 四种方法教你进行容器镜像加速
简介: 四种方法教你进行容器镜像加速
四种方法教你进行容器镜像加速
简介: 四种方法教你进行容器镜像加速

容器相比虚拟机最突出的特点之一便是轻量化和快速启动。相比虚拟机动辄十几个 G 的镜像,容器镜像只包含应用以及应用所需的依赖库,所以可以做到几百 M 甚至更少。但即便如此,几十秒的镜像拉取还是在所难免,如果镜像更大,则耗费时间更长。
我们团队(阿里云弹性容器 ECI)分析了 3000 个不同业务 Pod 的启动时间,具体如下图。可以看出,在 Pod 启动过程中,镜像拉取部分耗时最长。大部分 Pod 需要 30s 才能将镜像拉下来,这极大增加了容器的启动时间。
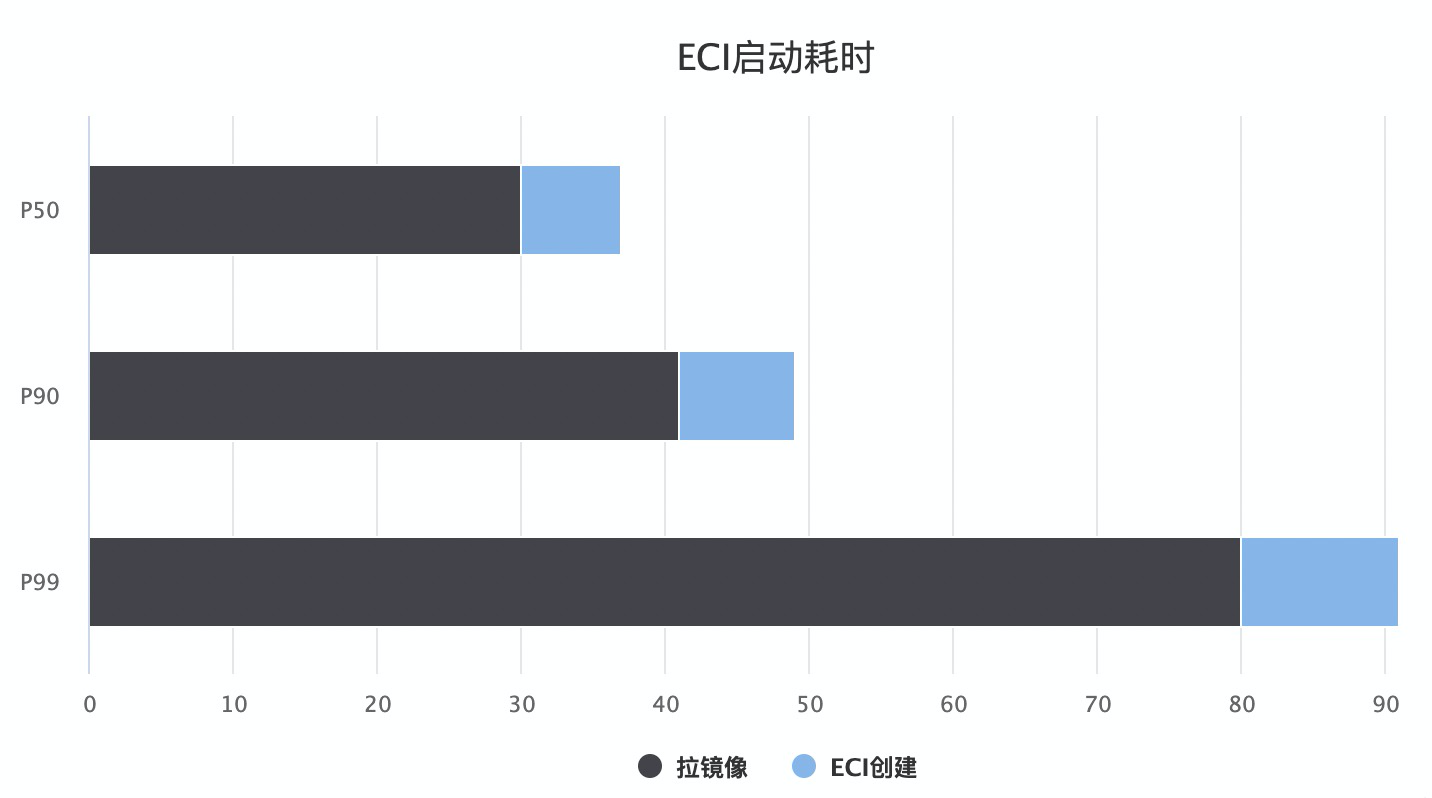
如果是大规模启动,这个问题则会变得更糟糕。镜像仓库会因为镜像并发拉取导致带宽打满或者服务端压力过大而直接崩溃。
我们多次遇到过这个问题。由于一个服务的副本数达到 1000+ ,在迅速扩容 1000+ 多个实例的时候,很多 Pod 都处于 Pending 状态,等待镜像拉取。
虽然 kubernetes 在调度的时候已经支持镜像的亲和性,但只针对老镜像,如果并发启动的新镜像的话,还是需要从镜像仓库里面拉取。下面提供几种常用的解决思路。
方法一:多镜像仓库
