PSI在知乎上看到大佬写的关于论文:Efficient Batched Oblivious PRF with Applications to Private Set Intersection的讲解,循序渐进,在这里摘抄一下学习。来自:隐私计算关键技术:隐私集合求交(PSI)原理介绍和隐私计算关键技术:隐私集合求交(PSI)的性能扩展。对应的开源库。
本文是基于OT的两方PSI。
隐私集合求交(Private Set Intersection)是纵向联邦学习中的关键前置步骤,用于在多家厂商联合计算前,找到多家共有的数据样本,并且不暴露每家厂商独有的样本。在本文中,我们详细介绍一种使用不经意传输协议(Oblivious Transfer)实现的隐私集合求交方法,该方法在现有的PSI方法中,是速度最快的。
纵向联邦学习纵向联邦,即样本大多相同,特征不同。
假设这样一个场景,淘宝和知乎联合起来训练一个模型,预测一个用户是否对科技类产品感兴趣。淘宝有用户A、B、C三个人的购买历史数据,而知乎有B、C、D三个人的知乎文章浏览数据。使用纵向联邦学习,在淘宝和知乎都不泄露各自的用户数据前提下,我们可以整合B、C两个人的淘宝和知乎数据特征,共同训练一个预测模型,由于使用到了两类数据进行训练,理论上来说得到的结果应该比淘宝或者知乎各自训练出的模型更准确。
由于模型训练需要同时使用淘宝和知乎的数据,我们发现用户A仅仅有淘宝的数据,没有知乎的数据,因此用户A无法做为训练样本使用。同样的,知乎的用户D也无法参与训练。因此在纵向联邦学习之前,双方需要计算出共有的样本(数据对齐),也就是B、C两人,后续的计算都围绕BC两人进行。而隐私集合求交就是双方通过加密计算,得到B、C两人这个集合,同时不暴露各自的原始集合的方法。
PSI+hashPSI是指,参与双方在不泄露任何额外信息的情况下,得到双方持有数据的交集。在这里,额外的信息指的是除了双方的数据交集以外的任何信息。
隐私集合求交在现实场景中非常有用,比如在纵向联邦学习中做数据对齐,或是在社交软件中,通过通讯录做好友发现(QQ好友推荐)。因此,一个安全、快速的隐私集合求交的算法是十分重要的。
我们可以用一种非常直观的方法来进行隐私集合求交,也就是朴素哈希(simple hash)的方法。参与双方A、B,使用同一个哈希函数H,计算他们数据的哈希值,再将哈希过的数据互相发送给对方,然后就能求得交集了。
这种方法看起来非常简单、快速,但是,它是不安全的,有可能会泄露额外的信息。如果参与双方需要求交集的数据本身,数据空间比较小,比如说手机号、身份证号等,那么,一个恶意的参与方,就可以通过哈希碰撞的方式,在有限的时间内,碰撞出对方传过来的哈希值,从而窃取到额外的信息。因此,我们需要设计出更加安全的隐私集合求交的方法。
所以通过简单hash实现的PSI,虽然简单快速,但不安全。
现在已经有了很多种不同的方法来实现隐私集合求交,比如基于Diffie-Hellman密钥交换的方法、基于不经意传输的方法等等。而截至目前,最快速的隐私集合求交方法,是基于不经意传输的。下面,我们介绍如何使用不经意传输,来实现一个隐私集合求交算法。
PSI+OT OT目前最快的PSI还是基于OT的。
不经意传输是一种密码学协议,实现了发送将将潜在的许多信息中的一个传递给接收方,但是对接收方所接收的信息保持未知。
一种比较实用的不经意传输方案,被称为1-2不经意传输。在1-2不经意传输中,发送方持有两个数据,接收方可以选择获取其中的一个,但是发送方并不知道接收方选择了哪一个数据。形式化描述如下:
发送方A持有数据\(m_0\)和\(m_1\),接收方B持有一个比特\(b\),\(b\in{0,1}\),则1-2不经意传输可以描述为:
\[OT((m_0,m_1),b)=m_b \]其中,B只知道\(m_b\),不知道\(m_{1-b}\),而A也不知道\(b\)。
我们也可以将1-2不经意传输扩展为1-n不经意传输,即接收方能从n个数据中选择获取一个,且对发送方保密。
