C++篇为本人学C++时所做笔记(特别是疑难杂点),全是硬货,虽然看着枯燥但会让你收益颇丰,可用作学习C++的一大利器
-
系统函数及其库是 C++语言所必须的,预处理命令不是 C++语言的必须组成部分
-
优先级比较:静态成员变量或静态代码块>main方法>非静态成员变量或非静态代码块>构造方法
-
C++不是类型安全的,因为支持强制类型转换;类型安全很大程度上可以等价于内存安全,类型安全的代码不会试图访问自己没被授权的内存区域
-
浮点数算术标准是ieee754
-
程序的动态性越强,内存管理就越重要,内存分配程序的选择也就更重要
-
C++真正正式公布的标准就三个:C++98、C++03、C++11
-
/..../中可以嵌套//注释,但不能嵌套/..../注释
-
Java和C++都是静态类型的面向对象编程语言
-
动态类型语言是指在运行期间才去做数据类型检查的语言,也就是说,在用动态类型的语言编程时,永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。静态类型语言与动态类型语言刚好相反,它的数据类型是在编译其间检查的,也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#、JAVA等
-
结构化程序设计的思想包括:自顶向下、逐步求精、模块化、限制使用 goto 语句
-
C++的实体通常有三类:变量或对象;函数;类型(结构体类型等)
-
每个程序单位由三部分组成:预处理指令,全局声明,函数
-
时间复杂度:评估执行程序所需的时间。可以估算出程序对处理器的使用程度
空间复杂度:评估执行程序所需的存储空间。可以估算出程序对计算机内存的使用程度 -
重入和不可重入:
这种情况出现在多任务系统当中,在任务执行期间捕捉到 信号 并对其进行处理时,进程正在执行的指令序列就被信号处理程序临时中断 。如果从信号处理程序返回,则继续执行进程断点处的正常指令序列,从重新恢复到断点重新执行的过程中,函数所依赖的环境没有发生改变,就说这个函数是 可重入 的,反之就是 不可重入 的。
满足下面条件之一的多数是不可重入函数:
① 使用了静态数据结构;
② 调用了malloc或free;
③ 调用了标准I/O函数;标准io库很多实现都以不可重入的方式使用全局数据结构
④ 进行了浮点运算.许多的处理器/编译器中,浮点一般都是不可重入的 (浮点运算大多使用协处理器或者软件模拟来实现。
- C语言规定main函数的参数只能有两个, 习惯上这两个参数写为argc和argv,并且还规定argc(第一个形参)必须是整型变量,argv( 第二个形参)必须是指向字符串的指针数组;
写成int main(int argc,char *argv[]),argc=arguments count表示参数个数,argv=argument vector表示数组指针,同时数组在参数传递时会转义为指针,即使[]中包含维度也会被忽略!所以char *argv[]等价于char argv,故也可以写成int main(int argc, char argv)
-
可以在类中或者名字空间中定义main函数,但是这个main函数与全局的main函数不是同一个函数,所以不是程序入口点。全局范围的main函数是程序的主函数,而且不能在全局范围内重载
-
其中C++98是第一个正式C++标准,C++03是在C++98上面进行了小幅度的修订,C++11则是一次全面的大进化( C++0x是C++11 标准成为正式标准之前的草案临时名字 )
-
面向对象程序设计优于传统的结构化程序设计,其优越性主要表现在,它有希望解决软
-
件工程的两个主要问题:软件复杂性控制和软件生产率的提高
-
面向对象系统的复用性是一种信息隐藏技术,目的在于将对象的使用者和设计者分开,使用者不必知道对象行为实现的细节,只需要设计者提供的协议命令对象去做即可
-
单一职责原则(SRP)
-
开放封闭原则(OCP)
-
里氏替换原则(LSP)
-
依赖倒置原则(DIP)
-
接口隔离原则(ISP)
① 文件作用域
② 函数作用域
③ 块作用域
