前面的文章Spring Ioc源码分析系列--Bean实例化过程(二)在讲解到Spring创建bean出现循环依赖的时候并没有深入去分析了,而是留到了这一篇去分析。为什么要另起一篇,首先循环依赖是个很经典的问题,也是面试屡屡被问到的问题,就这一点,就值得再起一篇。其次,循环依赖相对来说较为复杂,如果想要完全理解Spring解决循环依赖的设计思想需要对Spring有比较整体的认知,这里要理清思路最好是新开一篇去写。
Spring循环依赖相信都已经听过很多次了,那么Spring怎么处理循环依赖的知道吗?知道?不知道?亦或是一知半解知道个三级缓存,但是再往深了去就不知道了?
先说循环依赖是个什么,这个简单,就是不同的bean出现了循环引用。如下图所示,CycleA和CycleB出现了相互引用的情况,那么这个时候就会出现了循环依赖。那么这个时候在创建的时候就会陷入循环,除非有终止条件,不然会一直创建下去,直到资源耗尽。
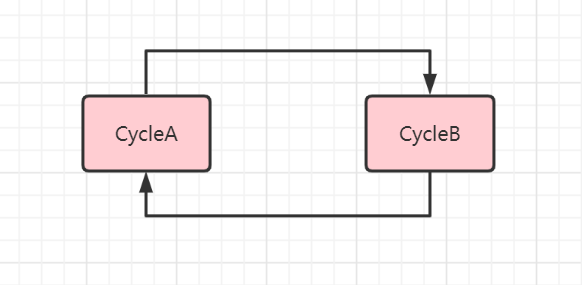
看到这里先不要急着往下看,如果是你,你会怎么处理?思考一下。
那么Spring是怎么处理的呢?Spring是通过提前暴露bean引用来解决的,这相当于是破坏了循环等待这个条件,先前的循环依赖是依赖于一个完整的bean,提前暴露半成品bean引用可以完成循环依赖的处理。那么提前暴露是怎么完成的呢?Spring是通过三级缓存来完成提前暴露的。
那这篇文章就来仔细剖析一下Spring是怎么处理循环依赖的。
构造例子工欲善其事,必先利其器。概念铺了很多,不搞个例子看看怎么对得起观众。
这里先指明现在网络上关于Spring循环依赖的一个误区,现在大部分的文章都说构造器循环依赖是没法处理的,只有setter方式的循环依赖能够被处理,其实这是不对的,构造器循环依赖也是能被处理的,只是大家用的姿势不对或者是不会用,文章后面会进行分析。
新建CycleA类,其中有属性CycleB依赖于CycleB类,然后有个report()方法打印这两个类的引用。
/**
* @author Codegitz