不经意传输也有很多种实现方式,不过一般都需要使用公私钥加密的方式来实现,比如RSA、椭圆曲线加密等。 在本篇文章中,我们不介绍具体的不经意传输协议,读者们可以把不经意传输当作是一个黑盒子,我们接下来详细介绍如何实用不经意传输,来构造一个隐私集合求交的方法。
使用OT我们先从最简单的情况开始。假设参与双方A、B,都只有一个元素,这时隐私集合求交,就退化成了隐私比较, 即A、B比较持有的元素是否相等,同时不泄露自己持有的元素。
我们假设A持有数据x,B持有数据x。不失一般性,我们假设x与y的字节长度相等,长度为\(l\),即\(|x|=|y|=l\)。 现在,A为数据x的每一位,都生成两个随机的二进制串(服从均匀分布),长度为\(n\),即\(K_{i,0},K_{i,1},i=(0,1,..,l-1),|K_{i,0}|=|K_{i,1}|=n\)。
现在,B作为接收方,A作为发送方,开始执行1-2不经意传输协议。B根据y的每一位\(y_i\),选择A持有的\(K_{i,0},K_{i,1}\)中的一个,即\(OT((K_{i,0},K_{i,1}),y_i)=K_{i,y_i},i=(0,1,..,l-1)\)。B将接收到的\(l\)个二进制串进行异或,得到一个二进制串\(K_y\),即\(K_y=\bigoplus K_{i,y_1},i=(0,1,..,l-1)\), 其中$\bigoplus $表示异或。
发送方A也可以跟B一样,根据x的每一位\(x_i\),选择一个二进制串\(K_{i,x_i}\),将这\(l\)个二进制串进行异或,得到一个二进制串\(K_x=\bigoplus K_{i,x_1},i=(0,1,..,l-1)\)。当然,A生成\(K_x\)的过程不需要使用不经意传输,因为x与K都在A的手中。
之后,A将\(K_x\)发送给B,B即可判断x与y是否相等。
这个隐私比较的方法,显然是安全的。
B使用不经意传输获得\(K_y\)的过程中,由于不经意传输的特性,A不会知道B的数据y;使用异或得到的\(K_x\)与\(K_y\),与一个随机的n位二进制串是无法区分的,所以B也无法通过\(K_x\)反推出x。A作为发送方,不经意传输保证了A无法得到B的数据y(除非\(x=y\));只要B是诚实的,即不能通过不断执行这个协议来碰撞A的数据,那么B也无法得到A的数据x(除非\(x=y\))。
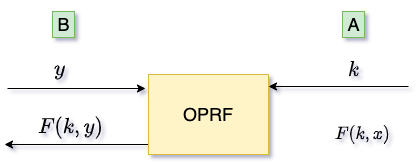
PSI+OPRF(OT) OPRF观察隐私比较,我们可以发现,发送方A持有一组二进制串\(K_{i,0},K_{i,1},i=(0,1,..,l-1)\),我们可以将这些二进制串整体当作一个随机种子\(K\),由A持有。从B的角度来看,隐私比较的过程,就是B输入数据y,得到一个随机二进制串\(K_y\),这个二进制串由A持有的随机种子\(K\)与输入y来决定,同时A无法得知B的输入y。这一过程,就可以看作是不经意伪随机函数(Oblivious Pseudorandom Function, OPRF)。
不经意伪随机函数是一种密码学协议[3],发送方可以选择一个随机种子\(s\),接收方可以选择一个输入\(r\)并得到一个伪随机函数\(F(s,r)\)的输出,同时发送方不知道\(r\)。那么,隐私比较中,接收方B就是执行了一个不经意伪随机函数\(F(k,y)=K_y\),发送方A可以执行一个普通的伪随机函数\(F(k,x)=K_x\),通过比较\(K_x\)和\(K_y\),即可实现隐私比较。
这样来看,我们就是使用不经意伪随机函数,来构建了一个隐私比较算法。接下来,我们要更进一步,看看如何使用不经意伪随机函数,来构建隐私集合求交。
使用OPRF这里的OPRF实际上是使用的OT协议实现的
假设A持有一组输入X,B持有一组输入Y,\(|X|=|Y|=n\)。通过不经意伪随机函数,我们可以构造出一个非常朴素的隐私集合求交算法:
- A构造\(n\)个不经意伪随机函数的种子\(k_i,i=(0,1,...,n-1)\)
- B为Y中的每一个元素y,执行一个对应不经意伪随机函数,得到集合\(H_B=(F(k_i,y_i)|y_i\in Y)\)
- A为X中的每一个元素x,执行每一个不经意伪随机函数,得到集合\(H_A=(F(k_i,x_i)|x_i\in X)\)
- A将集合\(H_A\)发送给B,B求交集\(H_A\bigcap H_B\),再将交集映射回Y,即可得到X与Y的交集
这种方法简单来讲,就是B将每一个Y中的每一个元素,都与A的X中的每一个元素,通过不经意伪随机函数进行隐私比较,进而得到X与Y的交集。
这种方法虽然直观,但是开销很大,因为集合\(H_A\)的大小是\(O(n^2)\),当集合大小n增长时,传输量增长很快。
单纯使用OPRF,会使得开销很大
那么,我们有没有办法将集合大小限制在\(O(n)\)呢?答案是可以的。这需要使用到哈希表的思想。这里,我们使用布谷鸟哈希(Cuckoo hashing)来解决这个问题。
PSI+OPRF(OT)+Cuckoo hash Cuckoo hash我们首先简单介绍一下布谷鸟哈希。
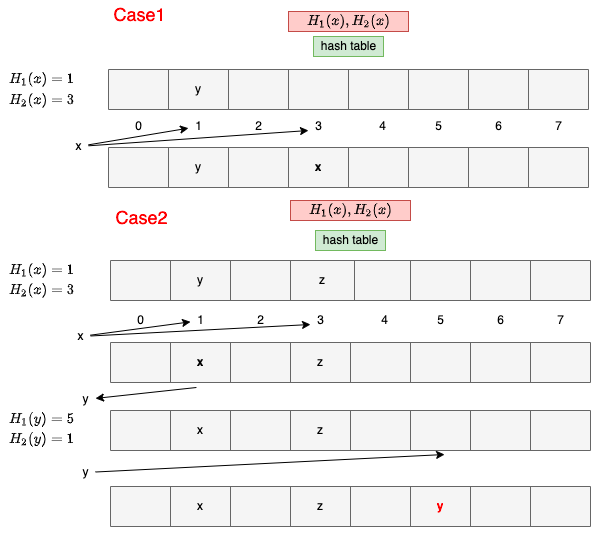
假设我们想要使用布谷鸟哈希,将n条数据放入\(b\)个桶中,则我们首先选择3个哈希函数\(h_1,h_2,h_3:(0,1)*->[b]\),以及b个空的桶\(B[1,...,b]\)。要放入一条数据\(x\),首先查看3个桶\(B[h_1],B[h_2],B[h_3]\)是否有空的(这里b=3),如果有空的,则将\(x\)放入空桶。如果没有空桶,则从这三个桶中随机选择一个桶\(B[h_i],i\in(1,2,3)\),踢出原来在这个桶中的元素\(x'\),并将x放进这个桶中,然后再继续尝试插入被踢出的元素\(x'\)。递归地执行这一过程,直到元素被放入一个空桶中。如果经过一定轮次后,仍然找不到空桶放入元素,那么就将被踢出的元素放到一个特殊的桶中,这个桶被称为储藏桶。
下图,case1就是任选一个空桶插入,case2若没有空桶,则踢出一个插入,然后重新选空位置插入
现在回到隐私集合求交的构建中,让我们看看如何在隐私集合求交中使用布谷鸟哈希。
首先,A、B双方共同选择三个哈希函数\(h_1,h_2,h_3\)。然后,B将其持有的\(n\)个元素Y,使用布谷鸟哈希,放入\(1.2n\)个桶与一个储藏桶中,储藏桶的大小为\(s\)。对B来说,现在每个桶中最多只有一个元素,并且储藏桶的中,最多有\(s\)个元素。现在B可以构造假数据,将这些桶和储藏桶都填满,使每个桶中都有一个元素,且储藏同中正好有\(s\)个元素。
然后,A可以生成\(1.2n+s\)个随机种子\(k_i,i\in(1,2,..,1.2n+s)\),用作\(1.2n+s\)个不经意伪随机函数的随机种子。B作为接收方,为其桶中的每一个元素\(y\),计算不经意伪随机函数。如果\(y\)被放在\(i\)号桶中,则计算\(F(k_i,y)\),如果\(y\)被放在了储藏桶中的第\(j\)个位置,则计算F\((k_{1.2n+j},y)\)。
发送方使用所有的hash函数,接收方任选一个hash函数使用
另一边,A作为发送方,可以任意地计算伪随机函数\(F(k_i,x)\),那么,A可以为其输入X计算以下两个集合:
\[H=(F(k_{h_i(x)},x)|x\in X,i={1,2,3}) \]\[S=(F(k_{1.2n+j},x)|x\in X,j={1,2,3,...,s}) \]A将集合\(H\)和集合\(S\)中的元素打乱,并将这两个集合发送给B。对于B来说,如果一个元素\(y\)被放到储藏桶中,则B可以在集合\(S\)中查找\(y\)对应的不经意伪随机函数输出;否则,就在集合\(H\)中查找。通过查找,就可以得到X与Y的交集。
通过计算,我们可以发现,集合\(H\)的大小为\(3n\),集合\(S\)的大小为\(ns\),\(s\)是一个常数,因此A需要传输的数据量为\(n(3+s)\),是\(O(n)\)的。通过结合布谷鸟哈希,我们减少了协议所需要传输的数据量,加快了协议的执行速度。
