1 Runtime简介Go语言是互联网时代的C,因为其语法简洁易学,对高并发拥有语言级别的亲和性。而且不同于虚拟机的方案。Go通过在编译时嵌入平台相关的系统指令可直接编译为对应平台
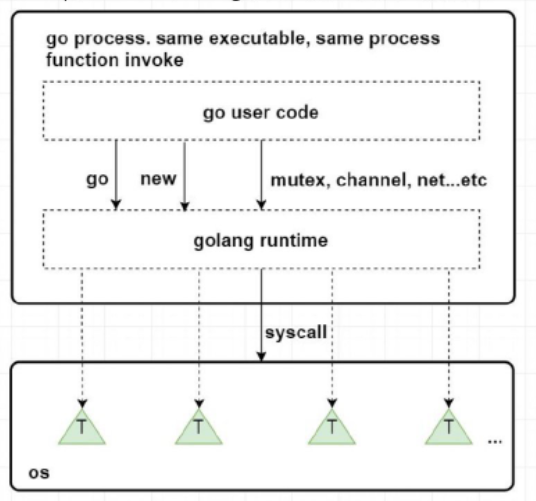 Go的runtime是与用户代码一起打包在一个可执行文件中,是程序的一部分,而不是向Java需要单独安装,与程序独立。所以用户代码与runtime代码在执行时没有界限都是函数调用。在Go语言中的关键字编译时会变成runtime中的函数调用。
Go的runtime是与用户代码一起打包在一个可执行文件中,是程序的一部分,而不是向Java需要单独安装,与程序独立。所以用户代码与runtime代码在执行时没有界限都是函数调用。在Go语言中的关键字编译时会变成runtime中的函数调用。
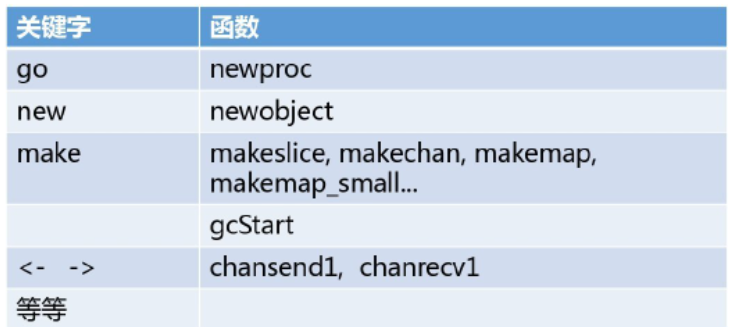 Go Runtime核心主要涉及三大部分:内存分配、调度算法、垃圾回收;本篇文章我们主要介绍GMP调度原理。关于具体应该叫GPM还是GMP,我更倾向于成为GMP,因为在runtime代码中经常看到如下调用:
Go Runtime核心主要涉及三大部分:内存分配、调度算法、垃圾回收;本篇文章我们主要介绍GMP调度原理。关于具体应该叫GPM还是GMP,我更倾向于成为GMP,因为在runtime代码中经常看到如下调用:
1 buf := &getg().m.p.ptr().wbBuf
其中getg代表获取当前正在运行的g即goroutine,m代表对应的逻辑处理器,p是逻辑调度器;所以我们还是称为GMP。
(以上部分图文来自:https://zhuanlan.zhihu.com/p/95056679)
2 GMP概览
下面这个图虽然有些抽象(不如花花绿绿的图片),确是目前我看到对整个调度算法设计的重要概念覆盖最全的。
1 +-------------------- sysmon ---------------//------+ 2 | | 3 | | 4 +---+ +---+-------+ +--------+ +---+---+ 5 go func() ---> | G | ---> | P | local | <=== balance ===> | global | <--//--- | P | M | 6 +---+ +---+-------+ +--------+ +---+---+ 7 | | | 8 | +---+ | | 9 +----> | M | <--- findrunnable ---+--- steal <--//--+ 10 +---+ 11 | 12 mstart 13 | 14 +--- execute <----- schedule 15 | | 16 | | 17 +--> G.fn --> goexit --+
我们来看下其中的三大主要概念:
- G:Groutine协程,拥有运行函数的指针、栈、上下文(指的是sp、bp、pc等寄存器上下文以及垃圾回收的标记上下文),在整个程序运行过程中可以有无数个,代表一个用户级代码执行流(用户轻量级线程);
- P:Processor,调度逻辑处理器,同样也是Go中代表资源的分配主体(内存资源、协程队列等),默认为机器核数,可以通过GOMAXPROCS环境变量调整
- M:Machine,代表实际工作的执行者,对应到操作系统级别的线程;M的数量会比P多,但不会太多,最大为1w个。
- 主协程,用来执行用户main函数的协程
- 主协程创建的协程,也是P调度的主要成员
- G0,每个M都有一个G0协程,他是runtime的一部分,G0是跟M绑定的,主要用来执行调度逻辑的代码,所以不能被抢占也不会被调度(普通G也可以执行runtime_procPin禁止抢占),G0的栈是系统分配的,比普通的G栈(2KB)要大,不能扩容也不能缩容
- sysmon协程,sysmon协程也是runtime的一部分,sysmon协程直接运行在M不需要P,主要做一些检查工作如:检查死锁、检查计时器获取下一个要被触发的计时任务、检查是否有ready的网络调用以恢复用户G的工作、检查一个G是否运行时间太长进行抢占式调度。
- 普通M,用来与P绑定执行G中任务
