越是简单的东西,在深入了解后发现越复杂。想起了曾在初中阶段,语文老师给我们解说《论语》的道理,顺便给我们提了一句,说老子的无为思想比较消极,学生时代不要太关注。现在有了一定的生活阅历,再来看老子的《道德经》,发现那才是大智慧,《论语》属于儒家是讲人与人的关系,《道德经》属于道家讲人与自然的关系,效法天之道来行人之道,儒家讲入世,仁义礼智信,道家讲出世,无为而无不为。老子把道比作水、玄牝(女性的生殖器)、婴儿、山谷等,高深莫测,却滋养万物,源源不断的化生万物并滋养之,而不居功,故能天长地久。儒家教我们做圣人,道家教我们修成仙,显然境界更高。
synchronized的设计思想就像道家的思想一样,看着用起来很简单,但是底层极其复杂,好像永远看不透一样。一直想深入写一篇synchronized的文章,却一直不敢动手,直到最近读了几遍hotspot源码后,才有勇气写一些自己的理解。下文就从几个层面逐步深入,谈谈对synchronized的理解,总结精华思想并用到我们自己的项目设计中。
首先通过一张图来概览synchronized在各层面的实现细节与原理,并在下面的章节逐一分析
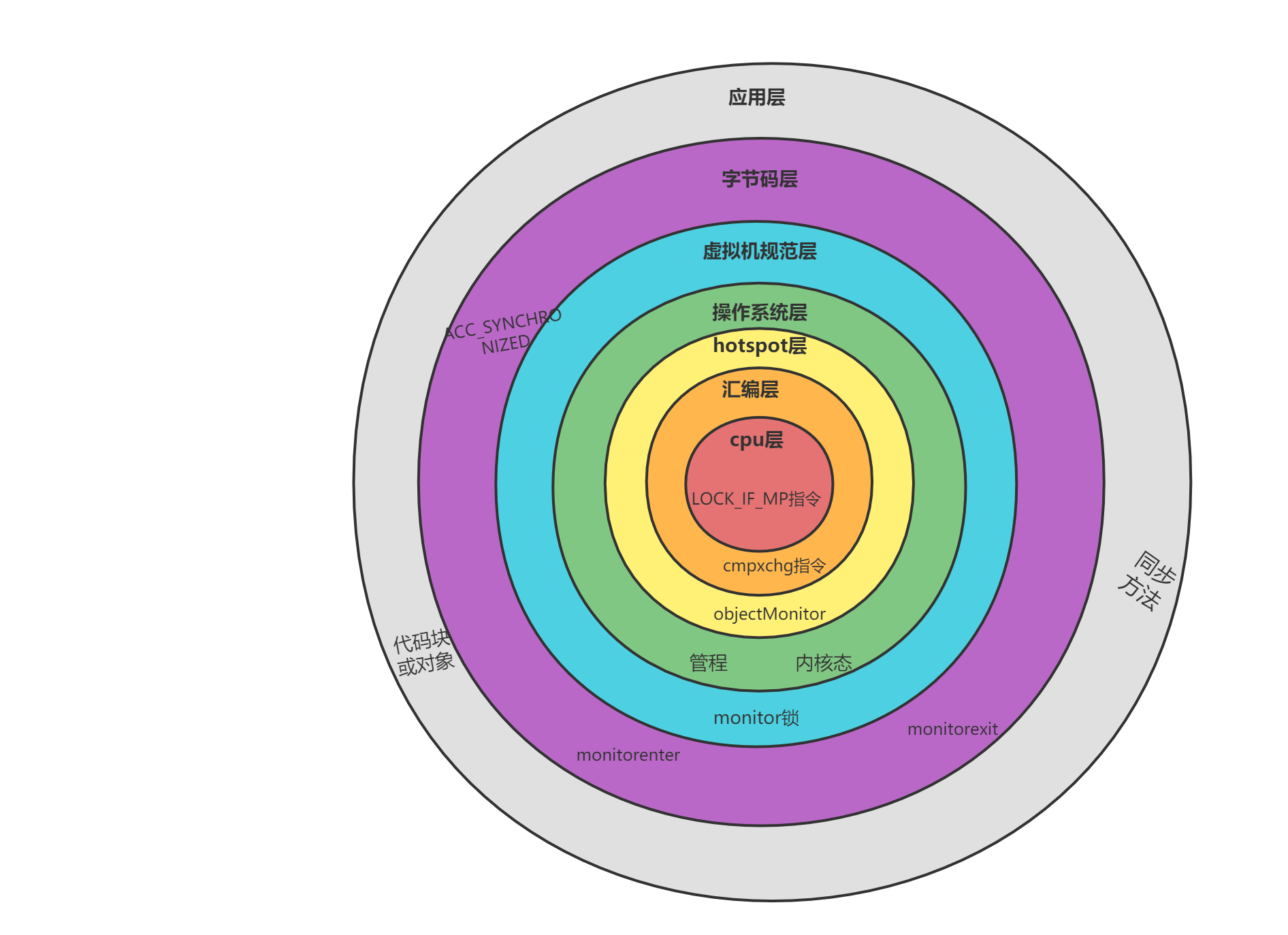
临界区与临界资源
一段代码块内如果存在对共享资源的多线程读写操作,称这段代码块为临界区,其共享资源为临界资源。举例如下:
@Slf4j
public class SyncDemo {
private static volatile int counter = 0;
public static void increment() {
counter++;
}
public static void decrement() {
counter--;
}
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100; i++) {
increment();
}
}, "t1");
Thread t2 = new Thread(() -> {
for (int i = 0; i < 100; i++) {
decrement();
}
}, "t2");
t1.start();
t2.start();
t1.join();
t2.join();
//思考: counter=?
log.info("counter={}", counter);
}
}
以上的结果可能是正数、负数、零。为什么呢?因为 Java 中对静态变量的自增、自减并不是原子操作,个线程执行过程中会被其他线程打断。
竞态条件
多个线程在临界区内执行,由于代码的执行序列不同而导致结果无法预测,称之为发生了竞态条件。为了避免临界区的竞态条件发生,有多种手段可以达到目的:
- 阻塞式的解决方案:synchronized,Lock
- 非阻塞式的解决方案:原子变量
synchronized 同步块是 Java 提供的一种原子性内置锁,Java 中的每个对象都可以把它当作一个同步锁来使用,这些 Java 内置的使用者看不到的锁被称为内置锁,也叫作监视器锁,目的就是保证多个线程在进入synchronized代码段或者方法时,将并行变串行。
使用层面

解决之前的共享问题,只需要在两个方法前面加上synchronized,就可以得到期望为零的结果。
public static synchronized void increment() {
counter++;
}
public static synchronized void decrement() {
counter--;
}
通过IDEA自带的工具view->show bytecode with jclasslib,查看到访问标志0x0029

通过查询java 字节码手册,synchronized对应的字节码为ACC_SYNCHRONIZED,0x0020,三个修饰符加起来正好是0x0029。

如果加在代码块或者对象上, 对应的字节码是monitorenter与monitorexit。

同步方法
The Java® Virtual Machine Specification针对同步方法的说明
Method-level synchronization is performed implicitly, as part of method invocation and return. A synchronized method is distinguished in the run-time constant pool’s method_info structure by the ACC_SYNCHRONIZED flag, which is checked by the method invocation instructions. When invoking a method for which ACC_SYNCHRONIZED is set, the executing thread enters a monitor, invokes the method itself, and exits the monitor whether the method invocation completes normally or abruptly. During the time the executing thread owns the monitor, no other thread may enter it. If an exception is thrown during invocation of the synchronized method and the synchronized method does not handle the exception, the monitor for the method is automatically exited before the exception is rethrown out of the synchronized method.
这段话适合好好读读,大致含义如下:
同步方法是隐式的。一个同步方法会在运行时常量池中的method_info结构体中存放ACC_SYNCHRONIZED标识符。当一个线程访问方法时,会去检查是否存在ACC_SYNCHRONIZED标识,如果存在,则先要获得对应的
monitor锁,然后执行方法。当方法执行结束(不管是正常return还是抛出异常)都会释放对应的monitor锁。如果此时有其他线程也想要访问这个方法时,会因得不到monitor锁而阻塞。当同步方法中抛出异常且方法内没有捕获,则在向外抛出时会先释放已获得的monitor锁。
同步代码块
同步代码块使用monitorenter和monitorexit两个指令实现同步, The Java® Virtual Machine Specification中有关于这两个指令的介绍:
Each object is associated with a monitor. A monitor is locked if and only if it has an owner. The thread that executes monitorenter attempts to gain ownership of the monitor associated with objectref, as follows:
If the entry count of the monitor associated with objectref is zero, the thread enters the monitor and sets its entry count to one. The thread is then the owner of the monitor.
If the thread already owns the monitor associated with objectref, it reenters the monitor, incrementing its entry count.
If another thread already owns the monitor associated with objectref, the thread blocks until the monitor's entry count is zero, then tries again to gain ownership.
大致含义如下:
每个对象都会与一个monitor相关联,当某个monitor被拥有之后就会被锁住,当线程执行到monitorenter指令时,就会去尝试获得对应的monitor。步骤如下:
1.每个monitor维护着一个记录着拥有次数的计数器。未被拥有的monitor的该计数器为0,当一个线程获得monitor(执行monitorenter)后,该计数器自增变为 1 。
- 当同一个线程再次获得该monitor的时候,计数器再次自增;
- 当不同线程想要获得该monitor的时候,就会被阻塞。
2.4 操作系统层面2.当同一个线程释放 monitor(执行monitorexit指令)的时候,计数器再自减。当计数器为0的时候。monitor将被释放,其他线程便可以获得monitor。
Monitor(管程/监视器)
monitor又称监视器,操作系统层面为管程,管程是指管理共享变量以及对共享变量操作的过程,让它们支持并发,所以管程是操作系统层面的同步机制。
MESA模型
在管程的发展史上,先后出现过三种不同的管程模型,分别是Hasen模型、Hoare模型和MESA模型。现在正在广泛使用的是MESA模型。下面我们便介绍MESA模型
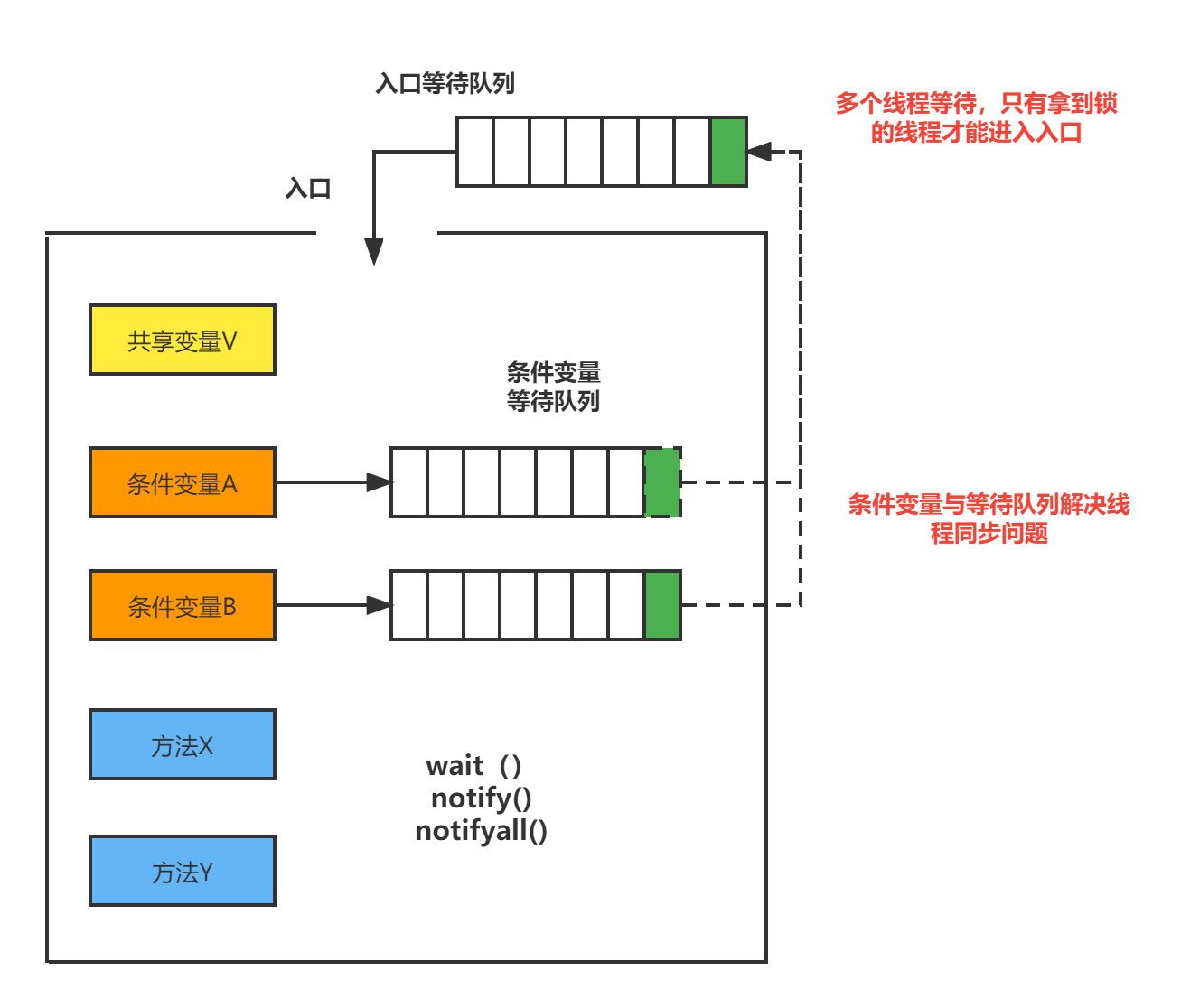
管程中引入了条件变量的概念,而且每个条件变量都对应有一个等待队列。条件变量和等待队列的作用是解决线程之间的同步问题。
synchronized关键字和wait()、notify()、notifyAll()这三个方法是Java中实现管程技术的组成部分,设计思想也是来源与操作系统的管程。在应用层面有个经典的等待通知范式。
等待方
等待方遵循如下的原则:
- 获取对象的锁
- 如果条件不满足,那么调用对象的wait方法,被通知后仍然需要检查条件
- 条件满足则继续执行对应的逻辑
synchronized( 对象 ) {
while( 条件不满足 ) {
对象.wait();
}
对应的处理逻辑
}
通知方
通知方遵循如下的原则:
- 获得对象的锁
- 改变条件
- 通知所有等待在对象上的线程
synchronized( 对象 ) {
改变条件;
对象.notifyAll();
}
唤醒的时间和获取到锁继续执行的时间是不一致的,被唤醒的线程再次执行时可能条件又不满足了,所以循环检验条件。MESA模型的wait()方法还有一个超时参数,为了避免线程进入等待队列永久阻塞。
Java语言的内置管程synchronized
Java 参考了 MESA 模型,语言内置的管程(synchronized)对 MESA 模型进行了精简。MESA模型中,条件变量可以有多个,ReentrantLock可以实现多个条件变量以及对应的队列,Java 语言内置的管程里只有一个条件变量。模型如下图所示。

内核态
jdk1.5之前,synchronized是重量级锁,会直接由操作系统内核态控制,jdk1.6以后,对synchronized做了大量的优化,如锁粗化(Lock Coarsening)、锁消除(Lock Elimination)、轻量级锁(Lightweight Locking)、偏向锁(Biased Locking)、自适应自旋(Adaptive Spinning)等技术来减少锁操作的开销,内置锁的并发性能已经基本与Lock持平,只有升级到重量级锁后才会有大的开销。
等待通知范式案例
用上面讲的等待通知范式,实现一个数据库连接池;连接池有获取连接,释放连接两个方法,DBPool模拟一个容器放连接,初始化20个连接,获取连接的线程得到连接池为空时,阻塞等待,唤起释放连接的线程;
import java.sql.Connection;
import java.util.LinkedList;
/**
*类说明:连接池的实现
*/
public class DBPool {
/*容器,存放连接*/
private static LinkedList<Connection> pool = new LinkedList<Connection>();
/*限制了池的大小=20*/
public DBPool(int initialSize) {
if (initialSize > 0) {
for (int i = 0; i < initialSize; i++) {
pool.addLast(SqlConnectImpl.fetchConnection());
}
}
}
/*释放连接,通知其他的等待连接的线程*/
public void releaseConnection(Connection connection) {
if (connection != null) {
synchronized (pool){
pool.addLast(connection);
//通知其他等待连接的线程
pool.notifyAll();
}
}
}
/*获取*/
// 在mills内无法获取到连接,将会返回null 1S
public Connection fetchConnection(long mills)
throws InterruptedException {
synchronized (pool){
//永不超时
if(mills<=0){
while(pool.isEmpty()){
pool.wait();
}
return pool.removeFirst();
}else{
/*超时时刻*/
long future = System.currentTimeMillis()+mills;
/*等待时长*/
long remaining = mills;
while(pool.isEmpty()&&remaining>0){
pool.wait(remaining);
/*唤醒一次,重新计算等待时长*/
remaining = future-System.currentTimeMillis();
}
Connection connection = null;
if(!pool.isEmpty()){
connection = pool.removeFirst();
}
return connection;
}
}
}
}
import java.sql.*;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.Executor;
/**
*类说明:
*/
public class SqlConnectImpl implements Connection{
/*拿一个数据库连接*/
public static final Connection fetchConnection(){
return new SqlConnectImpl();
}
@Override
public void commit() throws SQLException {
SleepTools.ms(70);
}
......
}
测试类:总共50个线程,每个线程尝试20次
import java.sql.Connection;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicInteger;
/**
*类说明:
*/
public class DBPoolTest {
static DBPool pool = new DBPool(10);
// 控制器:控制main线程将会等待所有Woker结束后才能继续执行
static CountDownLatch end;
public static void main(String[] args) throws Exception {
// 线程数量
int threadCount = 50;
end = new CountDownLatch(threadCount);
int count = 20;//每个线程的操作次数
AtomicInteger got = new AtomicInteger();//计数器:统计可以拿到连接的线程
AtomicInteger notGot = new AtomicInteger();//计数器:统计没有拿到连接的线程
for (int i = 0; i < threadCount; i++) {
Thread thread = new Thread(new Worker(count, got, notGot),
"worker_"+i);
thread.start();
}
end.await();// main线程在此处等待
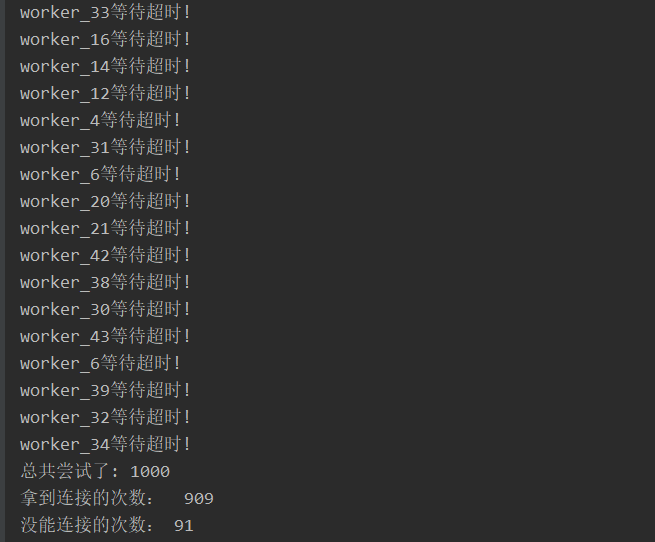
System.out.println("总共尝试了: " + (threadCount * count));
System.out.println("拿到连接的次数: " + got);
System.out.println("没能连接的次数: " + notGot);
}
static class Worker implements Runnable {
int count;
AtomicInteger got;
AtomicInteger notGot;
public Worker(int count, AtomicInteger got,
AtomicInteger notGot) {
this.count = count;
this.got = got;
this.notGot = notGot;
}
public void run() {
while (count > 0) {
try {
// 从线程池中获取连接,如果1000ms内无法获取到,将会返回null
// 分别统计连接获取的数量got和未获取到的数量notGot
Connection connection = pool.fetchConnection(1000);
if (connection != null) {
try {
connection.createStatement();
// PreparedStatement preparedStatement
// = connection.prepareStatement("");
// preparedStatement.execute();
connection.commit();
} finally {
pool.releaseConnection(connection);
got.incrementAndGet();
}
} else {
notGot.incrementAndGet();
System.out.println(Thread.currentThread().getName()
+"等待超时!");
}
} catch (Exception ex) {
} finally {
count--;
}
}
end.countDown();
}
}
}
结果:
hotspot源码ObjectMonitor.hpp定义了ObjectMonitor的数据结构
ObjectMonitor() {
_header = NULL; //对象头 markOop
_count = 0;
_waiters = 0,
_recursions = 0; // 锁的重入次数
_object = NULL; //存储锁对象
_owner = NULL; // 标识拥有该monitor的线程(当前获取锁的线程)
_WaitSet = NULL; // 等待线程(调用wait)组成的双向循环链表,_WaitSet是第一个节点
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ; //多线程竞争锁会先存到这个单向链表中 (FILO栈结构)
FreeNext = NULL ;
_EntryList = NULL ; //存放在进入或重新进入时被阻塞(blocked)的线程 (也是存竞争锁失败的线程)
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
_previous_owner_tid = 0;
}
大致执行过程如下如所示:

大量线程进入监视器的等待队列EntryList,只有通过CAS拿到锁的线程,把进入锁的标识变量_recursions置为1,如果方法是递归循环调用,支持锁重入,_recursions可以累加,并将_owner置为获取锁的线程ID,调用wait方法后,释放锁,再重新进入等待队列EntryList。
对象的内存布局
上述过程可以看到,加锁是加在对象头上的,Hotspot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头(Header)、实例数据
(Instance Data)和对齐填充(Padding)。
- 对象头:比如 hash码,对象所属的年代,对象锁,锁状态标志,偏向锁(线程)ID,偏向时间,数组长度(数组对象才有)等。
- 实例数据:存放类的属性数据信息,包括父类的属性信息;
- 对齐填充:由于虚拟机要求, 对象头字节大小必须是8字节的整数倍。填充数据不是必须存在的,仅仅是为了字节对齐。
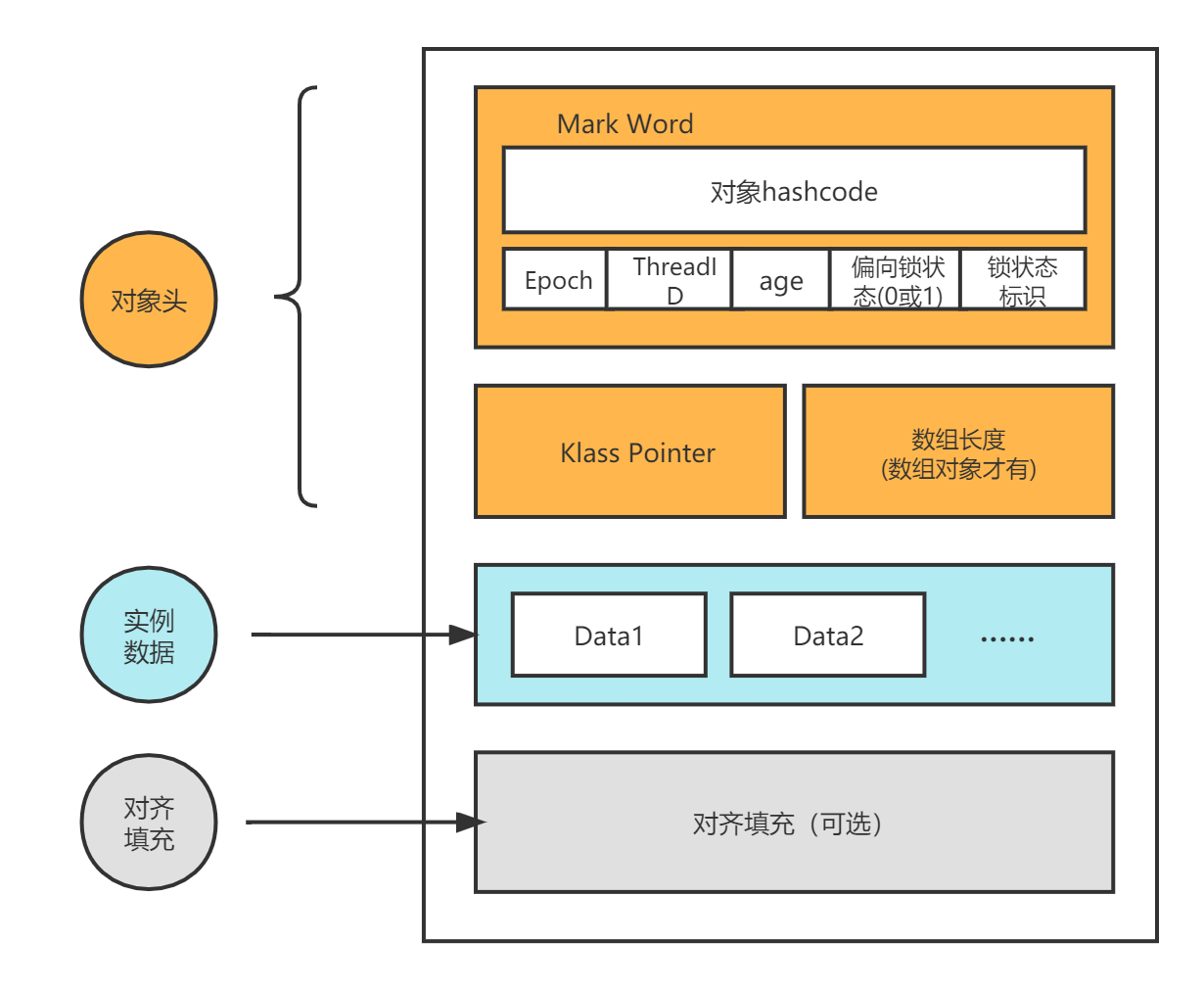
对象头详解
HotSpot虚拟机的对象头包括:
- Mark Word
用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,这部分数据的长度在32位和64位的虚拟机中分别为32bit和64bit,官方称它为"Mark Word"。 - Klass Pointer
对象头的另外一部分是klass类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。 32位4字节,64位开启指针压缩或最大堆内存<32g时4字节,否则8字节。jdk1.8默认开启指针压缩后为4字节,当在JVM参数中关闭指针压缩(-XX:-UseCompressedOops)后,长度为8字节。 - 数组长度(只有数组对象有)如果对象是一个数组,那在对象头中还必须有一块数据用于记录数组长度,开启压缩时,数组占4字节,不开启压缩数组占8字节,因为数组本质上也是指针。
使用JOL工具查看内存布局
给大家推荐一个可以查看普通java对象的内部布局工具JOL(JAVA OBJECT LAYOUT),使用此工具可以查看new出来的一个java对象的内部布局,以及一个普通的java对象占用多少字节。引入maven依赖
<!-- https://mvnrepository.com/artifact/org.openjdk.jol/jol-core -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
<scope>provided</scope>
</dependency>
使用方法:
//查看对象内部信息
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
测试
public static void main(String[] args) throws InterruptedException {
Object obj = new Object();
//查看对象内部信息
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
利用jol查看64位系统java对象(空对象),默认开启指针压缩,总大小显示16字节,前12字节为对象头。
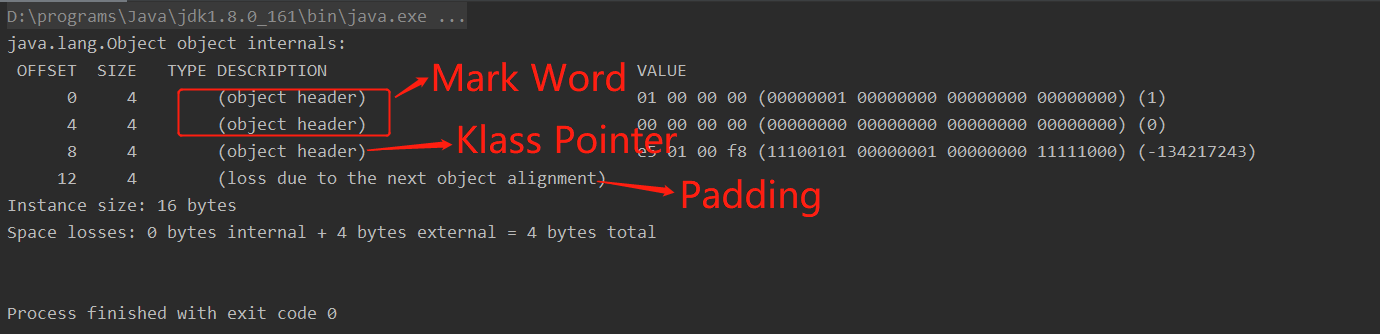
- OFFSET:偏移地址,单位字节;
- SIZE:占用的内存大小,单位为字节;
- TYPE DESCRIPTION:类型描述,其中object header为对象头;
- VALUE:对应内存中当前存储的值,二进制32位;
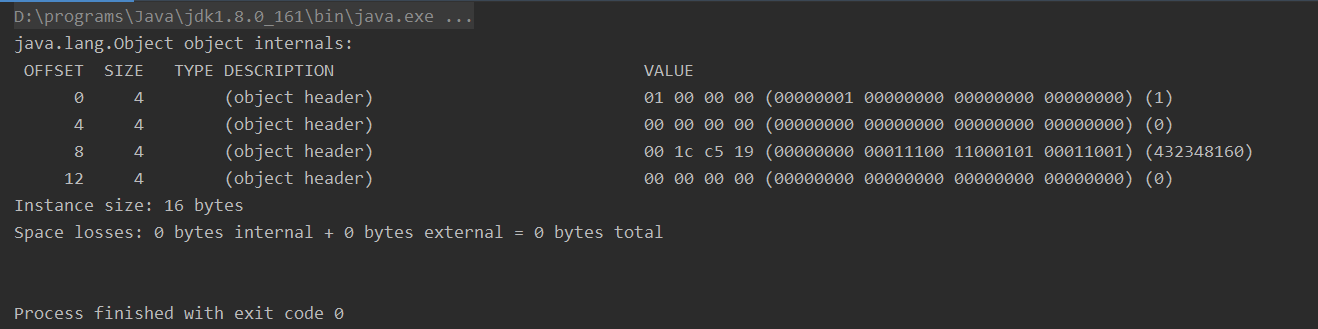
关闭指针压缩后,对象头为16字节:XX:UseCompressedOops
Mark Word的结构
Hotspot通过markOop类型实现Mark Word,具体实现位于markOop.hpp文件中。MarkWord 结构搞得这么复杂,是因为需要节省内存,让同一个内存区域在不
同阶段有不同的用处。
// Bit-format of an object header (most significant first, big endian layout below):
//
// 32 bits:
// --------
// hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
// size:32 ------------------------------------------>| (CMS free block)
// PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
//
// 64 bits:
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)
//
// unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
// JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
// narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
// unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
......
......
// [JavaThread* | epoch | age | 1 | 01] lock is biased toward given thread
// [0 | epoch | age | 1 | 01] lock is anonymously biased
//
// - the two lock bits are used to describe three states: locked/unlocked and monitor.
//
// [ptr | 00] locked ptr points to real header on stack
// [header | 0 | 01] unlocked regular object header
// [ptr | 10] monitor inflated lock (header is wapped out)
// [ptr | 11] marked used by markSweep to mark an object
// not valid at any other time
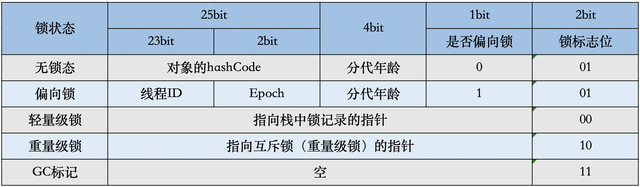
- hash: 保存对象的哈希码。运行期间调用System.identityHashCode()来计算,延迟计算,并把结果赋值到这里。
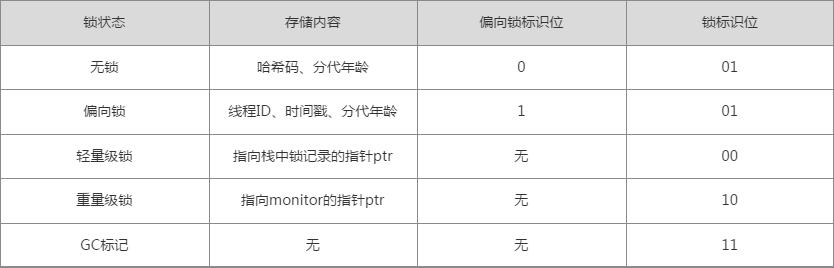
- age: 保存对象的分代年龄。表示对象被GC的次数,当该次数到达阈值的时候,对象就会转移到老年代。
- biased_lock: 偏向锁标识位。由于无锁和偏向锁的锁标识都是 01,没办法区分,这里引入一位的偏向锁标识位。
- lock: 锁状态标识位。区分锁状态,比如11时表示对象待GC回收状态, 只有最后2位锁标识有效。
- JavaThread*: 保存持有偏向锁的线程ID。偏向模式的时候,当某个线程持有对象的时候,对象这里就会被置为该线程的ID。 在后面的操作中,就无需再进行尝试获取锁的动作。这个线程ID并不是JVM分配的线程ID号,和Java Thread中的ID是两个概念。
- epoch: 用来计算偏向锁的批量撤销与批量重偏向。
32位JVM下的对象结构描述
64位JVM下的对象结构描述
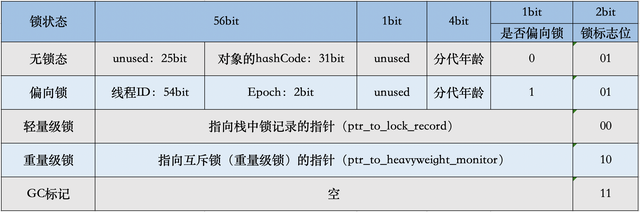
- ptr_to_lock_record:轻量级锁状态下,指向栈中锁记录的指针。当锁获取是无竞争时,JVM使用原子操作而不是OS互斥,这种技术称为轻量级锁定。在轻量级锁定的情况下,JVM通过CAS操作在对象的Mark Word中设置指向锁记录的指针。
- ptr_to_heavyweight_monitor:重量级锁状态下,指向对象监视器Monitor的指针。如果两个不同的线程同时在同一个对象上竞争,则必须将轻量级锁定升级到Monitor以管理等待的线程。在重量级锁定的情况下,JVM在对象的ptr_to_heavyweight_monitor设置指向Monitor的指针。
Mark Word中锁标记枚举
enum { locked_value = 0, //00 轻量级锁
unlocked_value = 1, //001 无锁
monitor_value = 2, //10 监视器锁,也叫膨胀锁,也叫重量级锁
marked_value = 3, //11 GC标记
biased_lock_pattern = 5 //101 偏向锁
};
更直观的理解方式
偏向锁
在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,对于没有锁竞争的场合,偏向锁有很好的优化效果。
/***StringBuffer内部同步***/
public synchronized int length() {
return count;
}
//System.out.println 无意识的使用锁
public void println(String x) {
synchronized (this) {
print(x); newLine();
}
}
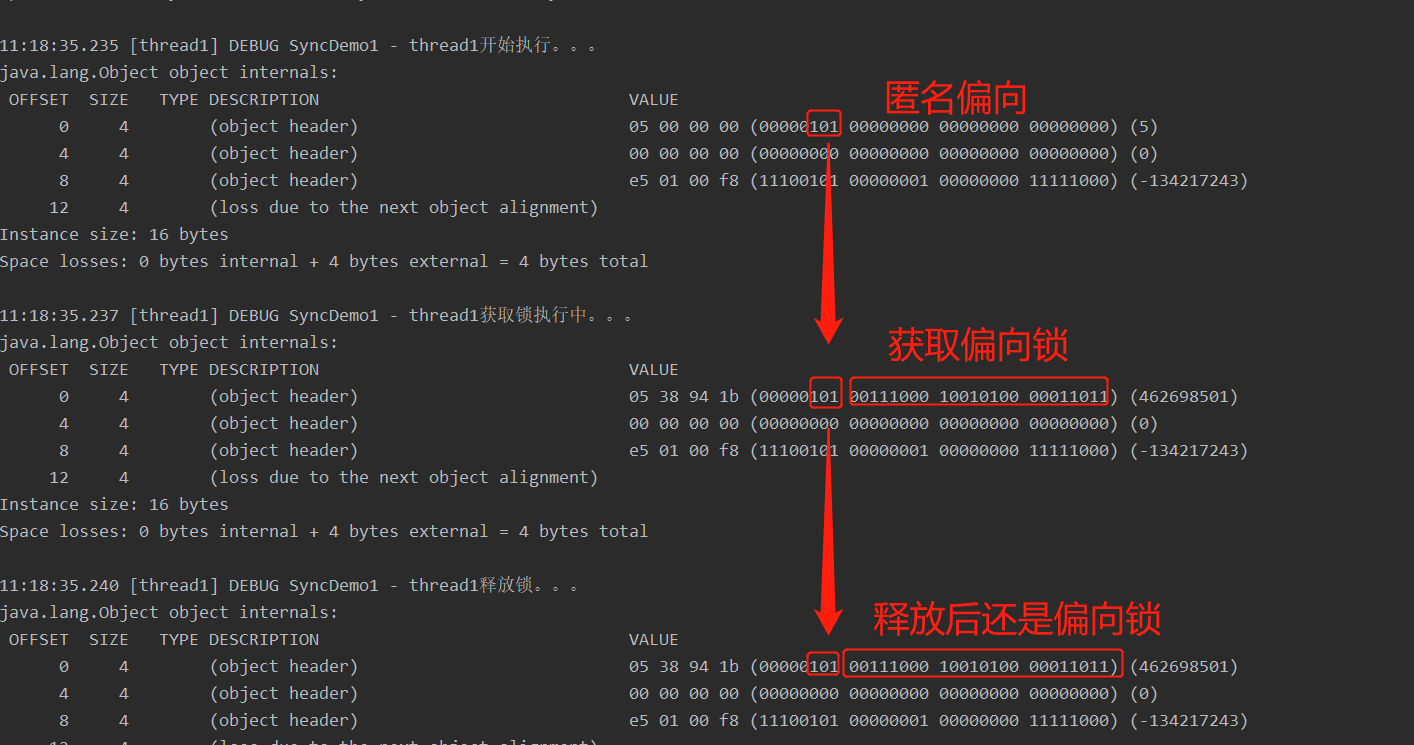
当JVM启用了偏向锁模式(jdk6默认开启),新创建对象的Mark Word中的Thread Id为0,说明此时处于可偏向但未偏向任何线程,也叫做匿名偏向状态(anonymously biased)
偏向锁延迟偏向
偏向锁模式存在偏向锁延迟机制:HotSpot 虚拟机在启动后有个 4s 的延迟才会对每个新建的对象开启偏向锁模式。因为JVM启动时会进行一系列的复杂活动,比如装载配置,系统类初始化等等。在这个过程中会使用大量synchronized关键字对对象加锁,且这些锁大多数都不是偏向锁。待启动完成后再延迟打开偏向锁。
//关闭延迟开启偏向锁
‐XX:BiasedLockingStartupDelay=0
//禁止偏向锁
‐XX:‐UseBiasedLocking
//启用偏向锁
‐XX:+UseBiasedLocking
@Slf4j
public class LockEscalationDemo{
public static void main(String[] args) throws InterruptedException {
log.debug(ClassLayout.parseInstance(new Object()).toPrintable());
Thread.sleep(5000);
log.info("===============延迟5秒后=================");
log.debug(ClassLayout.parseInstance(new Object()).toPrintable());
}
}

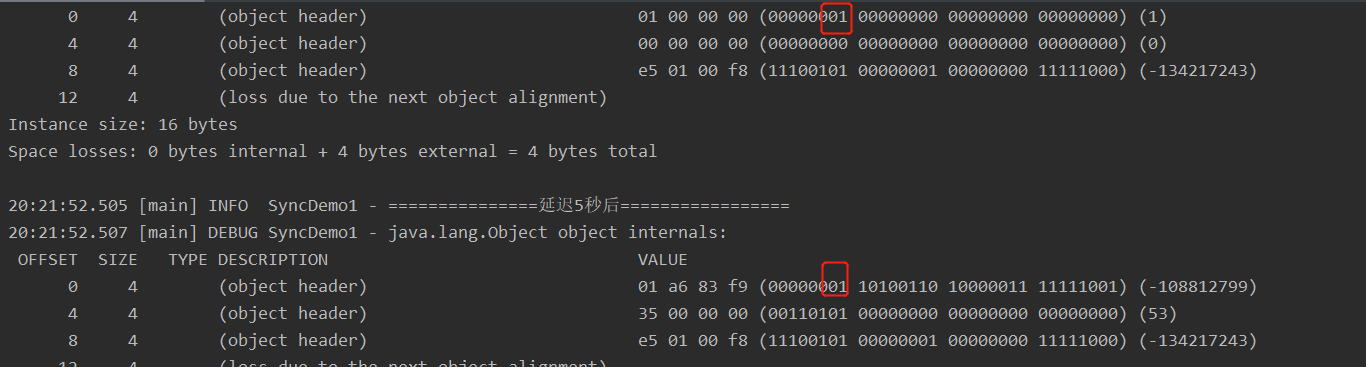
5s后偏向锁为可偏向或者匿名偏向状态,此时ThreadId=0;
偏向锁状态跟踪
@Slf4j
public class LockEscalationDemo{
private final static Logger log = LoggerFactory.getLogger(SyncDemo1.class);
public static void main(String[] args) throws InterruptedException {
log.debug(ClassLayout.parseInstance(new Object()).toPrintable());
//HotSpot 虚拟机在启动后有个 4s 的延迟才会对每个新建的对象开启偏向锁模式
Thread.sleep(5000);
log.info("===============延迟5秒后=================");
Object obj = new Object();
log.debug(ClassLayout.parseInstance(obj).toPrintable());
new Thread(new Runnable() {
@Override
public void run() {
log.debug(Thread.currentThread().getName()+"开始执行。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
synchronized (obj){
log.debug(Thread.currentThread().getName()+"获取锁执行中。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
}
log.debug(Thread.currentThread().getName()+"释放锁。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
}
},"thread1").start();
}
}

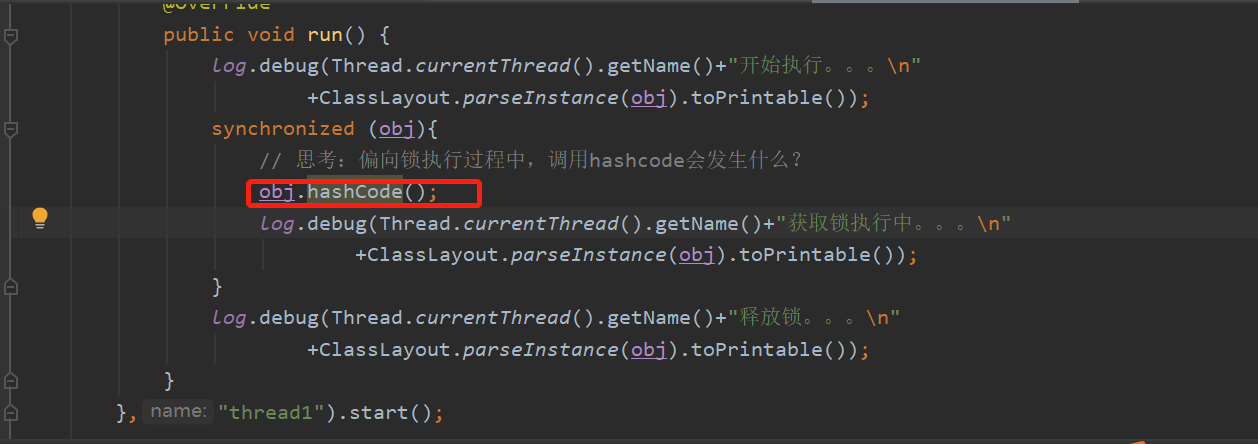
上图可以看出,只有一个线程时,从匿名偏向到偏向锁,并在偏向锁后面带上了线程id。
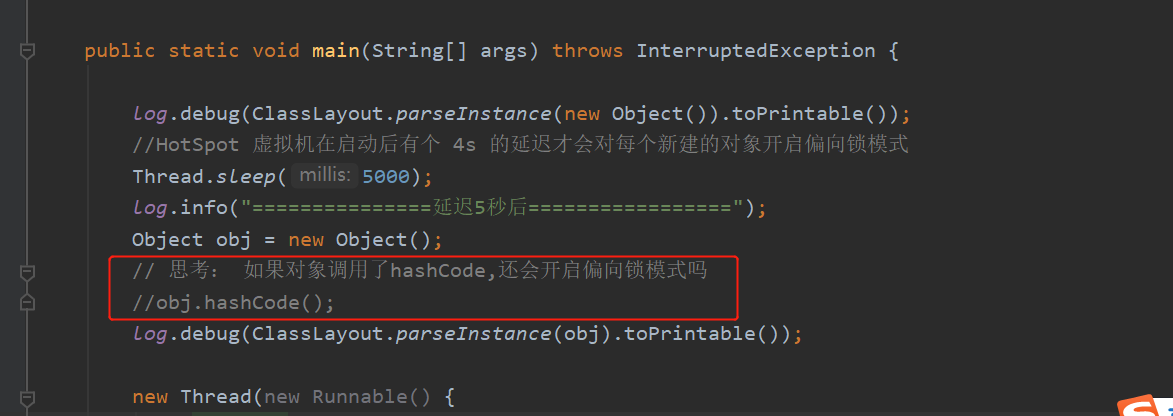
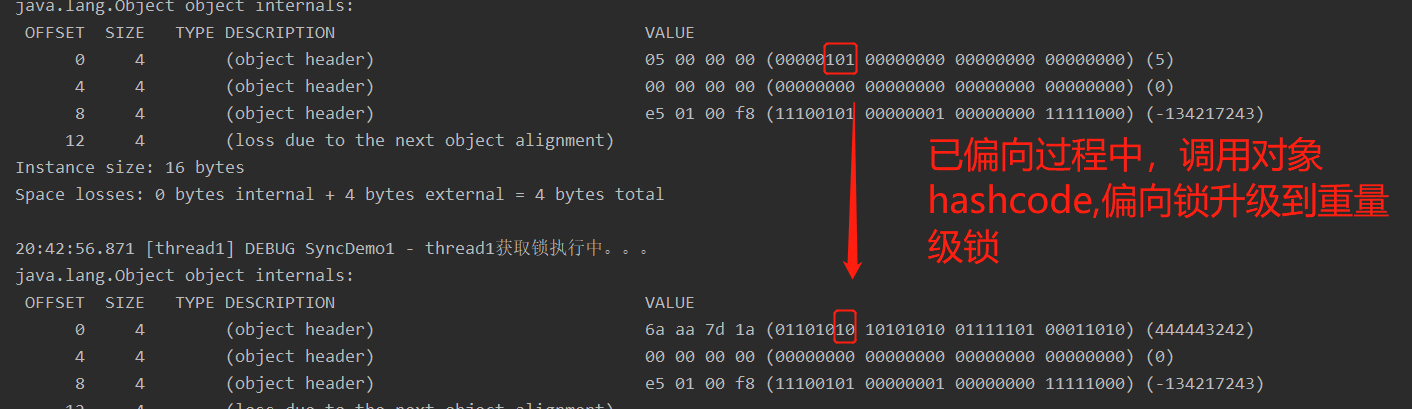
思考:如果对象调用了hashCode,还会开启偏向锁模式吗?
偏向锁撤销之调用对象HashCode
匿名偏向后,调用对象HashCode,导致偏向锁撤销。因为对于一个对象,其HashCode只会生成一次并保存,偏向锁是没有地方保存hashcode的。
- 轻量级锁会在锁记录中记录 hashCode
- 重量级锁会在 Monitor 中记录 hashCode
当对象处于匿名偏向(也就是线程ID为0)和已偏向的状态下,调用HashCode计算将会使对象再也无法偏向。 - 当对象匿名偏向,MarkWord将变成未锁定状态,并只能升级成轻量锁;
- 当对象正处于偏向锁时,调用HashCode将使偏向锁强制升级成重量锁。
如下图

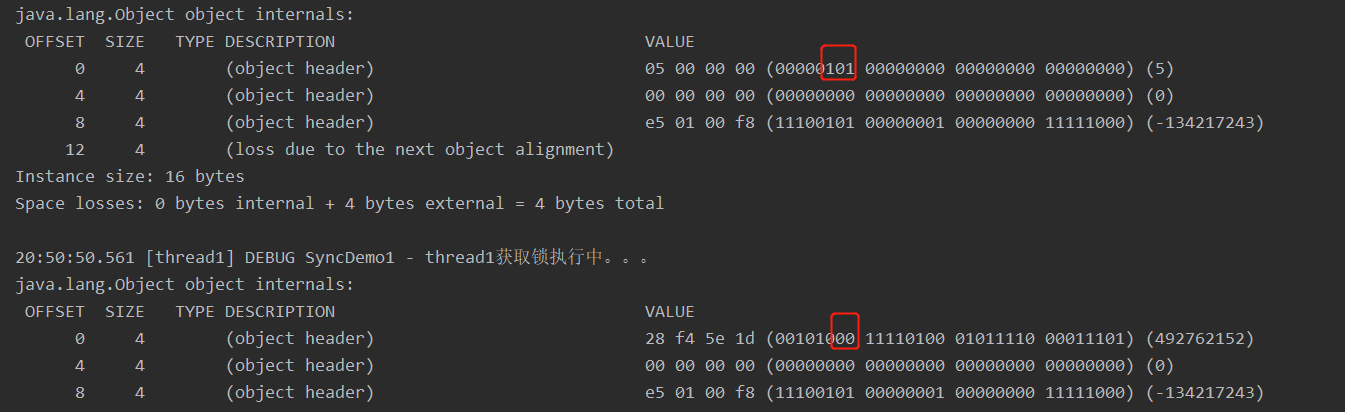
偏向锁撤销之调用wait/notify
偏向锁状态执行obj.notify() 会升级为轻量级锁,调用obj.wait(timeout) 会升级为重量级锁
synchronized (obj) {
obj.notify();
log.debug(Thread.currentThread().getName() + "获取锁执行中。。。\n"
+ ClassLayout.parseInstance(obj).toPrintable());
}
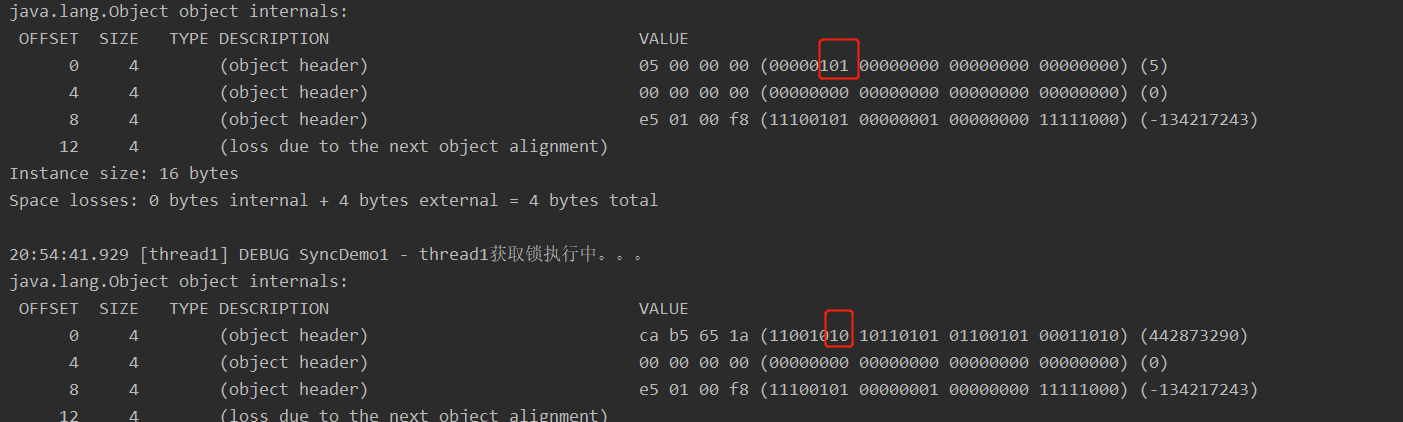
synchronized (obj) {
try {
obj.wait(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug(Thread.currentThread().getName() + "获取锁执行中。。。\n"
+ ClassLayout.parseInstance(obj).toPrintable());
}
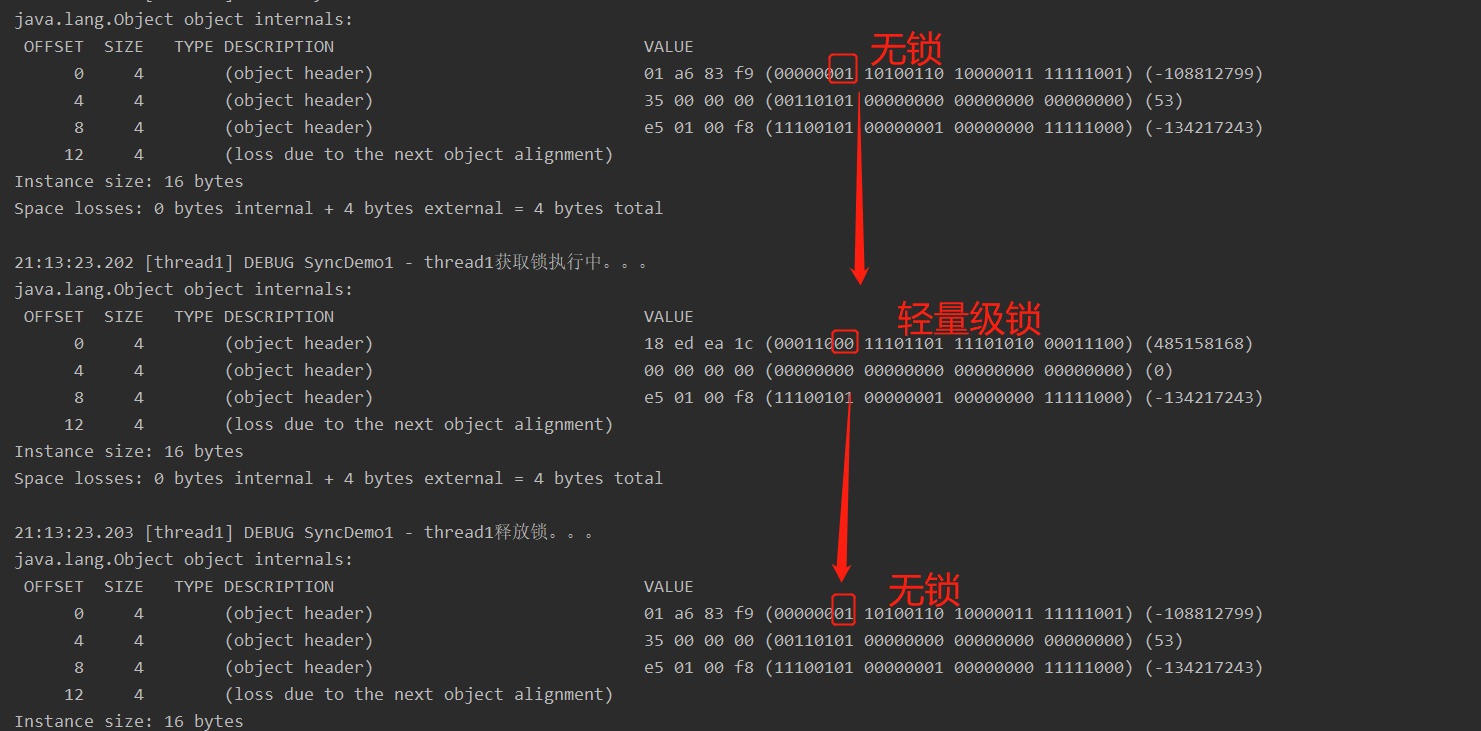
轻量级锁
倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,它还会尝试使用一种称为轻量级锁的优化手段,此时Mark Word 的结构也变为轻量级锁的结构。轻量级锁所适应的场景是线程交替执行同步块的场合,如果存在同一时间多个线程访问同一把锁的场合,就会导致轻量级锁膨胀为重量级锁。
轻量级锁跟踪
public class LockEscalationDemo {
public static void main(String[] args) throws InterruptedException {
log.debug(ClassLayout.parseInstance(new Object()).toPrintable());
//HotSpot 虚拟机在启动后有个 4s 的延迟才会对每个新建的对象开启偏向锁模式
Thread.sleep(4000);
Object obj = new Object();
// 思考: 如果对象调用了hashCode,还会开启偏向锁模式吗
obj.hashCode();
//log.debug(ClassLayout.parseInstance(obj).toPrintable());
new Thread(new Runnable() {
@Override
public void run() {
log.debug(Thread.currentThread().getName()+"开始执行。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
synchronized (obj){
log.debug(Thread.currentThread().getName()+"获取锁执行中。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
}
log.debug(Thread.currentThread().getName()+"释放锁。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
}
},"thread1").start();
Thread.sleep(5000);
log.debug(ClassLayout.parseInstance(obj).toPrintable());
}
}
偏向锁升级轻量级锁
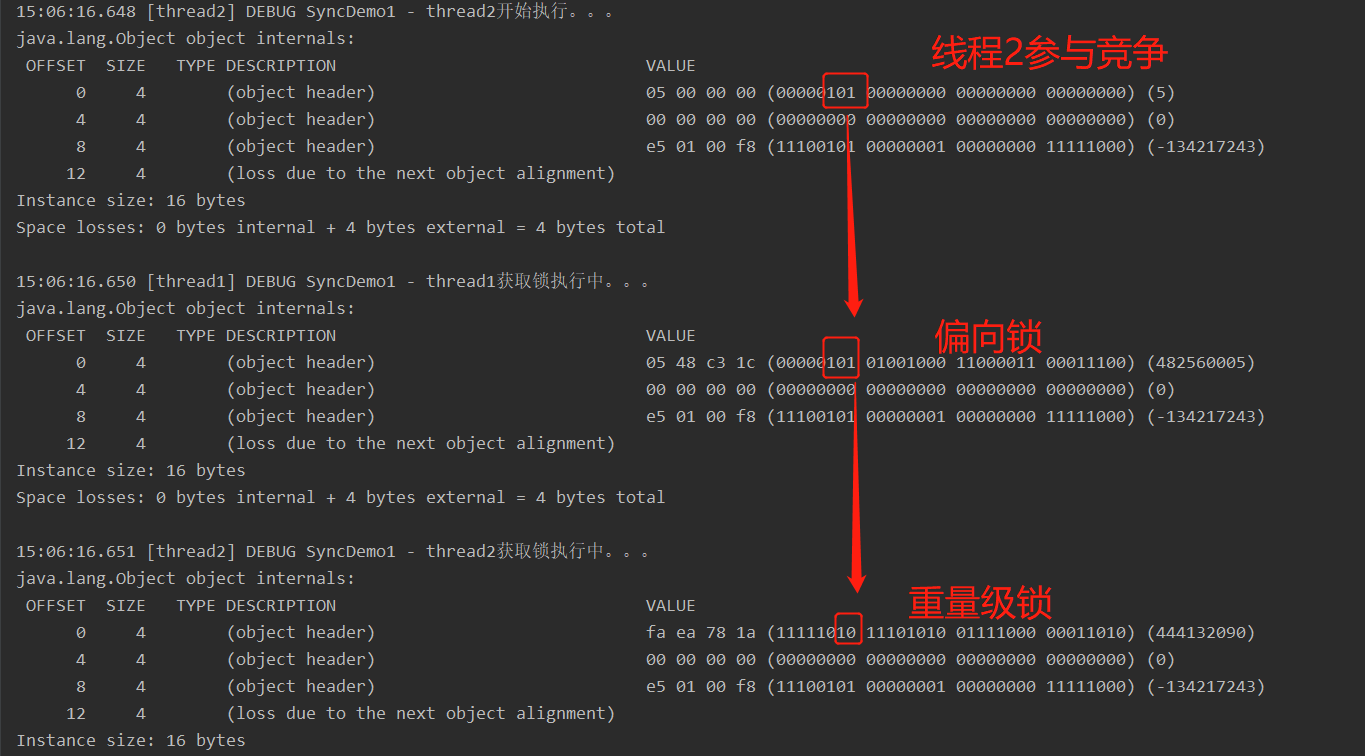
模拟两个线程轻度竞争场景
@Slf4j
public class LockEscalationDemo{
private final static Logger log = LoggerFactory.getLogger(SyncDemo1.class);
public static void main(String[] args) throws InterruptedException {
log.debug(ClassLayout.parseInstance(new Object()).toPrintable());
//HotSpot 虚拟机在启动后有个 4s 的延迟才会对每个新建的对象开启偏向锁模式
Thread.sleep(5000);
log.info("===============延迟5秒后=================");
Object obj = new Object();
log.debug(ClassLayout.parseInstance(obj).toPrintable());
new Thread(new Runnable() {
@Override
public void run() {
log.debug(Thread.currentThread().getName()+"开始执行。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
synchronized (obj){
log.debug(Thread.currentThread().getName()+"获取锁执行中。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
}
log.debug(Thread.currentThread().getName()+"释放锁。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
}
},"thread1").start();
//控制线程竞争时机
Thread.sleep(1);
new Thread(new Runnable() {
@Override
public void run() {
log.debug(Thread.currentThread().getName()+"开始执行。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
synchronized (obj){
log.debug(Thread.currentThread().getName()+"获取锁执行中。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
}
log.debug(Thread.currentThread().getName()+"释放锁。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
}
},"thread2").start();
}
}

轻量级锁膨胀为重量级锁
@Slf4j
public class LockEscalationDemo{
private final static Logger log = LoggerFactory.getLogger(SyncDemo1.class);
public static void main(String[] args) throws InterruptedException {
log.debug(ClassLayout.parseInstance(new Object()).toPrintable());
//HotSpot 虚拟机在启动后有个 4s 的延迟才会对每个新建的对象开启偏向锁模式
Thread.sleep(5000);
log.info("===============延迟5秒后=================");
Object obj = new Object();
// 思考: 如果对象调用了hashCode,还会开启偏向锁模式吗
// obj.hashCode();
log.debug(ClassLayout.parseInstance(obj).toPrintable());
new Thread(new Runnable() {
@Override
public void run() {
log.debug(Thread.currentThread().getName()+"开始执行。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
synchronized (obj){
// 思考:偏向锁执行过程中,调用hashcode会发生什么?
// obj.hashCode();
// obj.notify();
// try {
// obj.wait(50);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
log.debug(Thread.currentThread().getName()+"获取锁执行中。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
}
log.debug(Thread.currentThread().getName()+"释放锁。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
}
},"thread1").start();
//控制线程竞争时机
// Thread.sleep(1);
new Thread(new Runnable() {
@Override
public void run() {
log.debug(Thread.currentThread().getName()+"开始执行。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
synchronized (obj){
log.debug(Thread.currentThread().getName()+"获取锁执行中。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
}
log.debug(Thread.currentThread().getName()+"释放锁。。。\n"
+ClassLayout.parseInstance(obj).toPrintable());
}
},"thread2").start();
}
}
将上述控制线程竞争时机的代码注掉,让线程2与线程1发生竞争,线程2就由原来的偏向锁升级到重量级锁。
下面思考几个问题:
思考1:重量级锁释放之后变为无锁,此时有新的线程来调用同步块,会获取什么锁?
通过实验可以得出,后面的线程会获得轻量级锁,相当于线程竞争不激烈,多个线程通过CAS就能轮流获取锁,并且释放。
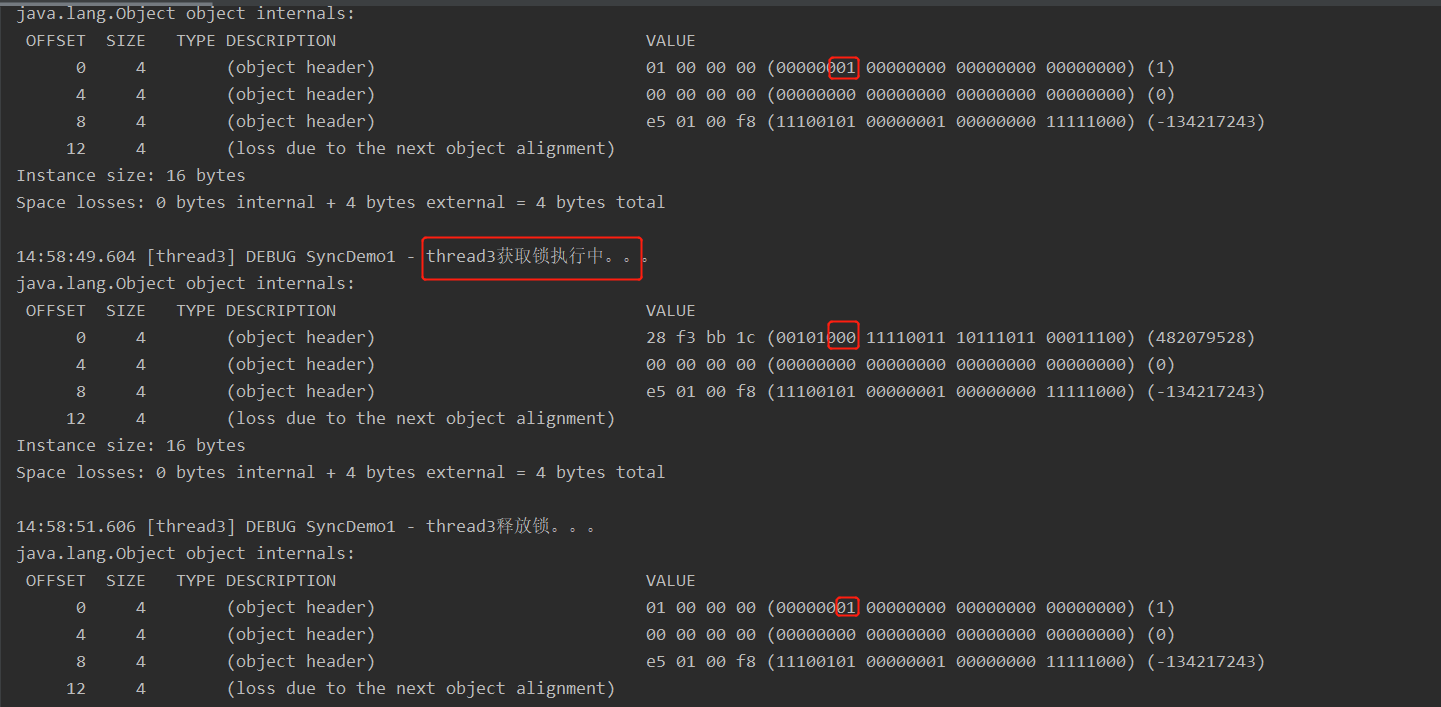
思考2:为什么有轻量级锁还需要重量级锁?
因为轻量级锁时通过CAS自旋的方式获取锁,该方式消耗CPU资源的,如果锁的时间长,或者自旋线程多,CPU会被大量消耗;而重量级锁有等待队列,所有拿不到锁的进入等待队列,不需要消耗CPU资源。
思考3:偏向锁是否一定比轻量级锁效率高吗?
不一定,在明确知道会有多线程竞争的情况下,偏向锁肯定会涉及锁撤销,需要暂停线程,回到安全点,并检查线程释放活着,故撤销需要消耗性能,这时候直接使用轻量级锁。
JVM启动过程,会有很多线程竞,所以默认情况启动时不打开偏向锁,过一段儿时间再打开。
锁升级的状态图

无锁是锁升级前的一个中间态,必须要恢复到无锁才能进行升级,因为需要有拷贝mark word的过程,并且修改指针。
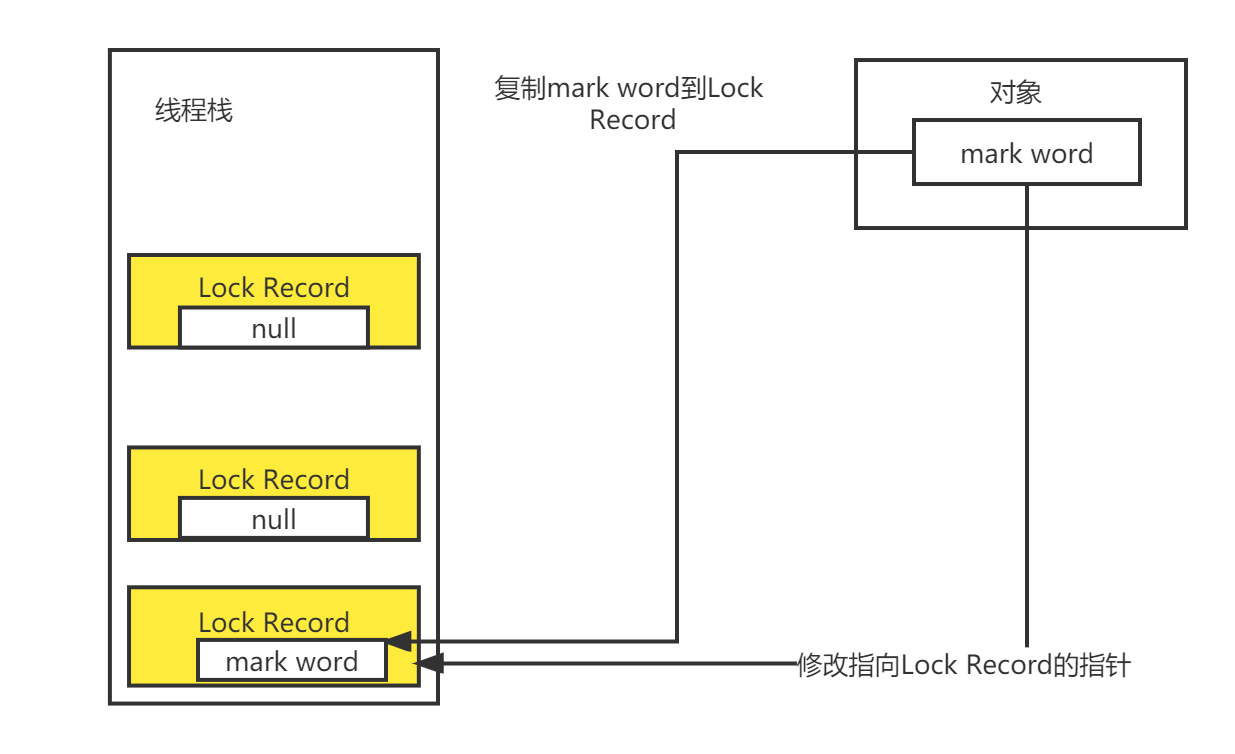
锁记录的重入
轻量级锁在拷贝mark word到线程栈Lock Record中时,如果有重入锁,则在线程栈中继续压栈Lock Record记录,只不过mark word的值为空,等到解锁后,依次弹出,最终将mard word恢复到对象头中,如图所示
锁升级的具体细节会稍后结合hotspot源码进行。
2.6 汇编层上面谈到的锁升级,一直提到了一个CAS操作,CAS是英文单词CompareAndSwap的缩写,中文意思是:比较并替换。CAS需要有3个操作数:内存地址V,旧的预期值A,即将要更新的目标值B。
CAS指令执行时,当且仅当内存地址V的值与预期值A相等时,将内存地址V的值修改为B,否则就什么都不做。整个比较并替换的操作是一个原子操作。
这个方法是java native方法,在unsafe类中,
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
需要打开hotspot的unsafe.cpp
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
可以看到调用了Atomic::cmpxchg方法,Atomic::cmpxchg方法引入了汇编指令,
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
-
mp是os::is_MP()的返回结果,os::is_MP()是一个内联函数,用来判断当前系统是否为多处理器。如果当前系统是多处理器,该函数返回1。否则,返回0。
-
__asm__代表是汇编开始,volatile代表,禁止CPU指令重排,并且让值修改后,立马被其他CPU可见,保持数据一致性。
-
LOCK_IF_MP(mp)会根据mp的值来决定是否为cmpxchg指令添加lock前缀。如果通过mp判断当前系统是多处理器(即mp值为1),则为cmpxchg指令添加lock前缀。否则,不加lock前缀。
内嵌汇编模板
asm ( assembler template
: output operands (optional)
: input operands (optional)
: list of clobbered registers
(optional)
);
这里涉及操作内存,与CPU的寄存器,大致意思就是在先判断CPU是否多核,如果是多核,禁止CPU级别的指令重排,并且通过Lock前缀指令,锁住并进行比较与交换,然后把最新的值同步到内存,其他CPU从内存加载数据取最新的值。
2.7 CPU指令层上面LOCK_IF_MP在atomic_linux_x86.inline.hpp有详细宏定义
#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
很明显,带了一个lock前缀的指令,lock 和cmpxchgl是CPU指令,lock指令是个前缀,可以修饰其他指令,cmpxchgl即为CAS指令,查阅英特尔操作手册,在Intel® 64 and IA-32 Architectures Software Developer’s Manual 中的章节LOCK—Assert LOCK# Signal Prefix 中给出LOCK指令的详细解释
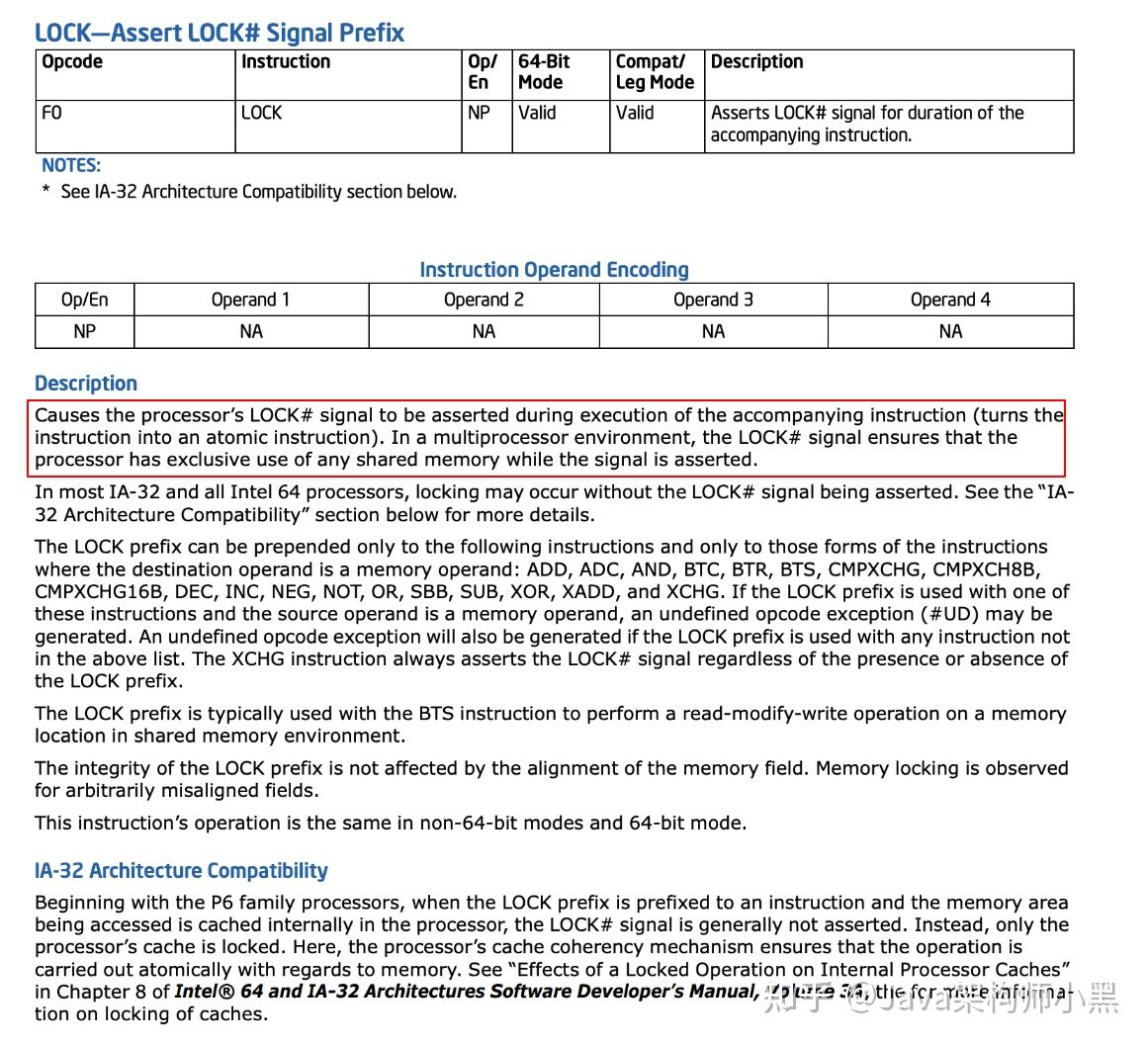
就是排他的使用共享内存。这里一般有两种方式,锁总线与锁cpu的缓存行
- 锁总线
LOCK#信号就是我们经常说到的总线锁,处理器使用LOCK#信号达到锁定总线,来解决原子性问题,当一个处理器往总线上输出LOCK#信号时,其它处理器的请求将被阻塞,此时该处理器此时独占共享内存;总线锁这种做法锁定的范围太大了,导致CPU利用率急剧下降,因为使用LOCK#是把CPU和内存之间的通信锁住了,这使得锁定时期间,其它处理器不能操作其内存地址的数据 ,所以总线锁的开销比较大。 - 锁缓存行
如果访问的内存区域已经缓存在处理器的缓存行中,P6系统和之后系列的处理器则不会声明LOCK#信号,它会对CPU的缓存中的缓存行进行锁定,在锁定期间,其它 CPU 不能同时缓存此数据,在修改之后,通过缓存一致性协议(在Intel CPU中,则体现为MESI协议)来保证修改的原子性,这个操作被称为缓存锁
lock指令会产生总线锁也可能会产生缓存锁,看具体的条件,有下面几种情况只能使用总线锁
- 当操作的数据不能被缓存在处理器内部,这个必须得使用总线锁了
- 操作的数据跨多个缓存行(cache line),缓存锁的前置条件是多个数据在一个缓存行里面
- 有些处理器不支持缓存锁定。对于Intel 486和奔腾处理器,就算锁定的内存区域在处理器的缓存行中也会调用总线锁定。
无论是总线锁还是缓存锁这都是CPU在硬件层面上提供的锁,肯定效率比软件层面的锁要高。
3. synchronized锁优化偏向锁批量重偏向&批量撤销
从偏向锁的加锁解锁过程中可看出,当只有一个线程反复进入同步块时,偏向锁带来的性能开销基本可以忽略,但是当有其他线程尝试获得锁时,就需要等到safe point时,再将偏向锁撤销为无锁状态或升级为轻量级,会消耗一定的性能,所以在多线程竞争频繁的情况下,偏向锁不仅不能提高性能,还会导致性能下降。于是,就有了批量重偏向与批量撤销的机制。
原理
以class为单位,为每个class维护一个偏向锁撤销计数器,每一次该class的对象发生偏向撤销操作时,该计数器+1,当这个值达到重偏向阈值(默认20)时,JVM就认为该class的偏向锁有问题,因此会进行批量重偏向。
每个class对象会有一个对应的epoch字段,每个处于偏向锁状态对象的Mark Word中也有该字段,其初始值为创建该对象时class中的epoch的值。每次发生批量重偏向时,就将该值+1,同时遍历JVM中所有线程的栈,找到该class所有正处于加锁状态的偏向锁,将其epoch字段改为新值。下次获得锁时,发现当前对象的epoch值和class的epoch不相等,那就算当前已经偏向了其他线程,也不会执行撤销操作,而是直接通过CAS操作将其Mark Word的Thread Id 改成当前线程Id。
当达到重偏向阈值(默认20)后,假设该class计数器继续增长,当其达到批量撤销的阈值后(默认40),JVM就认为该class的使用场景存在多线程竞争,会标记该class为不可偏向,之后,对于该class的锁,直接走轻量级锁的逻辑。
应用场景
批量重偏向(bulk rebias)机制是为了解决:一个线程创建了大量对象并执行了初始的同步操作,后来另一个线程也来将这些对象作为锁对象进行操作,这样会导致大量的偏向锁撤销操作。批量撤销(bulk revoke)机制是为了解决:在明显多线程竞争剧烈的场景下使用偏向锁是不合适的。
JVM的默认参数值
设置JVM参数-XX:+PrintFlagsFinal,在项目启动时即可输出JVM的默认参数值
intx BiasedLockingBulkRebiasThreshold = 20 //默认偏向锁批量重偏向阈值
intx BiasedLockingBulkRevokeThreshold = 40 //默认偏向锁批量撤销阈值
我们可以通过-XX:BiasedLockingBulkRebiasThreshold 和 -XX:BiasedLockingBulkRevokeThreshold 来手动设置阈值
测试:批量重偏向
@Slf4j
public class BiasedLockingTest {
private final static Logger log = LoggerFactory.getLogger(BiasedLockingTest.class);
public static void main(String[] args) throws InterruptedException {
//延时产生可偏向对象
Thread.sleep(5000);
// 创建一个list,来存放锁对象
List<Object> list = new ArrayList<>();
// 线程1
new Thread(() -> {
for (int i = 0; i < 50; i++) {
// 新建锁对象
Object lock = new Object();
synchronized (lock) {
list.add(lock);
}
}
try {
//为了防止JVM线程复用,在创建完对象后,保持线程thead1状态为存活
Thread.sleep(100000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "thead1").start();
//睡眠3s钟保证线程thead1创建对象完成
Thread.sleep(3000);
log.debug("打印thead1,list中第20个对象的对象头:");
log.debug((ClassLayout.parseInstance(list.get(19)).toPrintable()));
// 线程2
new Thread(() -> {
for (int i = 0; i < 40; i++) {
Object obj = list.get(i);
synchronized (obj) {
if(i>=15&&i<=21||i>=38){
log.debug("thread2-第" + (i + 1) + "次加锁执行中\t"+
ClassLayout.parseInstance(obj).toPrintable());
}
}
if(i==17||i==19){
log.debug("thread2-第" + (i + 1) + "次释放锁\t"+
ClassLayout.parseInstance(obj).toPrintable());
}
}
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "thead2").start();
Thread.sleep(3000);
new Thread(() -> {
for (int i = 0; i < 50; i++) {
Object lock =list.get(i);
if(i>=17&&i<=21||i>=35&&i<=41){
log.debug("thread3-第" + (i + 1) + "次准备加锁\t"+
ClassLayout.parseInstance(lock).toPrintable());
}
synchronized (lock){
if(i>=17&&i<=21||i>=35&&i<=41){
log.debug("thread3-第" + (i + 1) + "次加锁执行中\t"+
ClassLayout.parseInstance(lock).toPrintable());
}
}
}
},"thread3").start();
Thread.sleep(3000);
log.debug("查看新创建的对象");
log.debug((ClassLayout.parseInstance(new Object()).toPrintable()));
LockSupport.park();
}
}
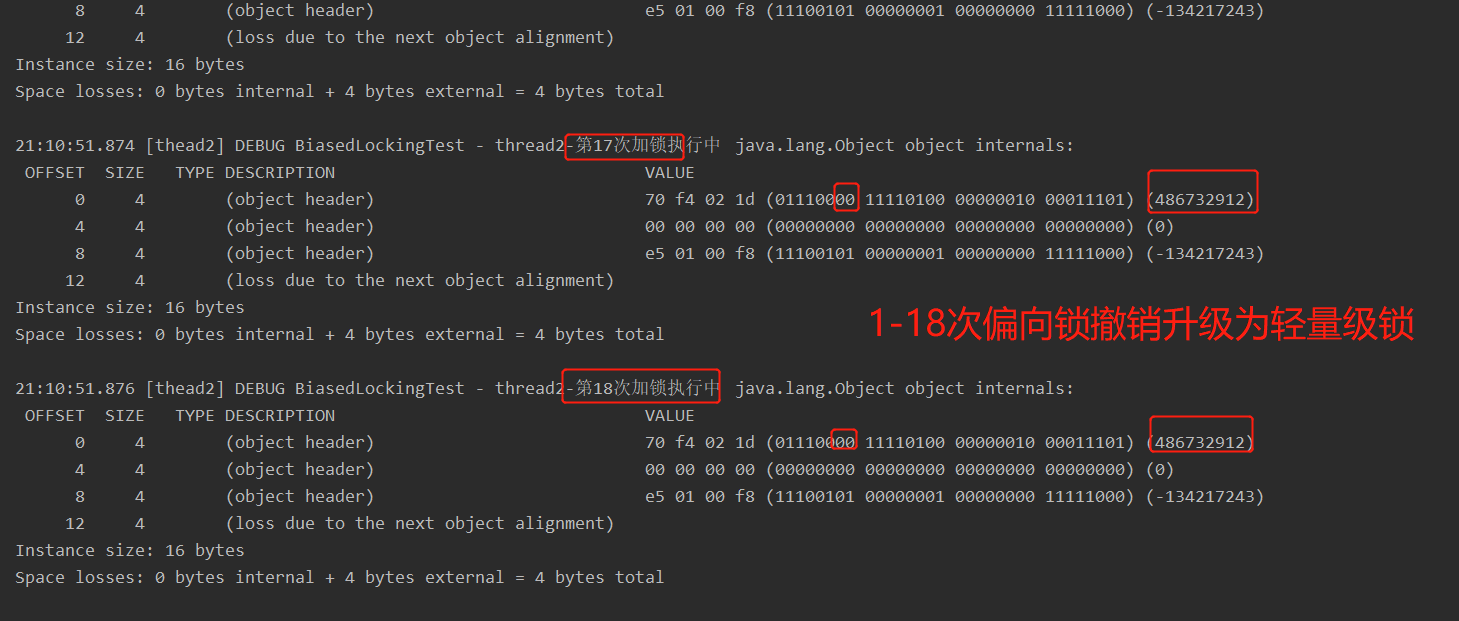
当撤销偏向锁阈值超过 20 次后,jvm 会这样觉得,我是不是偏向错了,于是会在给这些对象加锁时重新偏向至加锁线程,重偏向会重置象 的 Thread ID
测试结果:
thread1: 创建50个偏向线程thread1的偏向锁 1-50 偏向锁

thread2:
1-18 偏向锁撤销,升级为轻量级锁 (thread1释放锁之后为偏向锁状态)
19-40 偏向锁撤销达到阈值(20),执行了批量重偏向 (测试结果在第19就开始批量重偏向了)
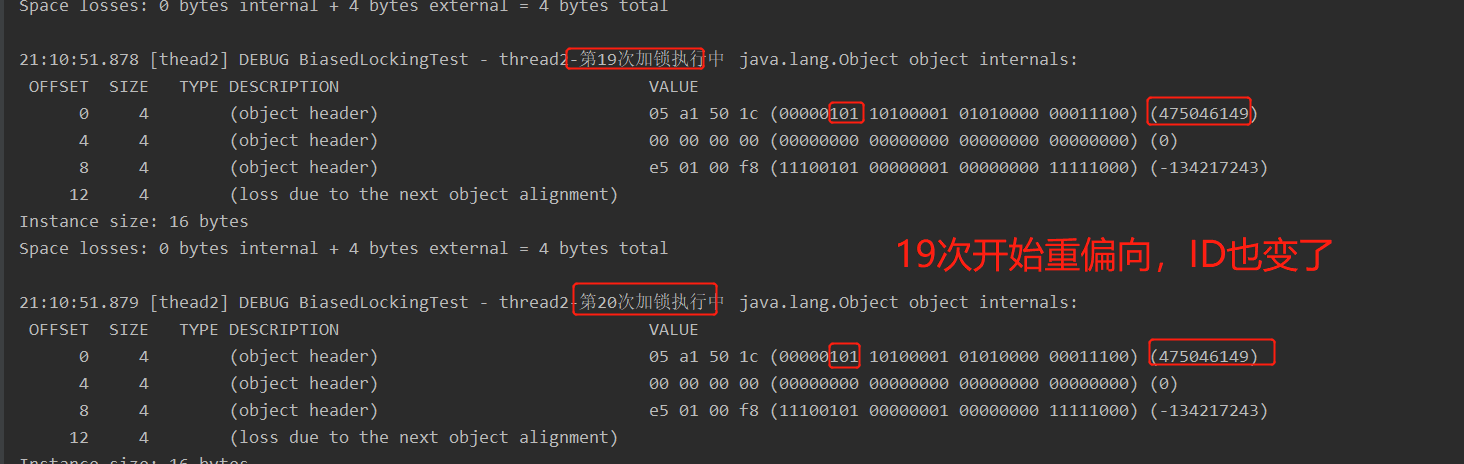
测试:批量撤销
当撤销偏向锁阈值超过 40 次后,jvm 会认为不该偏向,于是整个类的所有对象都会变为不可偏向的,新建的对象也是不可偏向的。
thread3:
1-18 从无锁状态直接获取轻量级锁 (thread2释放锁之后变为无锁状态)
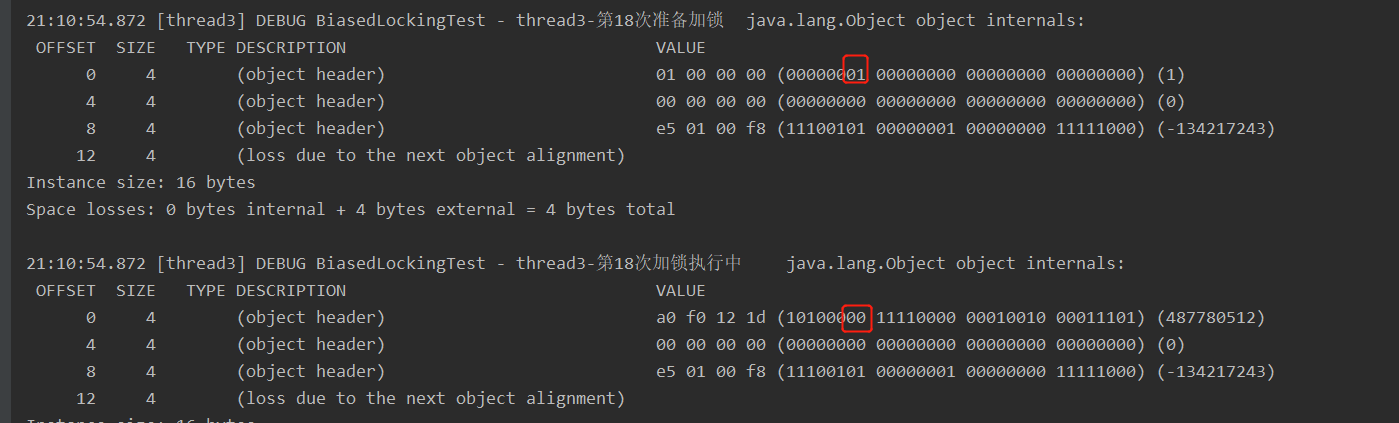
19-40 偏向锁撤销,升级为轻量级锁 (thread2释放锁之后为偏向锁状态)
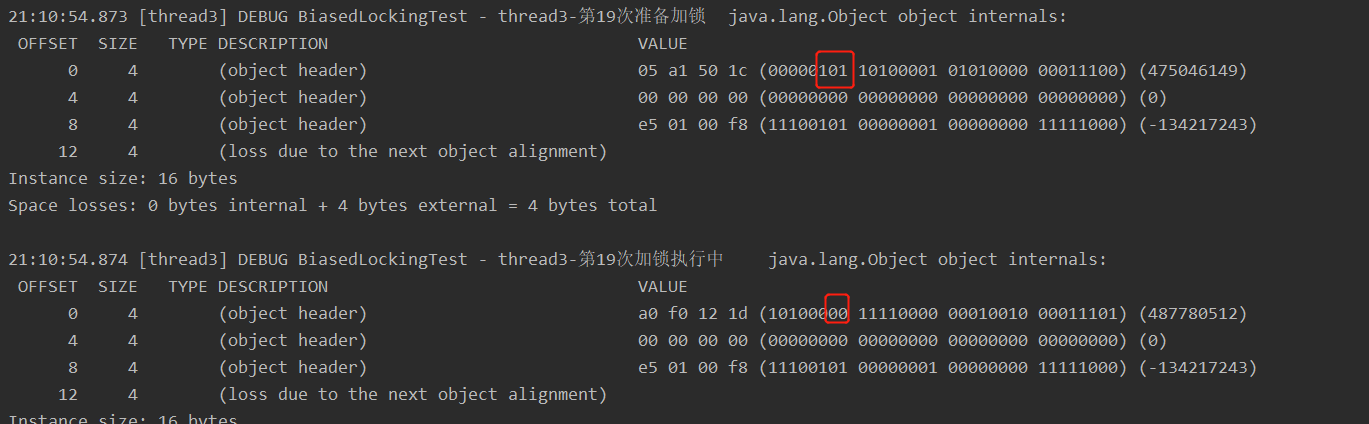
41-50 达到偏向锁撤销的阈值40,批量撤销偏向锁,升级为轻量级锁 (thread1释放锁之后为偏向锁状态)
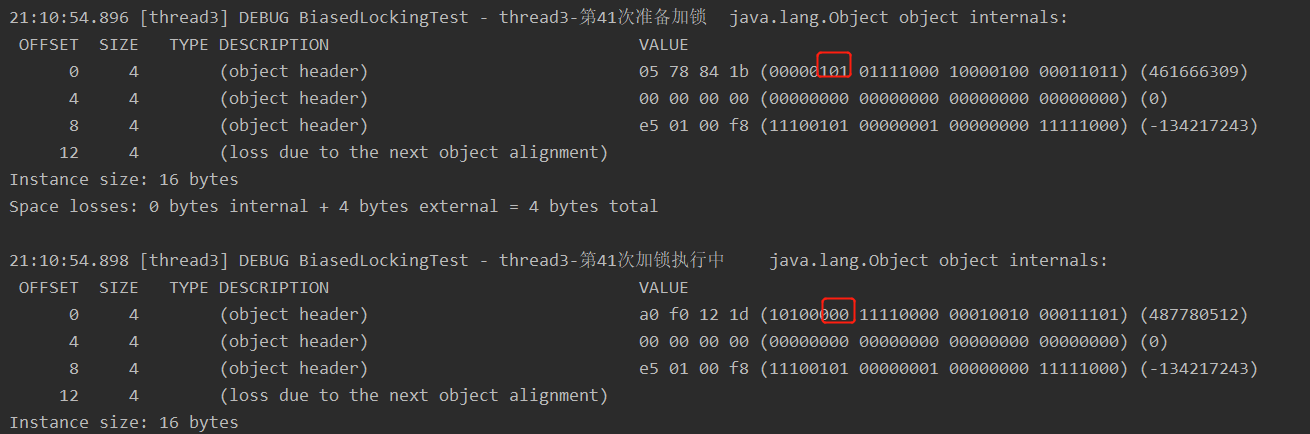
新创建的对象: 无锁状态
总结
- 批量重偏向和批量撤销是针对类的优化,和对象无关;
- 偏向锁重偏向一次之后不可再次重偏向;
- 当某个类已经触发批量撤销机制后,JVM会默认当前类产生了严重的问题,剥夺了该类的新实例对象使用偏向锁的权利。
自旋优化
量级锁竞争的时候,还可以使用自旋来进行优化,如果当前线程自旋成功(即这时候持锁线程已经退出了同步块,释放了锁),这时当前线程就可以避免阻塞。
- 自旋会占用 CPU 时间,单核 CPU 自旋就是浪费,多核 CPU 自旋才能发挥优势。
- 在 Java 6 之后自旋是自适应的,比如对象刚刚的一次自旋操作成功过,那么认为这次自旋成功的可能性会高,就多自旋几次;反之,就少自旋甚至不自旋,比较智能。
- Java 7 之后不能控制是否开启自旋功能。
注意:自旋的目的是为了减少线程挂起的次数,尽量避免直接挂起线程(挂起操作涉及系统调用,存在用户态和内核态切换,这才是重量级锁最大的开销)
锁粗化
假设一系列的连续操作都会对同一个对象反复加锁及解锁,甚至加锁操作是出现在循环体中的,即使没有出现线程竞争,频繁地进行互斥同步操作也会导致不必要的性能损耗。如果JVM检测到有一连串零碎的操作都是对同一对象的加锁,将会扩大加锁同步的范围(即锁粗化)到整个操作序列的外部。
StringBuffer buffer = new StringBuffer();
/**
* 锁粗化
*/
public void append(){
buffer.append("aaa").append(" bbb").append(" ccc");
}
上述代码每次调用 buffer.append 方法都需要加锁和解锁,如果JVM检测到有一连串的对同一个对象加锁和解锁的操作,就会将其合并成一次范围更大的加锁和解锁操作,即在第一次append方法时进行加锁,最后一次append方法结束后进行解锁。
锁消除
锁消除即删除不必要的加锁操作。锁消除是Java虚拟机在JIT编译期间,通过对运行上下文的扫描,去除不可能存在共享资源竞争的锁,通过锁消除,可以节省毫无意义的请求锁时间。
StringBuffer的append是个同步方法,但是append方法中的 StringBuffer 属于一个局部变量,不可能从该方法中逃逸出去,因此其实这过程是线程安全的,可以将锁消除。
public void append(String str1, String str2) {
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(str1).append(str2);
}
public static void main(String[] args) throws InterruptedException {
LockEliminationTest demo = new LockEliminationTest();
long start = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
demo.append("aaa", "bbb");
}
long end = System.currentTimeMillis();
System.out.println("执行时间:" + (end - start) + " ms");
}
通过比较实际,开启锁消除用时4秒多,未开启锁消除用时6秒多。
测试代码:
/**
进行两种测试
* 关闭逃逸分析,同时调大堆空间,避免堆内GC的发生,如果有GC信息将会被打印出来
* VM运行参数:-Xmx4G -Xms4G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
*
* 开启逃逸分析 jdk8默认开启
* VM运行参数:-Xmx4G -Xms4G -XX:+DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
*
* 执行main方法后
* jps 查看进程
* jmap -histo 进程ID
*
*/
@Slf4j
public class EscapeTest {
private final static Logger log = LoggerFactory.getLogger(EscapeTest.class);
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < 500000; i++) {
alloc();
}
long end = System.currentTimeMillis();
log.info("执行时间:" + (end - start) + " ms");
try {
Thread.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
/**
* JIT编译时会对代码进行逃逸分析
* 并不是所有对象存放在堆区,有的一部分存在线程栈空间
* Ponit没有逃逸
*/
private static String alloc() {
Point point = new Point();
return point.toString();
}
/**
*同步省略(锁消除) JIT编译阶段优化,JIT经过逃逸分析之后发现无线程安全问题,就会做锁消除
*/
public void append(String str1, String str2) {
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(str1).append(str2);
}
/**
* 标量替换
*
*/
private static void test2() {
Point point = new Point(1,2);
System.out.println("point.x="+point.getX()+"; point.y="+point.getY());
// int x=1;
// int y=2;
// System.out.println("point.x="+x+"; point.y="+y);
}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
class Point{
private int x;
private int y;
}
通过测试发现,开启逃逸分析后,线程实例总共50万个,只有8万多个在堆中,其他都在栈上分配;
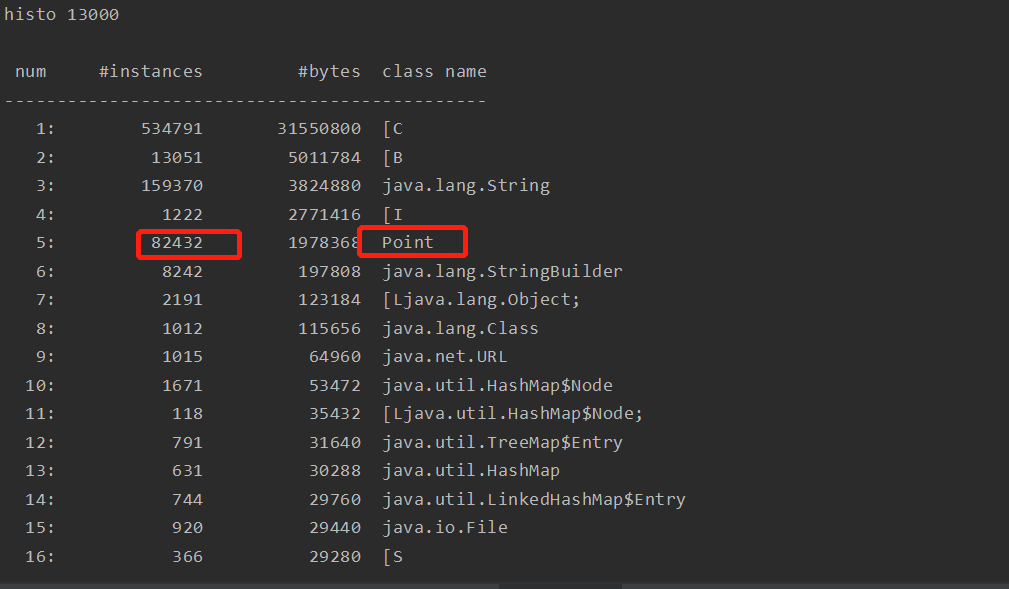
关闭逃逸分析后50万全部都在堆中。
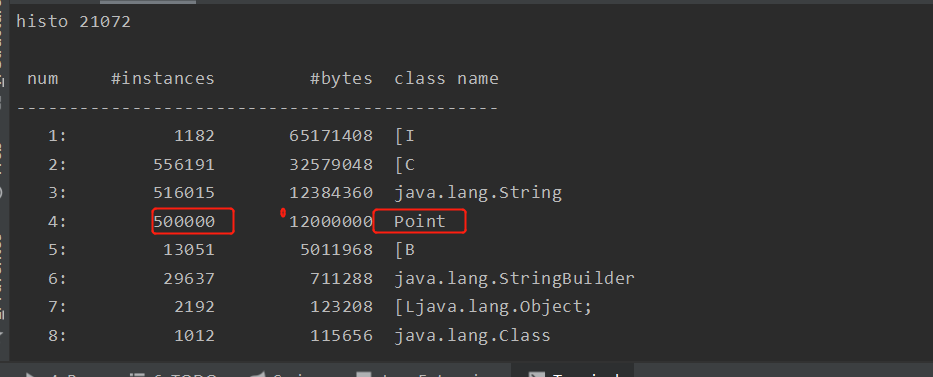
首先准备好HotSpot源码
jdk8 hotspot源码下载地址:http://hg.openjdk.java.net/jdk8u/jdk8u/hotspot/,选择gz或者zip包下载。
目录结构

- cpu:和cpu相关的一些操作
- os:在不同操作系统上的一些区别操作
- os_cpu:关联os和cpu的实现
- share:公共代码
share下面还有两个目录
- tools:一些工具类
- vm:公共源码
然后使用Source Insight工具打开源码工程,如下图
首先看入口InterpreterRuntime:: monitorenter方法
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))
#ifdef ASSERT
thread->last_frame().interpreter_frame_verify_monitor(elem);
#endif
if (PrintBiasedLockingStatistics) {
Atomic::inc(BiasedLocking::slow_path_entry_count_addr());
}
Handle h_obj(thread, elem->obj());
assert(Universe::heap()->is_in_reserved_or_null(h_obj()),
"must be NULL or an object");
if (UseBiasedLocking) {
// Retry fast entry if bias is revoked to avoid unnecessary inflation
ObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);
} else {
ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);
}
assert(Universe::heap()->is_in_reserved_or_null(elem->obj()),
"must be NULL or an object");
#ifdef ASSERT
thread->last_frame().interpreter_frame_verify_monitor(elem);
#endif
IRT_END
看到上面注解Retry fast entry if bias is revoked to avoid unnecessary inflation,意思就是如果偏向锁打开,就直接进入ObjectSynchronizer的fast_enter方法,避免不必要的膨胀,否则进入slow_enter方法,由此可知偏向锁执行fast_enter方法,锁的升级则进入slow_enter方法。
接着进入synchronizer.cpp
void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock, bool attempt_rebias, TRAPS) {
// 如果偏向锁打开
if (UseBiasedLocking) {
// 非安全点
if (!SafepointSynchronize::is_at_safepoint()) {
// 重偏向
BiasedLocking::Condition cond = BiasedLocking::revoke_and_rebias(obj, attempt_rebias, THREAD);
if (cond == BiasedLocking::BIAS_REVOKED_AND_REBIASED) {
return;
}
// 回到安全点
} else {
assert(!attempt_rebias, "can not rebias toward VM thread");
BiasedLocking::revoke_at_safepoint(obj);
}
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
}
// 重点看
slow_enter (obj, lock, THREAD) ;
}
void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) {
markOop mark = obj->mark();
assert(!mark->has_bias_pattern(), "should not see bias pattern here");
// 判断是否无锁
if (mark->is_neutral()) {
// Anticipate successful CAS -- the ST of the displaced mark must
// be visible <= the ST performed by the CAS.
//把mark word保存到偏向锁的displaced_header字段上
lock->set_displaced_header(mark);
// 通过CAS将mark word更新为指向Lock Record的指针
if (mark == (markOop) Atomic::cmpxchg_ptr(lock, obj()->mark_addr(), mark)) {
TEVENT (slow_enter: release stacklock) ;
return ;
}
// Fall through to inflate() ...
} else
// 已经有锁,并且mark中的指针指向当前线程的指针
if (mark->has_locker() && THREAD->is_lock_owned((address)mark->locker())) {
assert(lock != mark->locker(), "must not re-lock the same lock");
assert(lock != (BasicLock*)obj->mark(), "don't relock with same BasicLock");
// 锁重入,将null入栈到本地线程栈
lock->set_displaced_header(NULL);
return;
}
#if 0
// The following optimization isn't particularly useful.
if (mark->has_monitor() && mark->monitor()->is_entered(THREAD)) {
lock->set_displaced_header (NULL) ;
return ;
}
#endif
// The object header will never be displaced to this lock,
// so it does not matter what the value is, except that it
// must be non-zero to avoid looking like a re-entrant lock,
// and must not look locked either.
lock->set_displaced_header(markOopDesc::unused_mark());
// 1.先膨胀生成ObjectMonitor对象,
// 2.再进入enter方法
ObjectSynchronizer::inflate(THREAD, obj())->enter(THREAD);
}
首先看ObjectMonitor生成的过程。
ObjectMonitor * ATTR ObjectSynchronizer::inflate (Thread * Self, oop object) {
// Inflate mutates the heap ...
// Relaxing assertion for bug 6320749.
assert (Universe::verify_in_progress() ||
!SafepointSynchronize::is_at_safepoint(), "invariant") ;
//循环,保证多线程同时调用
for (;;) {
const markOop mark = object->mark() ;
assert (!mark->has_bias_pattern(), "invariant") ;
// The mark can be in one of the following states:
// * Inflated - just return 重量级锁直接返回
// * Stack-locked - coerce it to inflated 轻量级锁则膨胀
// * INFLATING - busy wait for conversion to complete 膨胀中,则等膨胀完成
// * Neutral - aggressively inflate the object. 无锁状态则膨胀
// * BIASED - Illegal. We should never see this 非法状态, 不会出现
// CASE: inflated 如果重量级锁
if (mark->has_monitor()) {
// 获取指向ObjectMonitor的指针,并直接返回
ObjectMonitor * inf = mark->monitor() ;
assert (inf->header()->is_neutral(), "invariant");
assert (inf->object() == object, "invariant") ;
assert (ObjectSynchronizer::verify_objmon_isinpool(inf), "monitor is invalid");
return inf ;
}
// CASE: inflation in progress - inflating over a stack-lock.
// Some other thread is converting from stack-locked to inflated.
// Only that thread can complete inflation -- other threads must wait.
// The INFLATING value is transient.
// Currently, we spin/yield/park and poll the markword, waiting for inflation to finish.
// We could always eliminate polling by parking the thread on some auxiliary list.
// 检查是否在膨胀状态,如果膨胀,调用ReadStableMark等待
if (mark == markOopDesc::INFLATING()) {
TEVENT (Inflate: spin while INFLATING) ;
ReadStableMark(object) ;
continue ;
}
// CASE: stack-locked
// Could be stack-locked either by this thread or by some other thread.
//
// Note that we allocate the objectmonitor speculatively, _before_ attempting
// to install INFLATING into the mark word. We originally installed INFLATING,
// allocated the objectmonitor, and then finally STed the address of the
// objectmonitor into the mark. This was correct, but artificially lengthened
// the interval in which INFLATED appeared in the mark, thus increasing
// the odds of inflation contention.
//
// We now use per-thread private objectmonitor free lists.
// These list are reprovisioned from the global free list outside the
// critical INFLATING...ST interval. A thread can transfer
// multiple objectmonitors en-mass from the global free list to its local free list.
// This reduces coherency traffic and lock contention on the global free list.
// Using such local free lists, it doesn't matter if the omAlloc() call appears
// before or after the CAS(INFLATING) operation.
// See the comments in omAlloc().
/// 轻量级锁时,开始膨胀
if (mark->has_locker()) {
// 创建ObjectMonitor对象
ObjectMonitor * m = omAlloc (Self) ;
// Optimistically prepare the objectmonitor - anticipate successful CAS
// We do this before the CAS in order to minimize the length of time
// in which INFLATING appears in the mark.
// 对象初始化
m->Recycle();
m->_Responsible = NULL ;
m->OwnerIsThread = 0 ;
m->_recursions = 0 ;
m->_SpinDuration = ObjectMonitor::Knob_SpinLimit ; // Consider: maintain by type/class
// CAS设置为膨胀中
markOop cmp = (markOop) Atomic::cmpxchg_ptr (markOopDesc::INFLATING(), object->mark_addr(), mark) ;
// CAS失败,释放重试
if (cmp != mark) {
omRelease (Self, m, true) ;
continue ; // Interference -- just retry
}
// We've successfully installed INFLATING (0) into the mark-word.
// This is the only case where 0 will appear in a mark-work.
// Only the singular thread that successfully swings the mark-word
// to 0 can perform (or more precisely, complete) inflation.
//
// Why do we CAS a 0 into the mark-word instead of just CASing the
// mark-word from the stack-locked value directly to the new inflated state?
// Consider what happens when a thread unlocks a stack-locked object.
// It attempts to use CAS to swing the displaced header value from the
// on-stack basiclock back into the object header. Recall also that the
// header value (hashcode, etc) can reside in (a) the object header, or
// (b) a displaced header associated with the stack-lock, or (c) a displaced
// header in an objectMonitor. The inflate() routine must copy the header
// value from the basiclock on the owner's stack to the objectMonitor, all
// the while preserving the hashCode stability invariants. If the owner
// decides to release the lock while the value is 0, the unlock will fail
// and control will eventually pass from slow_exit() to inflate. The owner
// will then spin, waiting for the 0 value to disappear. Put another way,
// the 0 causes the owner to stall if the owner happens to try to
// drop the lock (restoring the header from the basiclock to the object)
// while inflation is in-progress. This protocol avoids races that might
// would otherwise permit hashCode values to change or "flicker" for an object.
// Critically, while object->mark is 0 mark->displaced_mark_helper() is stable.
// 0 serves as a "BUSY" inflate-in-progress indicator.
// fetch the displaced mark from the owner's stack.
// The owner can't die or unwind past the lock while our INFLATING
// object is in the mark. Furthermore the owner can't complete
// an unlock on the object, either.
// CAS成功,替换mark word到本地线程栈,并设置monitor的_header、_owner、_object
markOop dmw = mark->displaced_mark_helper() ;
assert (dmw->is_neutral(), "invariant") ;
// Setup monitor fields to proper values -- prepare the monitor
m->set_header(dmw) ;
// Optimization: if the mark->locker stack address is associated
// with this thread we could simply set m->_owner = Self and
// m->OwnerIsThread = 1. Note that a thread can inflate an object
// that it has stack-locked -- as might happen in wait() -- directly
// with CAS. That is, we can avoid the xchg-NULL .... ST idiom.
m->set_owner(mark->locker());
m->set_object(object);
// TODO-FIXME: assert BasicLock->dhw != 0.
// Must preserve store ordering. The monitor state must
// be stable at the time of publishing the monitor address.
guarantee (object->mark() == markOopDesc::INFLATING(), "invariant") ;
// 设置mark word为重量级锁状态
object->release_set_mark(markOopDesc::encode(m));
// Hopefully the performance counters are allocated on distinct cache lines
// to avoid false sharing on MP systems ...
if (ObjectMonitor::_sync_Inflations != NULL) ObjectMonitor::_sync_Inflations->inc() ;
TEVENT(Inflate: overwrite stacklock) ;
if (TraceMonitorInflation) {
if (object->is_instance()) {
ResourceMark rm;
tty->print_cr("Inflating object " INTPTR_FORMAT " , mark " INTPTR_FORMAT " , type %s",
(void *) object, (intptr_t) object->mark(),
object->klass()->external_name());
}
}
return m ;
}
// CASE: neutral
// TODO-FIXME: for entry we currently inflate and then try to CAS _owner.
// If we know we're inflating for entry it's better to inflate by swinging a
// pre-locked objectMonitor pointer into the object header. A successful
// CAS inflates the object *and* confers ownership to the inflating thread.
// In the current implementation we use a 2-step mechanism where we CAS()
// to inflate and then CAS() again to try to swing _owner from NULL to Self.
// An inflateTry() method that we could call from fast_enter() and slow_enter()
// would be useful.
assert (mark->is_neutral(), "invariant");
// 如果无锁状态,创建ObjectMonitor并初始化
ObjectMonitor * m = omAlloc (Self) ;
// prepare m for installation - set monitor to initial state
m->Recycle();
m->set_header(mark);
m->set_owner(NULL);
m->set_object(object);
m->OwnerIsThread = 1 ;
m->_recursions = 0 ;
m->_Responsible = NULL ;
m->_SpinDuration = ObjectMonitor::Knob_SpinLimit ; // consider: keep metastats by type/class
// CAS设置对象为重量级锁状态,CAS失败,释放重量级锁再重试
if (Atomic::cmpxchg_ptr (markOopDesc::encode(m), object->mark_addr(), mark) != mark) {
m->set_object (NULL) ;
m->set_owner (NULL) ;
m->OwnerIsThread = 0 ;
m->Recycle() ;
omRelease (Self, m, true) ;
m = NULL ;
continue ;
// interference - the markword changed - just retry.
// The state-transitions are one-way, so there's no chance of
// live-lock -- "Inflated" is an absorbing state.
}
// Hopefully the performance counters are allocated on distinct
// cache lines to avoid false sharing on MP systems ...
// 下面是缓存行避免伪共享发生的情况
if (ObjectMonitor::_sync_Inflations != NULL) ObjectMonitor::_sync_Inflations->inc() ;
TEVENT(Inflate: overwrite neutral) ;
if (TraceMonitorInflation) {
if (object->is_instance()) {
ResourceMark rm;
tty->print_cr("Inflating object " INTPTR_FORMAT " , mark " INTPTR_FORMAT " , type %s",
(void *) object, (intptr_t) object->mark(),
object->klass()->external_name());
}
}
return m ;
}
}
ObjectMonitor生成后,进入ObjectMonitor.enter方法,重量级加锁的逻辑都是在这里完成的。
void ATTR ObjectMonitor::enter(TRAPS) {
Thread * const Self = THREAD ;
void * cur ;
//通过CAS操作尝试将_owner变量设置为当前线程,如果_owner为NULL表示锁未被占用
//CAS:内存值、预期值、新值,只有当内存值==预期值,才能将新值替换内存值
cur = Atomic::cmpxchg_ptr (Self, &_owner, NULL) ;
if (cur == NULL) { //如果NULL,表示获取锁成功,直接返回即可
assert (_recursions == 0 , "invariant") ;
assert (_owner == Self, "invariant") ;
return ;
}
//线程重入,synchronized的可重入特性原理,_owner保存的线程与当前正在执行的线程相同,将_recursions++
if (cur == Self) {
_recursions ++ ;
return ;
}
//表示线程第一次进入monitor,则进行一些设置
if (Self->is_lock_owned ((address)cur)) {
assert (_recursions == 0, "internal state error");
_recursions = 1 ; //锁的次数设置为1
_owner = Self ; //将_owner设置为当前线程
OwnerIsThread = 1 ;
return ;
}
.....
