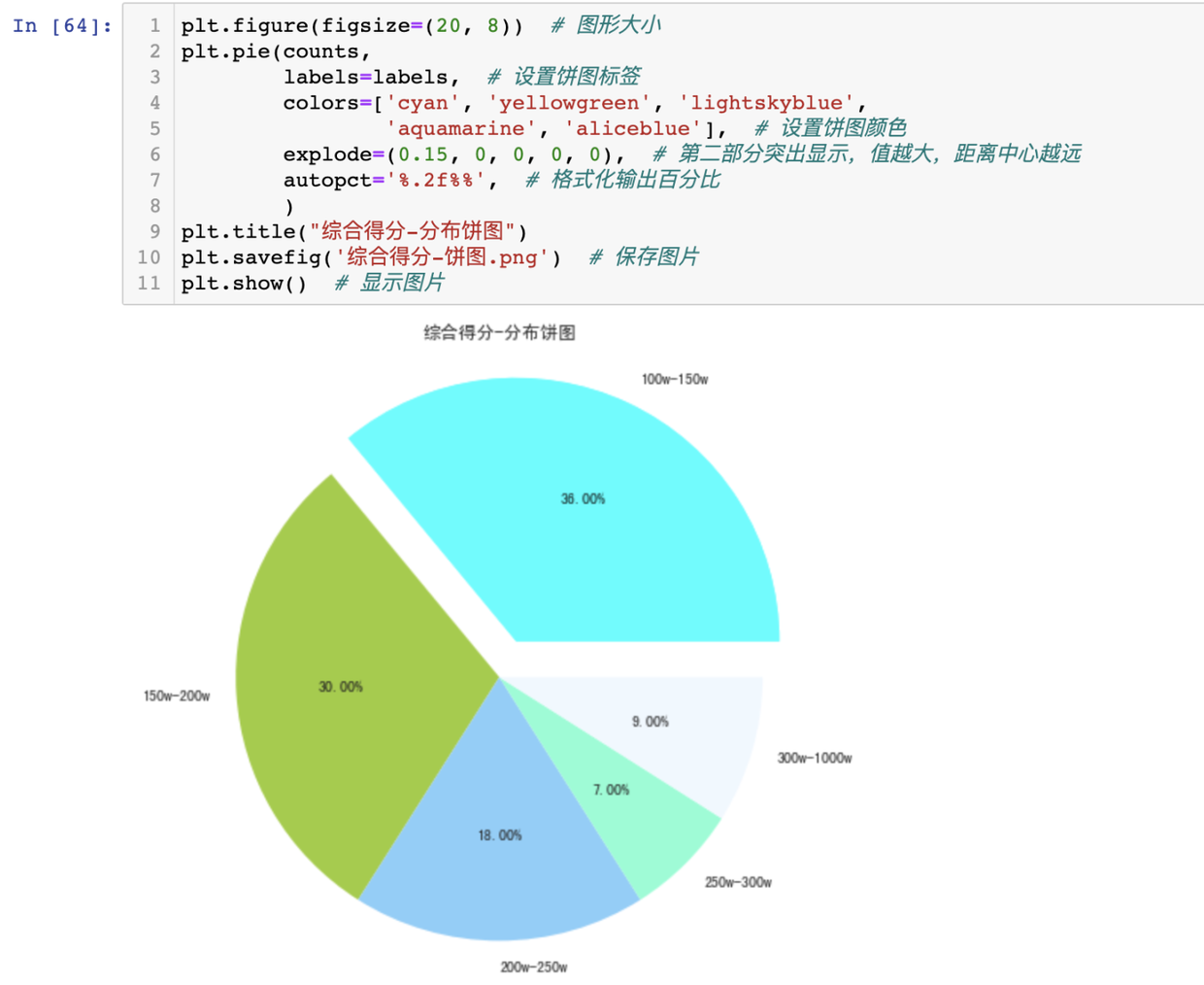
得出结论:综合得分在100w至150w这个区间的视频最多,有36个视频(占比36%)
箱形图,是一种分析数据分布、离散情况的数据分析方法。
首先,我尝试了把这几个数据指标,绘制在同一张图里:
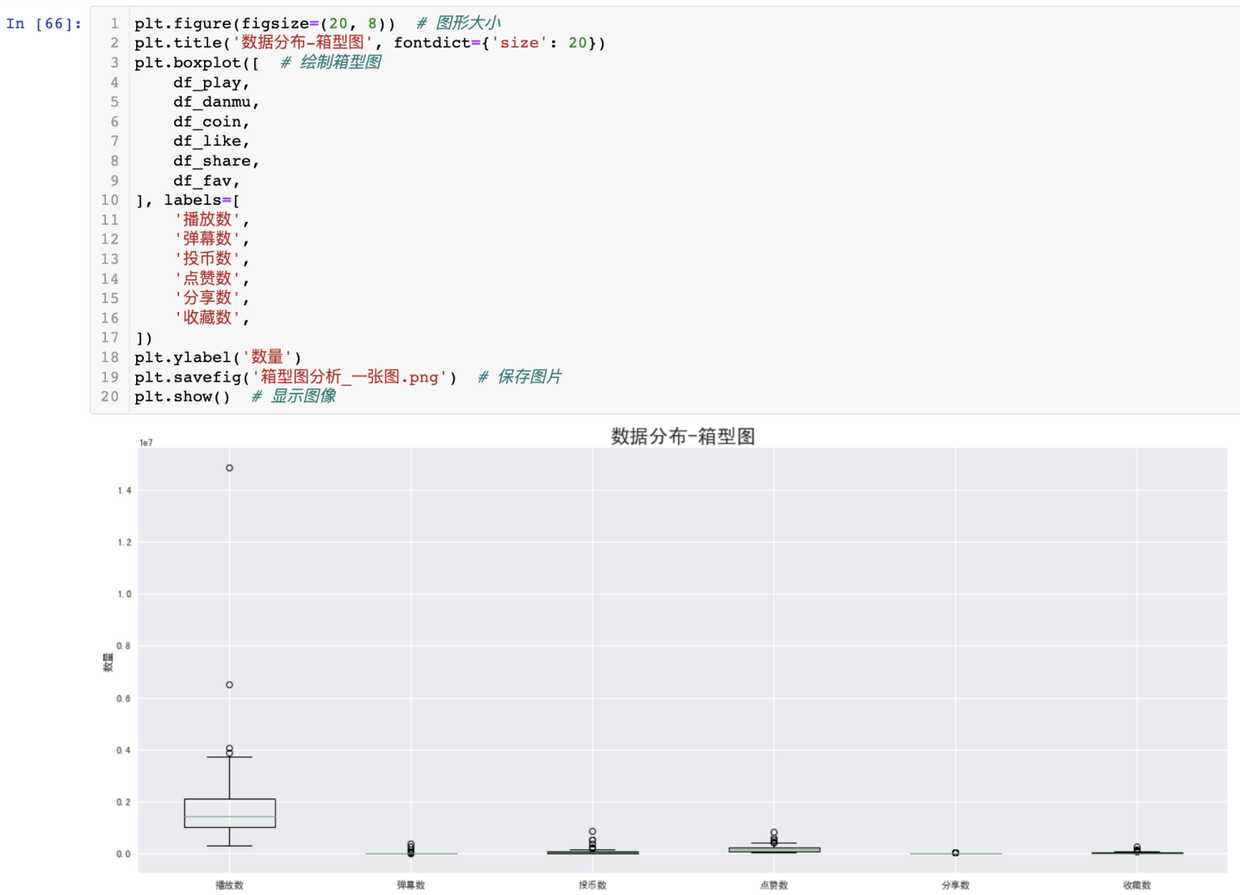
可以发现,由于播放数远远大于其他数据指标,不在一个数量级,导致其他数据指标的box都