本文面向有一定.NET C#基础知识的学习者,介绍C#中结构体定义、使用以及特点。
1. 阅读基础
了解C#基本语法
了解.NET中的栈与托管堆
2. 值类型 2.1 .NET的两大类型
在.NET中,所有类型都是object类型的子类,而在object繁多的子类中,又可以将它们归结为两种类型:引用类型与值类型,两者最大的区别在于值类型对象会在栈上分配,而引用类型对象则是在托管堆中分配,由于对栈上数据的操作通常远远快于对托管堆中数据的操作,因此对值类型访问与操作通常会更高效。.NET中的值类型有一个最为明显的特点,就是所有的值类型都继承自类ValueType。
2.2 ValueTypeValueType是一个继承自object的特殊抽象类,它是所有值类型的基类,它的意义在于区分值类型与引用类型。然而ValueType本身的定义很简单,只是重写了object中的Equals、GetHashCode以及ToString方法,并隐藏了默认构造方法:
public abstract class ValueType
{
protected ValueType() { ... }
public override bool Equals(object obj) { ... }
public override int GetHashCode() { ... }
public override string? ToString() { ... }
}ValueType通过重写Equals方法,让其子类的比较行为为比较相等性(而非object默认的用于比较同一性),这也符合“值”的特点-两个值应该比较是否相等而是否同一。尽管ValueType表面上看起来只是一个普通的抽象类,但是这是用于编译器的类,编译器禁止程序员显式从ValueType派生类,也就是说下面的代码是不允许的:
class Foo : ValueType { ... } // 不允许从ValueType派生不过将其用作类型声明是允许的,尽管大多数时候这一行为没有什么意义:
ValueType val = 1; // val的类型是ValueType
ValueType Add(ValueType a, ValueType b) { ... } // 将ValueType用于参数类型与返回类型总而言之,类型是否继承自ValueType是.NET中引用类型与值类型的分界线。
3.3 C#中的值类型(1)基元类型中的值类型
C#中最基础的值类型就是其基元类型中的值类型,如下:
C#基元类型 对应的FCL类型 sbyte System.SByte byte System.Byte short System.Int16 ushort System.UInt16 int System.Int32 uint System.UInt32 long System.Int64 ulong System.UInt64 char System.Char float System.Single double System.Double bool System.Boolean decimal System.Decimal这些类型都是常用且重要的类型,CLR也对上述类型提供了直接操作IL码,拥有相比于其他类型来说更高的操作效率。
(2)枚举类型
C#中的枚举类型也是值类型,因为所有枚举类型都继承自Enum类型,而Enum类型则继承自ValueType。枚举类型相比基元类型更复杂,需要一定的篇幅讲解,但考虑到本文重点,这里不做过多介绍。
(3)自定义值类型:结构体
C#也允许程序员通过使用struct来定义自己的值类型,这一类型被称为结构体。定义一个结构体的定义和定义一个类在语法上没有太大的区别,下面是一个简单的结构体的示例:
struct Point
{
public float X;
public float Y;
}上述代码定义了一个名为Point的结构体,该结构体中有两个float类型的字段,名为X与Y。你会发现其和定义一个类的区别似乎仅在于将class关键字替换为了struct。甚至在使用上也几乎与普通的类无异:
Point p = new Point();
p.X = 1;然而这只是表面上看起来,由于使用了struct来定义Point,Point现在是一个值类型而非引用类型,意味着它遵守值类型栈上分配的规则,同时还有一些更深层次的东西。
3.4 与C++的不同如果你写过C++,可能使用下面的方法来决定对象的分配方式:
Point p; // 分配到栈
Point* p = new Point(); // 分配到堆但在.NET中,你会意识到对象究竟会分配到栈还是分配到堆并不在分配时决定,而是在定义类型时就决定了(当然另一方面,C++中可以通过对析构函数与new运算符的私有化来实现在定义时限定分配方式)。
3. C#中的结构体 3.1 定义与使用结构体 3.1.1 定义
一个结构体的定义非常简单,从语法上来说只需要将定义一个类使用的class关键字替换为struct即可,如下:
public struct Point
{
public float X;