* @date 2022/6/7
**/
@Component
public class CycleA {
@Autowired
private CycleB cycleB;
public void report(){
System.out.println("cycleA: " + this + " reference cycleB: " + cycleB);
}
}
CycleB类的逻辑类似。
/**
* @author Codegitz
* @date 2022/6/7
**/
@Component
public class CycleB {
@Autowired
private CycleA cycleA;
public void report(){
System.out.println("cycleB: " + this + " reference cycleA: " + cycleA);
}
}
新建启动类CycleApplication跑一跑。
/**
* @author Codegitz
* @date 2022/6/7
**/
public class CycleApplication {
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext("io.codegitz.cycle");
CycleB cycleB = (CycleB) applicationContext.getBean("cycleB");
CycleA cycleA = (CycleA) applicationContext.getBean("cycleA");
cycleA.report();
cycleB.report();
}
}
启动完成后,发现循环引用是能够被正常处理的。

直接进入到核心逻辑里,这里的实现在AbstractAutowireCapableBeanFactory#doCreateBean()方法里,核心部分如下图所示,在该方法核心部分如图所示,会先进行引用的提前暴露,然后再进行属性填充,在进行属性填充的时候,会再去创建cycleB,然后创建cycleB的时候会再来创建cycleA,这个时候由于前面已经提前暴露了cycleA的引用,这里不会再进行cycleA的实例化,而是直接从缓存中获取半成品的cycleA。
这就是最简单情况下的循环依赖的处理,下面来分析一下细节。
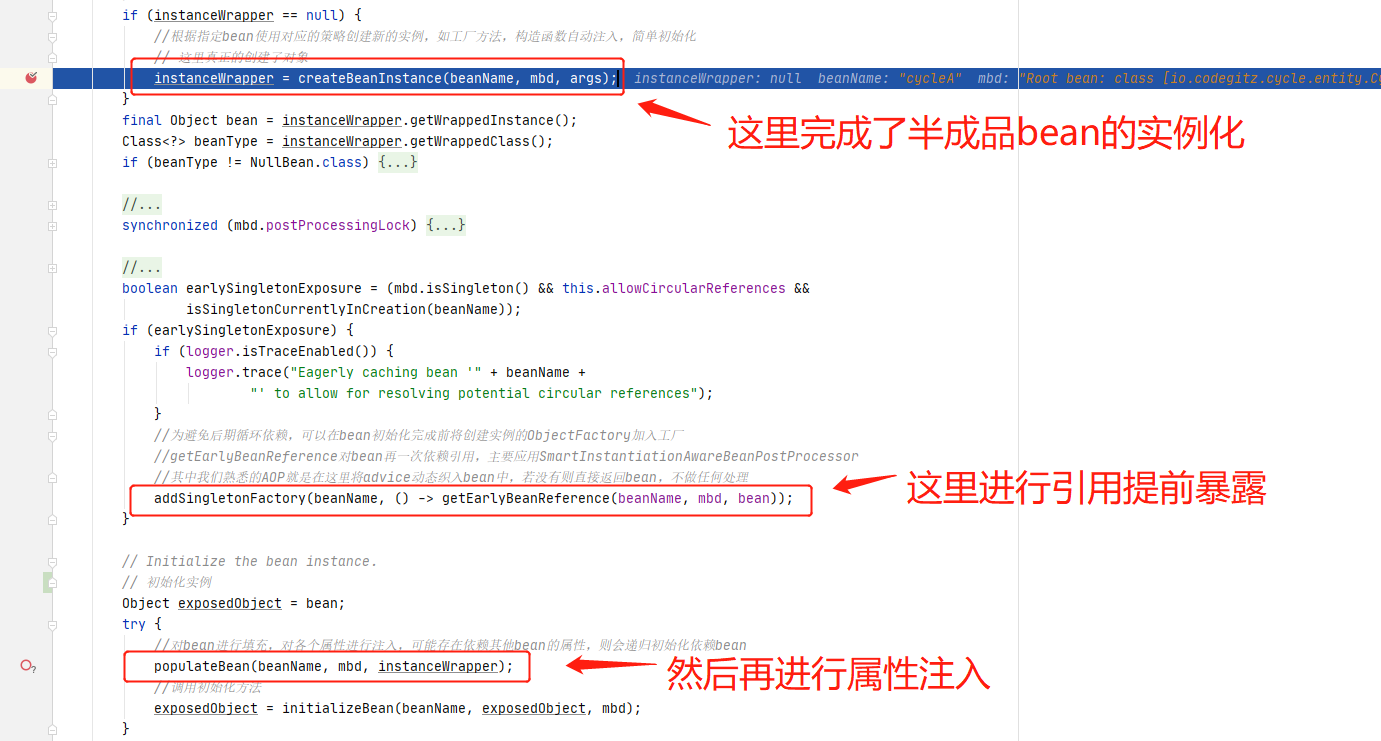
半成品bean的实例化我们就略过了,如果想知道细节,可以参考上一篇文章Spring Ioc源码分析系列--实例化Bean的几种方法里面有详细的分析。
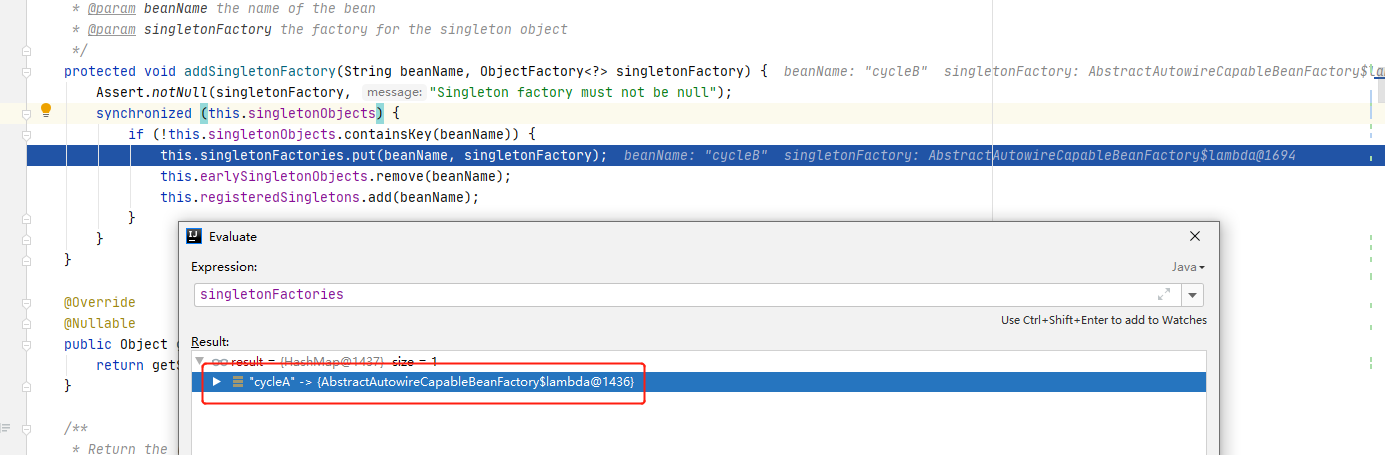
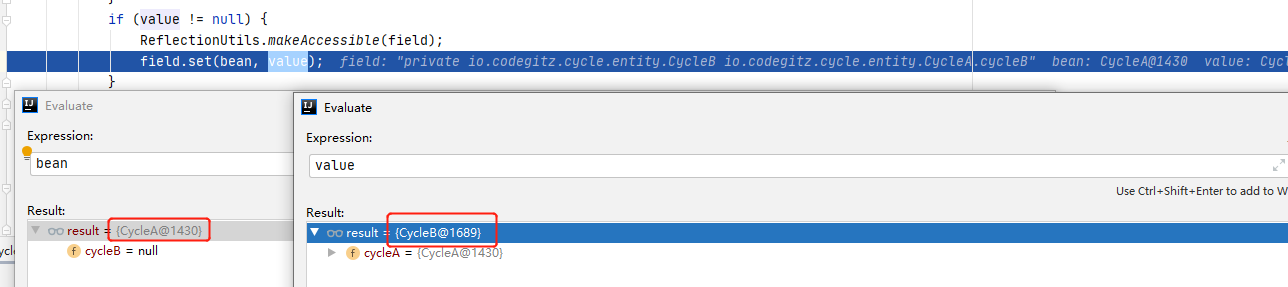
跟进addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean))方法。可以看到这里直接判断一下一级缓存里面是否已存在该bean,如果不存在,则放入到三级缓存里。
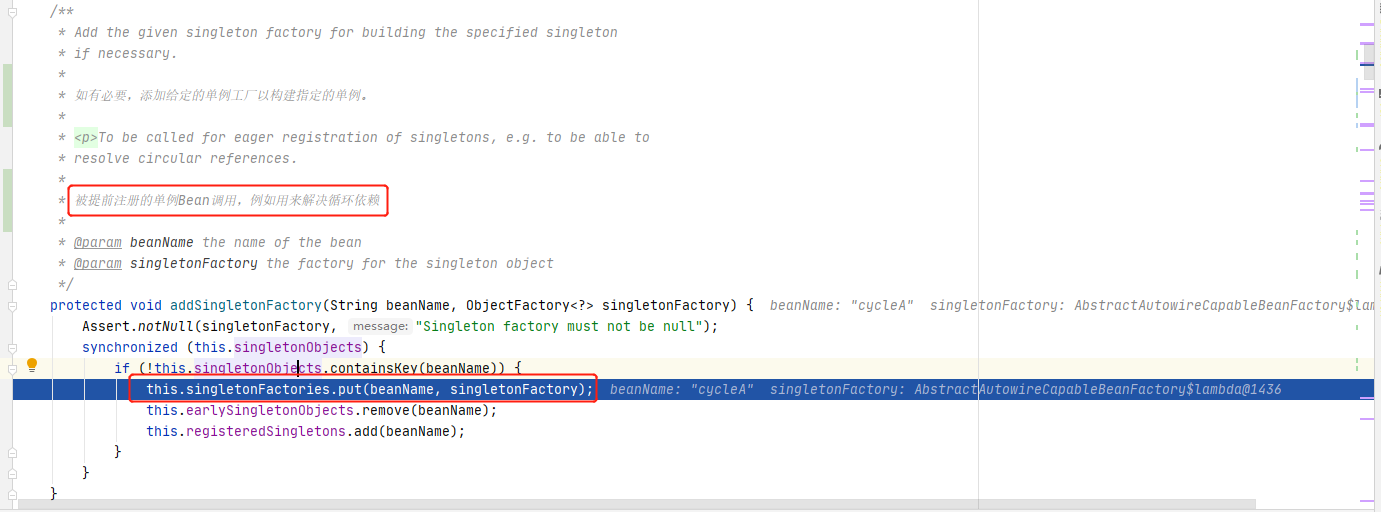
这里介绍一下三级缓存分别是什么以及里面缓存了什么内容:
- singletonObjects:单例对象的缓存,也就是常说的一级缓存,key-value为 bean 名称到 bean 实例,这里的实例是完整的bean。
- earlySingletonObjects:早期单例对象的缓存,也就是常说的二级缓存,key-value为 bean 名称到 bean 实例,这里的实例是半成品的bean。
- singletonFactories:单例工厂的缓存,也就是常说的三级缓存,key-value为 bean 名称到 创建该bean的
ObjectFactory。
可以看到,具体在addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean))方法上,放入的就是一段创建bean实例的lambada表达式。