④ 类型声明作用域
⑤ 函数原型作用域
(四)深层复制和浅层复制- 浅层复制:只复制指向对象的指针,而不复制引用对象本身
深层复制:复制引用对象本身,会拷贝动态分配的成员对象
如果是浅拷贝,修改一个对象可能会影响另外一个对象
如果是深拷贝,修改一个对象不会影响到另外一个对象
(五)软件测试和软件调试① 软件测试:设计测试用例,发现软件中存在的错误
② 软件调试:诊断和改正程序中的错误,故程序调试的任务是诊断和改正程序中的错误
(六)内存分类-
BSS段:通常是指用来存放程序中未初始化的或者初始化为0的全局变量和静态变量的一块内存区域。特点是可读写的,在程序执行之前BSS段会自动清0
-
数据段:通常是指用来存放程序中已初始化的全局变量 的一块内存区域,static意味着在数据段中存放变量;
-
代码段:通常是指用来存放程序执行代码的一块内存区域;
-
堆:存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减,这一块在程序运行前就已经确定了;对于堆来讲,它的生长方向是向上的,是向着内存地址增加的方向增长。对于堆来讲,频繁的 new/delete 势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题
-
栈:栈又称堆栈,存放程序的局部变量(不包括static声明的变量)除此以外,在函数被调用时,栈用来传递参数和返回值。对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制对于栈来讲,生长方向是向下的,也就是向着内存地址减小的方向
-
C++的内存分类:堆,栈,程序代码区,静态存储区,常量存储区
-
C++没有规定每一种数据所占字节数 只规定了谁大谁小,故一般在16位机的C++系统中,short和int占两个字节,long占4个字节;在virtual c++中,短整型占两个字节,整型和长整型占4个字节
-

- gcc 和 GCC 是两个不同的东西:
① GCC:GNU Compiler Collection(GUN 编译器集合),它可以编译C、C++、JAV、Fortran、Pascal、Object-C、Ada等语言。
② gcc是GCC中的GUN C Compiler(C 编译器)
③ g++是GCC中的GUN C++ Compiler(C++编译器)
④ 就本质而言,gcc和g++并不是编译器,也不是编译器的集合,它们只是一种驱动器,根据参数中要编译的文件的类型,调用对应的GUN编译器而已
- gcc和g++的主要区别:
① 对于 .c和.cpp文件,gcc分别当做c和cpp文件编译(c和cpp的语法强度是不一样的)
② 对于 .c和.cpp文件,g++则统一当做cpp文件编译
③ 使用g++编译文件时,g++会自动链接标准库STL,而gcc不会自动链接STL
④ gcc在编译C文件时,可使用的预定义宏是比较少的
⑤ gcc在编译cpp文件时/g++在编译c文件和cpp文件时(这时候gcc和g++调用的都是cpp文件的编译器),会加入一些额外的宏
-
obj-c 的编译器处理后缀为 m 的文件时,可以识别 obj-c 和 c 的代码,处理 mm 文件可以识别 obj-c,c,c++ 代码,但 cpp 文件必须只能用 c/c++ 代码,而且 cpp 文件 include 的头文件中,也不能出现 obj-c 的代码,因为 cpp 只是 cpp
-
c++的源程序是以. cpp作为后缀的
-
编译器把源程序翻译成二进制形式的“目标程序”,在windows系统中,目标程序以. obj作为后缀,在UNIX系统中,以. o作为后缀
-
从c++文件到生成exe文件经过预处理、编译、汇编和链接步骤
-
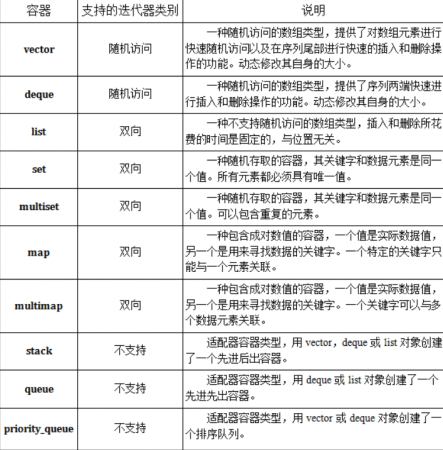
在C++中,容器是一种标准类模板
-

-
C++11 STL中的容器:
① 顺序容器:
(1) vector:可变大小数组
(2) deque:双端队列
(3) list:双向链表
(4) forward_list:单向链表