public float Y;
}同样和定义类一样,你可以定义为结构体添加访问修饰符,例如上述定义中就为其添加了public访问修饰符。同样的,你也可以在结构体中定义属性,方法,甚至事件。
3.1.2 使用结构体的使用也非常简单,和类的使用基本一致:
Point p = new Point(); // 实例化一个Point
p.X = 1; // 将p的字段X的值设为1
int x = p.X; // 获取p的字段X的值 简而言之,从语法层面来说,结构体的定义与使用和类的定义与使用没有太大的差别,两者大多数的操作基本可以通用。真正让结构体与类区分开来的是它作为的值类型特点。
3.2 结构体的特点 3.2.1 栈上分配在前文对值类型的简介中已经提到过,值类型在实例化时对象会被直接分配到栈上。而引用对象的变量只有在实例化的时候才会分配实际所需的内存:
FooClass foo; // 此处只是声明了一个FooClass对象的引用,FooClass实例尚未创建
foo = new FooClass(); // 到这里才实际分配了所需内存并实例化了一个FooClass对象而值类型是栈上对象,意味着当你声明值类型的变量后就会立马分配内存:
FooStruct foo; // 立马在栈上分配可以容纳FooStruct大小的内存,并将所有字段初始化为0
FooStruct foo = new FooStruct(); // 同上,但是语义更明确尽管上述代码的第一种写法无法通过编译,但这只是编译器的要求,第一行代码和第二行代码的作用在默认情况下完全相同(默认情况是指使用结构体的自动生成的构造方法)。你可以认为,栈上对象的内存分配在你写下的一瞬间就决定好了。你可以尝试如下代码来体会这一区别:
????? Foo {
public long A;
public long B;
public long C;
public long D;
public long E;
}
var foos = new Foo[100 * 100 * 100];
Console.WriteLine(GC.GetTotalAllocatedBytes());上述代码运行时会输出程序运行时分配过的内存大小,将开头的‘?????’替换为class或struct,你会发现当其为struct时程序所占的内存明显高于其为class时,原因在于当Foo为struct时数组中的每一项所占的内存就是储存一个Foo对象所需要的所有空间,而为class时则只会储存一个引用所占的内存(通常为8字节或4字节,取决于平台配置)。就像下图这样:

分配到栈是值类型的重要特征,理解这一点对于值类型的很多性质的理解以及正确使用值类型有巨大帮助。
3.2.2 无继承结构体不支持继承,所有的结构体都是隐式密封的,也就是说,下面的代码是不可行的:
struct Foo { }
struct Foo2 : Foo { } // 结构体不允许继承但是结构体可以实现接口:
struct Foo : IEquatable<Foo> { ... }关于为何结构体不可继承,其中一个重要的原因是由于结构体所代表的值类型需要直接分配到栈上,在入栈出栈的时候必须能够确定其数据大小,因此结构体需要提供明确固定的大小。如果允许继承,下面这种情况是难以预测的:
struct Foo { }
struct Foo2 : Foo { }
Foo foo;
foo = new Foo();
foo = new Foo2();foo的尺寸应该以Foo为准还是以Foo2为准?答案是Foo,然而根据“基类引用可以指向派生类引用”这一规则,foo应该也可以指向Foo2的实例。然而值类型是栈上分配,其内存大小在声明的一瞬间就已经确定,显然如果Foo2中有额外的字段,已分配给Foo对象的栈空间中将没有额外的储存空间容纳这些字段,另外从事实上来说,foo甚至不是一个引用。所以结构体不允许继承是理所当然的。
3.3.3 副本式赋值对一个引用类型进行赋值的时候,获得的是对指向对象的引用:
class Foo
{
public int Value;
}
Foo f1 = new Foo();
Foo f2 = f;
f2.Value = 10;
Console.WriteLine(f1.Value);上述代码将输出10,尽管是对f2赋值,但是实际上是将f1所指向的对象的引用赋值给了f2,此时f1与f2指向的是同一个对象,因此f2修改Value的值时等同于修改f1指向的对象的Value的值。但对于值类型来说则不如此:
struct Foo
{
public int Value;
}
Foo f1 = new Foo();
Foo f2 = f;
f2.Value = 10;
Console.WriteLine(f1.Value);上述代码将输出0,这是上述的赋值行为实际是将f的副本赋值给了f2,也就是说,不同于Foo为类时f1与f2指向的是同一个对象,f2在此时持有的是一个和f相同的副本,两者互不相干,因此修改f2的Value不会影响f1的值。
结构体的赋值方式如下:
- 实例化一个相同类型的结构体,作为副本