我们暂且先不管为什么要调用() -> getEarlyBeanReference(beanName, mbd, bean)来返回bean,只需要记住通过这个ObjectFactory能获取到一个bean就行。
后续我会再来解释getEarlyBeanReference(beanName, mbd, bean)的作用,这里也可以提前说一下,getEarlyBeanReference(beanName, mbd, bean)就是给创建代理提供了机会,例如一些出现了循环依赖的动态代理都是在这里完成了动态代理的创建,然后返回动态代理bean。
到这里cycleA已经完成了实例化和引用提前暴露,接下来就开始填充属性,这时候就会去获取属性cycleB。
那cycleB会在哪里进行获取呢?由于这里的循环依赖是使用@Autowired注解注入的,关于@Autowired的注入逻辑可以参考之前的文章Spring Ioc源码分析系列--@Autowired注解的实现原理,这里不再赘述。
找到了注入点之后,就会调用DefaultListableBeanFactory#resolveDependency()来解析依赖,直接断点到这里。
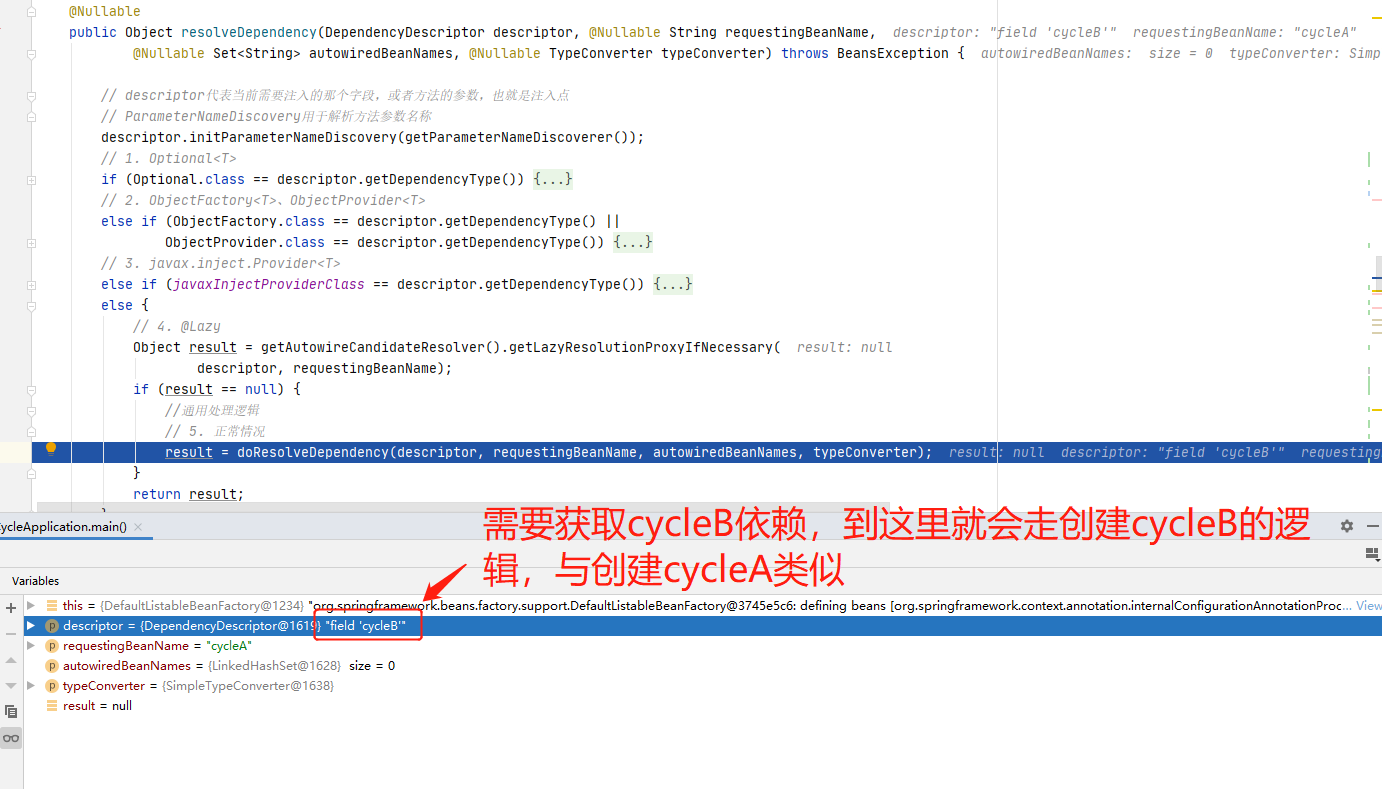
跳过了一些繁杂的逻辑,老套路,回到了AbstractAutowireCapableBeanFactory#doCreateBean()方法里,这里进行cycleB的创建,随后也会提前暴露cycleB的引用。

进入到提前暴露引用的addSingletonFactory()方法里,可以看到这里已经有了先前加入的cycleA的提前引用。这里会把cycleB的引用加入,随后进行cycleB的属性填充阶段,这个阶段又会进行cycleA的创建,由于已经能获取到cycleA的引用,所以不会再进行cycleA实例化。
cycleB的属性填充就不再贴过程了,与上文类似。这里贴一下调用链吧,可以跟着调用链回忆一下上篇文章的过程。
