Inception技术演进
V1(GoogLeNet)=> BN-Inception => V2 => V3 => V4 => Inception-ResNet => Xception
GoogLeNet Incepetion V1在过去三年中,图像识别和目标检测的质量以惊人的速度发展。令人振奋的是,大多数的进步并不只是因为更强大的硬件,更大的数据集和更大的模型,而是因为是新想法、算法和改进的网络架构。
提高深度神经网络的最直接的方法是增加size,包括depth(增加层数)和width(每层的单元数量),这是一个简单安全的方法,但是有两大缺点:(1)容易过拟合(2)增加计算量。解决这两个问题方法是用稀疏连接取代密集连接。
但是计算机在计算非统一的稀疏数据结构时力不从心,需要更复杂的工程和计算基础设施。早些的时候,为了打破网络对称性和提高学习能力,传统的网络都使用了随机稀疏连接。但到了AlexNet的时代重新启用了全连接层,目的是为了实现更好的并行运算加速。
如何既保持网络结构的稀疏性,又利用密集矩阵的高计算性能?论文提出了名为Inception的结构。
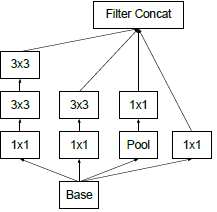
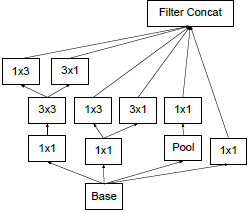
Architectural DetailsInception的主要思想是用密集模块去近似出局部最优稀疏结构。
(1)小的卷积核意味着小的感受野,由1×1卷积提取局部信息,由大卷积核提取大范围空间信息。
(2)为了方便堆叠,卷积核大小采用1、3和5。设定卷积步长stride=1之后,分别设定pad=0、1、2,卷积之后便可以得到相同宽度的特征。
(3)池化层在很多地方被证明很有用,所以在Inception里增加池化层。
(4)越靠前面的层越提取局部信息,越靠后面的层越提取大范围空间信息,在空间上重复Inception时3×3和5×5的卷积核比例要随模型的加深而提高。
原生版本的Inception如下图a所示

原生Inception模块的结构会导致通道数越来越多,计算量爆炸。(max pooling不改变通道数,再堆叠卷积的通道数。。。)。解决这个问题的方法是降维,但是太过密集压缩的嵌入向量不便于模型处理,所以只在3×3和5×5的卷积之前应用1×1卷积降维。
在开始的时候使用传统卷积,在高层使用Inception模块,在内存上似乎更加高效。
总而言之,Inception模块
- 可以增加模型宽度和深度,堆叠时不会导致无法控制的计算复杂度。
- 视觉信息可以在不同尺度上进行处理,然后进行聚合,以便下一阶段可以同时从不同尺度上提取特征。
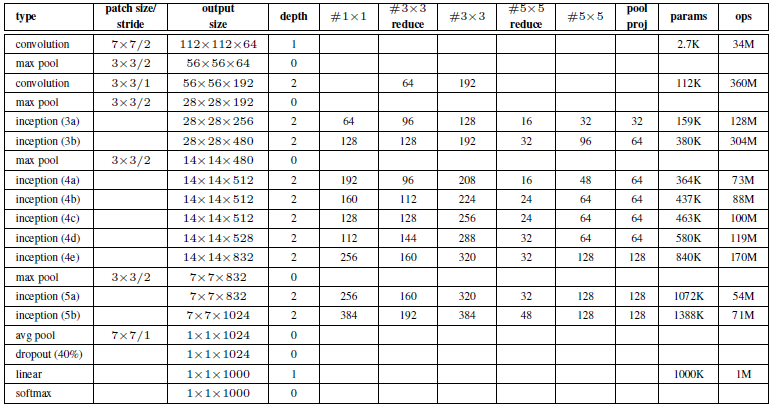
关于上图:
- 所有的卷积,包括Inception模块,用了ReLu激活。
- 输入是224×224的RGB图像减去均值
- “#3×3 reduce” 和 “#5×5 reduce” 表示在3×3和5×5卷积之前做了1×1的卷积减少维度。
- pool proj列表示3×3池化后的1×1卷积核的个数。·所有的1×1卷积降维也使用ReLu激活。
- 在分类之前做平均池化(代替flatten),提高了top-1精确度0.6%,也便于fine-tune迁移学习。
- dropout也很关键。
- 在4a和4d模块后面加辅助分类器,在训练阶段的损失函数L=L主干+0.3×L辅1+0.3×L辅2,在测试阶段去掉辅助分类器。
- 辅助分类器的组成(1)AvgPool 5×5 S=3 (2) 128个Conv 1×1 S=1 (3)fc (4)dropout 70%(5)softmax
以GoogLeNet Incepetion V1为基础,进行了改进:(1)引入批次归一化(Batch Normalization)(2)Inception模块中的5×5卷积核改为2个3×3卷积核
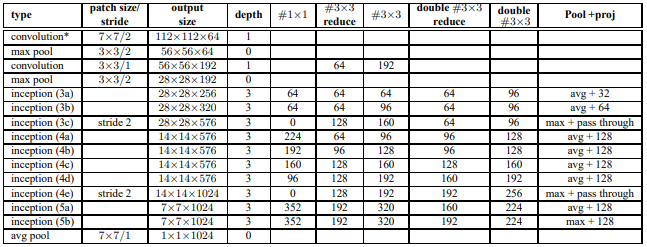
关于上图:
- 增加BN层,卷积=>BN=>ReLU
- 在Inception模块中,2个3×3卷积核代替5×5卷积核,有时最大池化有时平均池化。
- Pool + proj是说,先做池化再用proj个1×1的卷积降维。