//获取锁失败
for (;;) {
jt->set_suspend_equivalent();
//等待锁的释放
EnterI (THREAD) ;
if (!ExitSuspendEquivalent(jt)) break ;
_recursions = 0 ;
_succ = NULL ;
exit (false, Self) ;
jt->java_suspend_self();
}
Self->set_current_pending_monitor(NULL);
}
}
上面步骤总结为
- 1.通过CAS尝试将_owner变量设置为当前线程
- 2.如果是线程重入(下面有举例),则将_recurisons++
- 3.如果线程是第一次进入,则将_recurisons设置为1,将_owner设置为当前线程,该线程获取锁成功并返回
- 4.如果获取锁失败,则等待锁的释放
接着进入所等待源码
在锁竞争源码中最后一步,如果获取锁失败,则等待锁的释放,由MonitorObject类中的EnterI()方法来实现
void ATTR ObjectMonitor::EnterI (TRAPS) {
Thread * Self = THREAD ;
assert (Self->is_Java_thread(), "invariant") ;
assert (((JavaThread *) Self)->thread_state() == _thread_blocked , "invariant") ;
//再次尝试获取锁,获取成功直接返回
if (TryLock (Self) > 0) {
....
return ;
}
DeferredInitialize () ;
//尝试自旋获取锁,获取锁成功直接返回
if (TrySpin (Self) > 0) {
....
return ;
}
//前面的尝试都失败,则将该线程信息封装到node节点
ObjectWaiter node(Self) ;
Self->_ParkEvent->reset() ;
node._prev = (ObjectWaiter *) 0xBAD ;
node.TState = ObjectWaiter::TS_CXQ ;
ObjectWaiter * nxt ;
//将node节点插入到_cxq的头部,前面说过锁获取失败的线程首先会进入_cxq
//_cxq是一个单链表,等到一轮过去在该_cxq列表中的线程还未成功获取锁,
//则进入_EntryList列表
for (;;) { //注意这里的死循环操作
node._next = nxt = _cxq ;
//这里插入节点时也使用了CAS,因为可能有多个线程失败将加入_cxq链表
if (Atomic::cmpxchg_ptr (&node, &_cxq, nxt) == nxt) break ;
//如果线程CAS插入_cxq链表失败,它会再抢救一下看看能不能获取到锁
if (TryLock (Self) > 0) {
...
return ;
}
}
//竞争减弱时,将该线程设置为_Responsible(负责线程),定时轮询_owner
//后面该线程会调用定时的park方法,防止死锁
if ((SyncFlags & 16) == 0 && nxt == NULL && _EntryList == NULL) {
Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;
}
TEVENT (Inflated enter - Contention) ;
int nWakeups = 0 ;
int RecheckInterval = 1 ;
//前面获取锁失败的线程已经放入到了_cxq列表,但还未挂起
//下面是将_cxq列表挂起的代码,线程一旦挂起,必须唤醒之后才能继续操作
for (;;) {
//挂起之前,再次尝试获取锁,看看能不能成功,成功则跳出循环
if (TryLock (Self) > 0) break ;
assert (_owner != Self, "invariant") ;
if ((SyncFlags & 2) && _Responsible == NULL) {
Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;
}
//将当前线程挂起(park()方法)
// park self
//如果当前线程是_Responsible线程,则调用定时的park方法,防止死锁
if (_Responsible == Self || (SyncFlags & 1)) {
TEVENT (Inflated enter - park TIMED) ;
Self->_ParkEvent->park ((jlong) RecheckInterval) ;
// Increase the RecheckInterval, but clamp the value.
RecheckInterval *= 8 ;
if (RecheckInterval > 1000) RecheckInterval = 1000 ;
} else {
TEVENT (Inflated enter - park UNTIMED) ;
Self->_ParkEvent->park() ;
}
//当线程被唤醒之后,会再次尝试获取锁
if (TryLock(Self) > 0) break ;
//唤醒锁之后,还出现竞争,记录唤醒次数,这里的计数器
//并没有受锁的保护,也没有原子更新,为了获取更低的探究影响
TEVENT (Inflated enter - Futile wakeup) ;
if (ObjectMonitor::_sync_FutileWakeups != NULL) {
ObjectMonitor::_sync_FutileWakeups->inc() ;
}
++ nWakeups ; //唤醒次数
//自旋尝试获取锁
if ((Knob_SpinAfterFutile & 1) && TrySpin (Self) > 0) break ;
if ((Knob_ResetEvent & 1) && Self->_ParkEvent->fired()) {
Self->_ParkEvent->reset() ;
OrderAccess::fence() ;
}
if (_succ == Self) _succ = NULL ;
// Invariant: after clearing _succ a thread *must* retry _owner before parking.
OrderAccess::fence() ;
}
//已经获取到了锁,将当前节点从_EntryList队列中删除
UnlinkAfterAcquire (Self, &node) ;
if (_succ == Self) _succ = NULL ;
...
return ;
}
步骤分为如下几步:
- 1.首先tryLock再次尝试获取锁,之后再CAS尝试获取锁;失败后将当前线程信息封装成ObjectWaiter对象;
- 2.在for(;;)循环中,通过CAS将该节点插入到_cxq链表的头部(这个时刻可能有多个获取锁失败的线程要插入),CAS插入失败的线程再次尝试获取锁;
- 3.如果还没获取到锁,则将线程挂起;等待唤醒;
- 4.当线程被唤醒时,再次尝试获取锁。
这里的设计精髓是通过多次tryLock尝试获取锁和CAS获取锁无限推迟了线程的挂起操作,你可以看到从开始到线程挂起的代码中,出现了多次的尝试获取锁;因为线程的挂起与唤醒涉及到了状态的转换(内核态和用户态),这种频繁的切换必定会给系统带来性能上的瓶颈。所以它的设计意图就是尽量推辞线程的挂起时间,取一个极限的时间挂起线程。另外源码中定义了负责线程_Responsible,这种标识的线程调用的是定时的park(线程挂起),避免死锁.
锁释放源码
void ATTR ObjectMonitor::exit(bool not_suspended, TRAPS) {
Thread * Self = THREAD ;
if (THREAD != _owner) { //判断当前线程是否是线程持有者
//当前线程是之前持有轻量级锁的线程。由轻量级锁膨胀后还没调用过enter方法,_owner会是指向Lock Record的指针
if (THREAD->is_lock_owned((address) _owner)) {
assert (_recursions == 0, "invariant") ;
_owner = THREAD ;
_recursions = 0 ;
OwnerIsThread = 1 ;
} else { //当前线程不是锁的持有者--》出现异常
TEVENT (Exit - Throw IMSX) ;
assert(false, "Non-balanced monitor enter/exit!");
if (false) {
THROW(vmSymbols::java_lang_IllegalMonitorStateException());
}
return;
}
}
//重入,计数器-1,返回
if (_recursions != 0) {
_recursions--; // this is simple recursive enter
TEVENT (Inflated exit - recursive) ;
return ;
}
//_Responsible设置为NULL
if ((SyncFlags & 4) == 0) {
_Responsible = NULL ;
}
#if INCLUDE_JFR
if (not_suspended && EventJavaMonitorEnter::is_enabled()) {
_previous_owner_tid = JFR_THREAD_ID(Self);
}
#endif
for (;;) {
assert (THREAD == _owner, "invariant") ;
if (Knob_ExitPolicy == 0) {
//先释放锁,这时如果有其他线程获取锁,则能获取到
OrderAccess::release_store_ptr (&_owner, NULL) ; // drop the lock
OrderAccess::storeload() ; // See if we need to wake a successor
//等待队列为空,或者有"醒着的线程”,则不需要去等待队列唤醒线程了,直接返回即可
if ((intptr_t(_EntryList)|intptr_t(_cxq)) == 0 || _succ != NULL) {
TEVENT (Inflated exit - simple egress) ;
return ;
}
TEVENT (Inflated exit - complex egress) ;
//当前线程重新获取锁,因为后序要唤醒队列
//一旦获取失败,说明有线程获取到锁了,直接返回即可,不需要获取锁再去唤醒线程了
if (Atomic::cmpxchg_ptr (THREAD, &_owner, NULL) != NULL) {
return ;
}
TEVENT (Exit - Reacquired) ;
} else {
if ((intptr_t(_EntryList)|intptr_t(_cxq)) == 0 || _succ != NULL) {
OrderAccess::release_store_ptr (&_owner, NULL) ; // drop the lock
OrderAccess::storeload() ;
// Ratify the previously observed values.
if (_cxq == NULL || _succ != NULL) {
TEVENT (Inflated exit - simple egress) ;
return ;
}
//当前线程重新获取锁,因为后序要唤醒队列
//一旦获取失败,说明有线程获取到锁了,直接返回即可,不需要获取锁再去唤醒线程了
if (Atomic::cmpxchg_ptr (THREAD, &_owner, NULL) != NULL) {
TEVENT (Inflated exit - reacquired succeeded) ;
return ;
}
TEVENT (Inflated exit - reacquired failed) ;
} else {
TEVENT (Inflated exit - complex egress) ;
}
}
guarantee (_owner == THREAD, "invariant") ;
ObjectWaiter * w = NULL ;
int QMode = Knob_QMode ; //根据QMode的不同,会有不同的唤醒策略
if (QMode == 2 && _cxq != NULL) {
//QMode==2,_cxq中有优先级更高的线程,直接唤醒_cxq的队首线程
.........
return ;
}
//当QMode=3的时候 讲_cxq中的数据加入到_EntryList尾部中来 然后从_EntryList开始获取
if (QMode == 3 && _cxq != NULL) {
.....
}
....... //省略
.......
//当QMode=4的时候 讲_cxq中的数据加入到_EntryList前面来 然后从_EntryList开始获取
if (QMode == 4 && _cxq != NULL) {
......
}
//批量修改状态标志改成TS_ENTER
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
//插到原有的_EntryList前面 从员_EntryList中获取
// Prepend the RATs to the EntryList
if (_EntryList != NULL) {
q->_next = _EntryList ;
_EntryList->_prev = q ;
}
_EntryList = w ;
}
..........
}
}
上述代码总结如下步骤:
- 1.将_recursions减1,_owner置空;
- 2.如果队列中等待的线程为空或者_succ不为空(有"醒着的线程",则不需要去唤醒线程了),直接返回即可;
- 3.第二条不满足,当前线程重新获取锁,去唤醒线程;
- 4.唤醒线程,根据QMode的不同,有不同的唤醒策略;
QMode = 2且cxq非空:cxq中有优先级更高的线程,直接唤醒_cxq的队首线程;
QMode = 3且cxq非空:把cxq队列插入到EntryList的尾部;
QMode = 4且cxq非空:把cxq队列插入到EntryList的头部;
QMode = 0:暂时什么都不做,继续往下看;
只有QMode=2的时候会提前返回,等于0、3、4的时候都会继续往下执行:
这里的设计精髓是首先就将锁释放,然后再去判断是否有醒着的线程,因为可能有线程正在尝试或者自旋获取锁,如果有线程活着,需要再让该线程重新获取锁去唤醒线程。
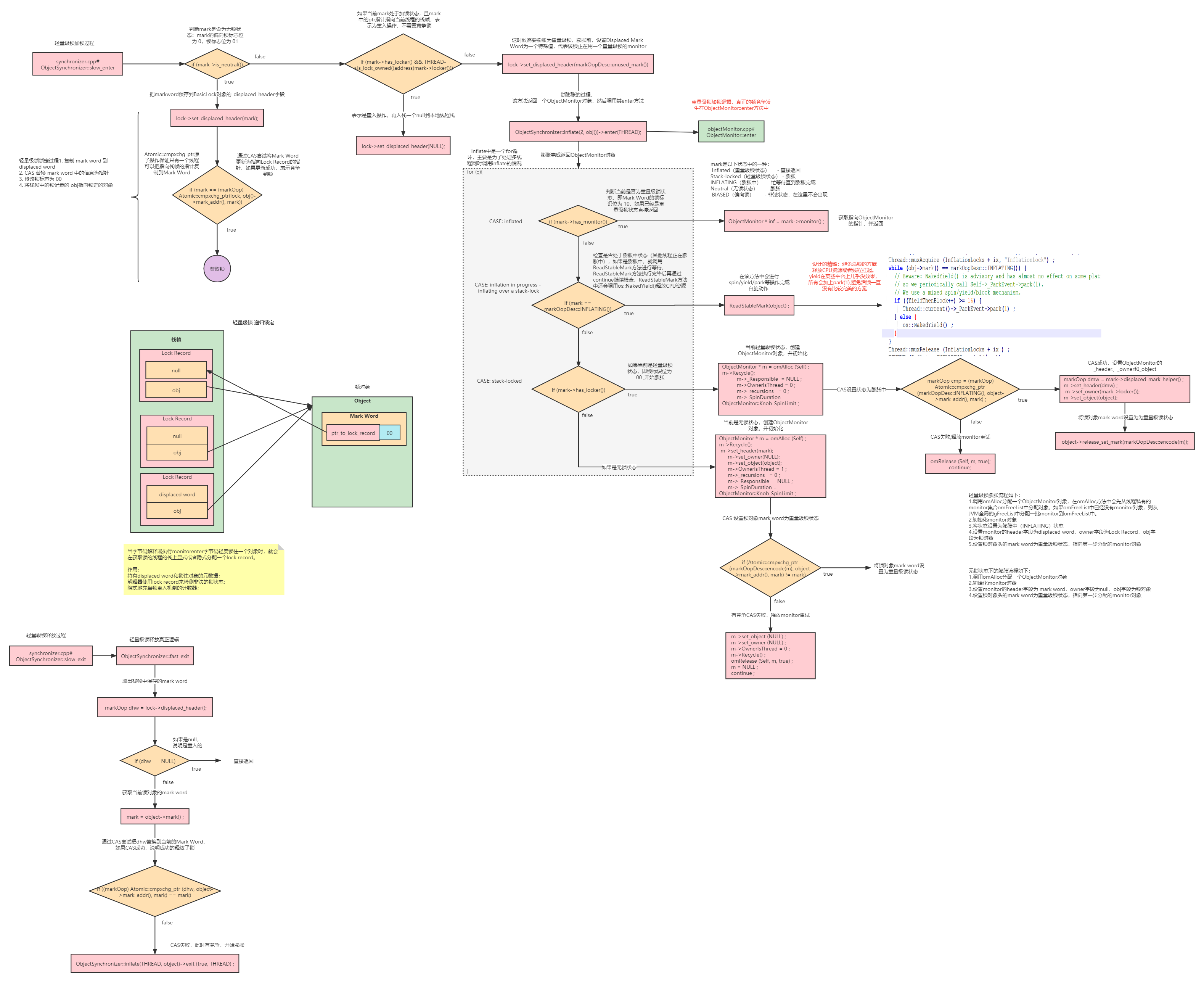
最后通过流程两张图把创建ObjectMonitor对象的过程与进入enter方法加锁与解锁的过程呈现出来,把我主要流程,更多地代码细节也可以从源码的英文注解中得到答案。

通过本篇由浅入深,逐步分析了synchronized从各层角度实现的细节以及原理,我们可以从中学到一些思路,比如锁的设计,能够通过CAS,偏向锁,轻量级锁等方式来实现的时候,尽量不要升级到重量级锁,等到竞争太大浪费cpu开销的时候,才引入重量级锁;比如synchronized原子性是通过锁对象保证只有一个线程访问临界资源来实现,可见性通过源码里的汇编volatile结合硬件底层指令实现,有序性通过源码底层的读写屏障并借助于硬件指令完成。synchronized底层在锁优化的时候也用了大量的CAS操作,提升性能;以及等待队列与阻塞队列设计如何同步进入管程的设计,这些设计思想也是后面Reentrantlock设计的中引入条件队列的思想,底层都是相同的,任何应用层的软件设计都能从底层的设计思想与精髓实现中找到原型与影子,当看到最底层C、C++或者汇编以及硬件指令级别的实现时,一切顶层仿佛就能通透。