populateBean:1626, AbstractAutowireCapableBeanFactory -> 这是cycleB的属性填充
postProcessProperties:406, AutowiredAnnotationBeanPostProcessor ->
inject:118, InjectionMetadata ->
inject:671, AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement ->
resolveDependency:1268, DefaultListableBeanFactory -> 解析cycleA依赖
doResolveDependency:1382, DefaultListableBeanFactory ->
resolveCandidate:283, DependencyDescriptor ->
getBean:204, AbstractBeanFactory -> 获取cycleA
doGetBean:259, AbstractBeanFactory ->
getSingleton:175, DefaultSingletonBeanRegistry ->
getSingleton:193, DefaultSingletonBeanRegistry -> 这里回到缓存获取cycleA
我们直接来到DefaultSingletonBeanRegistry#getSingleton()方法上,结合debug图片一看,是不是就豁然开朗。
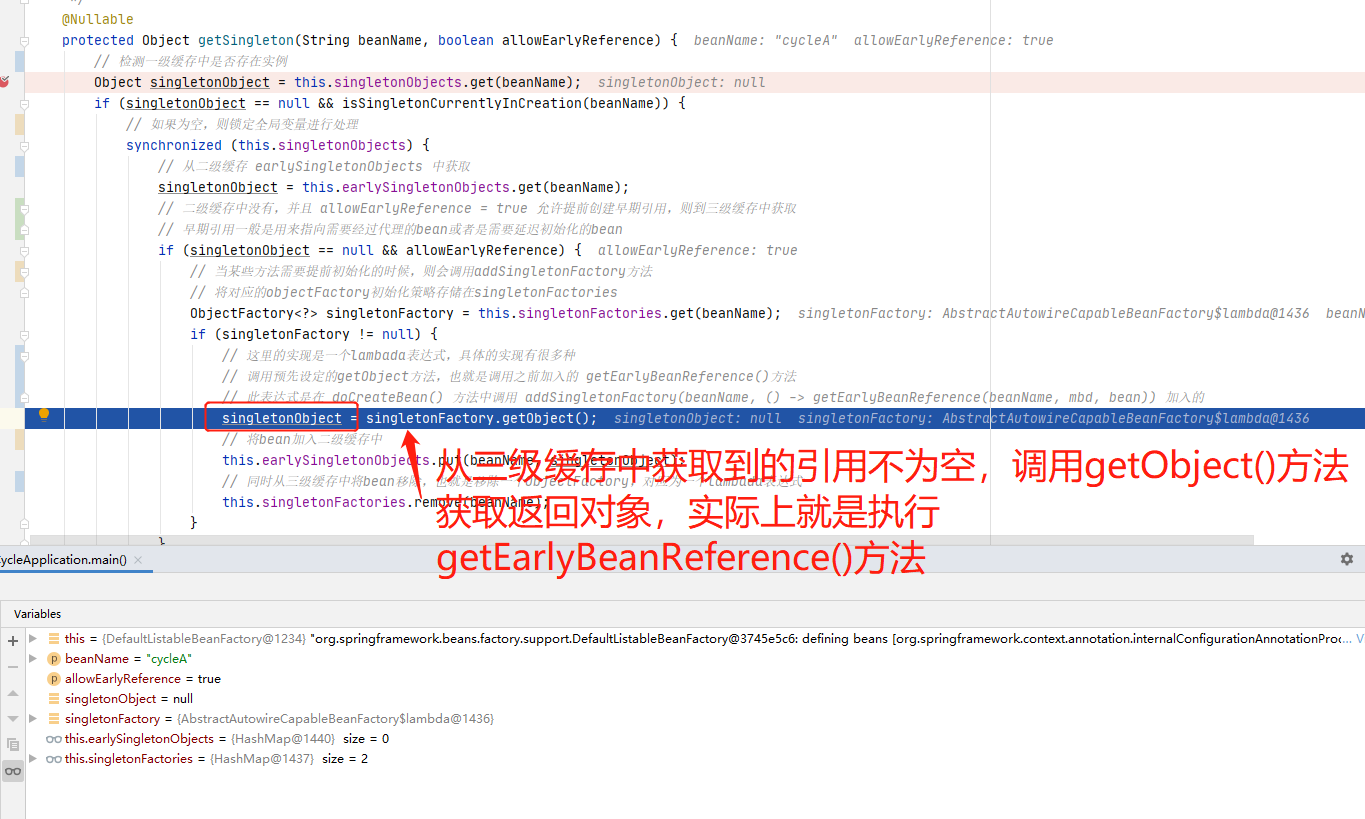
到了这里,我们就可以来看下为什么是要调用getEarlyBeanReference()方法了,我们跟进代码查看。
/**
* Obtain a reference for early access to the specified bean,
* typically for the purpose of resolving a circular reference.
