第十一章:持有对象三年之前就买了《Java编程思想》这本书,但是到现在为止都还没有好好看过这本书,这次希望能够坚持通读完整本书并整理好自己的读书笔记,上一篇文章是记录的第一章到第十章的内容,这一次记录的是第十一章到第十六章的内容,写《Java编程思想》读书笔记一的时间还是2022-01-26,没注意又拖这么久了,本文还是会把自己感兴趣的知识点记录一下,相关实例代码:https://gitee.com/reminis_com/thinking-in-java
如果一个程序只包含固定数量的且其生命周期都是已知的对象,那么这是一个非常简单的程序。
通常,程序总是根据运行时才知道的某些条件去创建新对象,在此之前,不会知道所需对象的数量,甚至不知道确切的对象。例如我们熟知的数组,它是编译器支持的类型,数组是保存一组对象的最有效的方式,如果你想保存一组基本类型的数据,也推荐使用这种方式。但是数组具有固定的尺寸,而在更一般的情况下中,你在写程序时并不知道需要多少个对象,或者是否需要更复杂的方式来存储对象,因此数组尺寸固定这一限制显得过于受限了。
Java实用类库提供了一套相当完整的容器类来解决这个基本问题,Java容器类都可以自动地调整自己的尺寸。Java容器类库的用途是“保存对象”,并将其划分成两个不同的概念:
- Collection:一个独立元素的序列,这些元素都服从一条或多条规则。List必须按照插入的顺序保存元素,而Set不能有重复元素。Queue按照排队规则来确定对象的产生顺序(通常与它们被插入的顺序相同)
- Map:一组成对的“键值对”对象,允许你使用键来查找值
-
添加一组元素
- Collections.addAll()方法接受一个Collection对象,以及一个数组或用逗号分隔的列表,将元素添加到Collection中。Collection.addAll()成员方法只能接受另一个Collection对象作为参数因此它不如Arrays.asList()或Collections.addAll()灵活,这两个方法都是使用的可变参数列表。
- 你也可以直接使用Arrays.asList()的输出作为List,但是在这种情况下,其底层表示的是数组,因此不能调整尺寸,如果你试图使用add()或delete()方法在这中列表中添加或删除元素,在运行时就会获得“java.lang.UnsupportedOperationException(不支持的操作)”异常。
import java.util.*; public class AddingGroup { public static void main(String[] args) { Collection<Integer> collection = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5)); Integer[] moreInts = { 6, 7, 8, 9, 10 }; collection.addAll(Arrays.asList(moreInts)); Collections.addAll(collection, 11, 12, 13, 14, 15); Collections.addAll(collection, moreInts); List<Integer> list = Arrays.asList(16, 17, 18, 19, 20); list.set(1, 99); // list.add(21); // java.lang.UnsupportedOperationException } } -
List:List承诺可以将元素维护在特定的序列中。List接口在Collection的基础上添加了大量的方法,使得可以在List的中间插入和移除元素,
-
ArrayList:长于随机访问元素,但是在List的中间插入和移除元素时较慢
-
LinkedList:它通过代价较低的在List中间进行插入和删除操作,提供了优化的顺序访问。LinkedList在随机访问方面相对较慢,但它的特性集较ArrayList更大。此外,LinkedList还提供了可以使其用作栈、队列或双端队列的方法。这些方法中有些彼此之间只是名称有些差异,或者只存在些许差异,以使得这些名字在特定用法的上下文环境中更加适用(特别是Queue中),如下:
-
getFirst()和element()完全一样,都是返回列表的头(第一个元素),而不移除它。如果List为空,则抛出NoSuchElementException。peek()方法与这两个方法只是稍有差异,它在列表为空时返回null。
-
removeFirst()和remove()也是完全一样的,它们移除并返回列表的头,而在列表为空时抛出NoSuchElementException。poll()方法稍有差异,它在列表为空时返回null。
-
addFirst()与add()和addLast()相同,它们都将某个元素插入到列表的尾(端)部。
-
removeLast()移除并返回列表的最后一个元素。
-
栈(Stack):通常是指“后进先出”(LIFO)的容器,即最后一个“压入”栈的元素,第一个“弹出”栈。LinkedList具有能够直接实现栈的所有功能的方法,因此可以直接将LinkedList作为栈使用,不过,有时一个真正的“栈”更能把事情讲清楚:
public class Stack<T> { private LinkedList<T> storage = new LinkedList<>(); public void push(T v) { storage.addFirst(v); } public T peek() { return storage.getFirst(); } public T pop() { return storage.removeFirst(); } public boolean isEmpty() { return storage.isEmpty(); } @Override public String toString() { return storage.toString(); } }
-
-
-
迭代器:任何容器类,都必须有某种方式可以插入元素并将它们再次取回。毕竟,持有事务是容器最基本的动作。迭代器统一了对容器的访问方式。迭代器通常被称为轻量级对象,创建它的代价小,并且Java的Iterator只能单向移动,这个Iterator只能用来:
- 使用iterator()方法要求容器返回一个Iterator。Iterator将准备好返回序列的第一个元素
- 使用next()获得序列中的下一个元素
- 使用hasNext()检查序列中是否还有元素
- 使用remove()将迭代器新近返回的元素删除
注意:
- 由于Iterator可以移除由next()产生的最后一个元素,这意味着在调用remove()之前必须先调用next()。
- ListIterator是一个更强大的Iterator的子类型,但它只能用于各种List类的访问。尽管Iterator只能向前移动,但是ListIterator可以双向移动。
-
Set:Set不保存重复的元素,Set具有与Collection完全一样的接口,因此没有任何额外的功能。HashSet所维护的顺序与TreeSet或LinkedHashSet都不同,HashSet使用的是散列函数,LinkedHashSet因为查询速度的原因也使用了散列,但是看起来它使用了链表来维护元素的插入顺序,它按照被添加的顺序保存元素。TreeSet默认会按照比较结果的升序保存对象。
-
Map:将对象映射到其它对象的能力是一种解决编程问题的杀手锏。例如,考虑一个程序,他将用来检查Java的Random类得随机性。理想状态下,Random可以产生理想的数字分布,但要想测试它,则需要生成大量的随机数,并对落入各种不同范围的数字进行计数,Map可以很容易的解决该问题,在本列中,键是Random产生的数字,值是该数字出现的次数。
public class Statistics { public static void main(String[] args) { Random rand = new Random(47); Map<Integer, Integer> map = new HashMap<>(); for (int i = 0; i < 10000; i++) { // 随机生成一个0~20范围内的数字 int r = rand.nextInt(20); Integer freq = map.get(r); map.put(r, freq == null ? 1 : freq + 1); } System.out.println(map); } } //output: {0=481, 1=502, 2=489, 3=508, 4=481, 5=503, 6=519, 7=471, 8=468, 9=549, 10=513, // 11=531, 12=521, 13=506, 14=477, 15=497, 16=533, 17=509, 18=478, 19=464} -
Queue(队列):队列是一个典型的先进先出(FIFO)的容器。即从容器的一端放入事物,从另一端取出,并且事务放入容器的顺序和取出的顺序是相同的。队列常被当作一种可靠的将对象从程序的某个区域传输到另一个区域的途径。LinkedList提供了方法支持队列的行为,并且它是实现了Queue接口,因此LinkedList可以用作Queue的一种实现。