- 将当前结构体各个字段的值逐一赋给创建的副本中相同的字段
不只于赋值操作,结构体作为方法参数、方法返回值时也是按值传递:
????? Foo
{
public int Value;
}
void IncreaseValue(Foo foo)
{
foo.Value += 1;
}
Foo f1 = new Foo();
IncreaseValue(f1);
Console.WriteLine(f1.Value);若Foo定义为class,则上述代码输出的为1,若Foo为struct,上述代码输出为0。原因是定义为class时,将f1作为参数传入后foo获得的是f1对其引用对象的引用,因此foo此时指向的就是f1指向的对象;而定义为struct时,foo此时获取的是f1的副本。这一行为有时候会带来一些奇怪的表现,例如:
struct CatCard
{
public int ID;
}
class Cat
{
public CatCard Card { get; } = new CatCard();
}
Cat cat = new Cat();
cat.CatCard.ID = 10;上述代码尝试修改直接修改Cat中CatCard属性的ID字段,咋一看好像没问题,但实际上上述代码甚至无法通过编译。不要忘记一个很重要的点:属性的本质是方法,因此上面的赋值代码的实质如下:
CatCard card = cat.get_Card();
card.ID = 10;你可能已经发现问题了:get_Card()返回了一个CatCard对象,然而根据值类型按副本赋值的特点,get_Card()返回的其实是Cat中Card属性的副本,因此card此时并不是表示Cat中的Card,而是其副本,这意味着对card的修改将不会对Cat的Card属性产生任何影响。为了防止潜在的编程错误,这一行为会被编译器阻止。
不过,就像C++中可以按引用传递栈上对象一样,C#也支持通过引用传值而直接修改原始数据,具体方法会在后文提到。
3.4. 特殊结构体 3.4.1 只读结构体(readonly)基元类型中的值类型的实例是不可变的,例如,下面的代码是无法通过编译的:
1 = 2;(字面值1可以视为Int32的一个实例)
这一点很容易理解,将数字2赋值给数字1从数学上来说是及其令人困惑的,因此基元类型的值类型都是不可变类型。不可变类型可以带来诸多好处,例如更安全的编程,可以基于不可变做出许多假设而进行优化等等,因此将类型定义为不可变类型是有意义的。你可以通过在结构体中只声明只读字段来保证这一点:
struct Point
{
public readonly float X;
public readonly float Y;
}这样当Point的实例创建后就无法修改其成员值了。当然这个结构体没有什么意义,因为它的X和Y值将永远是0。为此,你还需要提供构造方法来允许在实例化时指定字段的值:
struct Point
{
public readonly float X;
public readonly float Y;
public Point(float x, float y)
{
X = x;
Y = y;
}
}
Point p = new Point(1, 2); // 使用示例尽管如此,有时在编码时依然可能出现失误而导致忘记将某个字段设置为只读字段,并且只是在对字段声明只读显然缺乏更清晰的语义,因此C#还提供了一种语法来声明‘只读结构体’,只读结构体的所有的字段必须声明为只读字段,否则会出现编译错误:
readonly struct Point
{
public readonly float X;
public readonly float Y;
public float Z; // 编译错误,字段必须为只读
}如上,在struct关键字前添加readonly关键字,即可将结构体声明为只读结构体。编译器会为readonly结构体加上IsReadonlyAttribute,因此上述代码会被翻译为如下:
[System.Runtime.CompilerServices.IsReadOnly]
struct Point
{
public readonly float X;
public readonly float Y;
}(当然,IsReadonlyAttribute是一个internal的类,主要用于标记元数据,程序员不应该使用它)
除了只读字段外,同样还可以声明只读属性:
struct Point
{
public float X { get; }
public float Y { get; }
}和类的只读属性一样,结构体的只读属性同样是依赖一个只读字段实现。同样的,你可以设置init访问器来允许在‘对象初始值设定项’中初始化字段的值,避免定义过多的构造方法:
struct Point
{
public float X { get; init; }
public float Y { get; init; }
}
Point p = new Point()
{
X = 1,
Y = 2