*
* 获取对指定 bean 的早期访问的引用,通常用于解析循环引用。
*
* @param beanName the name of the bean (for error handling purposes)
* @param mbd the merged bean definition for the bean
* @param bean the raw bean instance
* @return the object to expose as bean reference
*/
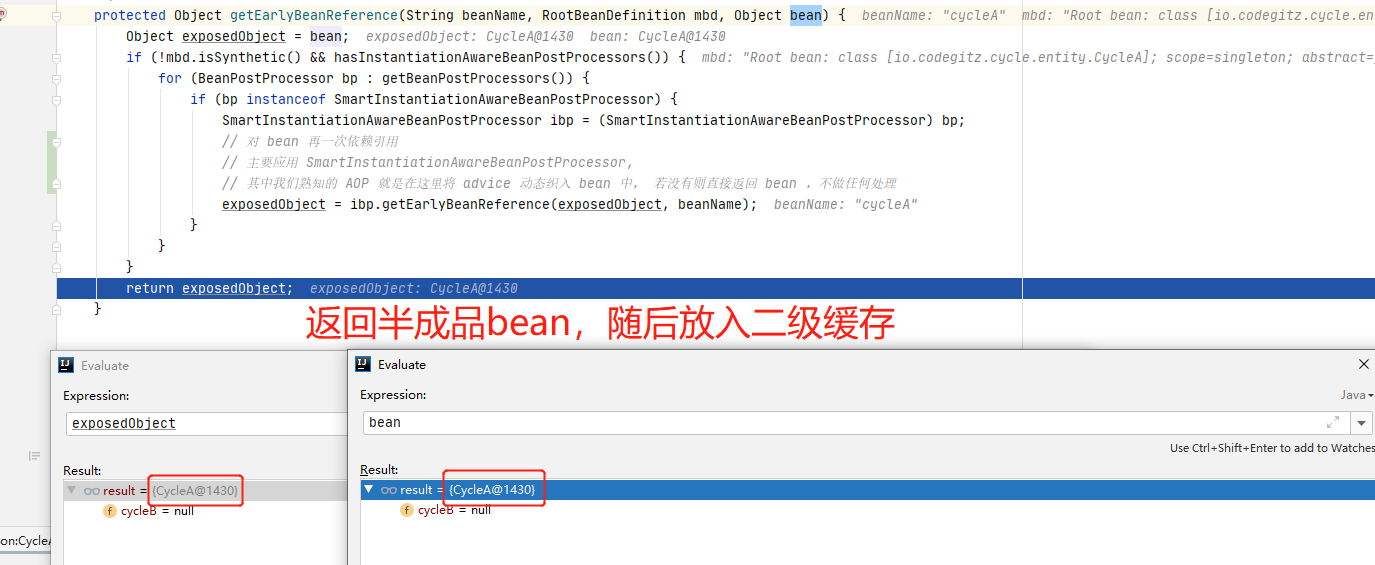
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
// 对 bean 再一次依赖引用
// 主要应用 SmartInstantiationAwareBeanPostProcessor,
// 其中我们熟知的 AOP 就是在这里将 advice 动态织入 bean 中, 若没有则直接返回 bean ,不做任何处理
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
首先来看这个方法名的命名getEarlyBeanReference(),翻译一下就是获取提前的 Bean 引用。那么思考一下提前是什么意思,是相对于什么提前了?