public class QueueDemo { public static void printQ(Queue queue) { while (queue.peek() != null) { System.out.print(queue.remove() + " "); } System.out.println(); } public static void main(String[] args) { Queue<Integer> queue = new LinkedList<>(); Random random = new Random(47); for (int i = 0; i < 10; i++) { queue.offer(random.nextInt(i + 10)); } printQ(queue); Queue<Character> qc = new LinkedList<>(); for (char c : "Reminis".toCharArray()) { qc.offer(c); } printQ(qc); } } /** * output: * 8 1 1 1 5 14 3 1 0 1 * R e m i n i s */offer()方法是与Queue相关的方法之一,它在允许的情况下,将一个元素插入到队尾,或者返回false。peek()和element()都将在不移除的情况下返回队头,但是peek()方法在队列为空时返回null,而element()在队列为空时抛出NoSuchElementException异常。poll()和remove()方法都将移除并返回队头,但是poll()方法在队列为空时返回null,而remove()在队列为空时抛出NoSuchElementException异常。
-
PriorityQueue: 先进先出描述了最典型的队列规则。队列规则是指在给定一组队列中的元素的情况下,确定一个弹出队列的元素的规则。先进先出声明的是下一个元素应该是等待时间最长的元素。
-
优先级队列声明下一个弹出元素是最需要的元素(具有最高的优先级)。例如,在飞机场,飞机临近起飞时,这架飞机的乘客可以在办理登机手续时排到队头。如果构建了一个消息系统。某些消息比其他消息更重要,因而应该更快地得到处理,那么它们何时得到处理就与它们何时到达无关。PriorityQueue添加到Java SE5中,是为了提供这种行为的一种自动实现。
-
当你在PriorityQueue上调用offer()方法来插入一个对象时,这个对象会在队列中被排序。默认的排序将使用对象在队列中的自然顺序,但是你可以通过提供自己的Comparator来修改这个顺序。PriorityQueue可以确保当你调用peek()、poll()和remove()方法时,获取的元素将是队列中优先级最高的元素。
-
让PriorityQueue与Integer、String和Character这样的内置类型一起工作易如反掌。在下面的示例中,第一个值集与前一个示例中的随机值相同,因此你可以看到它们从PriorityQueue中弹出的顺序与前一个示例不同∶
public class PriorityQueueDemo { public static void main(String[] args) { PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(); Random rand = new Random(47); for (int i = 0; i < 10; i++) { priorityQueue.offer(rand.nextInt(i + 10)); } QueueDemo.printQ(priorityQueue); List<Integer> ints = Arrays.asList(25, 22, 20, 18, 14, 9, 3, 1, 1, 2, 3, 9, 14, 18, 21, 23, 25); priorityQueue = new PriorityQueue<>(ints); QueueDemo.printQ(priorityQueue); priorityQueue = new PriorityQueue<>(ints.size(), Collections.reverseOrder()); priorityQueue.addAll(ints); QueueDemo.printQ(priorityQueue); String fact = "EDUCATION SHOULD ESCHEW OBFUSCATION"; List<String> strings = Arrays.asList(fact.split("")); PriorityQueue<String> stringPQ = new PriorityQueue<>(strings); QueueDemo.printQ(stringPQ); stringPQ = new PriorityQueue<>(strings.size(), Collections.reverseOrder()); stringPQ.addAll(strings); QueueDemo.printQ(stringPQ); Set<Character> charSet = new HashSet<>(); for (char c : fact.toCharArray()) { charSet.add(c); } PriorityQueue<Character> charPQ = new PriorityQueue<>(charSet); QueueDemo.printQ(charPQ); } } /** * output: * * 0 1 1 1 1 1 3 5 8 14 * 1 1 2 3 3 9 9 14 14 18 18 20 21 22 23 25 25 * 25 25 23 22 21 20 18 18 14 14 9 9 3 3 2 1 1 * A A B C C C D D E E E F H H I I L N N O O O O S S S T T U U U W * W U U U T T S S S O O O O N N L I I H H F E E E D D C C C B A A * A B C D E F H I L N O S T U W */你可以看到,重复是允许的,最小的值拥有最高的优先级(如果是String,空格也可以算作值,并且比字母的优先级高)。为了展示你可以使用怎样的方法通过提供自己的Comparator象来改变排序,第三个对PriorityQueue
的构造器调用,和第二个对PriorityQueue 的调用使用了由Collection.reverseOrder()(新添加到JavaSE5中的)产生的反序Comparator。 最后一部分添加了一个HashSet来消除重复的Character,这么做只是为了增添点乐趣 Integer、String和Character可以与PriorityQueue一起工作,因为这些类已经内建了自排序。如果你想在PriorityQueue中使用自己的类,就必须包括额外的功能以产生自然排序,或者必须提供自己的Comparator。
总结:
Java提供了大量持有对象的方式∶
1)数组将数字与对象联系起来。它保存类型明确的对象,查询对象时,不需要对结果做类型转换。它可以是多维的,可以保存基本类型的数据。但是,数组一旦生成,其容量就不能改变。
2)Collection保存单一的元素,而Map保存相关联的键值对。有了Java的泛型,你就可以指定容器中存放的对象类型,因此你就不会将错误类型的对象放置到容器中,并且在从容器中获取元素时,不必进行类型转换。各种Collection和各种Map都可以在你向其中添加更多的元素时,目动调整其尺寸。容器不能持有基本类型,但是自动包装机制会仔细地执行基本类型到容器中所持有的包装器类型之间的双向转换。
3)像数组一样,List也建立数字索引与对象的关联,因此,数组和List都是排好序的容器。Lis能够自动扩充容量。
4)如果要进行大量的随机访问,就使用ArrayList;如果要经常从表中间插入或删除元素,则应该使用LinkedList。
5)各种Queue以及栈的行为,由LinkedList提供支持。
6) Map是一种将对象(而非数字)与对象相关联的设计。HashMap设计用来快速访问;而TreMap保持"键"始终处于排序状态,所以没有HashMap快。LinkedHashMap保持元素插入的顺序,但是也通过散列提供了快速访问能力。
7)Set不接受重复元素。HashSet提供最快的查询速度,而TreeSet保持元素处于排序状态。linkedHashSet以插入顺序保存元素
8)新程序中不应该使用过时的Vector、Hashtable和Stack。
-
Java的基本理念是“结构不佳的代码不能运行”。
发现错误的理想时机是在编译阶段,也就是在你试图运行程序之前。然而,编译期间并不能找出所有的错误,余下的问题必须在运行期间解决。Java使用异常来提供一致的错误报告模型,使得构件能够与客户端代码可靠地沟通问题。
异常情形是指阻止当前方法或作用域继续执行的问题。把异常情形和普通问题区分相当重要,所谓普通问题是指,在当前环境能够得到足够的信息,总能处理这个错误。而对于异常 情形,就不能继续下去了,因为在当前环境下无法获得必要信息来解决问题。你所能做的就是从当前环境中跳出,并且把问题交给上一级环境,这就是抛出异常时所发生的事情。
与使用Java中的其它对象一样,我们总是用new在堆上创建异常对象,这也伴随着存储空间的分配和构造器的调用。所有标准异常类都有两个构造器:一个是默认构造器;另一个是接受字符串作为参数,以便能把相关信息放入异常对象的构造器,如throw new NullPointerException("t = null");。此外,能够抛出任意类型的Throwable对象,它是异常类型的根类。通常对于不同类型的错误,要抛出相应的异常。错误信息可以保存在异常对象内部或者使用异常类的名称来暗示。