};此外你还可以定义只读方法:
struct Point
{
// ... 省略其他代码
public readonly void Print()
{
// X = 1; // 不允许的操作
Console.WriteLine(X + Y);
}
}被readonly修饰的方法意味方法做出保证:不会修改实例状态,也就是说readonly方法中不能对字段进行赋值操作,只能访问字段。因此如果将上面Print方法的X = 1那一行取消注释,编译器将会报错,因为它尝试修改结构体的状态。
3.4.2 仅栈分配结构体(ref)‘结构体分配到栈上’这一重点被反复强调,然而有时候可能并不是那么简单:
struct Point
{
public float X;
public float Y;
}
class Square
{
public Point Position;
}
Square square = new Square();上述代码中,Square的Position字段并没有分配到栈上,反而是和Square的实例一起被分配到了托管堆中。除此之外,装箱也会导致结构体实例分配到托管堆:
Point point = new Point();
object obj = point; // 装箱,结构体转移到托管堆上述代码从逻辑上来说是可行的,但有时候因为性能要求或者种种原因我们希望结构体只能分配到栈上,此时便可以使用仅栈分配结构体,即ref结构体:
ref struct Point
{
public float X;
public float Y;
}尽管ref这一关键字让人疑惑,但是在struct关键字前添加ref确实是指将结构体声明为只能在栈上分配的结构体,对于这种结构体,任何可能将其转移到托管堆的行为都将被阻止(例如在引用类型中定义ref结构体字段,或者进行装箱操作):
class Square
{
public Point Position; // 错误,Position会随着Square实例转移到托管堆
}
Point point = new Point();
object obj = point; // 错误,point会被装箱到托管堆ref结构体保证了结构体只能在栈上分配,但是也因此有了诸多限制,MSDN上指出了ref结构体的的使用限制:
- 不能是数组的元素类型。
- 不能是类或非 ref 结构的字段的声明类型。
- 不能实现接口。
- 不能被装箱为 System.ValueType 或 System.Object。
- 不能是类型参数。
- 不能由 lambda 表达式或本地函数捕获。
- 不能在 async 方法中使用。 但是,可以在同步方法中使用 ref 结构变量,例如,在返回 Task 或 Task<TResult>的方法中使用结构变量。
- 不能在迭代器中使用。
需要说明的是,你可以声明在其他ref结构体中声明ref结构体字段,因为ref结构体保证栈上分配:
ref struct AlsoPoint
{
public Point Point; // 允许,因为XPoint同样保证了栈上分配
}另外,你可以声明只读ref结构体:
readonly ref struct Point
{
public Point Point; // 允许,因为XPoint同样保证了栈上分配
}(注意,readonly关键字必须位于ref之前)
ref结构体可以让程序员对结构体的分配做出预设,从而放心实现一些高性能的库。例如Span<T>与ReadOnlySpan<T>就是对ref结构体的具体应用。
3.4.3 记录结构体(record)record是一个新的概念,阐述它需要一定的篇幅,这不是本文的重点,因此这里不多做阐述,只是简单说明以下可以将结构体也声明为记录:
record struct Point
{
public float X;
public float Y;
}从实质上来讲,记录结构体就是实现了IEquatable<>接口,重写了ToString、GetHashCode与Equals方法,并重载了==与!=运算符的结构体,不过这些操作均由编译器自动完成。另外,同样可以用下面的语法声明声明记录结构体:
record struct Point3(float X, float Y);上述代码的对等代码大概如下:
查看代码
record struct Point
{
private float _x;
private float _y;
public float X
{
get => this._x;
set => this._x = value;
}
public float Y
{
get => this._y;
set => this._y = value;
}
public Point(float X, float Y)
{
this._x = X;
this._y = Y;
}
public void Deconstruct(out float X, out float Y)
{
X = this.X;
Y = this.Y;
}