(5) array:固定大小数组
(6) string:与vector相似的容器,但专门用于保存字符
② 关联容器:
(1) 按关键字有序保存元素:(底层实现为红黑树)
(2) map:关联数组;保存关键字-值对
(3) set:关键字即值,即只保存关键字的容器
(4) multimap:关键字可重复的map
(5) multiset:关键字可重复的set
③ 无序集合:
(1) unordered_map:用哈希函数组织的map
(2) unordered_set:用哈希函数组织的set
(3) unordered_multimap:哈希组织的map;关键字可以重复出现
(4) unordered_multiset:哈希组织的set;关键字可以重复出现
④ 其他项:
(1) stack、queue、valarray、bitset
-
构造异质链表的意义是用抽象类指针构造派生类对象链表(很多场景都要用链表来管理不同类型的对象/结点,这样的链表叫异质链表)
-
List封装了链表,Vector封装了数组, list和vector得最主要的区别在于:vector使用连续内存存储的,他支持[]运算符,而list是以链表形式实现的,不支持[]
-
关于STL各种容器和算法的sort和find函数对重载运算符的描述:
① 线性类型容器使用std::find会调用operator ==
② 线性类型容器sort会调用operator <
③ 二叉树类型的容器的sort和find都会调用operator <
④ 二叉树类型的容器进行std::sort和std::find时,都会调用operator < 。
⑤ 线性类型(vector、list)容器进行std::sort算法时,会调用operator <;进行std::find时,会调用operator ==。
-
根据它们具体的数据结构类型特点,都是可以非常好理解的。前者链式查找和排序,后者顺序查找和排序
-
-
STL中的vector在增加成员时可能会引起原有成员的存储位置发生改变,因为vector是动态分配空间,随着元素的不断插入,它会按照自身的一套机制不断扩充自身的容量导致存储位置改变
-
迭代器支持的操作符:
① 比较两个迭代器的相等和不相等运算符(==和!=)
② 用于推进迭代器的后置和前置递增运算(++)
③ 用于读取元素的接应用运算符(*),解引用只会出现在赋值运算符右侧(即不可修改,只可读)
④ 箭头运算符(->)
⑤ 迭代器支持“+=”操作符的有deque,vector
⑥ 迭代器没有重载左移,右移运算符
(九)程序加载和运行-
加载时地址就是程序放置的地址,运行地址就是程序定位的绝对地址,也即在编译连接时定位的地址。如果程序是在flash里运行,则运行地址和加载地址是相同的。如果程序是在ram里运行,但程序是存储在flash里,则运行地址指向ram,而加载地址是指向flash
-
运行时地址和加载地址不一定相同;运行时地址和加载地址时程序链接时决定的
-
程序文件名的后缀是.cpp,经过编译后是.obj,经过连接后是.exe
① xx.h文件中一般放的是同名.c文件中定义的变量、数组、函数的声明,需要让.c外部使用的声明。
② xx.cpp文件一般放的是变量、数组、函数的具体定义。
- 程序实现经过:
① 头文件的预编译,预处理。
编译器在编译源代码时,会先编译头文件,保证每个头文件只被编译一次。
在预处理阶段,编译器将c文件中引用的头文件中的内容全部写到c文件中。
② 词法和语法分析(查错)。
③ 编译(汇编代码,.obj文件)。
转化为汇编码,这种文件称为目标文件。后缀为.obj。
④ 链接(二进制机器码,.exe文件)。
将汇编代码转换为机器码,生成可执行文件
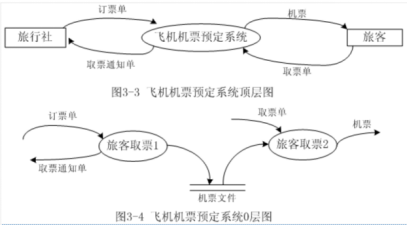
(十一)数据流图- 数据流程图包括:
① 指明数据存在的数据符号,这些数据符号也可指明该数据所使用的媒体
② 指明对数据执行的处理的处理符号,这些符号也可指明该处理所用到的机器功能
③ 指明几个处理和(或)数据媒体之间的数据流的流线符号
④ 便于读、写数据流程图的特殊符号
例: