这一篇,我们来学习一些重要的命令,在工作中也会经常用到。
一、简单正则要注意的是,有些命令不支持正则模式,比如fs、find等,有些是支持正则的,比如grep、awk、sed等。正则的语法和js中的正则几乎没有区别,下面仅简单罗列下常用的正则:
例如.[aoeiu]匹配任意一个元音字母, [0-9] 匹配任意一位数字,
[a-z][0-9] 匹配由小写字母和一位数字构成的两位字符 grep ab[bc]c reg.txt [^] 匹配除中括号中的字符以外的任意一个字符。例如,[^0-9] 匹配任意一位非数字字符,
[^a-z] 匹配任意一位非小写字母 grep a[^fg]c reg.txt \ 转义符,用于取消特殊符号的含义 grep \.$ reg.txt {n} 表示其前面的字符恰好出现 n 次。例如,[0-9]{4} 匹配4位数字,[1][3-8][0-9]{9} 匹配手机号码 grep "a{1}" reg.txt (n,} 表示其前面的字符出现不少于 n 次。例如,[0-9]{2,} 匹配两位及以上的数字 grep "a{1,}" reg.txt {n,m} 表示其前面的字符至少出现 n 次,最多出现 m 次。例如,[a-z]{6,8} 匹配 6〜8 位的小写字母 grep "a{2,3}" reg.txt
例子已经写在表格里了,大家可以自己去试一下。这里不多说。
二、cut命令用来提取文本中的某一部分。
选项有:
- -b,以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
- -c,以字符为单位进行分割。
- -f,与-d一起使用,指定显示哪个区域。
- -d,自定义分隔符,默认为制表符。
如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
cut最常用的就是-d和-f的配合使用:
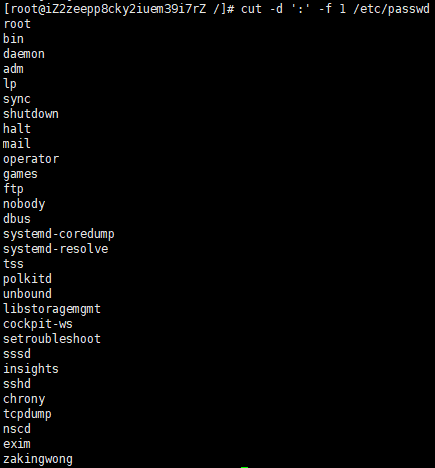
或者:

然后,cut的作用可远不止如此,还有一些其他的用法。要注意灵活运用。
三、printf命令printf 由 POSIX 标准所定义,因此使用 printf 的脚本比使用 echo 移植性好。printf 使用引用文本或空格分隔的参数,外面可以在 printf 中使用格式化字符串,还可以制定字符串的宽度、左右对齐方式等。默认 printf 不会像 echo 自动添加换行符,我们可以手动添加 \n。
printf的语法是这样的:
- printf format-string [arguments...],
- format-string: 为格式控制字符串
- arguments: 为参数列表。
我们先来看个例子:
#!/bin/bash printf "%-10s %-8s %-4s\n" 姓名 性别 体重kg printf "%-10s %-8s %-4.2f\n" 郭靖 男 66.1234 printf "%-10s %-8s %-4.2f\n" 杨过 男 48.6543 printf "%-10s %-8s %-4.2f\n" 郭芙 女 47.9876
结果是:
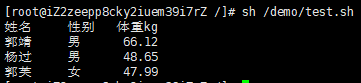
1、%s %c %d %f 都是格式替代符,%s 输出一个字符串,%d 整型输出,%c 输出一个字符,%f 输出实数,以小数形式输出。
2、%-10s 指一个宽度为 10 个字符(- 表示左对齐,没有则表示右对齐),任何字符都会被显示在 10 个字符宽的字符内,如果不足则自动以空格填充,超过也会将内容全部显示出来。
3、%-4.2f 指格式化为小数,其中 .2 指保留2位小数。
我们再来看个例子:
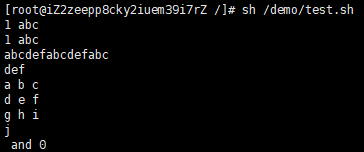
#!/bin/bash # format-string为双引号 printf "%d %s\n" 1 "abc" # 单引号与双引号效果一样 printf '%d %s\n' 1 "abc" # 没有引号也可以输出 printf %s abcdef # 格式只指定了一个参数,但多出的参数仍然会按照该格式输出,format-string 被重用 printf %s abc def printf "%s\n" abc def printf "%s %s %s\n" a b c d e f g h i j # 如果没有 arguments,那么 %s 用NULL代替,%d 用 0 代替 printf "%s and %d \n"
结果如下:
另外,printf的转义序列如下:
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
https://www.runoob.com/linux/linux-comm-awk.html
五、sed命令sed 命令是利用脚本来处理文本文件。sed 可依照脚本的指令来处理、编辑文本文件。sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
https://www.runoob.com/linux/linux-comm-sed.html
六、sort命令sort命令用于将文本文件内容加以排序。sort可针对文本文件的内容,以行为单位来排序。
语法是这样的:
-
sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--verison][文件]
- -b 忽略每行前面开始出的空格字符。
- -c 检查文件是否已经按照顺序排序。
- -d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
- -f 排序时,将小写字母视为大写字母。
- -i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
- -m 将几个排序好的文件进行合并。
- -M 将前面3个字母依照月份的缩写进行排序。
- -n 依照数值的大小排序。
- -u 意味着是唯一的(unique),输出的结果是去完重了的。
- -o<输出文件> 将排序后的结果存入指定的文件。
- -r 以相反的顺序来排序。
- -t<分隔字符> 指定排序时所用的栏位分隔字符。
- +<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
- --help 显示帮助。
- --version 显示版本信息。
wc命令用于计算字数。利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
语法如下:
- wc [-clw][--help][--version][文件...]
- -c或--bytes或--chars 只显示Bytes数。
- -l或--lines 显示行数。
- -w或--words 只显示字。
- --help 在线帮助。
- --version 显示版本信息。
这个命令比较简单,大家可以自己尝试下。
站在巨人的肩膀上,希望我可以看的更远。