}(注意Point的X和Y是被定义为属性而非字段,并且这种声明方式还实现了Deconstruct解构方法)
同样的,可以声明只读记录结构体。
3.4.4 不安全结构体(unsafe)所谓不安全结构体就是允许出现不安全成员的结构体,例如:
unsafe struct Window
{
public void* Handle;
}Handle是一个void*指针,是不安全代码,因此使用该字段的结构体需要声明为unsafe。unsafe结构体不是什么新东西,只是unsafe作用于结构体范围的体现,不安全代码也不是本文重点,故这里不多做阐述。
3.4.5 多特性结构体可以将readonly、record、ref、unsafe等修饰符组合,来创建诸如‘只读ref结构体’、‘只读记录结构体’、‘只读不安全结构体’等具有多种特性的结构体。鉴于这些结构体只是相应修饰符含义的组合,这里不过多阐述。
4. 对结构体的特殊操作 4.1 按引用传递值类型
来看下面的一个例子:
struct Point
{
public int X;
public int Y;
}
void AddX(Point point)
{
point.X += 1;
point.Y += 1;
}
Point p = new Point();
AddX(p);
Console.WriteLine(point.X);上述代码中将输出0。请记住结构体默认是副本式复制,也就是说上述代码中调用AddX方法,并将p作为参数传入后,方法中的point只是p的副本而非p本身,因此对point的改变不会影响到p。但有时候确实需要通过方法直接修改p的值,此时可以使用按引用传递:
void AddX(ref Point point)
{
point.X += 1;
point.Y += 1;
}
Point p = new Point();
AddX(ref p);
Console.WriteLine(point.X);现在AddX方法的point现在是一个ref参数,传递参数p时,point此时直接指向p所在的数据地址,因此修改point的值等同于直接修改p。ref参数并不奇怪,你很可能已经用过了。但现在回过头来看前文的一个例子:
struct CatCard
{
public int ID;
}
class Cat
{
public CatCard Card { get; } = new CatCard();
}
Cat cat = new Cat();
cat.CatCard.ID = 10; // 报错上述代码无法通过编译,然而如果将上述代码中Cat的Card属性修改为字段,则代码可以正常运行:
class Cat
{
public CatCard Card = new CatCard(); // 修改为字段
}
Cat cat = new Cat();
cat.CatCard.ID = 10; // 此时可以通过编译这是由于属性的本质是方法,因此当Card为属性时,其等效代码类似如下:
struct CatCard
{
public int ID;
}
class Cat
{
private readonly CatCard _card = new CatCard();
public CatCard get_Card()
{
return this._card;
};
}
Cat cat = new Cat();
cat.get_Card().ID = 10; // 报错请思考一下为何编译器不允许上述代码:get_Card是方法,返回一个CatCard类型的对象,而CatCard是一个结构体,这意味着该方法返回的将是字段_card的副本而非_card字段本身,因此修改get_Card的返回值不会对_card字段本身造成任何影响,而仅仅是修改_card字段的一个临时副本的X,并在修改完成后就丢弃此副本。由于这一问题会导致人对代码本身做的事产生误解而编写出错误的代码,因此C#编译器禁止了上述行为。但就像按参数可以引用传递一样,返回值也可以按引用返回,因此,你可以写出如下代码:
class Cat
{
// ... 省略其他代码
public ref CatCard get_Card()
{
return ref this._card;
};
}
Cat cat = new Cat();
cat.get_Card().ID = 10; // 正确,get_Card()返回的是字段_card的引用注意cat.get_Card().ID = 10等效代码如下:
ref CatCard card = ref cat.get_Card(); // 而不是CatCard card = cat.get_Card(),否则card依然只是副本
card.ID = 10回到属性上,你可以声明按引用返回的值类型属性:
class Cat
{
private readonly CatCard _card;
public ref CatCard Card
{
get
{
return ref this._card;
}
}
}
Cat cat = new Cat();