挤到一块了,可视化效果很差,所以,我打算把每个box画到一个图里,避免这种情况的发生。
以下代码,含知识点(subplot(n_row, n_col, order) n_row代表几行,n_col代表几列,order代表第几个)

得出结论:每个数据指标都存在极值的情况(最大值距离box很远),数据比较离散,方差较大。
针对视频作者,画出词云图。
代码中各个细节设置项,已添加对应注释,不再赘述。
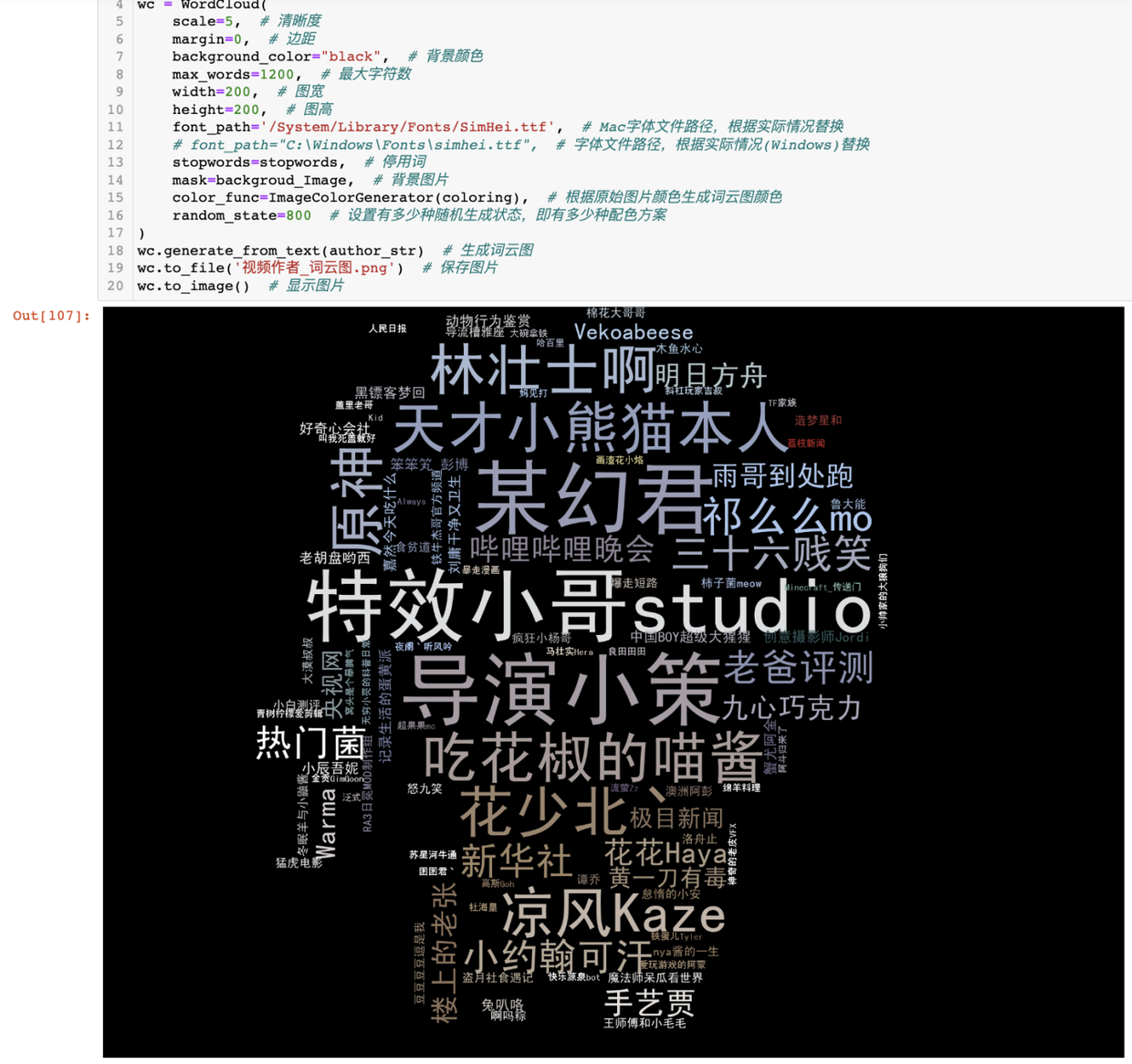
和原始背景图对比:

这个背景图,是我找的一个动漫小人的图片,对比词云图,你会发现:
-
词云图和背景图的形状,大体一致(mask参数的作用)
-
词云图和背景图的颜色分布,大体一致(color_func参数的作用)
至此,全部分析结束。
六、同步讲解视频此案例的讲解视频:
https://www.zhihu.com/zvideo/1513851213354893312
by 马哥python说