捕获异常:要明白异常是如何被捕获的,必须首先理解监控区域的概念。它是一段可能产生异常的代码,并且后面跟着处理这些异常的代码。在try块里“尝试”各种(可能产生异常的)方法调用。当然,抛出的异常必须在某处得到处理,这个地点就是异常处理程序 ,而且针对每个要捕获的异常,得准备相应的处理程序。异常处理程序紧跟在try块之后,以关键字catch表示:
try {
// code that might generate exceptions
} catch (Type1 t1) {
// handle exception of Type1
} catch (Type2 t2) {
// handle exception of Type2
} catch (Type3 t3) {
// handle exception of Type3
}
每个catch子句(异常处理程序)看起来就像是接受一个且仅接受一个特殊类型的参数的方法。异常处理程序必须紧跟在try块之后,当异常被抛出时,异常处理机制将负责搜寻参数与异常类型相匹配的第一个处理程序。然后进入catch子句执行,此时认为异常得到了处理。一旦catch子句执行结束,则处理程序的查找过程执行结束。注意,只有匹配的catch子句才能得到执行。
使用finally进行清理:对于一些代码,可能会希望无论try块中的异常是否抛出,它们都能得到执行。这通常适用于除内存之外的资源恢复到它们初始状态时,这种需要清理的资源包括:已经打开的文件或网络连接,在屏幕上画的图形,甚至可以是外部世界的某个开关,如下例所示:
public class Switch {
private boolean state = false;
public boolean read() { return state; }
public void on() { state = true; print(this); }
public void off() { state = false; print(this); }
public String toString() { return state ? "on" : "off"; }
}
/**
* 程序的目的是要确保main()结束的时候开关必须是关的,所以在每个try块和异常处理程序的末尾
* 都加入了对sw.off()方法的调用。但也可能有这种情况:异常被抛出,但没被异常处理程序捕获,
* 这时sw.off()就得不到调用。但是有了finally,只要把try块中清理代码移放在一处即可:
*/
public class OnOffSwitch {
private static Switch sw = new Switch();
public static void f() throws OnOffException1,OnOffException2 {}
public static void main(String[] args) {
try {
sw.on();
// Code that can throw exceptions...
f();
sw.off();
} catch(OnOffException1 e) {
System.out.println("OnOffException1");
sw.off();
} catch(OnOffException2 e) {
System.out.println("OnOffException2");
sw.off();
}
}
}
/**
* 这里sw.off()被移到一处,并且保证在任何情况下都能得到执行。
*/
public class WithFinally {
static Switch sw = new Switch();
public static void main(String[] args) {
try {
sw.on();
// Code that can throw exceptions...
OnOffSwitch.f();
} catch(OnOffException1 e) {
System.out.println("OnOffException1");
} catch(OnOffException2 e) {
System.out.println("OnOffException2");
} finally {
sw.off();
}
}
}
异常使用指南
-
在恰当的级别处理问题。(在知道该如何处理的情况下才捕获异常。)
-
解决问题并且重新调用产生异常的方法。
-
进行少许修补,然后绕过异常发生的地方继续执行。
-
用别的数据进行计算,以代替方法预计会返回的值。
-
把当前运行环境下能做的事情尽量做完,然后把相同的异常重抛到更高层。
-
把当前运行环境下能做的事情尽量做完,然后把不同的异常抛到更高层。
-
终止程序。
-
进行简化。(如果你的异常模式使问题变得太复杂,那用起来会非常痛苦也很烦人。)
-
让类库和程序更安全。(这既是在为调试做短期投资,也是在为程序的健壮性做长期投资。)
由于字符串在我们开发中使用频率是相当高的,本章内容也主要介绍了一些关于字符串常用的API,需要注意的是String对象是不可变的,String类中每一个看起来会修改String值的方法,实际上都是创建了一个全新的String对象,以包含修改后的字符串内容,而最初的String对象则丝毫未动。
重载“+”与StringBuilder
不可变性会带来一定的效率问题,为String对象重载的“+”操作符就是一个例子。重载的意义是,一个操作符在应用于特定的类时,被赋予了特殊的意义(用于String的“+”与“+=”是Java中仅有的两个重载过的操作符,而Java并不允程序员重载任何操作符,但C++允许程序员任意重载操作符)。操作符可以用来连接String:
public class Concatenation {
public static void main(String[] args) {
String mango = "mango";
String s = "abc" + mango + "def" + 47;
System.out.println(s);
}
}
// output: abcmangodef47
我们可以通过JDK自带的javap来反编译以上代码,命令如下:javap -c Concatenation.class,这里的-c表示将要生成JVM字节码。
public class strings.Concatenation {
public strings.Concatenation();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: ldc #2 // String mango
2: astore_1
3: new #3 // class java/lang/StringBuilder
6: dup
7: invokespecial #4 // Method java/lang/StringBuilder."<init>":()V
10: ldc #5 // String abc
12: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
15: aload_1
16: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
19: ldc #7 // String def
21: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
24: bipush 47
26: invokevirtual #8 // Method java/lang/StringBuilder.append:(I)Ljava/lang/StringBuilder;
29: invokevirtual #9 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
32: astore_2
33: getstatic #10 // Field java/lang/System.out:Ljava/io/PrintStream;
36: aload_2
37: invokevirtual #11 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
40: return
}
我们从生成后的字节码中可以看到,编译器自动引入了java.lang.StringBuilder类,虽然我们在源代码中并没有使用StringBuilder类,但是编译器却自主主张地使用了它,因为它更高效。
现在,也许你会觉得可以随意使用String对象,反正编译器会为你自动地优化性能,让我们更深入地看看编译器能为我们优化到什么程度。下面程序采用两种方式生成一个String:方法一使用了多个String对象,方法二在代码中使用了StringBuilder。
public class WitherStringBuilder {
/**
* 使用String进行字符串拼接
* @param fields 字符串数组
* @return 拼接后的字符串
*/
public String implicit(String[] fields) {
String result = "";
for (int i = 0; i < fields.length; i++) {
result += fields[i];
}
return result;
}
/**
* 使用StringBuilder进行字符串拼接
* @param fields 字符串数组
* @return 拼接后的字符串
*/
public String explicit(String[] fields) {
StringBuilder result = new StringBuilder();
for (int i = 0; i < fields.length; i++) {
result.append(fields[i]);
}
return result.toString();
}
}
现在运行javap -c WitherStringBuilder.class,可以看到 两个方法对应的字节码,首先是implict()方法:
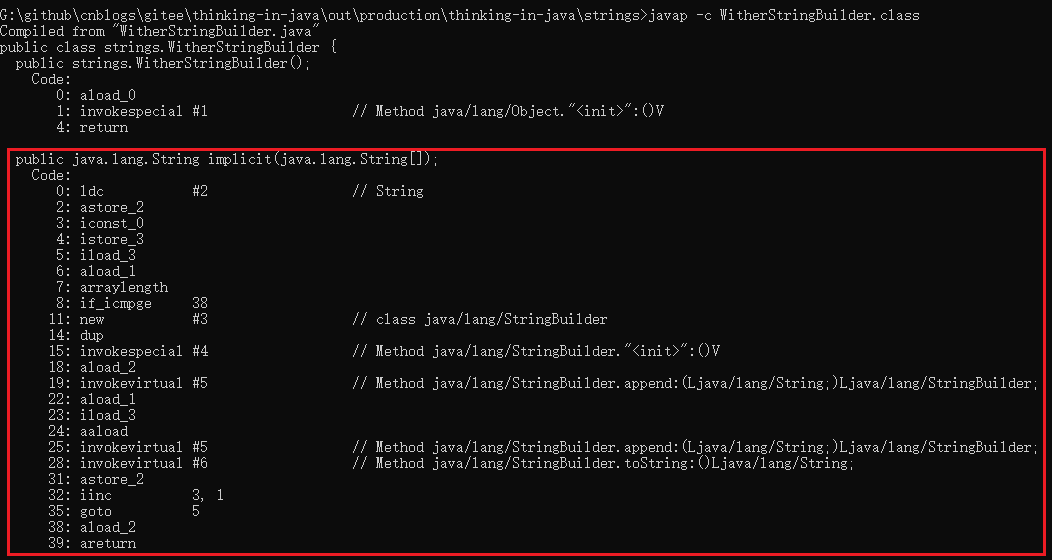
注意从第8行到第35行构成了一个循环体。第8行∶对堆栈中的操作数进行"大于或等于的整数比较运算",循环结束时跳到第38行。第35行∶返回循环体的起始点(第5行)。要注意的重点是;StringBuilder是在循环之内构造的,这意味着每经过循环一次,就会创建一个新的StringBuilder 对象。
下面是explicit()方法对应的字节码∶

可以看到.不仅循环部分的代码更简短、更简单,而目它只生成了一个StringBuilder对象。显式地创建StringBuilder还允许你预先为其指定大小。如果你已经知道最终的字符串大概有多长,那预先指定StringBuilder的大小可以避免多次重新分配缓冲。
因此,当你为一个类编写toString()方法时,如果字符串操作比较简单,那就可以信赖编译器,它会为你合理地构造最终的字符串结果。但是,如果你要在toString()方法中使用循环,那么最好自己创建一个StringBuilder对象,用它来构造最终的结果。请参考以下示例∶
public class UsingStringBuilder {
private static Random random = new Random(47);
@Override
public String toString() {
StringBuilder result = new StringBuilder("[");
for (int i = 0; i < 25; i++) {
result.append(random.nextInt(100));
result.append(", ");
}
result.delete(result.length() - 2, result.length());
result.append("]");
return result.toString();
}
public static void main(String[] args) {
UsingStringBuilder usb = new UsingStringBuilder();
System.out.println(usb);
}
}
StringBuilder提供了丰富而全面的方法,包括insert()、repleace()、substring()甚至reverse(),但是最常用的还是append()和toString()。还有delete()方法,上面的例子中我们用它删除最后一个逗号与空格,以便添加右括号。
StringBuilder是Java SE5引入的,在这之前Java用的是StringBuffer。后者是线程安全的,因此开销也会大些,所以在Java SE5/6中,字符串操作应该还会更快一点。
第十四章:类型信息运行时类型信息使得你可以在程序运行时发现和使用类型信息。
它使你从只能在编译期执行面向类型的操作的整锢中解脱了出来。并且可以使用某些非常强大的程序。对RTTI的需要,揭示了面向对象设计中许多有趣(并且复杂)的问题,同时也提出了如何组织程序的问题。
本章将讨论 Java 是如何让我们在运行时识别对象和类的信息的。主要有两种方式∶一种是"传统的"RTTI,它假定我们在编译时已经知道了所有的类型;另一种是"反射"机制,它允许我们在运行时发现和使用类的信息。在Java中,所有的类型转换都是在运行时进行正确检查的,这也是RTTI名字的含义:在运行时,识别一个对象的类型。
Class对象 要理解RTTI在Java中的工作原理,首先必须知道类型信息在运行时是如何表示的。这项工作是由称为Class对象的特殊对象完成的,它包含了与类有关的信息。事实上,Class对象就是用来创建类的所有的”常规“对象的。Java使用Class对象来执行其RTTI,即使你正在执行的是类似转型这样的操作。Class类还拥有大量的使用RTTI的其他方式。 类是程序的一部分,每个类都有一个Class对象。换言之,每当编写并且编译了一个新类,就会产生一个Class对象(更恰当地说,是被保存在一个同名的.class文件中)。为了生成这个类的对象,运行这个程序的Java虚拟机(JVM)将使用被称为"类加载器"的子系统。
类加载器子系统实际上可以包含一条类加载器链,但是只有一个原生类加载器,它是JVM 实现的一部分。原生类加载器加载的是所谓的可信类,包括Java API类,它们通常是从本地盘加载的。在这条链中,通常不需要添加额外的类加载器,但是如果你有特殊需求(例如以某种特殊的方式加载类,以支持Web服务器应用,或者在网络中下载类),那么你有一种方式可以挂接额外的类加载器。 所有的类都是在对其第一次使用时,动态加载到JVM中的。当程序创建第一个对类的静态成员的引用时,就会加载这个类。这个证明构造器也是类的静态方法,即使在构造器之前并没有使用static关键字。因此,使用new操作符创建类的新对象也会被当作对类的静态成员的引用。 因此,Java程序在它开始运行之前并非被完全加载,其各个部分是在必需时才加载的。这一点与许多传统语言都不同。动态加载使能的行为,在诸如C++这样的静态加载语言中是很难或者根本不可能复制的。
类加载器首先检查这个类的Class对象是否已经加载。如果尚未加载,默认的类加载器就会根据类名查找.class文件(例如,某个附加类加载器可能会在数据库中查找字节码)。在这个类的字节码被加载时,它们会接受验证,以确保其没有被破坏,并且不包含不良Java代码(这是Java 中用于安全防范目的的措施之一)。
一旦某个类的Class对象被载入内存,它就被用来创建这个类的所有对象。下面的示范程序可以证明这一点∶
class Candy {
static {
System.out.println("Loading Candy");
}
}
class Gum {
static {
System.out.println("Loading Gum");
}
}
class Cookie {
static {
System.out.println("Loading Cookie");
}
}
public class SweetShop {
public static void main(String[] args) {
System.out.println("inside main");
new Candy();
System.out.println("After creating Candy");
try {
Class.forName("typeinfo.Gum");
} catch (ClassNotFoundException e) {
System.out.println("Couldn't find Gum");
}
System.out.println("After Class.forName(\"Gum\")");
new Cookie();
System.out.println("After creating Cookie");
}
}/** output:
* inside main
* Loading Candy
* After creating Candy
* Loading Gum
* After Class.forName("Gum")
* Loading Cookie
* After creating Cookie
*/
这里的每个类Candy、Gum和Cookie,都有一个static子句,该子句在类第一次被加载时执行。这时会有相应的信息打印出来,告诉我们这个类什么时候被加载了。在main()中,创建对象的代码被置于打印语句之间,以帮助我们判断加载的时间点。 从输出中可以看到,Cass对象仅在需要的时候才被加载。
类字面常量
Java还提供了另一种方法来生成对Class对象的引用,即使用类字面常量。对上述程序来说,就像下面这样∶
Gum.class;
这样做不仅更简单,而且更安全,因为它在编译时就会受到检查(因此不需要置于try语句块中)。并且它根除了对forName()方法的调用,所以也更高效。
类字面常量不仅可以应用于普通的类,也可以应用于接口、数组以及基本数据类型。另外,对于基本数据类型的包装器类,还有一个标准字段TYPE。TYPE字段是一个引用,指向对应的基本数据类型的Class对象,如下所示∶
书中建议使用".class"的形式,以保持与普通类的一致性。
注意,有一点很有趣,当使用".class"来创建对Class对象的引用时,不会自动地初始化该Class对象。为了使用类而做的准备工作实际包含三个步骤∶
1. 加载,这是由类加载器执行的。该步骤将查找字节码(通常在classpath所指定的路径中查找,但这并非是必需的),并从这些字节码中创建一个Class对象。
2. 链接。在链接阶段将验证类中的字节码,为静态域分配存储空间,并且如果必需的话,将解析这个类创建的对其他类的所有引用。
