前一篇内容,我们学习了nginx的一些基本概念、安装和目录的作用。这篇文章我们来学习一些更加深入的内容。
一、Nginx请求处理流程我们先来看张图吧:
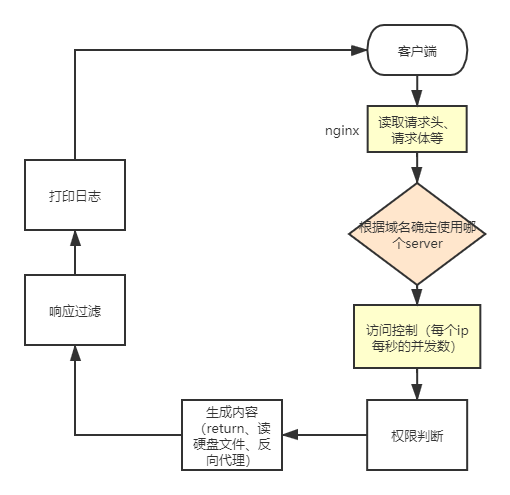
我们看上图,首先客户端请求到Nginx服务器,此时会有nginx服务器读取http带过来的相关内容,比如headers、body等。然后nginx根据域名确定使用的server配置是什么,下一步进行访问控制,防止恶意攻击,然后会进行权限判断,最后处理需要返回的内容,可能是写死的字符串,也可能是硬盘文件,也可能是反向代理的处理。最后进行相应过滤和日志打印。然后就会返回给客户端了。
二、核心模块 1、监控nginx客户端状态
该模块的名称是:--with-http_stub_status_module。
语法:
Syntax: stub_status on/off; # 启动状态 Default: - # 默认值 Context: server->location # 上下文,可以放在server或location中
实战:
打开/etc/nginx/conf.d/default.conf文件,如果没有自己新建一个default.conf文件。然后,我们在新建的default.conf文件里加入如下配置:
location /status{
stub_status on;
}
这里,我要说明下,default.conf是在核心配置文件(/etc/nginx/nginx.conf)中引入的,所以,你要注意语法和层级关系。具体在哪引入,就要遵循其上下文关系。这里可以回头去看那个配置文件,就不多说了。
然后我们重载一下nginx服务:
systemctl reload nginx.service
我们就可以通过浏览器访问“你的服务器ip/status”。然后,浏览器会显示:
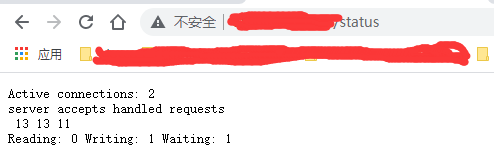
什么意思呢:
- Active connections:当前Nginx正在处理的活动链接数。
- accepts:总共处理的连接数。
- handled:成功创建的握手数。
- requests:总共处理的请求数。
- Reading:读取到客户端的header信息
- Writing:正在返回给客户端header信息
- Waiting:等待,如果开启了keep-alive的话,等待中的请求数。= Active - (reading + writing)。
这些信息可以让你非常清晰的知道nginx的负载。也可以使用nagios,一个开源的监听系统,可以监控服务器的状态。
2)随机主页该模块的名称是:--with-http_random_index_module。
这个模块可以随机在根目录选取一个主页进行显示。这个东西用处不大,咱们来玩一玩吧。
语法:
Syntax: random_index on/off;
Default: off
Context: location
实战:
我们还是在那个default.conf里加这个模块:
location / { root /opt/app; random_index on; }
然后呢,我们依次执行下面的命令,生成两个html文件,以供nginx服务器使用。注意目录级别哦。
mkdir /opt/app cd /opt/app ls echo red > read.html echo yellow > yellow.html echo blue > blue.html
然后我们再重载下服务器,访问服务器ip试一下。是不是很好玩,虽然实际用处几乎没有。还是那句话,注意你引入的位置。
3)内容替换该模块的名称是:--with-http_sub_module。
语法:
Syntax: sub_filter string replacement; Default: -- Context: http,service,location
实战:
location / { root /usr/share/nginx/html; index index.html index.htm; sub_filter 'yellow' 'pink'; }
这里我就不多说了,经历前两个例子,这个就很好理解了。
4)请求限制模块名:
- --with-limit_conn_module:连接频率限制
- --with-limit_req_module:请求频率限制
额外的我们需要安装一个工具,http-tools,是一个http测试的工具,它可以模拟请求和并发数,Apache的ab命令模拟多线程并发请求,测试服务器负载压力,也可以测试nginx、lighthttp、IIS等其它Web服务器的压力:
yum -y install httpd-tools
通过这样的命令来模拟:
ab -n 40 -c 20 http://127.0.0.1/
上面命令的意思是,总请求数量40次,每秒并发20次。
1、连接限制
该模块的名称是:ngx_http_limit_conn_module。
该模块针对所有的worker生效,依赖realip模块从而获得真实的ip地址。
语法:
limit_conn_zone:定义共享内存的大小,以及key关键字。key关键字的意思,一般就是你要限制的内容、或者维度,一般都是ip。
# 可以以IP为key zone为空间的名称 size为申请空间的大小 Syntax: limit_conn_zone key zone=name:size; Default: -- Context: http(定义在server以外)
limit_conn:定义名称和每秒并发数。
# zone名称 number限制的数量 Syntax: limit_conn zone number; Default: -- Context: http,server,location
limit_conn_log_level:错误日志的级别。
Syntax: limit_conn_log_level info|notice|warn|error; Default: limit_conn_log_level error; Context: http,server,location
limit_conn_status:失败的连接要返回的状态码。
Syntax: limit_conn_status code; Default: limit_conn_status 503; Context: http,server,location
实战:
我们直接再/etc/nginx/nginx.conf中编写即可。
limit_conn_zone $binary_remote_addr zone=conn_zone:10m; server { location /{ limit_conn_status 500; limit_conn_log_level warn; limit_rate 50; # 每秒最多返回50字节 limit_conn conn_zone 1; # 每秒并发连接数最多是1 } }
上面代码的含义就是:表明以ip为key,来限制每个ip访问文件时候,最多只能有1个在线,否则其余的都要返回不可用。
然后,我们就可以用我们上面的ab命令来测试了,40 20的请求时间有点长,咱们稍微改一下:
ab -n 10 -c 10 http://127.0.0.1/
在这里咱们看的不是很清楚哈,所以咱们进入之前学过的nginx日志里看一下:
cd /var/log/nginx
ll
然后我们看下图,有两个log,就是我们刚刚执行测试生成的log:

然后我们就可以查看到之前测试的日志了。
2.请求限制
该模块的名称是:ngx_http_limit_req_module。
该模块的核心算法是漏斗算法,把突出的流量限定为恒定多少个请求。limit_req再limit_conn之前生效。
语法:
limit_req_zone:定义共享内存,以及key和限制速度。
# 可以以IP为key zone为空间的名称 size为申请空间的大小 Syntax: limit_req_zone key zone=name:size rate=rate; Default: -- Context: http(定义在server以外)
limit_req:限制并发请求数。
# zone名称 number限制的数量 Syntax: limit_req zone=name [burst=number] [nodelay]; Default: -- Context: http,server,location
burst 是bucket的数量,默认为0。nodelay是对burst中的请求不再采用延迟处理的做法,而是立刻处理。
实战:
limit_req_zone $binary_remote_addr zone=req_zone:10m rate=1r/s; server { location /{ //缓存区队列burst=3个,不延期,即每秒最多可处理rate+burst个.同时处理rate个 //limit_req zone=req_zone; limit_req zone=one burst=5 nodelay; } }
- $binary_remote_addr 表示远程的IP地址
- zone=req_zone:10m 表示一个内存区域大小为10m,并且设定了名称为
req_zone -
rate=1r/s 表示允许相同标识的客户端的访问频次,这里限制的是每秒1次,即每秒只处理一个请求
-
zone=req_zone 表示这个参数对应的全局设置就是req_zone的那个内存区域
- burst 设置一个大小为3的缓冲区,当有大量请求(爆发)过来时,超过了访问频次限制的请求可以先放到这个缓冲区内等待,但是这个等待区里的位置只有3个,超过的请求会直接报503的错误然后返回。
- nodelay 如果设置,会在瞬时提供处理(burst + rate)个请求的能力,请求超过(burst + rate)的时候就会直接返回503,永远不存在请求需要等待的情况,如果没有设置,则所有请求会依次等待排队
5)访问控制
有两个模块:
http_access_module:基于IP的访问控制。
http_auth_basic_module:基于用户的信任登录。这个很少用,大多数都是用ip来限制。
语法:
Syntax: allow address|all; Default: -- Context: http,server,location,limit_except
Syntax: deny address|CIDR|all; Default: -- Context: http,server,location,limit_except
CIDR可以百度详细的了解一下。指无类别域间路由。
实战:
server { location ~ ^/admin.html{ deny 192.171.207.100; allow all; } }
这两个例子,跟之前的写法没区别,我就不多说了,大家自己尝试下哦。
好啦,今天的内容就到此位置了。后面我们学下CDN。
站在巨人的肩膀上,希望我可以看的更远。