Redis 是以字典(关联数组)的形式存储的,一个 key 对应一个 value。在字符串类型中,value 只能是一个字符串。那么在散列类型,也叫哈希类型中,value 对应的也是一个字典(关联数组)。那么就可以理解,Redis 的哈希类型/散列类型中,key 对应的 value 是一个二维数组。但是字段的值只可以是字符串。也就是说只能是二维数组,不能有更多的维度。
字典又称符号表,关联数组和映射等,用于保存键值对的数据结构
redis数据库由字典实现,增删改查都在字典基础上产生。
字典的内部实现字典用哈希表做底层实现,哈希表由哈希表节点产生,每个节点保存了字典的键值对。
哈希表typedef struct dictht { // 哈希表数组 dictEntry **table; // 哈希表大小 unsigned long size; // 哈希表大小掩码,用于计算索引值 // 总是等于size-1 unsigned long sizemask; // 该哈希表已有节点的数量 unsigned long used; } dictht;
table 指向dictEntry(哈希表节点,保存键值对),size记录大小,sizemask则是size-,用于(n-1&hash)运算放到table的索引。
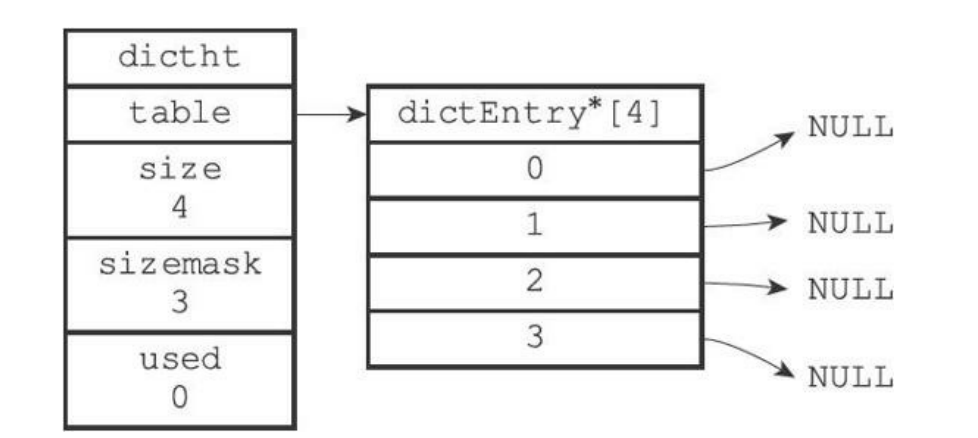
哈希表节点
typedef struct dictEntry { // 键 void *key; // 值 union{ void *val; uint64_tu64; int64_ts64; } v; // 指向下个哈希表节点,形成链表 struct dictEntry *next; } dictEntry;
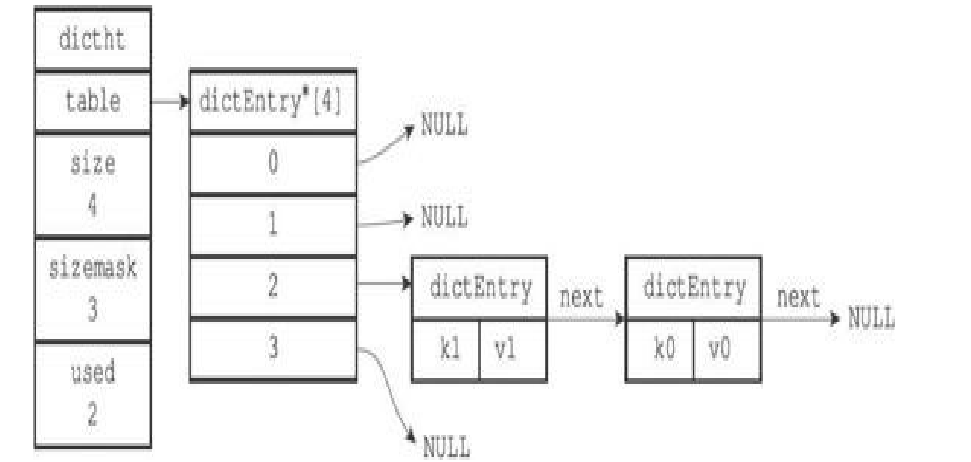
key属性保存着键值对中的键,而v属性则保存着键值对中的值,其中键值对的值可以是一个指针,或者是一个uint64_t整数,又或者是个int64_t整数。next属性是指向另一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对连接在一次,以此来解决键冲突(collision)的问题。
、
字典
typedef struct dict { // 类型特定函数 dictType *type; //指向dictType结构的指针 // 私有数据 void *privdata; // 哈希表 dictht ht[2]; // rehash 索引 // 当rehash 不在进行时,值为-1 int rehashidx; /* rehashing not in progress if rehashidx == -1 */ } dict;
ht为二维哈希表数组,ht[0]为字典,ht[1]rehash ht[0]用得到
rehashidx记录当前哈希进度
哈希算法当字典被用作数据库的底层实现,或者哈希键的底层实现时,Redis使用MurmurHash2算法来计算键的哈希值。
发生冲突时(键被分到哈信表数组同一个索引上),用拉链法解决,next指向,新接待那添加到链表表头(O (1))
rehash随着操作的不断执行,哈希表保存的键值对会逐渐地增多或者减少,为了让哈希表的负载因子(loadfactor)维持在一个合理的范围之内,当哈希表保存的键值对数量太多或者太少时,程序需要对哈希表的大小进行相应的扩展或者收缩。扩展和收缩哈希表的工作可以通过执行rehash(重新散列)操作来完成,Redis对字典的哈希表执行rehash的步骤如下:
-
·为字典的ht[1]哈希表分配空间,这个哈希表的空间大小取决于要执行的操作,以及ht[0]当前包含的键值对数量(也即是ht[0].used属性的值):
- 如果执行的是扩展操作,那么ht[1]的大小为第一个大于等于ht[0].used*2的2 n(2的n次方幂)
- 如果执行的是扩展操作,那么ht[1]的大小为第一个大于等于ht[0].used*2的2 n(2的n次方幂);如果执行的是收缩操作,那么ht[1]的大小为第一个大于等于ht[0].used的2 n。
- 将保存在ht[0]中的所有键值对rehash到ht[1]上面:rehash指的是重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上。
- 当ht[0]包含的所有键值对都迁移到了ht[1]之后(ht[0]变为空表),释放ht[0],将ht[1]设置为ht[0],并在ht[1]新创建一个空白哈希表,为下一次rehash做准备。
rehash为间进行,分多次渐进完成扩展收缩,因为如果键值对数量庞大,全部一次性rehash会停止服务