如果你执意追逐我的幻影,迟早会被真正的我打败。
https://www.ylcoder.top/post/1649241412
概述工作队列(又称任务队列)的主要思想是避免立即执行资源密集型任务,我们可以在安排任务之后再执行。
我们把任务封装为消息并将其发送到队列,在后台运行的工作进程将弹出任务,并最终执行作业。
当有多个工作线程时,这些工作线程将一起处理这些任务。
轮询分发消息在这里案例中我们会启动两个工作线程,一个消息发送线程
源码:https://github.com/yltrcc/rabbitmq-demo/tree/master/demo2/src/main/java/com/yltrcc/demo
不公平分发轮询分发在某些场景下并不是很好。
例子:比如有两个消费者在处理任务,其中有1个消费者1处理任务非常快,另外一个消费者2处理速度很慢。
这个时候采用轮询分发,速度快的消费者1很大部分时间处于空闲状态,处理慢的消费者2一直在处理。
这种情况下其实不太好,但是RabbitMQ不知道,它依然很公平的进行分发。
为了避免这种情况,我们可以设置参数
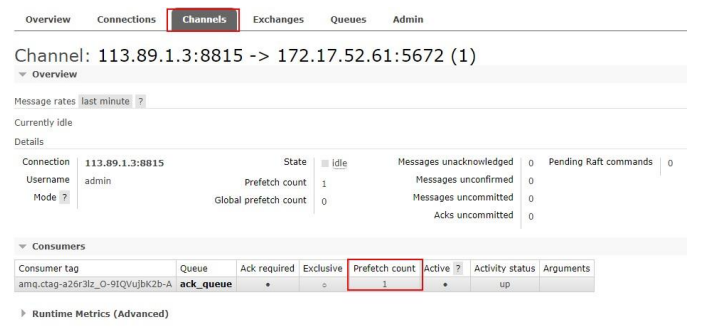
它的意思是:这个任务我还没有处理完或者我还没有应答你,你先别分配给我,我目前只能处理一个任务,然后RabbitMQ就会把任务分配给没有那么忙的那个空闲消费者。
当然如果所有的消费者都没有完成手上的任务,队列还在不停的添加新任务,队列有可能就会遇到队列被撑满的情况,这个时候就只能添加新的worker或者改变其他存储任务的策略。
预取值本身消息的发送就是异步发送的,所以在任何时候,channel 上肯定不止只有一个消息另外来自消费者的手动确认本质上也是异步的。
因此这里就存在一个未确认的消息缓冲区,因此希望开发人员能限制此缓冲区的大小,以避免缓冲区里面无限制的未确认消息问题。
这个时候就可以通过使用** basic.qos 方法设置“预取计数”值来完成的。该值定义通道上允许的未确认消息的最大数量**。一旦数量达到配置的数量,
RabbitMQ 将停止在通道上传递更多消息,除非至少有一个未处理的消息被确认。
例如,假设在通道上有未确认的消息 5、6、7,8,并且通道的预取计数设置为 4,此时RabbitMQ 将不会在该通道上再传递任何消息,除非至少有一个未应答的消息被 ack。
比方说 tag=6 这个消息刚刚被确认 ACK,RabbitMQ 将会感知这个情况到并再发送一条消息。
消息应答和 QoS 预取值对用户吞吐量有重大影响。通常,增加预取将提高向消费者传递消息的速度。
面试题 String和StringBuilder、StringBuffer的区别?String是只读字符串,String 的底层是一个 char[] 通过final关键字进行修饰,所以说它的内容是不能被改变的。
StringBuilder是Java 5中引入的,它和StringBuffer的方法完全相同,
区别在于它是在单线程环境下使用的,因为它的所有方面都没有被synchronized修饰,因此它的效率也比StringBuffer要高。
字符串的+操作其本质是创建了StringBuilder对象进行append操作,然后将拼接后的StringBuilder对象用toString方法处理成String对象,
这一点可以用javap -c Test.class命令获得class文件对应的JVM字节码指令就可以看出。
# 列出所有的key
redis> keys *
# 列出匹配的key
redis>keys apple*
1) apple1
2) apple2
https://leetcode-cn.com/problems/two-sum/
题目描述给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
0 <= s.length <= 5 * (10 ^ 4)
s 由英文字母、数字、符号和空格组成
用一个例子考虑如何在较优的时间复杂度内通过本题。
以示例一中的字符串abcabcbb为例,找出从每一个字符开始的,不包含重复字符的最长子串,那么其中最长的那个字符串即为答案。
对于示例一中的字符串,我们列举出这些结果,其中括号中表示选中的字符以及最长的字符串:
- 以 (a)bcabcbb 开始的最长字符串为 (abc)abcbb;
- 以 a(b)cabcbb 开始的最长字符串为 a(bca)bcbb;
- 以 ab(c)abcbb 开始的最长字符串为 ab(cab)cbb;
- 以 abc(a)bcbb 开始的最长字符串为 abc(abc)bb;
- 以 abca(b)cbb 开始的最长字符串为 abca(bc)bb;
- 以 abcab(c)bb 开始的最长字符串为 abcab(cb)b;
- 以 abcabc(b)b 开始的最长字符串为 abcabc(b)b;
- 以 abcabcb(b) 开始的最长字符串为 abcabcb(b);
如果我们依次递增地枚举子串的起始位置,那么子串的结束位置也是递增的!这里的原因在于,假设我们选择字符串中的第 k 个字符作为起始位置,并且得到了不包含重复字符的最长子串的结束位置为 r_k。
那么当我们选择第 k+1 个字符作为起始位置时,首先从 k+1 到 r_k的字符显然是不重复的,并且由于少了原本的第 k 个字符,我们可以尝试继续增大 r_k,直到右侧出现了重复字符为止。
这样一来,我们就可以使用「滑动窗口」来解决这个问题了:
- 我们使用两个指针表示字符串中的某个子串(或窗口)的左右边界,其中左指针代表着上文中「枚举子串的起始位置」,而右指针即为上文中的 r_k;
- 在每一步的操作中,我们会将左指针向右移动一格,表示 我们开始枚举下一个字符作为起始位置,然后我们可以不断地向右移动右指针,但需要保证这两个指针对应的子串中没有重复的字符。在移动结束后,这个子串就对应着 以左指针开始的,不包含重复字符的最长子串。我们记录下这个子串的长度;
- 在枚举结束后,我们找到的最长的子串的长度即为答案。
判断重复字符
在上面的流程中,我们还需要使用一种数据结构来判断 是否有重复的字符,常用的数据结构为哈希集合(即 C++ 中的 std::unordered_set,Java 中的 HashSet,Python 中的 set, JavaScript 中的 Set)。在左指针向右移动的时候,我们从哈希集合中移除一个字符,在右指针向右移动的时候,我们往哈希集合中添加一个字符。
class Solution {
public int lengthOfLongestSubstring(String s) {
// 哈希集合,记录每个字符是否出现过
Set<Character> occ = new HashSet<Character>();
int n = s.length();
// 右指针,初始值为 -1,相当于我们在字符串的左边界的左侧,还没有开始移动
int rk = -1, ans = 0;
for (int i = 0; i < n; ++i) {
if (i != 0) {
// 左指针向右移动一格,移除一个字符
occ.remove(s.charAt(i - 1));
}
while (rk + 1 < n && !occ.contains(s.charAt(rk + 1))) {
// 不断地移动右指针
occ.add(s.charAt(rk + 1));
++rk;
}
// 第 i 到 rk 个字符是一个极长的无重复字符子串
ans = Math.max(ans, rk - i + 1);
}
return ans;
}
}
复杂度分析
- 时间复杂度:O(N)O(N),其中 NN 是字符串的长度。左指针和右指针分别会遍历整个字符串一次。
- 空间复杂度:O(∣Σ∣),其中 Σ 表示字符集(即字符串中可以出现的字符),∣Σ∣ 表示字符集的大小。在本题中没有明确说明字符集,因此可以默认为所有 ASCII 码在[0,128) 内的字符,即 ∣Σ∣=128。我们需要用到哈希集合来存储出现过的字符,而字符最多有 ∣Σ∣ 个,因此空间复杂度为O(∣Σ∣)。
你好,我是yltrcc,日常分享技术点滴,欢迎关注我:ylcoder