3. 初始化。如果该类具有超类,则对其初始化,执行静态初始化器和静态初始化块。初始化被延迟到了对静态方法(构造器隐式地是静态的)或者非常数静态域进行首次引用时才执行∶
class Initable {
// 编译期常量,Initable不需要被初始化就可以读取
static final int staticFinal = 47;
static final int staticFinal2 = ClassInitialization.rand.nextInt(1000);
static {
System.out.println("Initializing Initable");
}
}
class Initable2 {
static int staticNonFinal = 147;
static {
System.out.println("Initializing Initable2");
}
}
class Initable3 {
static int staticNonFinal = 74;
static {
System.out.println("Initializing Initable3");
}
}
public class ClassInitialization {
public static Random rand = new Random(47);
public static void main(String[] args) throws Exception {
Class initable = Initable.class;
System.out.println("After creating Initable ref");
// 编译期常量,这个值不需要对Initable类初始化就可以被读取
System.out.println(Initable.staticFinal);
// 对Initable.staticFinal2的访问将强制进行类得初始化,因为他不是一个编译器常量
System.out.println(Initable.staticFinal2);
// 如果一个static域不是final的,那么在对它访问时,总是要求被读取之前,要先进行链接(为这个域分配存储空间)和初始化(初始化该存储空间)
System.out.println(Initable2.staticNonFinal);
// Class.forName()立即就进行了初始化
Class initable3 = Class.forName("typeinfo.Initable3");
System.out.println("After creating Initable3 ref");
System.out.println(Initable3.staticNonFinal);
}
}/* output:
After creating Initable ref
47
Initializing Initable
258
Initializing Initable2
147
Initializing Initable3
After creating Initable3 ref
74
*/
关于关键字instanceof,它返回一个布尔值,告诉我们对象是不是某个特定类型的实例,可以用提问的方式使用它,就像这样 :
if (x instanceof Dog) {
((Dog)x).bark();
}
instanceof局限性:只可将其与命名类型进行比较,而不能与Class对象作比较。Class.isInstance()方法提供了一种动态地测试对象的途径。我们可以创建出一个Class对象的数组,然后将目标对象与这数组中的对象进行逐一比较来代替一大堆的instanceof表达式。
instanceOf与Class的等价性 在查询类型信息时,以instanceof的形式(即以instanceof的形式或isInstance()的形式,它们产生相同的结果)与直接比较Class对象有一个很重要的差别。下面的例子展示了这种差别∶
class Base {}
class Derived extends Base {}
public class FamilyVsExactType {
static void test(Object x) {
System.out.println("Testing x of type " + x.getClass());
System.out.println("x instanceof Base " + (x instanceof Base));
System.out.println("x instanceof Derived "+ (x instanceof Derived));
System.out.println("Base.isInstance(x) "+ Base.class.isInstance(x));
System.out.println("Derived.isInstance(x) " +
Derived.class.isInstance(x));
System.out.println("x.getClass() == Base.class " +
(x.getClass() == Base.class));
System.out.println("x.getClass() == Derived.class " +
(x.getClass() == Derived.class));
System.out.println("x.getClass().equals(Base.class)) "+
(x.getClass().equals(Base.class)));
System.out.println("x.getClass().equals(Derived.class)) " +
(x.getClass().equals(Derived.class)));
}
public static void main(String[] args) {
test(new Base());
test(new Derived());
}
}/* output:
Testing x of type class typeinfo.Base
x instanceof Base true
x instanceof Derived false
Base.isInstance(x) true
Derived.isInstance(x) false
x.getClass() == Base.class true
x.getClass() == Derived.class false
x.getClass().equals(Base.class)) true
x.getClass().equals(Derived.class)) false
Testing x of type class typeinfo.Derived
x instanceof Base true
x instanceof Derived true
Base.isInstance(x) true
Derived.isInstance(x) true
x.getClass() == Base.class false
x.getClass() == Derived.class true
x.getClass().equals(Base.class)) false
x.getClass().equals(Derived.class)) true
*/
test()方法使用了两种形式的instanceof作为参数来执行类型检查。然后获取Class引用,并用和equals()来检查Class对象是否相等。使人放心的是,instancof和isInstance()生成的结果完全一样,equals()和也一样。但是这两组测试得出的结论却不相同。instanceof保持了类型的概念,它指的是"你是这个类吗,或者你是这个类的派生类吗?"而如果用==比较实际的Class 对象,就没有考虑继承—它或者是这个确切的类型,或者不是。
反射:运行时的类信息 如果不知道某个对象的确切类型,RTTI可以告诉你。但是有一个限制;这个类型在编译时必须已知,这样才能使用RTTI识别它,并利用这些信息做一些有用的事。换句话说,在编译时,编译器必须知道所有要通过RTTI来处理的类。
当通过反射与一个未知类型的对象打交道时,JVM只是简单地检查这个对象,看它属于哪个特定的类(就像RTTI那样)。在用它做其他事情之前必须先加载那个类的Class对象。因此,那个类的.class文件对于JVM来说必须是可获取的∶要么在本地机器上,要么可以通过网络取得。所以RTTI和反射之间真正的区别只在于,对RTTI来说,编译器在编译时打开和检查.class文件。(换句话说,我们可以用"普通"方式调用对象的所有方法。)而对于反射机制来说,.class文件在编译时是不可获取的,所以是在运行时 打开和检查.class文件。
通常你不需要直接使用反射工具,但是它们在你需要创建更加动态的代码时会很有用。反射在Java中是用来支持其他特性的,例如对象序列化和JavaBean(它们在本书稍后部分都会提到)。但是,如果能动态地提取某个类的信息有的时候还是很有用的。请考虑类方法提取器,代码如下:
public class ShowMethods {
private static String usage =
"usage:\n" +
"ShowMethods qualified.class.name\n" +
"To show all methods in class or:\n" +
"ShowMethods qualified.class.name word\n" +
"To search for methods involving 'word'";
private static Pattern p = Pattern.compile("\\w+\\.");
public static void main(String[] args) {
args = new String[]{"typeinfo.ShowMethods"};
if(args.length < 1) {
System.out.println(usage);
System.exit(0);
}
int lines = 0;
try {
Class<?> c = Class.forName(args[0]);
Method[] methods = c.getMethods();
Constructor[] ctors = c.getConstructors();
if(args.length == 1) {
for(Method method : methods)
System.out.println(
p.matcher(method.toString()).replaceAll(""));
for(Constructor ctor : ctors)
System.out.println(p.matcher(ctor.toString()).replaceAll(""));
lines = methods.length + ctors.length;
} else {
for(Method method : methods)
if(method.toString().indexOf(args[1]) != -1) {
System.out.println(
p.matcher(method.toString()).replaceAll(""));
lines++;
}
for(Constructor ctor : ctors)
if(ctor.toString().indexOf(args[1]) != -1) {
System.out.println(p.matcher(
ctor.toString()).replaceAll(""));
lines++;
}
}
} catch(ClassNotFoundException e) {
System.out.println("No such class: " + e);
}
}
}/** output:
public static void main(String[])
public final void wait() throws InterruptedException
public final void wait(long,int) throws InterruptedException
public final native void wait(long) throws InterruptedException
public boolean equals(Object)
public String toString()
public native int hashCode()
public final native Class getClass()
public final native void notify()
public final native void notifyAll()
public ShowMethods()
*/
Class的getMethods()和getConstructors()方法分别返回Method对象的数组和Constructor 对象的数组。这两个类都提供了深层方法,用以解析其对象所代表的方法,并获取其名字、输入参数以及返回值。但也可以像这里一样,只使用toString(生成一个含有完整的方法特征签名的字符串。代码其他部分用于提取命令行信息,判断某个特定的特征签名是否与我们的目标字符串相符(使用indexOf(O)),并使用正则表达式去掉了命名修饰词。
Class.forName()生成的结果在编译时是不可知的,因此所有的方法特征签名信息都是在执行时被提取出来的。如果研究一下JDK文档中关于反射的部分,就会看到,反射机制提供了足够的支持,使得能够创建一个在编译时完全未知的对象,并调用此对象的方法。
动态代理 代理是基本的设计模式之一,它是你为了提供额外的或不同的操作,而插入的用来代替"实际"对象的对象。这些操作通常涉及与"实际"对象的通信,因此代理通常充当着中间人的角色。下面是一个用来展示代理结构的简单示例∶
interface Interface {
void doSomething();
void somethingElse(String arg);
}
class RealObject implements Interface {
public void doSomething() {
System.out.println("doSomething"); }
public void somethingElse(String arg) {
System.out.println("somethingElse " + arg);
}
}
class SimpleProxy implements Interface {
private Interface proxied;
public SimpleProxy(Interface proxied) {
this.proxied = proxied;
}
public void doSomething() {
System.out.println("SimpleProxy doSomething");
proxied.doSomething();
}
public void somethingElse(String arg) {
System.out.println("SimpleProxy somethingElse " + arg);
proxied.somethingElse(arg);
}
}
public class SimpleProxyDemo {
public static void consumer(Interface iface) {
iface.doSomething();
iface.somethingElse("bonobo");
}
public static void main(String[] args) {
consumer(new RealObject());
consumer(new SimpleProxy(new RealObject()));
}
}/** output:
doSomething
somethingElse bonobo
SimpleProxy doSomething
doSomething
SimpleProxy somethingElse bonobo
somethingElse bonobo
*/
因为consumer()接受的Interface,所以它无法知道正在获得的到底是RealObject还是SimpleProxy,因为这二者都实现了Interface。但是SimpleProxy已经被插入到了客户端和RealObject之间,因此它会执行操作,然后调用RealObject上相同的方法。
在任何时刻,只要你想要将额外的操作从"实际"对象中分离到不同的地方,特别是当你希望能够很容易地做出修改,从没有使用额外操作转为使用这些操作,或者反过来时,代理就显得很有用(设计模式的关键就是封装修改——因此你需要修改事务以证明这种模式的正确性)。例如,如果你希望跟踪对RealObject中的方法的调用,或者希望度量这些调用的开销,那么你应该怎样做呢?这些代码肯定是你不希望将其合并到应用中的代码,因此代理使得你可以很容易地添加或移除它们。
Java的动态代理比代理的思想更向前迈进了一步,因为它可以动态地创建代理并动态地处理对所代理方法的调用。在动态代理上所做的所有调用都会被重定向到单一的调用处理器上,它的工作是揭示调用的类型并确定相应的对策。下面是用动态代理重写的SimpleProxyDemojava∶
class DynamicProxyHandler implements InvocationHandler {
private Object proxied;
public DynamicProxyHandler(Object proxied) {
this.proxied = proxied;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object invoke = method.invoke(proxied, args);
System.out.println("**** proxy: " + proxy.getClass() +
", method: " + method + ", args: " + args);
if(args != null)
for(Object arg : args)
System.out.println(" " + arg);
return invoke;
}
}
public class SimpleDynamicProxy {
public static void consumer(Interface iface) {
iface.doSomething();
iface.somethingElse("bonobo");
}
public static void main(String[] args) {
RealObject real = new RealObject();
consumer(real);
// Insert a proxy and call again:
Interface proxy = (Interface) Proxy.newProxyInstance( // 通过调用静态方法Proxy.newProxyInstance()可以创建动态代理
Interface.class.getClassLoader(), // 需要一个类加载器参数
new Class[]{ Interface.class }, // 需要一个你希望该代理实现的接口列表(不是类或抽象类)
new DynamicProxyHandler(real)); // 以及一个InvocationHandler接口的实现
// 动态代理可以将所有的调用重定向到调用处理器,因此通常会向调用处理器的构造器传递一个“实际”对象的引用
// 从而使得调用处理器在执行其中介任务时,可以将请求转发
consumer(proxy);
}
}/** output:
doSomething
somethingElse bonobo
doSomething
**** proxy: class typeinfo.proxy.$Proxy0, method: public abstract void typeinfo.proxy.Interface.doSomething(), args: null
somethingElse bonobo
**** proxy: class typeinfo.proxy.$Proxy0, method: public abstract void typeinfo.proxy.Interface.somethingElse(java.lang.String), args: [Ljava.lang.Object;@2503dbd3
bonobo
*/
通过调用静态方法Proxy.newProxyInstance()可以创建动态代理,这个方法需要得到一个类加载器(你通常可以从已经被加载的对象中获取其类加载器,然后传递给它),一个你希望该代理实现的接口列表(不是类或抽象类),以及InvocationHandler接口的一个实现。动态代理可以将所有调用重定向到调用处理器,因此通常会向调用处理器的构造器传递给一个"实际"对象的引用,从而使得调用处理器在执行其中介任务时,可以将请求转发。
invoke()方法中传递进来了代理对象,以防你需要区分请求的来源,但是在许多情况下,你并不关心这一点。然而,在invoke())内部,在代理上调用方法时需要格外当心,因为对接口的调用将被重定向为对代理的调用。 通常,你会执行被代理的操作,然后使用Method.invoke())将请求转发给被代理对象,并传入必需的参数。
第十五章:泛型简单泛型我们希望达到的目的是编写更通用的代码,要使代码能够应用于“某种不具体的类型”,而不是一个具体的接口或类。
有许多原因促进了泛型的出现,而最引人注目的一个原因,就是为了创建容器类。有些情况下,我们确实希望容器能够同时持有多种类型的对象。但是,通常而言,我们只会使用容器类来存储一种类型的对象。泛型的主要目的之一就是用来指定容器要持有什么类型的对象,而且由编译器来保证类型的正确性。
一个元组库类 仅一次方法调用就能返回多个对象,你应该经常需要这样的功能吧。可是return语句只允许返回单个对象,因此,解决办法就是创建一个对象,用它来持有想要返回的多个对象。当然,可以在每次需要的时候,专门创建一个类来完成这样的工作。可是有了泛型,我们就能够一次性地解决该问题,以后再也不用在这个问题上浪费时间了。同时,我们在编译期就能确保类型安全。
这个概念称为元组(tuple),它是将一组对象直接打包存储于其中的一个单一对象。这个容器对象允许读取其中元素,但是不允许向其中存放新的对象。(这个概念也称为数据传送对象,或信使。)
通常,元组可以具有任意长度,同时,元组中的对象可以是任意不同的类型。不过,我们希望能够为每一个对象指明其类型,并且从容器中读取出来时,能够得到正确的类型。要处理不同长度的问题,我们需要创建多个不同的元组。下面的程序是一个2维元组,它能够持有两个对象∶
public class TwoTuple<A, B> {
public final A first;
public final B second;
public TwoTuple(A a, B b) {
first = a;
second = b;
}
// 注意:元组隐含地保持了其中元素的次序
public String toString() {
return "(" + first + ", " + second + ")";
}
}
构造器捕获了要存储的对象,而toString()是一个遍历函数,用来显示列表中的值。注意:元组隐含地保持了其中元素的次序。
我们可以利用继承机制实现长度更长的元组,从下面的例子中可以看到,增加类型参数是件很简单的事情:
/**
* 三维元组
*/
public class ThreeTuple<A, B, C> extends TwoTuple<A, B> {
public final C third;
public ThreeTuple(A a, B b, C third) {
super(a, b);
this.third = third;
}
@Override
public String toString() {
return "(" + first + ", " + second + ", " + third + ")";
}
}
/**
* 四维元组
*/
public class FourTuple<A,B,C,D> extends ThreeTuple<A,B,C> {
public final D fourth;
public FourTuple(A a, B b, C c, D d) {
super(a, b, c);
fourth = d;
}
public String toString() {
return "(" + first + ", " + second + ", " +
third + ", " + fourth + ")";
}
}
/**
* 五维元组
*/
public class FiveTuple<A,B,C,D,E> extends FourTuple<A,B,C,D> {
public final E fifth;
public FiveTuple(A a, B b, C c, D d, E e) {
super(a, b, c, d);
fifth = e;
}
public String toString() {
return "(" + first + ", " + second + ", " +
third + ", " + fourth + ", " + fifth + ")";
}
}
为了使用元组,你只需要定义一个长度适合的元组,将其作为方法的返回,然后在return语句中创建该元组,并返回即可。
class Amphibian {}
class Vehicle {}
public class TupleTest {
static TwoTuple<String,Integer> f() {
// Autoboxing converts the int to Integer:
return new TwoTuple<>("hi", 47);
}
static ThreeTuple<Amphibian,String,Integer> g() {
return new ThreeTuple<>(new Amphibian(), "hi", 47);
}
static FourTuple<Vehicle,Amphibian,String,Integer> h() {
return new FourTuple<>(new Vehicle(), new Amphibian(), "hi", 47);
}
static FiveTuple<Vehicle,Amphibian,String,Integer,Double> k() {
return new FiveTuple<>(new Vehicle(), new Amphibian(), "hi", 47, 11.1);
}
public static void main(String[] args) {
TwoTuple<String,Integer> ttsi = f();
System.out.println(ttsi);
// ttsi.first = "there"; // Compile error: final
System.out.println(g());
System.out.println(h());
System.out.println(k());
}
}
public class LinkedStack<T> {
private static class Node<U> {
U item;
Node<U> next;
Node() { item = null; next = null; }
Node(U item, Node<U> next) {
this.item = item;
this.next = next;
}
boolean end() { return item == null && next == null; }
}
// 末端哨兵
private Node<T> top = new Node<T>();
public void push(T item) {
top = new Node<T>(item, top);
}
public T pop() {
T result = top.item;
if(!top.end())
top = top.next;
return result;
}
public static void main(String[] args) {
LinkedStack<String> lss = new LinkedStack<>();
for(String s : "Phasers on stun!".split(" "))
lss.push(s);
String s;
while((s = lss.pop()) != null)
System.out.println(s);
}
}
内部类Node也是一个泛型,它拥有自己的类型参数。
这个例子使用了一个末端哨兵(end sentinel)来判断堆栈何时为空。这个末端哨兵是在构造LinkedStack时创建的。然后,每调用一次push()方法,就会创建一个Node<T>对象,并将其链接到前一个Node<T>对象。当你调用pop()方法时,总是返回top.item,然后丢弃当前top所指的Node<T>,并将top转移到下一个Node<T>,除非你已经碰到了未端哨兵,这时候就不再移动top了。如果已经到了末端,客户端程序还继续调用pop()方法,它只能得到null,说明堆栈已经空了。
到目前为止,我们看到的泛型,都是应用于整个类上。但同样可以在类中包含参数化方法,而这个方法所在的类可以是泛型类,也可以不是泛型类。 也就是说,是否拥有泛型方法,与其所在的类是否是泛型没有关系。
泛型方法使得该方法能够独立于类而产生变化。以下是一个基本的指导原则:无论何时,只要你能做到,你就应该尽量使用泛型方法。也就是说,如果使用泛型方法可以取代将整个类泛型化,那么就应该只使用泛型方法,因为它可以使事情更清楚明白。另外,对于一个static的方法而言,无法访问泛型类的类型参数,所以,如果static方法需要使用泛型能力,就必须使其成为泛型方法。
要定义泛型方法,只需将泛型参数列表置于返回值之前,就像下面这样:
public class GenericMethods {
// 泛型方法
// <T> 叫做类型参数
public <T> void f(T t) {
System.out.println(t.getClass().getSimpleName());
}
public static void main(String[] args) {
GenericMethods gen = new GenericMethods();
gen.f("");
gen.f(1);
gen.f(1.0);
gen.f(1.0F);
gen.f('c');
gen.f(gen);
}
}
泛型方法与可变参数列表能够很好地共存
public class GenericVarargs {
public static <T> List<T> makeList(T... args) {
List<T> result = new ArrayList<>();
for (T arg : args) {
result.add(arg);
}
return result;
}
public static void main(String[] args) {
List<String> list = makeList("A");
System.out.println(list);
list = makeList("A", "B", "C");
System.out.println(list);
list = makeList("ABCDEFGHIGKLMNOPQRSTUVWXYZ".split(""));
System.out.println(list);
}
}
// makeList()展示了与标准类型中java.util.Arrays.asList()方法相同的功能
public class Sets {
/**
* 将两个参数合并在一起,即并集
*/
public static <T> Set<T> union(Set<T> a, Set<T> b) {
Set<T> result = new HashSet<T>(a);
result.addAll(b);
return result;
}
/**
* @return 返回两个参数共有的部分,即取交集
*/
public static <T> Set<T> intersection(Set<T> a, Set<T> b) {
Set<T> result = new HashSet<T>(a);
result.retainAll(b);
return result;
}
/**
* 从superset中移除subset包含的元素,既取差集
* @return
*/
public static <T> Set<T> difference(Set<T> superset, Set<T> subset) {
Set<T> result = new HashSet<T>(superset);
result.removeAll(subset);
return result;
}
/**
*
* @return 返回除了交集之外的所有元素
*/
public static <T> Set<T> complement(Set<T> a, Set<T> b) {
return difference(union(a, b), intersection(a, b));
}
}
在前三个方法中,都将第一个参数Set复制了一份,将Set中的所有引用都存入一个新的 HeshSet对象中,因此,我们并未直接修改参数中的Set。返回的值是一个全新的Set对象。这四个方法表达了如下的数学集合操:union()返回一个Set,它将两个参数合并在一起, intersection()返回的Set只包含两个参数共有的分;difference()方法从superset中移除subset包的元素;complement()返回的Set包含除了交集之外的所有元素。
擦除的神秘之处由于Java泛型是通过擦除来实现的,这意味着当你在使用泛型时,任何具体类型都被擦除了,你唯一知道的就是你在使用一个对象。因此,List
边界使得你可以在用于泛型的参数类型上设置限制条件,尽管这使得你可以强制规定泛型可以应用的类型,但是其潜在的一个更重要的效果是你可以按照自己的边界类型来调用方法。
因为擦除移除了类型信息,所以可以用无界泛型参数调用的方只是那些可以用Object调用的方法。但是,如果能够将这个参数限制为某个类型子集,那么你就可以用这些类型子集来调用方法。为了执行这种限制,Java泛型 重用了extends关键字。如<T extends HasColor>,我们就说泛型类型参数将它擦除到它的第一个边界(它可能y有多个边界),编译器实际上会把类型参数替换为它的擦除,就好像用HasColor替换掉T一样。
擦出的代价是显著的,泛型不能用于显示地引用运行时类型的操作之中,例如转型、instanceof操作和new表达式。由于擦除丢失了在泛型代码中执行某些操作的能力,任何在运行时需要知道确认类型信息的操作都将无法工作。
public class Erased<T> {
private final int SIZE = 100;
public static void f(Object arg) {
if (arg instanceof T) {} // ERROR
T var = new T(); // EROOR
T[] array = new T[SIZE]; // Error
}
}
在上述代码中,new T()无法实现,部分原因是因为擦除,而另一部分原因是因为编译器不能验证T具有无参构造器。
关于泛型问题就写到这里了,书中用了大量的篇幅来讲述泛型擦除的问题,有兴趣的小伙伴建议阅读原书,由于这块的内容写起来也晦涩难懂,需要多写测试代码去运行看效果,这里就不再用文字赘述了。
第十六章:数组Java中已经有了容器,为什么还需要数组呢,是因为数组可以持有基本类型吗?但是在泛型出来之后,通过自动包装机制,其实通过容器也能够持有基本类型。在Jav中,数组是一种效率最高的存储和随机访问对象引用序列的方式。数组就是一个简单的线性用,这使得元素访问非常快速。但是为这种速度所付出的代价是数组对象的大小被固定,并其生命周期中不可改变。
在java.util类库中可以找到Arrays类,它有一套用于数组的static实用方法,其中有六个基本方法,equals()用于比较两个数组是否相等(deepEquals()用于多位数组),fill()为数组填充数据,sort()用于对数组的排序;binarySearch()用于在已排序的数组中查找元素。
Java标准类库提供有static方法System.arrayCopy(),用它赋值数组比for循环赋值要快很多,System.arrayCopy()针对所有类型做了重载。arrayCopy()需要的参数有:源数组,表示从源数组中的什么位置开始赋值的偏移量,表示从目标数组的什么位置开始复制的偏移量,以及需要赋值的元素的个数。如果是复制对象数组,这里做得是浅复制。而且System.arrayCopy()不会执行自动拆包和自动装包,所以两个数组必须具有相同的确切类型。
总结目前进度也只看到了第十六章,后面会持续更新,目前的打算是想把整本书通读完后,再对书中使用到设计模式的代码都再敲一次,并上传到我的码云。本书后面的内容都比较重要,分别是容器的深入研究、Java I/O系统,注解、并发。最后一章是图形化用户界面,这一章我也不打算看,主要是讲的Swing组件,因为这章的内容对我来说几乎没什么接触,所以就暂时略过吧。
第一章到第十章的内容:《Java编程思想》读书笔记一
本文原创自自由互联文章,想了解Java相关知识,欢迎到我的博客踩踩~ 地址:https://www.cnblogs.com/reminis/