我个人的理解是创建代理的时机提前了,我们可以看到AbstractAutoProxyCreator#getEarlyBeanReference()方法的实现,该实现会调用wrapIfNecessary()方法进行代理的创建,而wrapIfNecessary()另一个调用点在postProcessAfterInitialization()方法里,该方法会在对象实例化后、初始化完成后再进行调用。这里是在属性注入的时候就已经创建,所以相对而言,创建代理的时机提前了。当然这是我个人的理解,如果错误还请指正。
继续调试,我们这里并没有代理的逻辑,所以返回的就是实例化后半成品的bean,该bean会被放入二级缓存,三级缓存会被清除。
这时候cycleB已经获得了cycleA的引用,可以返回继续cycleB的属性填充,随后cycleB已经完成填充,会被放入一级缓存。随后回到AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement#inject()方法里,完成了cycleA的注入。此时cycleB是一个正常的bean了,回到cycleA的依赖解析。

可以看到cycleA的依赖解析也能获取到cycleB了。
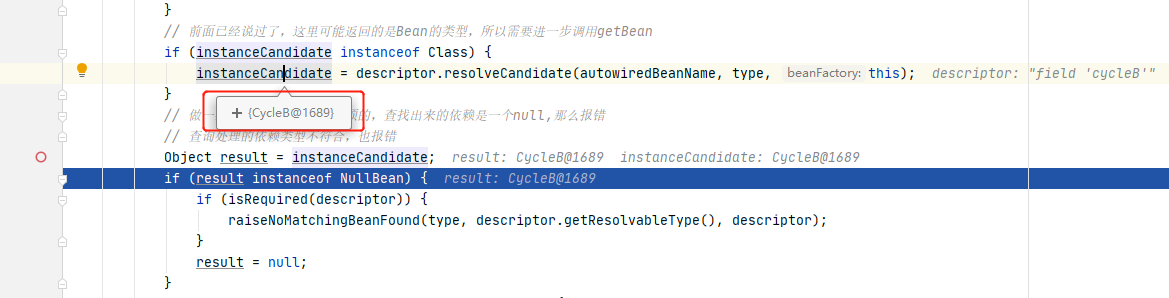
至此,cycleA也完成了注入,到这里循环依赖完美解决。
经过上面的分析,你觉得事情就完了吗?是不是上面的解析是不是有点简单了,感觉还意犹未尽。还记得开头提到的一个观点吗?就是构造器循环依赖也是可以处理的,那么我们来创建一个构造器循环依赖的例子。
简单改造一下上面的例子,将@Autowired注入改为构造器注入。
CycleA类如下
@Component
public class CycleA {
private CycleB cycleB;
public CycleA(CycleB cycleB){
this.cycleB = cycleB;
}
public void report(){
System.out.println("cycleA: " + this + " reference cycleB: " + cycleB);
}
}
CycleB类如下
@Component
public class CycleB {
private CycleA cycleA;
public CycleB(CycleA cycleA){
this.cycleA = cycleA;
}
public void report(){
System.out.println("cycleB: " + this + " reference cycleA: " + cycleA);
}
}
其他的不变,启动例子,会发现启动报错。

那么为什么构造器注入就不行了呢?很简单,因为构造器注入的话,Spring没办法获得一个半成品的bean,从而无法提早暴露引用,就会陷入死循环。
为什么构造器注入没法获得半成品bean?因为构造函数需要的参数获取不到,构造函数没法调用,所以永远没法实例化一个半成品bean出来。
那就没有办法了吗?方法是有的,按照刚刚说的条件,我们是因为构造函数的参数获取不到,所以没法执行构造函数,那有没有办法欺骗一下构造函数,给它返回一个伪参数,先让它完成构造函数的调用,后续我们再去保证这个参数的正确性。
按照这个思路,怎么样能实现这个想法呢?很简单,只需要在构造函数上面加上一个@Lazy注解,即可完成构造函数的调用。
public CycleB(@Lazy CycleA cycleA){
this.cycleA = cycleA;
}
再启动,会发现没有报错,这究竟是怎么处理的呢?
关键在DefaultListableBeanFactory#resolveDependency()方法里,这个方法是解析依赖的,这个方法的调用时机在前面的文章也有多次提到了,这里不再赘述,贴一下代码。
可以看到这里分了五种情况来处理:
- Optional类型
- ObjectFactory、ObjectProvider类型
- javax.inject.Provider类型
- @Lazy类型
- 正常Bean类型
很显然,构造器的参数加了@Lazy是属于第四种类型,那么接下来分析一个它是怎么处理的。
public Object resolveDependency(DependencyDescriptor descriptor, @Nullable String requestingBeanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
// descriptor代表当前需要注入的那个字段,或者方法的参数,也就是注入点
// ParameterNameDiscovery用于解析方法参数名称
descriptor.initParameterNameDiscovery(getParameterNameDiscoverer());
// 1. Optional<T>
if (Optional.class == descriptor.getDependencyType()) {
return createOptionalDependency(descriptor, requestingBeanName);
}
// 2. ObjectFactory<T>、ObjectProvider<T>