CNN的成功应用促进了对高性能CNN模块本身的研究,好的分类网络可以迁移到各种应用领域,因为计算机视觉任务都依赖深度卷积架构提取高质量的特征。也可以开发CNN的新应用,比如AlexNet无法在目标检测任务中生成区域提议。
GoogLeNet使用5million参数,是AlexNet的1/12,VGGNet是AlexNet的3倍。但是(1)单纯地堆叠Inception模块,会导致效果急剧变差(2)对GoogLeNet架构设计的贡献因子也没有清晰的描述,导致Inception模块在新使用场景下难以保持高效性。因此在这篇文章中,我们会介绍一些实用的通用准则和优化想法,以高效的方法扩大卷积网络。这些并不限制于Inception风格的网络,但你会发现,Inception的结构非常灵活,足以自然地实现这些原则。这得益于维度减少和并行结构使得结构改变造成的影响减小。
通用设计原则原则1:避免过度降维或收缩特征,尤其是在网络浅层。feature map的长宽大小应该随网络的加深慢慢减小。
原则2:特征越多,收敛越快。相互独立的特征越多,输入的信息分解的越彻底。
原则3:空间大卷积核之前可以用1×1卷积降维,信息不会损失。相邻的两个单元的感受野也是高度相关的,在做完1×1卷积后仍然是高度相关的。
原则4:均衡网络的宽度和深度,两者同时提升,既可提高性能,也能提高计算效率。
分解大卷积- 分解为小卷积
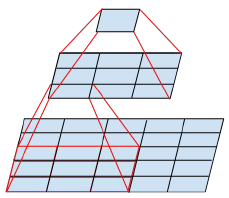
大的卷积核会导致高昂的计算量。比如在卷积核个数和feature map尺寸相同的情况下,5×5卷积的计算量是3×3卷积的25/9=2.78倍。我们利用两个3×3卷积代替5×5卷积,感受野都是5×5,计算量为9+9/25。这种替换会导致网络的表现能力变差吗?要在第一个3×3之后使用非线性激活吗?实验发现在分解各个阶段用ReLu激活效果更好。我们将其归因于网络可以学习到的增强的变化空间,尤其是如果我们batchnormalize输出 。
- 空间分解为非对称卷积
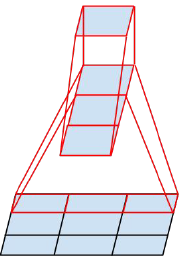
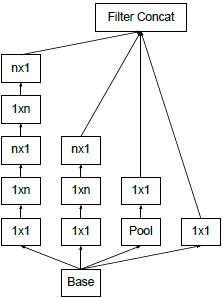
是不是可以分解为更小的,比如2×2卷积。结果表明,n×1的非对称卷积的效果往往比2×2更好。比如,用3×1的卷积后接一个1×3的卷积,和用3×3的卷积是一样的感受野。计算量变为原来的(3+3)/9=67%,节约了33%。相比之下,将3×3分解为两个2×2卷积才节约11%的计算量。更进一步地说,用1×n和n×1的卷积替代n×n的卷积,计算量变为1/n。不对称卷积分解在浅层效果不好,在中等网格尺寸(12-20)时效果很好。
使用辅助分类器辅助分类器的最初目的是将有用的梯度推到较低的层,使其立即有用,以及在非常深的网络中解决消失梯度问题。然而我们发现,辅助分类器在训练初期并没有提高收敛性,在训练快结束的时候,有辅助分支网络的精确度超过了没有辅助分支的网络。同时,将第一个辅助分类器移除,网络并没有受到影响。这意味着“这些分支有助于进化低级特征”的假设很可能是错误的。取而代之,我们认为辅助分类器起到了正则化的作用,同时我们揣测BN也有正则化作用。
高效下采样技巧在最大池化或者平均池化之前会先增加维度。比如d×d×k要变为d/2×d/2×2k,有两种方法:(1)先用k=m,s=1的卷积将维度变为2k,然后池化,计算量为2d2k2m2。(2)用2k个步长为2的卷积核,计算量为2(d/2)2k2m2,会丢失很多特征,违背了原则1。
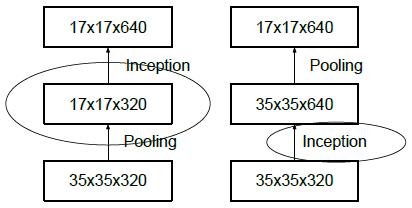
如上图所示,左边先池化再升维,丢失信息太多,违反原则1;右图,先升维再池化,计算量太大,都有较大缺陷。
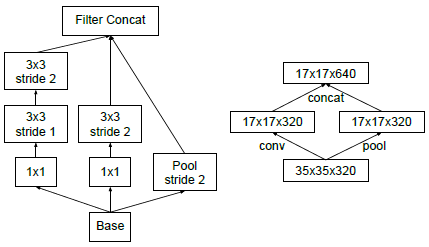
左右两个图表示相同操作:Inception模块采用并行结构,在扩充通道数的同时下采样,保证了计算效率,又避免了特征表示瓶颈。
Inception-v2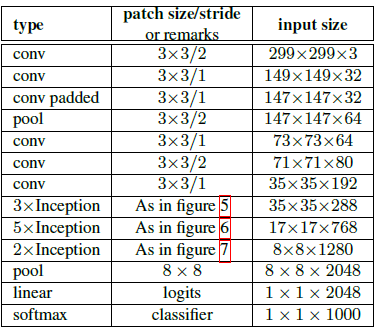
关于上图:
- 将V1的7×7的卷积分解为3个3×3的卷积
- Inception部分,前面三个是【将5×5卷积分为两个3×3卷积的】Inception模块,然后是5个【将5×5卷积分为两个3×3,再将所有3×3卷积分解为1×3和3×1不对称卷积的】Inception模块,最后两个Inception模块如右图所示。