显然,使用不经意伪随机函数构造的隐私集合求交算法,是安全的。
由于不经意伪随机函数的特性,发送方A无法得知接收方B的输入。同时,对于集合\(X-Y\)中的元素,其经过伪随机函数的输出,与一个随机的二进制串无法区分,因此B也无法从伪随机函数的输出中反推出输入。在B是诚实的条件下(不能无限次地执行不经意伪随机函数来进行碰撞),这个协议是安全的。
使用OPRF,能抵抗恶意的接收者,虽然安全,但是效率并不高。
现在,我们已经成功地通过OPRF(基于OT),构造了一个安全的隐私集合求交算法。 但是这并不是结束,只是一个开始。因为我们构造的算法虽然安全,但是并不快速。
OPRF的实现有两种方式,一种是基于DH,一种是基于OT
在这里,影响隐私集合求交算法速度的主要因素,OPRF的执行速度。回顾上文的内容,在算法中,我们需要执行\(1.2n+s\)次不经意伪随机函数,而每个不经意伪随机函数,需要执行\(l\)次1-2不经意传输,\(l\)为求交集的元素的长度,所以,我们一共需要\(O(nl)\)次不经意传输。而不经意传输,是个很慢的操作,因为不经意传输需要使用到公私钥加密,公私钥加密本身就很慢。
根据现在的隐私集合求交的算法,算法的速度取决于求交集的集合元素数量\(n\),以及每个元素的大小\(l\)。这导致了当集合大小变得很大,或者集合中的元素变得很长时,算法的速度会越来越慢。
PSI+OPRF(OT extenstion)+Cuckoo hash快速的OT,实现快速的OPRF,进而构造快速的PSI!
上面PSI性能受限的主要原因就是求OPRF次数较多,导致OT次数较多,而OT又相对耗时间,所以在此去优化OT的次数,从而提升性能。要做到这一点,我们就需要引入一个新的方法,不经意传输扩展(Oblivious Transfer Extension, OTE)。能够用少量(常数次)“慢速”的不经意传输,来实现大量“快速”的不经意传输。下面,我就来介绍不经意传输扩展。
OT extention这里介绍的不经意传输扩展方法,来自文章[4]
不经意传输扩展的目标,是使用少量“慢速”的基础不经意传输,配合对称加密(之前是公钥加密),来实现大量“快速”的不经意传输。
没看太懂。。
参考[1] Kolesnikov V, Kumaresan R, Rosulek M, et al. Efficient batched oblivious PRF with applications to private set intersection[C]//Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. 2016: 818-829.
[2] Pinkas B, Schneider T, Segev G, et al. Phasing: Private set intersection using permutation-based hashing[C]//24th {USENIX} Security Symposium ({USENIX} Security 15). 2015: 515-530.
[3] Freedman M J, Ishai Y, Pinkas B, et al. Keyword search and oblivious pseudorandom functions[C]//Theory of Cryptography Conference. Springer, Berlin, Heidelberg, 2005: 303-324.
[4] Ishai Y, Kilian J, Nissim K, et al. Extending oblivious transfers efficiently[C]//Annual International Cryptology Conference. Springer, Berlin, Heidelberg, 2003: 145-161.
【本文转自:韩国服务器 http://www.558idc.com/kt.html提供,感谢支持】