多镜像仓库能够很好降低单个仓库的压力,在并发拉取镜像的时候,可以通过域名解析负载均衡的方法,将镜像仓库地址映射到不同的镜像仓库,从而降低单个仓库的压力。
不过,这里有个技术挑战点:镜像仓库之间的镜像同步。
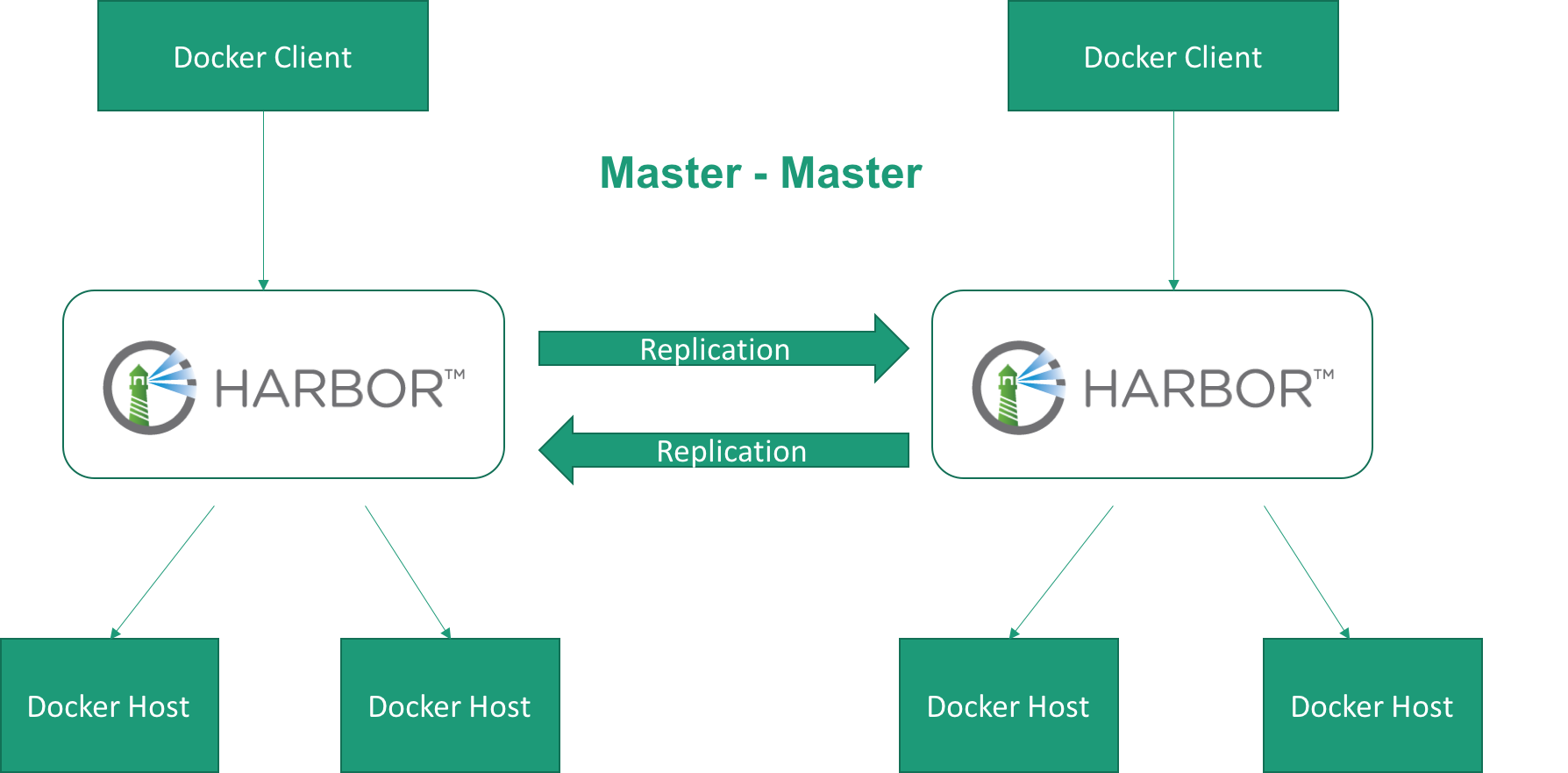
为了确保 Docker 客户端无论从哪个仓库都可以获取到最新的镜像,需要保证镜像已经成功复制到了每个镜像仓库。开源的镜像仓库 Harbor 已经支持镜像复制功能,可以帮助我们将镜像分发到不同的仓库中。
方法二:P2P 镜像分发
多镜像仓库虽然能够缓解单个仓库的压力,但仍然不能完全避免单个仓库被打爆的问题,而且多个仓库的运维成本也比较高。相比而论 P2P 的方案则更加优雅。
说起 P2P 大家可能都不陌生,我们常用的迅雷下载就是使用了 P2P 的原理,还有最近比较火的区块链技术底层也是基于 P2P 技术。
P2P 镜像分发的原理比较简单。首先将镜像分成很多的“块(block)”,如果某个 Docker 客户端拉取了这个块,那么其他的 Docker 客户端就可以从这个客户端拉数据,从而避免所有的请求都打到镜像仓库。Dragonfly 是阿里开源的 P2P 分发工具。原理如下图所示:

其中的 SuperNode 是大脑,负责存储 “块”和客户端的关系,客户端第一次请求会被打到 SuperNode 节点,然后 SuperNode 回源去镜像仓库拉取数据转发给客户端,并且会记录这些块和客户端的对应关系。后续其他客户端请求这些块的时候,SuperNode 会告诉客户端应该去刚才成功拉取的节点上获取数据,从而降低 registry 的负载。下面是我们生产环境并发拉取 Tensorflow 镜像的实测的数据:

可以看到,当并启动数比较低的时候,是否使用 P2P 影响不大,但随着并发数的增加,P2P 可以保障镜像拉取时间稳定在 50s。而直接使用镜像仓库的话,拉取时间会随着并发数不断增加,在 1000 并发的时候,已经达到 180s 了。
方法三:镜像延迟加载
OCI 分层的镜像格式是一把双刃剑。一方面,通过分层可以提升镜像的复用,每次镜像拉取只需要拉增量的部分,另一方面分层的镜像也存在很多问题:
- 数据冗余:不同层之间相同数据在传输和存储时存在冗余内容,每次针对文件的一个小修改就需要复制整个文件;
- 无法针对小块数据的进行校验,只有完整的层下载完成之后,才能对整个层的数据做完整性校验;
- 难以实现跨层的删除,当前 OCI 设计中,删除一个文件只能通过 Whiteouts 文件玩了一个障眼法让用户看不到,真实的文件并没有删除。
那么,有没有一种不需要下载完整镜像,只在读数据的时候临时加载镜像的方案呢?