else if (ObjectFactory.class == descriptor.getDependencyType() ||
ObjectProvider.class == descriptor.getDependencyType()) {
//ObjectFactory和ObjectProvider类的特殊注入处理
return new DependencyObjectProvider(descriptor, requestingBeanName);
}
// 3. javax.inject.Provider<T>
else if (javaxInjectProviderClass == descriptor.getDependencyType()) {
return new Jsr330Factory().createDependencyProvider(descriptor, requestingBeanName);
}
else {
// 4. @Lazy
Object result = getAutowireCandidateResolver().getLazyResolutionProxyIfNecessary(
descriptor, requestingBeanName);
if (result == null) {
//通用处理逻辑
// 5. 正常情况
result = doResolveDependency(descriptor, requestingBeanName, autowiredBeanNames, typeConverter);
}
return result;
}
}
直接把断点打到这里。我是在CycleB的构造函数上加了注解。
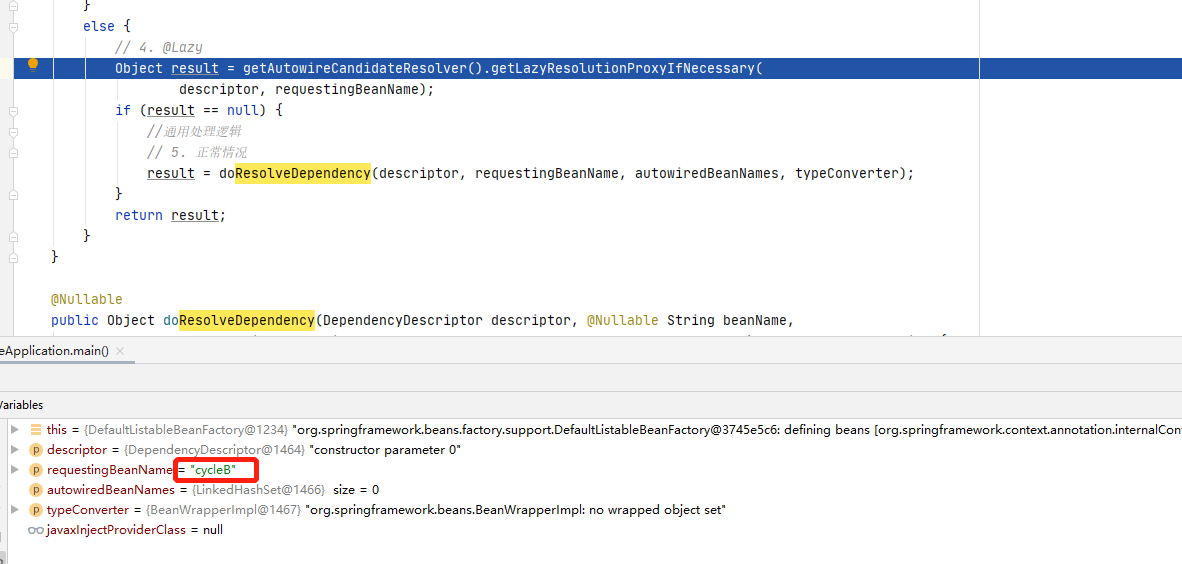
进入getLazyResolutionProxyIfNecessary()方法,这里的实现在ContextAnnotationAutowireCandidateResolver类里。

可以看到最终会调用buildLazyResolutionProxy()方法构建一个代理类返回,从而让构造函数得以正常地走下去,破坏了循环等待的条件。

那这个代理是怎么跟真正的cycleA产生联系的呢?答案在buildLazyResolutionProxy()方法的TargetSource里,截图上TargetSource的代码被我收起来了,展开代码查看,豁然开朗,原来它会再去容器里获取依赖,只不过这时候容器已经存在该bean,@Lazy也如字面意思一样做到了延迟加载该bean。
TargetSource ts = new TargetSource() {
@Override
public Class<?> getTargetClass() {
return descriptor.getDependencyType();
}
@Override
public boolean isStatic() {
return false;
}
@Override
public Object getTarget() {
// 这里会重新解析依赖
Object target = beanFactory.doResolveDependency(descriptor, beanName, null, null);
if (target == null) {
Class<?> type = getTargetClass();
if (Map.class == type) {
return Collections.emptyMap();
}
else if (List.class == type) {
return Collections.emptyList();
}
else if (Set.class == type || Collection.class == type) {
return Collections.emptySet();
}
throw new NoSuchBeanDefinitionException(descriptor.getResolvableType(),
"Optional dependency not present for lazy injection point");
}
return target;
}
@Override
public void releaseTarget(Object target) {
}
};
到这里,构造器依赖我们也处理完了。细心的朋友会说,上面可不止@Lazy可以处理,别的类型能不能处理呢?答案是能的,也是类似的延迟加载策略,感兴趣的可以继续去手动操作一下。
这一篇简单介绍了一些循环依赖是什么,然后通过@Autowired注解构造了循环依赖例子,随后通过该例子进行了源码分析。但是这样看起来似乎是太简单了,所以我们又分析了构造器依赖的场景,普通的场景下的构造器依赖注入是会报错的,但是我们有巧妙的方法能够提供一个伪参数,让构造函数能够正常的执行,从而完成构造器的循环依赖注入。随后我们分析了可以达到这个效果的原因何在,这一点是网络上很多文章都没有考虑的误区,除了@Lazy可以完成这个操作外,还有其他的几种类型参数也能完成类似的功能,使用的都是延迟加载策略。
个人水平有限,如有错误,还请指出。
如果有人看到这里,那在这里老话重提。与君共勉,路漫漫其修远兮,吾将上下而求索。