cat.CatCard.ID = 10; // 正确基于显而易见的原因,这种属性不能有set访问器。
4.2 装箱与拆箱既然结构体是值类型,那么结构体也存在装箱与拆箱,将数据在栈与托管堆之间迁移:
struct Foo { }
Foo foo = new Foo();
object obj = foo; // 装箱,移动到托管堆
Foo foo2 = (Foo)obj; // 拆箱,从托管堆中获取数据并移动到栈上装箱与拆箱的相关概念不是本文的重点,故此处不做过多介绍。另外,理所当然的,ref结构体(仅栈上结构体)不允许装箱与拆箱。
4.3. 控制结构体的内存布局既然结构体是分配到栈上的,那结构体需要的内存大小必然是在编译时与运行时都可以确定的。例如下述结构体:
struct Point
{
public int X;
public int Y;
}Point结构体有两个int类型的字段,C#中每个int直接映射到System.Int32类型,因此每个int字段长度为4字节,故储存上述结构体所需要的内存大小就是4+4=8字节。可以通过sizeof来查看结构体所需的内存大小:
unsafe
{
Console.WriteLine(sizeof(Point)); // 输出8
}一般来说,结构体所需的内存大小就是各个字段大小的总和,但有时候还需要考虑内存对齐的问题。例如下述结构体:
struct Point
{
public byte X;
public int Y;
}byte类型只占用一个字节,所以你可能会认为上述代码中Point的大小是1+4=5字节,然而由于内存对齐,byte依然会需要占据4字节大小,因此该结构体实际上依然需要8字节来储存。关于内存对齐是一个需要一定篇幅来阐述的问题,这个不是本文的重点,如有兴趣可以参考C语言中结构体的内存对齐的相关文章进行了解。
另一个重要的点是,你可以通过System.Runtime.InteropServices.StructLayoutAttribute来指定字段布局方案,该Attribute主要接受一个System.Runtime.InteropServices.LayoutKind枚举来指定对齐模式,该枚举有三个枚举值:
(1)Sequential:顺序布局,按字段的声明顺序布局,是默认行为
(2)Auto:自动布局,自动排列字段顺序以用最小的空间来储存字段
例如对于下面结构体:
struct Foo
{
public byte A;
public int B;
public byte C;
}默认情况下由于内存对齐,该结构体所需的内存大小为4+8+4=12,但你可以按下面的顺序声明字段让其只需要8个字节:
struct Foo
{
public byte A;
public byte C;
public int B;
}也就是说字段的声明顺序影响结构体的内存占用,而通过StructLayoutAttribute,你可以让运行时对字段顺序自动调整以求最小内存浪费:
[StructLayout(LayoutKind.Auto)]
struct Foo
{
public byte A;
public int B;
public byte C;
}经过运行时的自动调整字段储存顺序后,一个Foo对象在程序运行的时候的内存占用同样是8。
(3)Explicit:显式布局,手动指定字段地址的偏移
你可以手动指定字段的偏移值,来达到一些特殊的效果:
[StructLayout(LayoutKind.Explicit)]
struct Foo
{
[FieldOffset(0)]
public short A;
[FieldOffset(4)]
public int B;
[FieldOffset(2)]
public short C;
}通常,按照Foo中字段的声明顺序,Foo的内存布局应该如下图:

但这里将结构体的LayoutKind设置为了Explicit,并使用了FieldOffsetAttribute来显式指定了各个字段相对于结构体起始地址的偏移(以字节为单位)。因此Foo的实际内存布局如下图:

这一功能一个比较重要的用途是用于模拟C语言中的联合体(union),例如对于下面C中的联合体定义:
union Foo
{
int IntValue;
long LongValue;
double DoubleValue;
};可以使用下述的C#的结构体来模拟:
[StructLayout(LayoutKind.Explicit)]
struct Foo
{
[FieldOffset(0)]
public int IntValue;
[FieldOffset(0)]
public long LongValue;
[FieldOffset(0)]
public double DoubleValue;
}上述结构体的内存布局如下图:
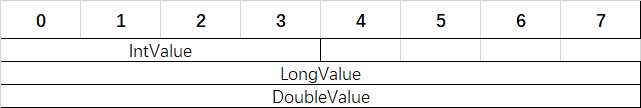
同样,显式指定内存也受内存对齐的影响。
5. 结构体杂谈 5.1. 字段 or 属性
