Bitmap 实现 用户画像的标签
Bit-map的基本思想就是用一个bit位来标记某个元素对应的Value,而Key即是该元素。由于采用了Bit为单位来存储数据,因此节省存储空间;
如何存储一个数0表示不存在,1表示存在
例如:存储{1,2,5,6}这四个整型数
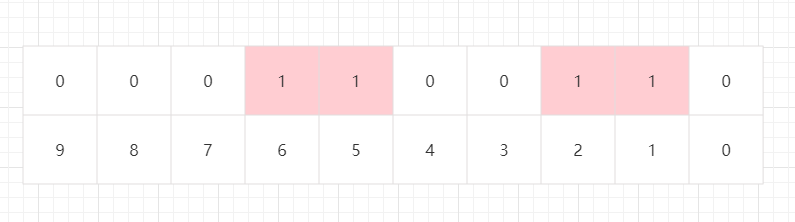
Bitmap 去掉重复的整数型
虽然HashSet和HashMap也能实现用户的查询和统计,但是如果使用HashSet或HashMap存储的话,每一个数据,比如用户ID都要存成int,占4字节 = 32bit;而一个用户ID在Bitmap中只占一个bit,内存节省了32倍。
优秀的并集和交集运算
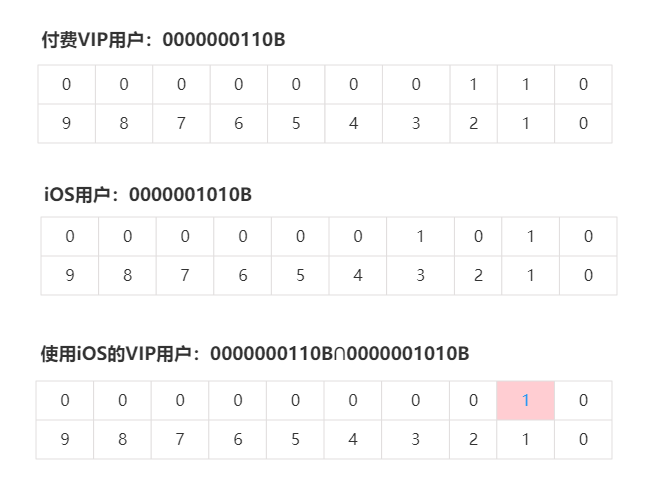
交集∩运算:如何查找使用iOS系统和付费VIP的用户
并集∪运算:如何查找Windows系统或付费VIP的用户
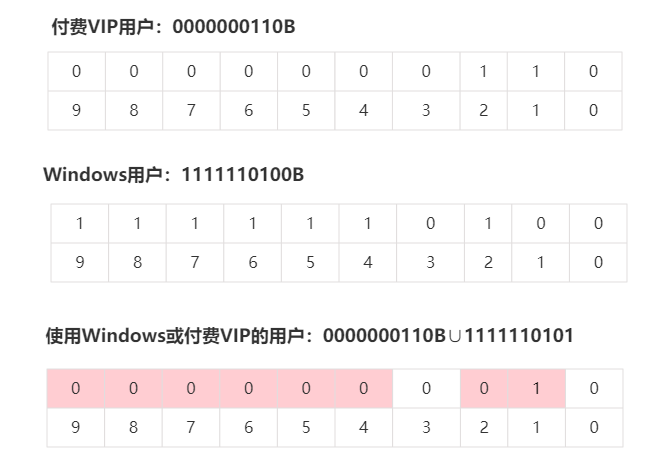
这就是Bitmap算法的另一个优势:位运算的高性能。
缺点:无法做非运算例如:标签中有勇士球迷和湖人球迷
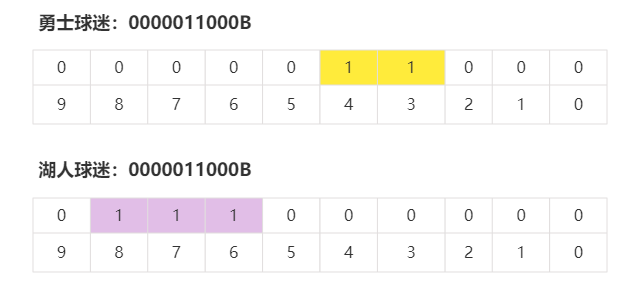
求非湖人球迷,去做非运算的话

只有2个是非湖人球迷,却有7个结果,这样是不行的。
注意在Bitmap中,1代表:具有某个属性;
0 代表:不具有某个属性
Bitmap初始化时,数组中的每个字节都是0,此时0代表的并非 “不具有某个属性” ,而是代表的是,“不存在这个元素”
如何解决此时,借助一个全量的Bitmap

