前几天遇到一个需要实现oracle批量插入的需求,于是我自己疯狂的百度,搞了一个oracle批量插入的小工具。
批量插入语句格式insert into tableName(column1(主键),column2,column3...)
select value1 column1,value2 column2,value3 column3 from dual
union all
select value1 column1,value2 column2,value3 column3 from dual
union all
select value1 column1,value2 column2,value3 column3 from dual
union all
select value1 column1,value2 column2,value3 column3 from dual
例子:
insert into Student(id, name, sex, age, tel)
select '24' id, 'jack' name, '男' sex, 22 age, '13345674567' tel from dual
union select '25' id, 'jack' name, '男' sex, 22 age, '13345674567' tel from dual
union select '26' id, 'jack' name, '男' sex, 32 age, '13345674567' tel from dual
首先定义一oracle的个主键序列:"HZERO"."CFS_CST_SC_RECORD_S".nextval,具体的自己根据自己的业务上来定义
定义主键序列sql:
minvalue:序列最小值
maxvalue:序列最大值
start with:序列起始值
increment by:序列每查一次增加的步长
cache:预缓存。当访问量很大的时候可以先缓存20个序列提供使用,每一次扩容都是按照20个进行增加
-- Create sequence
create sequence CFS_CST_SC_RECORD_S
minvalue 1
maxvalue 9999999999999999999999999999
start with 1
increment by 1
cache 20;
Java代码获取主键ID
第一种方式:使用Java代码获取主键ID后在赋值给插入的数据。
简单获取主键的方式如下:
select "HZERO"."CFS_CST_SC_RECORD_S".nextval from dual;
但是如何批量呢?我尝试过这个!
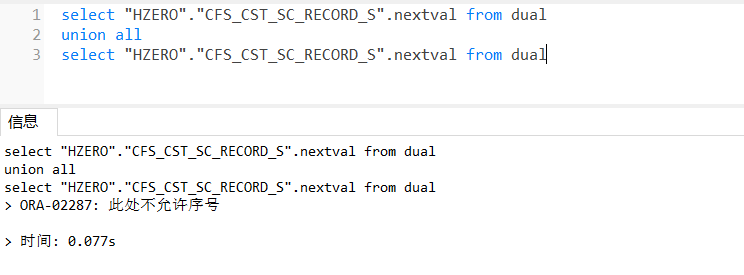
无法批量获取难道我只能单条数据循环获取,那要是数据上万咋办,岂不是直接炸了。于是有了下面的方案:
1、找一张或者自己定义一张大数据量的表,比如:CFS_CST_SC_SECORD
2、实现sql
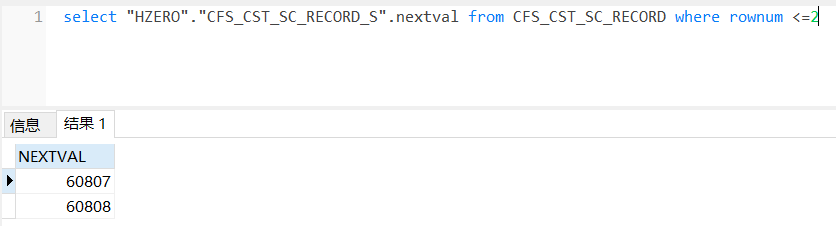
上述方案存在一些缺陷:
1、虽然使用了CFS_CST_SC_SECORD表但是没有使用该表的任何数据,只是利用了表里面存在的数据量来查询主键ID,代码可读性比较差。
2、如果表里面的数据突然清空或者少了,查询的主键ID查询不出来或者数量变少。
3、如果查询的主键ID总条数大于CFS_CST_SC_SECORD表中数据也会出现主键ID数量变少的情况,还需要再java代码里面查询CFS_CST_SC_SECORD表总数量并且根据这个数量做分批次查询。
配置主键ID的自增序列
第二种方式:在表设计中配置表主键ID的序列默认自增,这样在我们插入的时候不需要插入ID字段
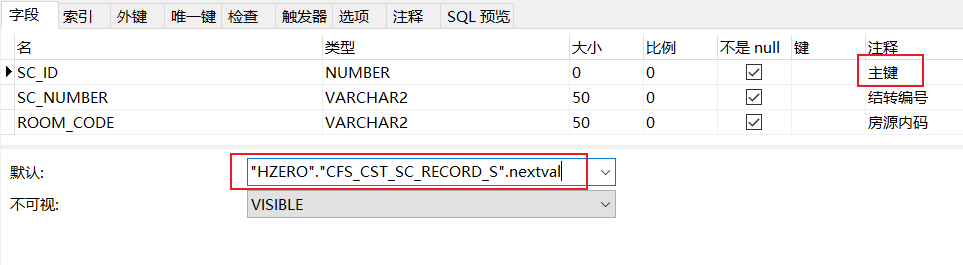
插入格式:
insert into tableName(column1, column2, column3...)