前文给出的结构体几乎都是直接使用字段而非属性,但这只是为了避开属性的复杂性,从而更方便更直观地说明结构体的一些性质。在实际使用中,鉴于属性的种种好处,一般情况下即便是结构体也应该优先使用属性。
不过有时候确实使用字段更好,例如定义与非托管代码交互的结构体的成员就最好使用字段,或者性能瓶颈确实出现在使用属性上因此不得不直接使用字段(大多数情况这并不可能)。
简而言之,除非确实真的有必要,否则对于结构体也应该优先使用属性而非字段。
5.2. 类 or 结构通常使用结构体是因为结构体的栈上分配特点而有使其具有更好的操作性能,因此结构体通常是为高性能需要服务的。然而,结构体默认使用副本式传值,可能会导致程序运行时创建不必要的副本,例如:
struct MethodArgs { ... }
MethodArgs args = new MethodArgs();
Method(args); // 第一次副本
Method(args); // 第二次创建副本
Method(args); // ...创建副本上述代码中每一次传参都会有一次额外的创建副本的开销,然而如果将MethodArgs定义为class,则只会传递对同一个实例引用,则避免了创建副本的开销。当然,可以通过按引用传递参数来解决,但这仍然不是一个完美的解决方法。
此外,结构体不允许继承,这意味着结构体的代码重用能力远低于类,并且结构体不会有多态行为。
最后,从概念上来讲,结构体是值类型,应当将其认为是表现类似于int、long、double这类数值类型的类型,遵循用于“表达一个值”的用法,并根据轻量原则,结构体不应该定义的过于复杂。
基于上述原因,《CLR via C#》一书中建议在下面的情况下使用结构体:
- 类型定义十分简单,具有类似基元类型的表现。
- 不需要继承,也不需要被继承。
- 内存的实例较小(16字节以下)
- 或者内存实例较大(16字节以上),但是不会作为方法的参数与返回值使用
不过例外的是,与非托管代码交互时,内存布局明确且不受托管堆影响的的结构体有不可替代的优势,此时使用结构体基本是唯一的选择。
5.3. 实现一个更好的结构体(1)重写Equals与GetHashCode方法
默认的结构体实现会使用ValueType中重写的Equals方法,默认实现会考虑对普遍情况的可靠性,但这往往意味着它对特定实现来说是低效的,实际上ValueType对Equals的重写方法远比想象中的复杂。考虑到值类型往往需要在性能敏感的场合使用,因此有必要手动重写其Equals方法,关于如何重写Equals方法已经在另一篇文章中提出,这里不再赘述。同样的,也需要重写结构体的GetHashCode方法。
(2)使用只读结构体
由于结构体最好具有基元类型的表现,因此最佳的做法是尽可能地将结构体定义为只读结构体。
(3)实现IEqualable<>接口
作为值类型,那么结构体自然也应该可以进行相等性比较,实现IEquatable<>接口可以为结构体提供更好的比较方法,并提高结构体的泛用性。
(4)重载==与!=运算符
理由同上,使用==与!=对值类型进行相等性比较是符合直觉的。
(5)仅包含字段、属性与只读方法
尽管可行,但是不应该在结构体中定义事件。此外,结构体中的方法应该尽可能定义为只读方法,或者说方法不应该修改结构体的字段状态。
5.4. 语法糖C#中提供了一种名为with表达式的语法糖来获得对结构体进行非破坏性修改的副本:
Point p1 = new Point();
Point p2 = p1 with { X = 1 };上述代码实际做的事如下:
Point p1 = new Point();
Point temp = p1;
temp.X = 1;
Poitn p2 = temp;在一些场合,这一语法可以有效减少不必要的代码量。
5.5. 奇技淫巧如果结构体不是只读结构体,那么下述代码是可行的:
struct Point
{
public float X;
public float Y;
public void Reset(Point p)
{
this = p; // 修改this
}
}这并不奇怪,结构体在声明时就分配好了内存,并遵循按副本赋值。因此上述代码中this = p实际就是将p逐字段赋值给this表示的实例的相应字段的值而已。不过如果没有必要还是应该避免这种迷惑性的操作。
5.6. 其他注意事项(1)结构体类型无法嵌套,也就是说下面的代码是不可行的
struct Foo
{
public Foo Foo; // 嵌套一个字节
}显然,这会导致递归定义,所以是不允许的。
(2)构造方法必须保证对每个字段都赋值
struct Foo
{
public int X;
public int Y;
public Foo(int x)
{
X = x;
}
}尽管可以看出上述代码中的构造方法是想仅设置X的值,让Y的值保持其默认值0。然而该构造方法无法通过编译,因为构造方法中还没有完成对字段Y赋值,需要将其修改为如下:
struct Foo
{
public int X;
public int Y;
public Foo(int x)
{
X = x;
Y = 0;
}
}