- 写padded的卷积进行了填充,没写的都没有填充,包括Inception里面。
- 尽管网络达到了42层,计算量是v1的2.5倍,也仍然比VGG高效。
- 输入的感受野小于299的话,可以在前两层减小步长,或者移除第一个池化层。
例如:三分类问题
正确的答案为(1,0,0) 独热one-hot编码
softmax预测为(0.5,0.4,0.1)
此时的交叉熵为L=-(1×log0.5 + 0×log0.4 + 0×log0.1)=0.3
当softmax预测为(0.8,0.1,0.1)
此时的交叉熵为L=-(1×log0.8 + 0×log0.1 + 0×log0.1)=0.1
也就是说,如果用独热one-hot编码,最小化交叉熵损失函数等效于最大化正确类别的对数似然函数:L=Σqilog(pi) = log(py) = -zy + log(Σezi)
此时,zy就会一直增大到正无穷,也就是说独热编码鼓励模型过于自信,不计一切增大某一类的logit,也会导致过拟合,模型死记硬背无法泛化。
我们可以用label smooth来解决这个问题:
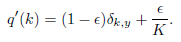
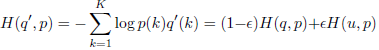
比如:
原始的独热标签为(1,0,0),取ε=0.1,此时标签为(0.9,0.05,0.05)
此时的交叉熵为L=-(0.9×log0.8 + 0.05×log0.1 + 0.05×log0.1)
有点像知识蒸馏,比如识别猫,老虎像猫,可乐不像猫,这些相关性的知识会被保留下来。
GoogLeNet Incepetion V42015年,何凯明引入残差连接,大大提升了图像识别和目标检测的效果,作者认为,残差连接对于训练非常深的卷积模型是内在必要的。但本论文发现,即使不用残差连接,训练很深的网络也不会特别困难(Incepetion V4),但是使用残差连接可以大大提升收敛的速度。给出了3个网络架构的细节:
- Inception-ResNet-v1:一种混合的Inception版本,其计算成本与Inception-v3类似。
- Inception-ResNet-v2:成本更高的混合版Inception,识别性能显著提高。
- Inception-v4:一种没有残差连接的纯Inception变体,其识别性能与Inception-ResNet-v2大致相同。
Inception-v4:Input (299x299x3) => Stem => 4 x Inception-A => Reduction-A => 7 x Inception-B => Reduction-B => 3 x Inception-C => Avarage Pooling => Dropout (keep 0.8) => Softmax
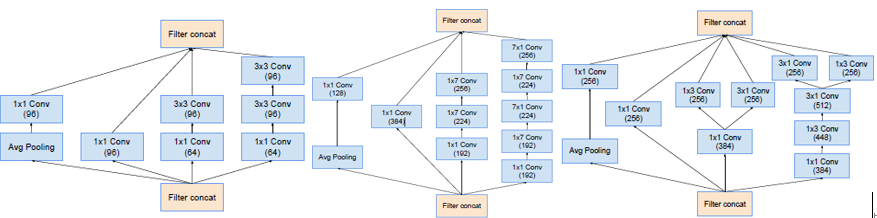
Block35(Inception-A) Block17(Inception-B) Block8(Inception-C)
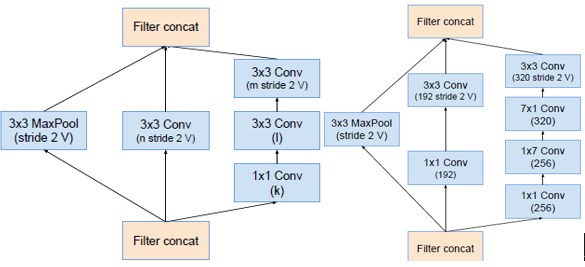
Reduction-A Reduction-B
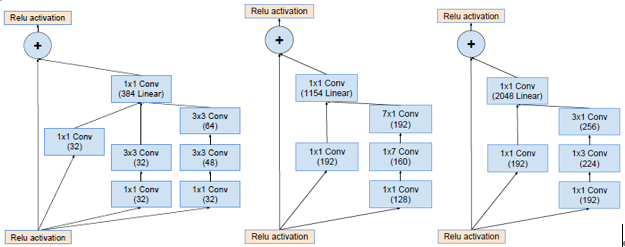
Residual IncepetionInception-ResNet-v1
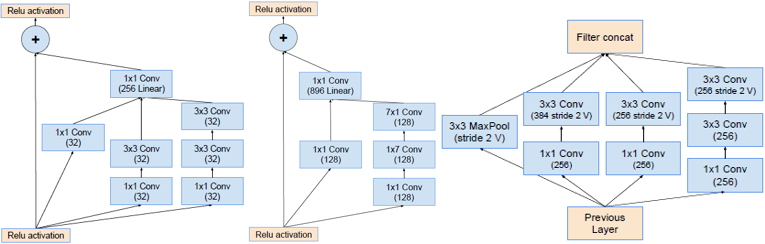
Inception-ResNet-v2
- Incepetion之后使用不带激活函数的1×1卷积升维扩展,以匹配输入维度。
- 只在传统层后面使用bn,在相加层之后不做bn减少计算量。
- Scaling of the Residuals:如果卷积核的个数超过1000个,输出会变得不稳定,只训练一会,平均池化前的有些神经元会输出0。使用很低的学习率和增加bn层都不能解决这个问题。论文提出在加法融合之前对残差分支的结果乘以幅度缩小系数。
这篇就不细说了,每个模块很好搭,但是在组装的时候维度对不上。源码也和论文上不一样,源码的Inception-ResNet-v2的stem用的是Figure14的结构(论文上Fig14是v1的,Fig3是v2的),因此stem的输出为35×35×256,三个Inception_resnet模块的concat后利用1×1卷积升维,卷积的个数分别为320,1088和2080,和论文上也不一样。还有三个Inception_resnet模块的重复个数,原论文是【5,10,5】,源码是【10,17,9】。网上找不到解释,也或许是我理解错了。
Xcepetion普通的卷积核处理长、宽以及跨通道的信息,一个kernel处理所有的通道。而深度可分离卷积,一个kernel处理一个通道。Inception模块是普通卷积和深度可分离卷积的中间形态,将通道划分为3或4部分再分别利用3×3或5×5卷积(如下图中),将空间信息和跨通道信息解耦。
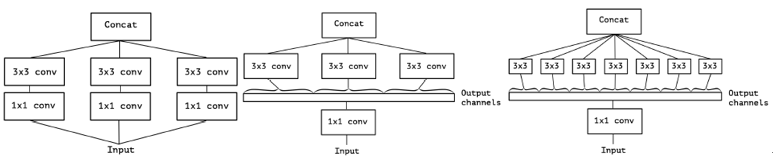
Xception模块和深度可分离卷积的两个微小不同:
(1)深度可分离卷积先进行逐通道的空间卷积,然后是1×1的卷积,而Inception模块是先进行1×1卷积
(2)Inception模块所有操作后都接ReLU,而深度可分离卷积一般没有非线性层
作者认为第一个差异并不重要,因为这些操作往往被用来堆叠。第二个差异,在depthwise和pointwise之间不要用非线性激活比较好。
Architectural Details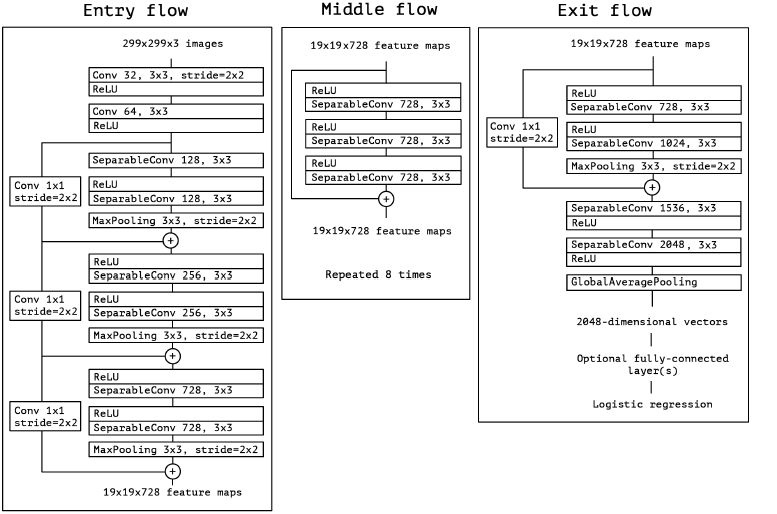
- 一共有36个卷积层,分为14个模块,除了第一个和最后一个,其余所有模块都用线性残差连接。
- depthwise和pointwise之间不用非线性激活
- 扩大数据集本身也是一种正则化,所以没有用dropout
- V3提到辅助分类器没什么用,所以Xception没有用辅助分类器
import torch from torch import nn from utils.BasicModule import BasicModule class Xception(BasicModule): def __init__(self, num_classes): super(Xception, self).__init__() self.model_name = "Xception" self.conv1 = BasicConv2d(in_channels=1, out_channels=32, kernel_size=3, stride=2) self.conv2 = BasicConv2d(in_channels=32, out_channels=64, kernel_size=3) # --------------------------------------------------------------------------------- self.sepconv1 = SeparableConv(in_channels=64, out_channels=128, kernel_size=3) self.sepconv2 = SeparableConv(in_channels=128, out_channels=128, kernel_size=3) self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.conv_id1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=1, stride=2) self.bn1 = nn.BatchNorm2d(num_features=128) # --------------------------------------------------------------------------------- self.sepconv3 = SeparableConv(in_channels=128, out_channels=256, kernel_size=3) self.sepconv4 = SeparableConv(in_channels=256, out_channels=256, kernel_size=3) self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.conv_id2 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=1, stride=2) self.bn2 = nn.BatchNorm2d(num_features=256) # --------------------------------------------------------------------------------- self.sepconv5 = SeparableConv(in_channels=256, out_channels=728, kernel_size=3) self.sepconv6 = SeparableConv(in_channels=728, out_channels=728, kernel_size=3) self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.conv_id3 = nn.Conv2d(in_channels=256, out_channels=728, kernel_size=1, stride=2) self.bn3 = nn.BatchNorm2d(num_features=728) #----------------------------------------------------------------------------------- self.Middleflow = Middleflow() #----------------------------------------------------------------------------------- self.sepconv7 = SeparableConv(in_channels=728, out_channels=728, kernel_size=3) self.sepconv8 = SeparableConv(in_channels=728, out_channels=1024, kernel_size=3) self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.conv_id4 = nn.Conv2d(in_channels=728, out_channels=1024, kernel_size=1, stride=2) self.bn4 = nn.BatchNorm2d(num_features=1024) #------------------------------------------------------------------------------------ self.sepconv9 = SeparableConv(in_channels=1024, out_channels=1536, kernel_size=3) self.sepconv10 = SeparableConv(in_channels=1536, out_channels=2048, kernel_size=3) self.avgpool = nn.AdaptiveAvgPool2d((1,1)) self.dropout = nn.Dropout(0.5) self.fc = nn.Linear(2048, num_classes) self.relu = nn.ReLU() self.softmax = nn.Softmax() def forward(self, x): x = self.relu(self.conv1(x)) x = self.relu(self.conv2(x)) identity1 = self.bn1(self.conv_id1(x)) x = self.relu(self.sepconv1(x)) x = self.maxpool1(self.sepconv2(x)) x = x+identity1 # 1, 128, 74, 74 identity2 = self.bn2(self.conv_id2(x)) x = self.sepconv3(self.relu(x)) x = self.sepconv4(self.relu(x)) x = self.maxpool2(x) x = x + identity2 # 1, 256, 37, 37 identity3 = self.bn3(self.conv_id3(x)) x = self.sepconv5(self.relu(x)) x = self.sepconv6(self.relu(x)) x = self.maxpool3(x) x = x + identity3 # 1, 728, 19, 19 x = self.Middleflow(x) # 1, 728, 19, 19 identity4 = self.bn4(self.conv_id4(x)) x = self.sepconv7(self.relu(x)) x = self.sepconv8(self.relu(x)) x = self.maxpool4(x) x = x + identity4 # 1, 1024, 10, 10 x = self.relu(self.sepconv9(x)) x = self.relu(self.sepconv10(x)) x = self.avgpool(x) x = torch.flatten(x,1) x = self.dropout(x) x = self.fc(x) x = self.softmax(x) return x class BasicConv2d(nn.Module): def __init__(self, in_channels, out_channels, **kwargs): super(BasicConv2d, self).__init__() self.conv = nn.Conv2d(in_channels, out_channels, **kwargs) self.bn = nn.BatchNorm2d(out_channels) def forward(self, x): x = self.conv(x) x = self.bn(x) return x class SeparableConv(nn.Module): def __init__(self, in_channels, out_channels, kernel_size): super(SeparableConv, self).__init__() self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size, stride=1, padding=1, groups=in_channels) self.conv2 = nn.Conv2d(in_channels, out_channels, 1) self.bn = nn.BatchNorm2d(out_channels) def forward(self, x): x = self.conv1(x) x = self.bn(self.conv2(x)) return x class Middleflow(nn.Module): def __init__(self): super(Middleflow, self).__init__() self.sepconv = SeparableConv(in_channels=728, out_channels=728, kernel_size=3) self.relu = nn.ReLU(inplace=True) def forward(self, x): identity = x for i in range(8): for i in range(3): x = self.sepconv(self.relu(x)) x = x + identity identity = x return identity # input = torch.randn(1, 3, 224, 224) # model = Xception() # output = model(input) # print(output.shape)
根据论文搭的,在训练集很好,但是在测试集上效果巨差。。。和tf版本的源码也对照了一下,感觉没什么问题,过拟合了?
参考文献:
1. GoogLeNet系列解读
2. 【精读AI论文】谷歌Xception深度可分离卷积的极致Inception轻量化网络