根据统计显示,在镜像启动的时候,平均只有 6.4%的数据被真正使用到,其余 90%多的数据都属于延迟被使用或者压根用不到。就像手机里面的 App,我们每天常用的也就几个。于是诞生了一种新的镜像加速方案:延迟加载。比较流行的开源项目包括 stargz、dadi 以及 nydus。
这里还有一个技术细节,在 OCI 分层的镜像格式中,如何快速找到一个文件呢?如果每次按需加载的时候都需要逐层查找效率就太低了。所以,为了实现镜像数据的低延迟按需加载,我们不能再使用传统的 OCI 镜像格式了,无论是 nydus、dadi 还是 stargz 都重新定义了一种新的镜像格式。
其中,Nydus 采用了一种“拍平”的方案,将多个分层“拍平”成一层。元数据是一个目录树,每个叶子节点里面存储了数据块是索引,可以快速定位到一个或者多个数据块。如下图所示,可以看到 Nydus 可以实现不同镜像之间块级别的共享。

回想刚才传统 OCI 镜像格式的弊端,使用 Nydus 格式不仅可以去重文件,而且可以实现块级别的按需加载。下图是 Nydus 按需加载的原理图:
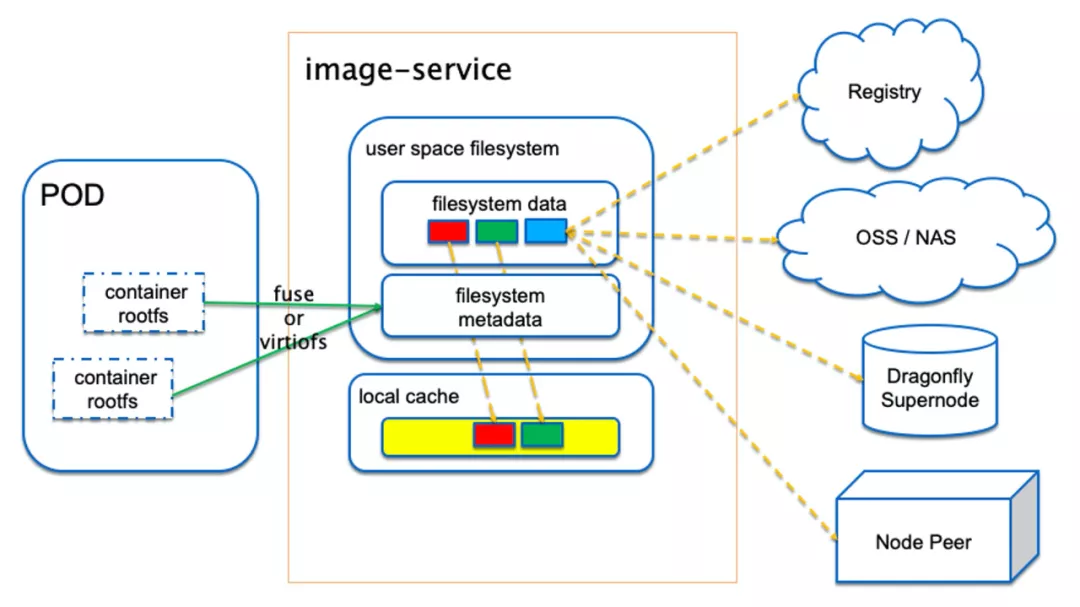
通过用户态文件系统为 Pod 里面的容器提供 rootfs,当程序启动需要访问某个数据的时候,如果发现本地没有,于是 nydusd 守护进程,便会回源到后端,将数据加载回来。和内核里面的缺页原理非常相似,只不过缺页用于内存懒加载,而 Nydus 应用于镜像文件的懒加载。
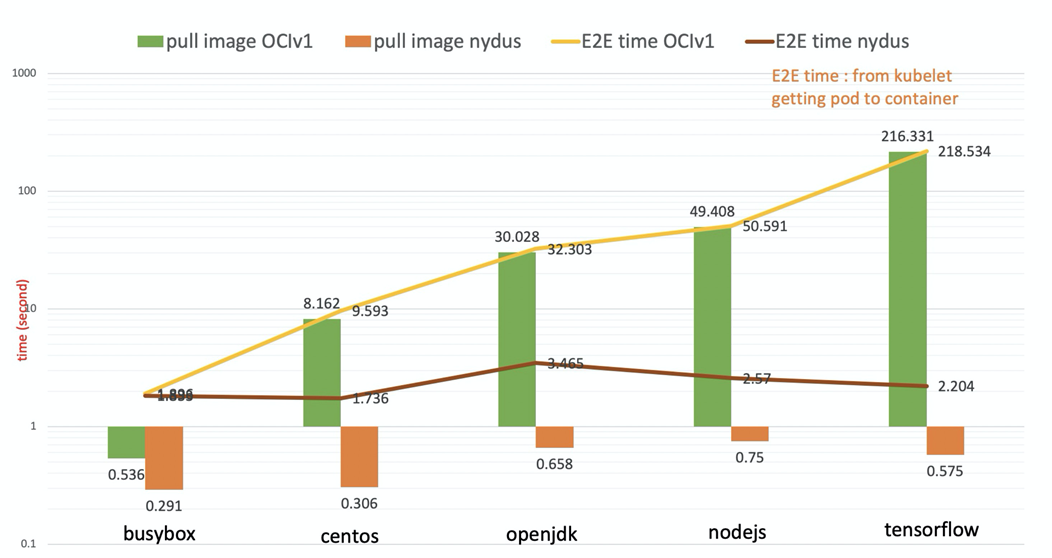
下面是 Nydus 镜像加速对比原生 OCI 镜像,在拉取时间上的对比效果图,可以看到极大的缩短了镜像拉取时间。(注:统计从镜像开始拉取到镜像拉取成功的耗时)
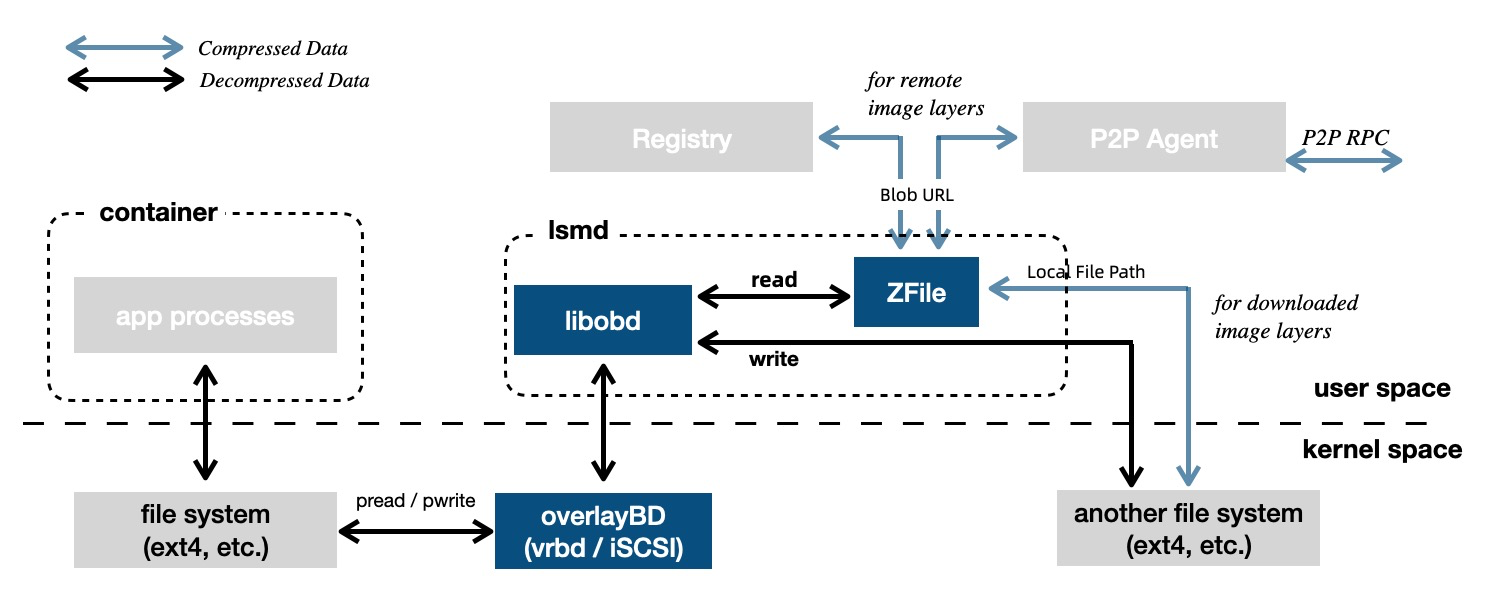
镜像的按需加载不仅可以在文件系统层面实现,还可以下移到更底层的块设备实现,DADI 便是一种基于块设备延迟加载方案。
容器应用层 I/O 经过文件系统转换为简单的 Block I/O request,传递给内核虚拟块设备 overlayBD 并转发到用户态进程 lsmd。lsmd 负责对请求进行数据定位,读请求将从不同的上游数据源获取(registry/p2pagent/nas/localfile),写请求将直接写入本地文件系统。
上面的 Nydus 测试的是镜像拉取时间,很多人会担心延迟加载解决了镜像拉取耗时,那后续会不会影响应用启动呢?所以这次针对 DADI 的测试,我们实测应用执行的耗时。比如,下面第一个 demo 是运行一个识别猫狗图片的 AI 学习任务,排除 ECI 本身启动耗时之外,如果采用 OCI 镜像需要 62s,而使用 DADI 镜像则只需要 14 秒。

最后,细心的你可能已经发现,无论是 Nydus 还是 DADI,不仅可以从 registry 加载数据,也可以从 dragonfly 加载,这就和上面方案二完美结合了。
方法四:镜像缓存
上面说的几种方案,最终还是需要拉取镜像。传统观念里,我们肯定是需要先把镜像拉到本地,然后启动容器的,但这并不一定是对的。我们能不能不拉镜像,直接将镜像提前加载到一个存储里面,然后在启动容器的时候,直接将这个存储挂载到宿主机上,那么这台机器上面就天然具备这个镜像了,真正做到镜像仓库零压力和镜像拉取零耗时呢?
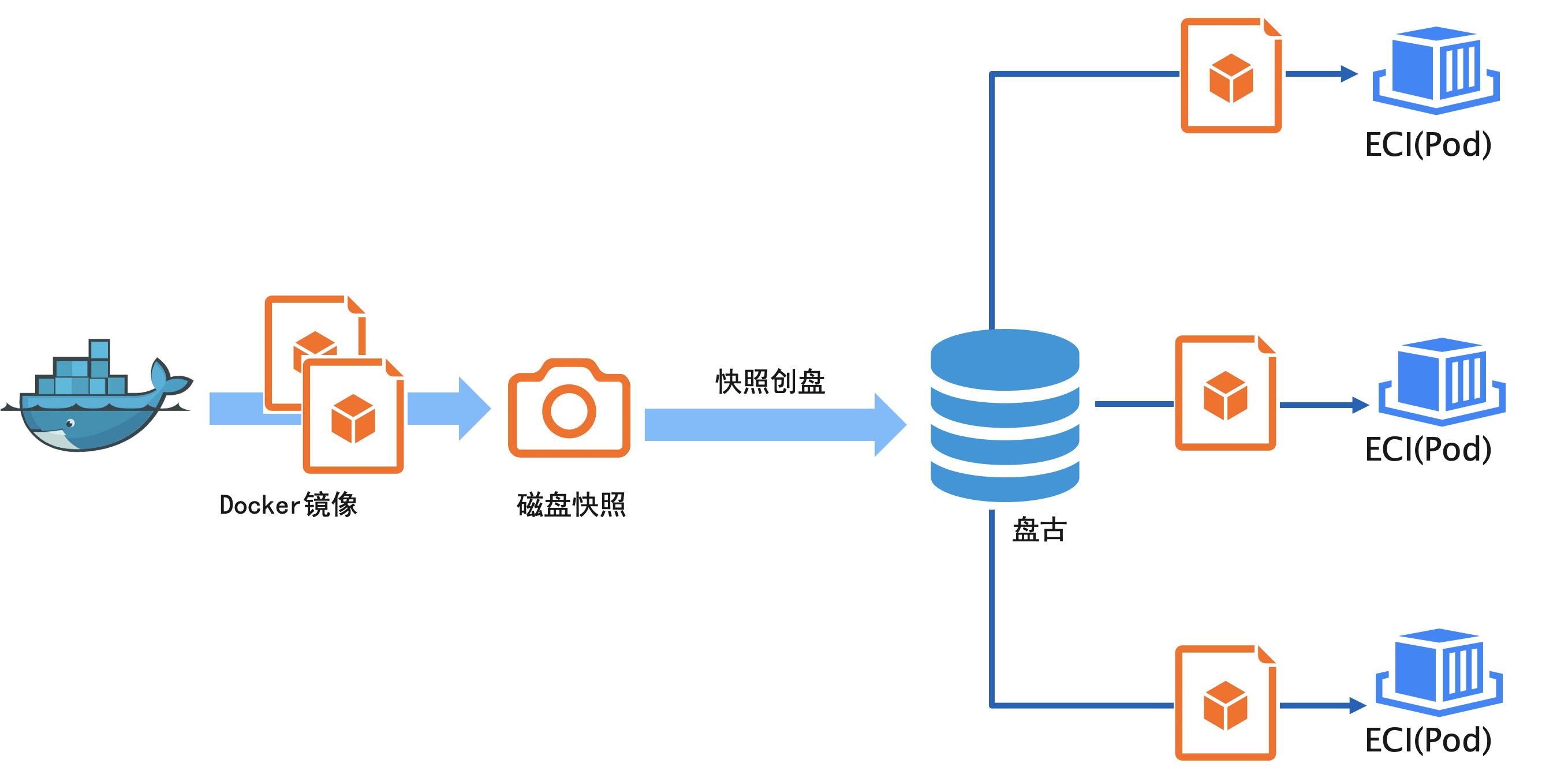
在 ECI 场景中,我们设计了镜像缓存。预先将镜像下载并且解压到云盘,然后制作成云盘快照,等到用户启动容器的时候,先通过快照创建一个云盘,再将云盘挂载到 ECI 上面,从而省去了容器拉取时间。无论是一个几百 M 的镜像还是几百 G 的镜像,在 ECI 上都可以 Pod 都可以实现端到端 10s 启动。
上面的介绍的这些镜像加速的方案,无论是 P2P 、Nydus、DADI 还是镜像缓存,目前 ECI 已经全部支持。ECI 的目标之一就是实现容器的极致弹性能力,所以我们会不断优化容器的启动过程,缩短启动耗时,更用户带来更好的体验。
