awk是什么 awk是一个强大的linux命令,有强大的文本格式化的能力,好比将一些文本数据格式化成专业的excel表的样式。 再谈三剑客 grep,擅长单纯的查找或匹配文本内容 sed,更适合编辑
awk是一个强大的linux命令,有强大的文本格式化的能力,好比将一些文本数据格式化成专业的excel表的样式。
再谈三剑客
- grep,擅长单纯的查找或匹配文本内容
- sed,更适合编辑、处理匹配到的文本内容
- awk,更适合格式化文本内容,对文本进行复杂处理后、更友好的显示
awk 指令是由模式,动作,或者模式和动作的组合组成.
-
模式即 pattern,可以类似理解成 sed 的模式匹配,可以由表达式组成,也可以使两个正斜杠之间的正则表 达式.比如 NR==1,这就是模式,可以把他理解为一个条件.
-
动作即 action,是由在大括号里面的一条或多条语句组成,语句之间使用分号隔开,如下 awk 使用格式
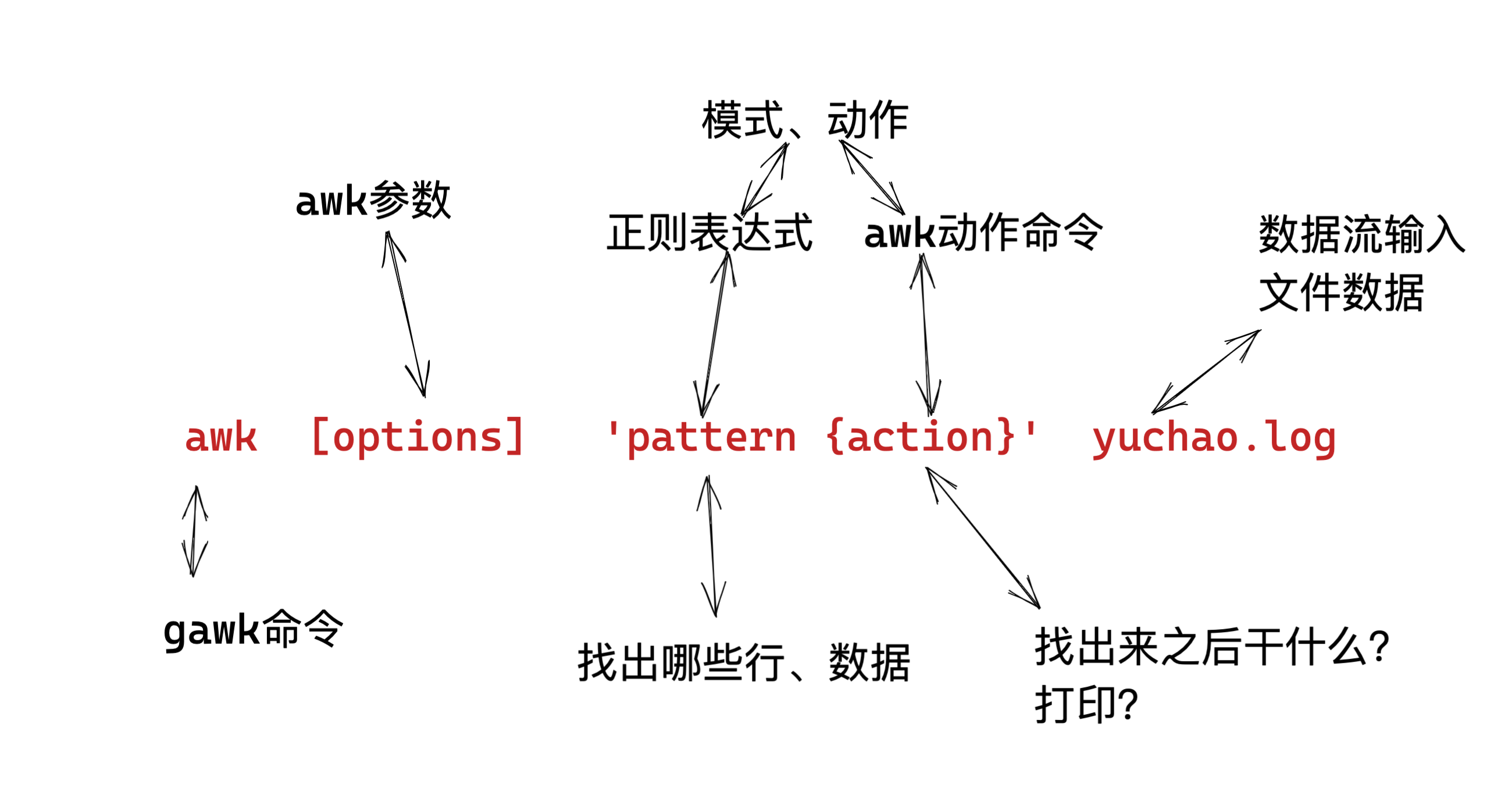
- Action指的是动作,awk擅长文本格式化,且输出格式化后的结果,因此最常用的动作就是
print
awk模式动作
生成测试数据
[root@nodel /tmp20:40:00]#echo cc{01..50} | xargs -n 5
cc01 cc02 cc03 cc04 cc05
cc06 cc07 cc08 cc09 cc10
cc11 cc12 cc13 cc14 cc15
cc16 cc17 cc18 cc19 cc20
cc21 cc22 cc23 cc24 cc25
cc26 cc27 cc28 cc29 cc30
cc31 cc32 cc33 cc34 cc35
cc36 cc37 cc38 cc39 cc40
cc41 cc42 cc43 cc44 cc45
cc46 cc47 cc48 cc49 cc50
[root@nodel /tmp20:44:28]#echo cc{01..50} | xargs -n 5 > ztd.log
[root@nodel /tmp20:44:59]#
初体验awk,提取第一列数据,仅使用打印动作
[root@nodel /tmp20:44:59]#awk '{print $1}' ztd.log
cc01
cc06
cc11
cc16
cc21
cc26
cc31
cc36
cc41
cc46
[root@nodel /tmp21:03:07]#
加上模式、和动作,比如指定行号
NR>=2&&NR<=5 是awk的模式,NR也是内置变量, 打印2-5行
[root@nodel /tmp21:03:07]#awk 'NR>=2&&NR<=5{print $0}' ztd.log
cc06 cc07 cc08 cc09 cc10
cc11 cc12 cc13 cc14 cc15
cc16 cc17 cc18 cc19 cc20
cc21 cc22 cc23 cc24 cc25
[root@nodel /tmp21:07:44]#
以及指定打印某个字段的数据,如$3
[root@nodel /tmp21:07:44]#awk 'NR>=2&&NR<=5{print $3}' ztd.log
cc08
cc13
cc18
cc23
[root@nodel /tmp21:09:37]#
限定模式、打印动作、以及显示对应行号