select value1 column1, value2 column2, value3 column3 from dual
union all
select value1 column1, value2 column2, value3 column3 from dual
union all
select value1 column1, value2 column2, value3 column3 from dual
union all
select value1 column1, value2 column2, value3 column3 from dual
例子:
insert into Student(name, sex, age, tel)
select 'jack' name, '男' sex, 22 age, '13345674567' tel from dual
union select 'jack' name, '男' sex, 22 age, '13345674567' tel from dual
union select 'jack' name, '男' sex, 32 age, '13345674567' tel from dual
注意:配置了ID的自增序列,在拼接插入语句的时候千万不要拼接主键ID(上图就是SC_ID字段)字段。
定义一个对象字段的批量插入注解:
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface BatchInsertField {
String fieldName() default "";
// 插入时忽略字段
boolean insertIgnore() default false;
// 日期格式
String dateFormat() default "yyyy-MM-dd HH:mm:ss";
}
注解的使用:
注意以下几点
- 对象必须带有
@Table注解 - 主键必须带有
@Id注解 - 与批量更新(先删除在插入带有主键ID值得数据)做对比,可配置批量插入忽略字段
insertIgnore = true,表示在插入的时候忽略这个字段,在更新时候保留这个字段。
@Data
@JsonInclude(value = JsonInclude.Include.NON_NULL)
@Table(name = "CFS_CST_SC_RECORD")
public class ScRecord extends AuditDomain {
@ApiModelProperty("主键")
@Id
@GeneratedValue
@BatchInsertField(fieldName = "SC_ID", insertIgnore = true)
private Long scId;
@ApiModelProperty(value = "结转编号", required = true)
@NotBlank
@BatchInsertField(fieldName = "SC_NUMBER")
private String scNumber;
@ApiModelProperty(value = "房源内码", required = true)
@NotBlank
@BatchInsertField(fieldName = "ROOM_CODE")
private String roomCode;
@ApiModelProperty(value = "营销系统交房日期,格式YYYY-MM-DD")
@BatchInsertField(fieldName = "SD_DELIVERY_DATE", dateFormat = "yyyy-MM-dd")
private Date sdDeliveryDate;
}
批量插入工具类:
BatchInsertUtil.java
package org.xd.cfs.common.util;
import cn.hutool.core.date.DateUtil;
import cn.hutool.core.util.ObjectUtil;
import io.choerodon.core.exception.CommonException;
import org.hzero.core.base.BaseConstants;
import org.xd.cfs.common.annotations.BatchInsertField;
import javax.persistence.Id;
import javax.persistence.Table;
import java.lang.reflect.Field;
import java.util.*;
import java.util.stream.Collectors;
/**
* 批量插入sql工具,需要在集合对象中配置@BatchInsertField注解和@Table,如果插入需要忽略设置insertIgnore = true
* 例: @Table(name = "table_name")
* 例: @BatchInsertField(fieldName = "SC_ID", insertIgnore = true) 插入时忽略字段
* @author can.he@hand-china.com
* @description
* @date 2022/3/18 15:14
*/
public class BatchInsertUtil {
private static final String insertDateFormat = "yyyy-MM-dd hh24:mi:ss";
/**
* @description 获取批量插入sql
* @param collection 批量插入的集合
* @return java.lang.String 返回的sql语句
* @author can.he@hand-china.com
* @date 2022/3/18 16:50
*/
public static String getInsertSql(Collection<?> collection) {
List<Object> list = new ArrayList<>(collection);
StringBuilder sql = new StringBuilder();
Class<?> cs = list.get(0).getClass();
String tableName = cs.getAnnotation(Table.class).name();
String fieldStr = getFieldNameStr(list.get(0));
String header = "INSERT INTO "+tableName+" ( " + fieldStr + " )";
sql.append(header);
for (int i = 0; i < list.size(); i++) {
Object item = list.get(i);
String valuesStr = getParamsStr(item);
if (i == 0) {
sql.append(" SELECT ").append(valuesStr).append(" FROM DUAL");
}else {
sql.append(" UNION ALL SELECT ").append(valuesStr).append(" FROM DUAL");
}
}
return sql.toString();