这篇文章主要介绍容器镜像加速的几种常用方案。总结说来,主要是通过 P2P 降低镜像仓库压力,通过延迟加载提升容器和应用启动速度,还有通过云盘挂载的方式直接加载镜像,用户可以根据自己的场景选择合适的加速方案。
容器启动的全链路中,除了镜像下载以为,还需要 Kubernetes 和 ECI 底层多个方面优化,后续文章会逐渐为大家解密阿里云 ASK 设计过程中各种技术细节,请大家继续关注。
本文节选自阿里云技术专家陈晓宇的《深度揭秘阿里云 Serverless Kubernetes》系列专题。本专栏将主要围绕如何在 Serverless Kubernetes 场景中实现秒级扩容,以及在大规模并发启动中遇到的各种技术挑战、难点以及解决方案,系统地揭秘阿里云 Serverless Kubernetes 的发展、架构以及核心技术。
(文章首发于InfoQ平台,已获得作者授权转载,原文链接)
作者简介:
陈晓宇,阿里云技术专家,负责阿里云弹性容器(ECI)底层研发工作,曾出版《深入浅出 Prometheus》 和 《云计算那些事儿》。
相关阅读:
故事,从 Docker 讲起 | 深度揭秘阿里云 Serverless Kubernetes(1)
如何进行架构设计 | 深度揭秘阿里云 Serverless Kubernetes(2)