[root@nodel /tmp21:09:37]#awk 'NR>=2&&NR<=5{print $0.NR}' ztd.log
cc06 cc07 cc08 cc09 cc102
cc11 cc12 cc13 cc14 cc153
cc16 cc17 cc18 cc19 cc204
cc21 cc22 cc23 cc24 cc255
[root@nodel /tmp21:10:29]#
只有模式
awk不指定动作的话,默认打印整行信息
[root@nodel /tmp21:12:01]#awk 'NR>=2&&NR<=6' ztd.log
cc06 cc07 cc08 cc09 cc10
cc11 cc12 cc13 cc14 cc15
cc16 cc17 cc18 cc19 cc20
cc21 cc22 cc23 cc24 cc25
cc26 cc27 cc28 cc29 cc30
[root@nodel /tmp21:12:04]#
只有动作
没有模式,也就是没限定条件,
Awk默认处理所有行
[root@nodel /tmp21:14:24]#awk '{print $2}' ztd.log cc02 cc07 cc12 cc17 cc22 cc27 cc32 cc37 cc42 cc47 [root@nodel /tmp21:14:29]#
多个模式和动作
- 指定行,
NR==4,number of record,行号的记录 - 指定动作,
print $0,NF,NR- 内置变量$0表示整行数据
- NF表示Number of filed,字段的数量,表示这一行数据分了几列
- NR表示,number of record,行号的记录,表示在处理第几行
小结
- pattern和action都要用单引号,防止shell作特殊解释(是交给awk去执行的,而不是bash)
- 不指定模式,awk默认处理输入的文件数据,每一行,每一列
- 如果指定模式,例如指定的行,awk就处理指定那一行的数据
- awk的动作,必须写在花括号里
{print},括号里写入awk提供的命令。- 如果没有
{ }花括号,就会被识别为patter,而不是action
- 如果没有
- 注意给awk传入数据,一般都是file
- pattern和action都要用单引号,防止shell作特殊解释(是交给awk去执行的,而不是bash)
- 不指定模式,awk默认处理输入的文件数据,每一行,每一列
- 如果指定模式,例如指定的行,awk就处理指定那一行的数据
- awk的动作,必须写在花括号里
{print},括号里写入awk提供的命令。- 如果没有
{ }花括号,就会被识别为patter,而不是action
- 如果没有
- 注意给awk传入数据,一般都是file
小结
- pattern和action都要用单引号,防止shell作特殊解释(是交给awk去执行的,而不是bash)
- 不指定模式,awk默认处理输入的文件数据,每一行,每一列
- 如果指定模式,例如指定的行,awk就处理指定那一行的数据
- awk的动作,必须写在花括号里
{print},括号里写入awk提供的命令。- 如果没有
{ }花括号,就会被识别为patter,而不是action
- 如果没有
- 注意给awk传入数据,一般都是file
awk其他内置变量(翻译)
awk的其他内置变量如下。
FILENAME:当前文件名
FS:字段分隔符,默认是空格和制表符。
Input field separator variable.输入字段分隔符变量。