}
// 插入列拼接
public static String getFieldNameStr(Object object) {
StringBuilder str = new StringBuilder();
boolean isAdd = false;
Field[] fields = object.getClass().getDeclaredFields();
List<Field> fieldList = Arrays.stream(fields).filter(field -> field.isAnnotationPresent(Id.class)).collect(Collectors.toList());
if (ObjectUtil.isEmpty(fieldList)) {
throw new CommonException("实体对象@Id注解不能为空");
}
try {
Field field = fieldList.get(0);
if (!field.isAccessible()) {
field.setAccessible(true);
}
isAdd = ObjectUtil.isEmpty(field.get(object));
} catch (IllegalAccessException e) {
e.printStackTrace();
}
for (Field field : fields) {
if (field.isAnnotationPresent(BatchInsertField.class)) {
boolean insertIgnore = field.getAnnotation(BatchInsertField.class).insertIgnore();
if (!field.isAccessible()) {
field.setAccessible(true);
}
// 插入忽略
if (isAdd && insertIgnore) {
continue;
}
String fieldName = field.getAnnotation(BatchInsertField.class).fieldName();
str.append(str.length() == 0 ? fieldName : ", " + fieldName);
}
}
return str.toString();
}
// 插入值拼接
public static String getParamsStr(Object object) {
StringBuilder str = new StringBuilder();
boolean isAdd = false;
Field[] fields = object.getClass().getDeclaredFields();
List<Field> fieldList = Arrays.stream(fields).filter(field -> field.isAnnotationPresent(Id.class)).collect(Collectors.toList());
if (ObjectUtil.isEmpty(fieldList)) {
throw new CommonException("实体对象@Id注解不能为空");
}
try {
Field field = fieldList.get(0);
if (!field.isAccessible()) {
field.setAccessible(true);
}
isAdd = ObjectUtil.isEmpty(field.get(object));
} catch (IllegalAccessException e) {
e.printStackTrace();
}
for (Field field : fields) {
if (field.isAnnotationPresent(BatchInsertField.class)) {
String fieldName = field.getAnnotation(BatchInsertField.class).fieldName();
boolean insertIgnore = field.getAnnotation(BatchInsertField.class).insertIgnore();
if (!field.isAccessible()) {
field.setAccessible(true);
}
Object value = null;
try {
value = field.get(object);
} catch (IllegalAccessException e) {
e.printStackTrace();
}
// 判断是否插入忽略字段
if (isAdd && insertIgnore) {
continue;
}
// 对字符串进行处理
if ("class java.lang.String".equals(field.getGenericType().toString())) {
// 对空字符串和字符串进行处理
value = ObjectUtil.isEmpty(value) ? null : "'" + value + "'";
}
// 对日期进行处理
if ("class java.util.Date".equals(field.getGenericType().toString())) {
// 对空字符串和字符串进行处理
if (ObjectUtil.isNotEmpty(value)) {
String dateFormat = field.getAnnotation(BatchInsertField.class).dateFormat();
String date = DateUtil.format((Date) value, dateFormat);
dateFormat = ObjectUtil.equal(BaseConstants.Pattern.DATETIME, dateFormat) ? insertDateFormat : dateFormat;
value = "to_date('" + date + "', '"+dateFormat+"')";
}else {
value = null;
}
}
value = str.length() == 0 ? value : ", " + value;
str.append(value).append(" ").append(fieldName);
}
}
return str.toString();
}
}
// 批量插入结转记录
List<List<ScRecord>> batchList = ListUtils.partition(updateScRecordList, 1000);
batchList.forEach(itemList -> {
String sql = BatchInsertUtil.getInsertSql(itemList);
scRecordRepository.handleBatchInsert(sql);
});
handleBatchInsert:是执行sql的一个service接口
<insert id="handleBatchInsert">
${sql}
</insert>
通过以上操作实现了oracle的批量插入。其实还有一个方案,就是开发一个oracle的存储过程,在存储过程里面实现循环插入,这样也可以减少java对数据库的访问来提高插入效率。