使用异或操作求出:非湖人球迷
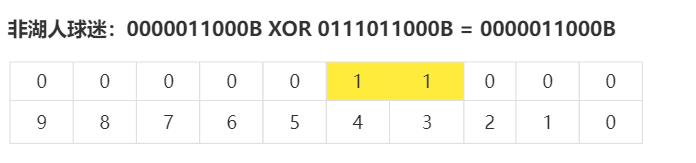
有多个标签也是一样的道理。
Bitmap的二次封装在一个很长的Bitmap中,如果只有几个用户,就会浪费空间,Google 的 EWAHCompressedBitmap 对此做了优化
EWAH 把 Bitmap 存储在 long 数组中,long数组的每一个元素都当作是64位的二进制数,也是整个Bitmap的子集,Google把这些子集称为 Word
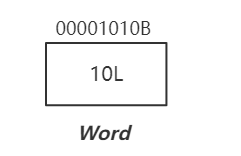
当EWAH创建一个新的Bitmap时,初始化4个Word,即long数组的长度为4,随着数据不断插入进行扩容。
执行过程插入ID = 1,Word1的值变为2?
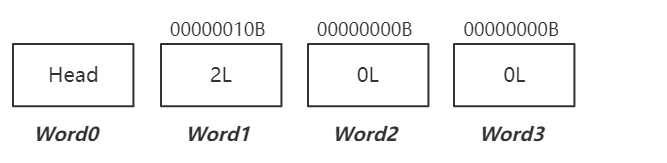
Word0存放头信息,二进制最右边的一位0代表着ID为0的用户
插入ID = 4 ,Word1值变为18?
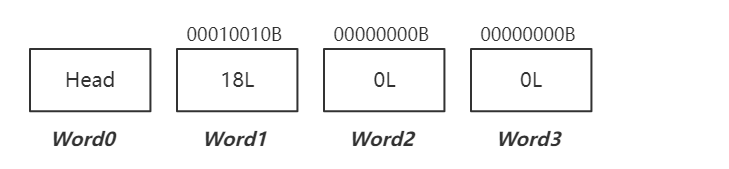
2的四次方 + 2的一次方,计算结果继续放入Word1
插入ID =64 ,结果是多少?
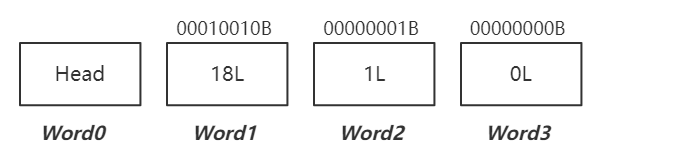
由于每个Word的存储范围是 0 ~ 63,所以 ID = 64 的放到Word2中
插入ID = 128
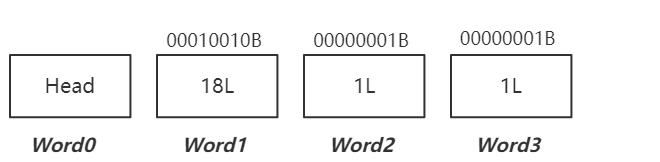
前Word1和Word2只能存储到127,所以 ID = 128 放入到 Word3
此时所有的Word中都存放数据,于是EWAH开始进行动态扩容:

Bitmap优化的关键所在
如果要插入一个ID = 43961557 的用户,难道要把所有Word创建出来么?答:当然不用
(43961557 + 1) / 64 = 686899 余 22,所以Word的值应该是22,而前面有686899个Word
Bitmap不会真的扩容686899个Word,而是只用到了后面的Word4和Word5,Word4存储跨度信息(RLW),Word5存储了686899个Word!
Running Length Word 和 Literal WordWord分为两种:
- Running Length Word 存储跨度信息
- Literal Word 直接存储数据
Word0 和 Word4 就属于 RLW
RLW的存储结构
每一个RLW分成两部分
低32位:表示当前Word横跨了多少个空Word
高32位:表示当前RLW后方有多少个连续的 LW
以上图为例子
Word0 :后方有三个连续的Word,自身横跨了0个Word
-
值:25769803776L
-
二进制:110 00000000000000000000000000000000B
Word4:后方有一个连续的Word,自身横跨了686899个Word
-
值:8591308390L
-
二进制:10 00000000000101001111011001100110B
对于极端稀疏的数据,Bitmap节省了大量空间
But 当一个新数据插入时,Word的类别无法区分,如何找到正确的存储位置呢?
依靠每一个RLW作为 “路标”,比如要插入的新ID是400003,寻找过程如下:
- 解析Word0,得到当前RLW横跨的空Word数量为0,后面有连续3个普通Word;
- 计算当前RLW后方连续普通Word的最大ID是 64 * (0 + 3) - 1= 191;
- 由于191 < 400003,所以新ID必然在下一个RLW(Word4)之后;
- 解析Word4,得到当前RLW横跨的空Word数量为6247,后面有连续1个普通Word;
- 计算当前RLW(Word4)后方连续普通Word的最大ID是 191 + (6247 + 1) * 64 = 400063;
- 由于400003 < 400063,因此新ID 400003的正确存放位置就在当前RLW(Word4)的下一个普通Word中,即Word5.
最终插入结果:

如果新插入的ID刚好在RLW中,例如插入200000,该如何操作?
此时,原RLW进行分裂,如果插入的ID是200000,Word4就会分裂为三个Word:
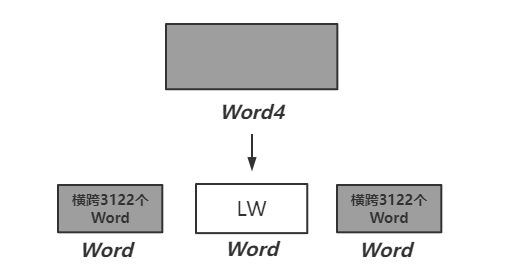
在RLW中插入数据,此类操作影响了执行效率,要尽量避免,Google官方建议按照从小到大的顺序来插入数据!
在Java中的使用* Though you can set the bits in any order (e.g., set(100), set(10), set(1), * you will typically get better performance if you set the bits in increasing order (e.g., set(1), set(10), set(100)). * * Setting a bit that is larger than any of the current set bit * is a constant time operation. Setting a bit that is smaller than an * already set bit can require time proportional to the compressed * size of the bitmap, as the bitmap may need to be rewritten.
JDK 提供了 java.util.BitSet 类
谷歌的 com.googlecode.javaewah.EWAHCompressedBitmap; Maven如下
<dependency>
<groupId>com.googlecode.javaewah</groupId>
<artifactId>JavaEWAH</artifactId>
<version>1.1.0</version>
</dependency>
根据《漫画算法-小灰的算法之旅》总结
你应当热爱自由!