RS:行分隔符,用于分割每一行,默认是换行符。
Record Separator variable,行分隔符变量
OFS:输出字段的分隔符,用于打印时分隔字段,默认为空格。
Output Field Separator Variable,输出字段分隔符变量
ORS:输出记录的分隔符,用于打印时分隔记录,默认为换行符。
Output Record Separator Variable,输出记录分隔符变量
OFMT:数字输出的格式,默认为%.6g。
RS变量/ORS变量
OFS变量:Output Field Separator Variable,输出字段分隔符变量
RS变量: record separator,记录分隔符
图解awk执行的输入、输出
awk 对每个要处理的输入数据认为都是具有格式和结构的,而不仅仅是一堆字符串
默认情况下,每一行 内容都是一条记录,并以换行符分隔(\n)结束
- awk默认下,每一行就是每一个record(记录)
- RS 即 record separator 输入输入数据 ,表示每个记录输入的时候分隔符.即行与行之间如何分隔.
- NR 即 number of record 记录(行)号,表示当前正在处理的记录(行)的号码
- ORS 即 output record separator 输出记录分隔符
修改RS/修改awk输入显示
[root@nodel /tmp21:30:40]#head -2 ztd.log | awk -v RS=' ' '{print $0}'
cc01
cc02
cc03
cc04
cc05
cc06
cc07
cc08
cc09
cc10
修改ORS/修改awk输出显示
面试题,统计单词出现频率
I have a dog, it is lovely, it is called Mimi. Every time I go home from school, Mimi always cruising around me, I will go to the kitchen to get a piece of meat to it, it lay on the floor to eat. My legs and then jump to bark "Wang "called, so I picked up Mimi, it is the opportunity to lick my hand, making me laugh.I like Mimi, like puppies.代码思路
- 先让所有单词合并为1列,注意是一列、排成一队、然后排序,合并重复的,且统计重复次数
grep [root@nodel /opt17:30:53]#grep '[a-zA-Z]+' -E -o dog.txt |sort |uniq -c|sort -r 6 to 5 it 5 I 4 Mimi 3 the 3 is sed [root@nodel /opt17:33:06]#sed -nr 's#[^a-zA-Z]#\n#pg' dog.txt |sort |uniq -c|sort -r 6 to 5 it 5 I 4 Mimi 3 the awk [root@nodel /opt17:44:28]#awk -v RS='[^a-zA-Z]+' '{print $0}' dog.txt |sort |uniq -c|sort -r 6 to 5 it 5 I 4 Mimi 3 the 3 is