雪花算法的原理与实现简介 雪花算法(SnowFlake)是Twitter开源的一种用于在分布式环境下生成全局唯一ID的算法。并且提供了该算法的满足工业级要求的Scala实现,该项目已经不再更新,
雪花算法(SnowFlake)是Twitter开源的一种用于在分布式环境下生成全局唯一ID的算法。并且提供了该算法的满足工业级要求的Scala实现,该项目已经不再更新,官方宣称是因为该实现高度依赖Twitter内部的网络基础设施,所以不具备普适性。
原理雪花算法是将一个64位的整数分成三个部分:
- 41个比特位表示生成ID时的时间戳(精确到毫秒),所以理论上可以使用69年。
- 10个比特位表示当前机器的编号,所以理论上可以支持1024台机器。
- 12个比特位表示当前时间戳下已生成的雪花ID数量,所以理论上一毫秒内可以产生4096个不同的ID。
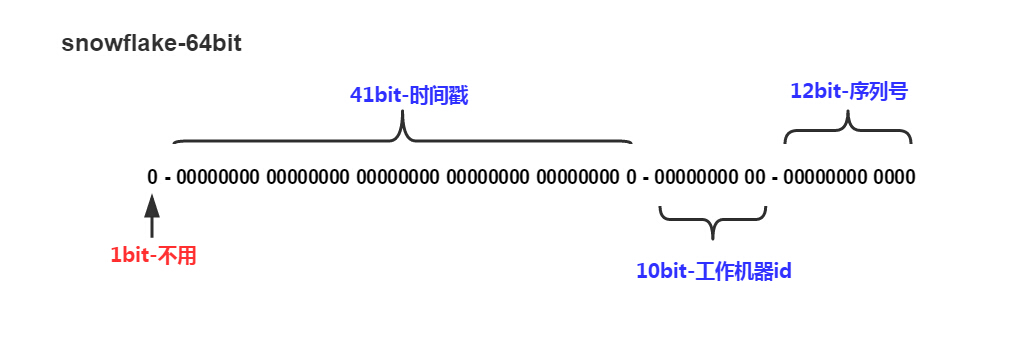
因为在有些语言中最高位是符号位,所以不用。
在实际使用中,可以根据实际情况来对64个比特位进行划分,比如:集群中的机器数量超过1024台,那么可以给机器多分配一个比特位。
优缺点先说说优点:
- 一毫秒内可以生成4096个ID,可以用69年, 可用性非常高。
- 因为在分布式集群中使用机器编号来作区分,所以不会重复。
- 时间戳是递增的,机器编号也是递增的,序列号也是递增的,所以ID的整体趋势是递增的,又因为不重复,所以ID可以作为数据库索引来提高查询效率。
它的优点很明显,缺点也同样明显:
- ID和时钟是强绑定的,一旦时间出现回退,就会出现重复的ID。
算法的实现,我放在了我的GitHub仓库中:https://github.com/funtrin/toys