- m0:Go程序是一个进程,进程都有一个主线程,m0就是Go程序的主线程,通过一个与其绑定的G0来执行runtime启动加载代码;一个Go程序只有一个m0
- 运行sysmon的M,主要用来运行sysmon协程。
- 主动调度,协程通过调用`runtime.Goshed`方法主动让渡自己的执行权利,之后这个协程会被放到全局队列中,等待后续被执行
- 被动调度,协程在休眠、channel通道阻塞、网络I/O堵塞、执行垃圾回收时被暂停,被动式让渡自己的执行权利。大部分场景都是被动调度,这是Go高性能的一个原因,让M永远不停歇,不处于等待的协程让出CPU资源执行其他任务。
- 抢占式调度,这个主要是sysmon协程上的调度,当发现G处于系统调用(如调用网络io)超过20微秒或者G运行时间过长(超过10ms),会抢占G的执行CPU资源,让渡给其他协程;防止其他协程没有执行的机会;(系统调用会进入内核态,由内核线程完成,可以把当前CPU资源让渡给其他用户协程)
- 调度发生地点:Go中协程的调度发生在runtime,属于用户态,不涉及与内核态的切换;一个协程可以被切换到多个线程执行
- 上下文切换速度:协程的切换速度远快于线程,不需要经过内核与用户态切换,同时需要保存的状态和寄存器非常少;线程切换速度为1-2微秒,协程切换速度为0.2微秒左右
- 调度策略:线程调度大部分都是抢占式调度,操作系统通过发出中断信号强制线程切换上下文;Go的协程基本是主动和被动式调度,调度时机可预期
- 栈大小:线程栈一般是2MB,而且运行时不能更改大小;Go的协程栈只有2kb,而且可以动态扩容(64位机最大为1G)
1 runtime/amd_64.s 涉及到进程启动以及对CPU执行指令进行控制的汇编代码,进程的初始化部分也在这里面 2 runtime/runtime2.go 这里主要是运行时中一些重要数据结构的定义,比如g、m、p以及涉及到接口、defer、panic、map、slice等核心类型 3 runtime/proc.go 一些核心方法的实现,涉及gmp调度等核心代码在这里这里我们主要关心gmp中与调度相关的代码; 3.1 G源码部分 3.1.1 G的结构 先来看下g的结构定义:
1 // runtime/runtime2.go 2 type g struct { 3 // 记录协程栈的栈顶和栈底位置 4 stack stack // offset known to runtime/cgo 5 // 主要作用是参与一些比较计算,当发现容量要超过栈分配空间后,可以进行扩容或者收缩 6 stackguard0 uintptr // offset known to liblink 7 stackguard1 uintptr // offset known to liblink 8 9 // 当前与g绑定的m 10 m *m // current m; offset known to arm liblink 11 // 这是一个比较重要的字段,里面保存的一些与goroutine运行位置相关的寄存器和指针,如rsp、rbp、rpc等寄存器 12 sched gobuf 13 syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc 14 syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc 15 stktopsp uintptr // expected sp at top of stack, to check in traceback 16 17 // 用于做参数传递,睡眠时其他goroutine可以设置param,唤醒时该g可以读取这些param 18 param unsafe.Pointer 19 // 记录当前goroutine的状态 20 atomicstatus uint32 21 stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus 22 // goroutine的唯一id 23 goid int64 24 schedlink guintptr 25 26 // 标记是否可以被抢占 27 preempt bool // preemption signal, duplicates stackguard0 = stackpreempt 28 preemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule 29 preemptShrink bool // shrink stack at synchronous safe point 30 31 // 如果调用了LockOsThread方法,则g会绑定到某个m上,只在这个m上运行 32 lockedm muintptr 33 sig uint32 34 writebuf []byte 35 sigcode0 uintptr 36 sigcode1 uintptr 37 sigpc uintptr 38 // 创建该goroutine的语句的指令地址 39 gopc uintptr // pc of go statement that created this goroutine 40 ancestors *[]ancestorInfo // ancestor information goroutine(s) that created this goroutine (only used if debug.tracebackancestors) 41 // goroutine函数的指令地址 42 startpc uintptr // pc of goroutine function 43 racectx uintptr 44 waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order 45 cgoCtxt []uintptr // cgo traceback context 46 labels unsafe.Pointer // profiler labels 47 timer *timer // cached timer for time.Sleep 48 selectDone uint32 // are we participating in a select and did someone win the race? 49 }
跟g相关的还有两个数据结构比较重要: stack是协程栈的地址信息,需要注意的是m0绑定的g0是在进程被分配的系统栈上分配协程栈的,而其他协程栈都是在堆上进行分配的。 gobuf中保存了协程执行的上下文信息,这里也可以看到协程切换的上下文信息极少;sp代表cpu的rsp寄存器的值,pc代表CPU的rip寄存器值、bp代表CPU的rbp寄存器值;ret用来保存系统调用的返回值,ctxt在gc的时候使用。 其中几个寄存器作用如下:
- SP:永远指向栈顶位置
- BP:某一时刻的栈顶位置,当新函数调用时,把当前SP地址赋值给BP、SP指向新的栈顶位置
- PC:代表代码经过编译为机器码后,当前执行的机器指令(可以理解为当前语句)
1 // Stack describes a Go execution stack. 2 // The bounds of the stack are exactly [lo, hi), 3 // with no implicit data structures on either side. 4 // goroutine协程栈的栈顶和栈底 5 type stack struct { 6 lo uintptr // 栈顶,低地址 7 hi uintptr // 栈底,高地址 8 } 9 10 // gobuf中保存了非常重要的上下文执行信息, 11 type gobuf struct { 12 // 代表cpu的rsp寄存器的值,永远指向栈顶位置 13 sp uintptr 14 // 代表代码经过编译为机器码后,当前执行的机器指令(可以理解为当前语句) 15 pc uintptr 16 // 指向所保存执行上下文的goroutine 17 g guintptr 18 // gc时候使用 19 ctxt unsafe.Pointer 20 // 用来保存系统调用的返回值 21 ret uintptr 22 lr uintptr 23 // 某一时刻的栈顶位置,当新函数调用时,把当前SP地址赋值给BP、SP指向新的栈顶位置 24 bp uintptr // for framepointer-enabled architectures 25 }
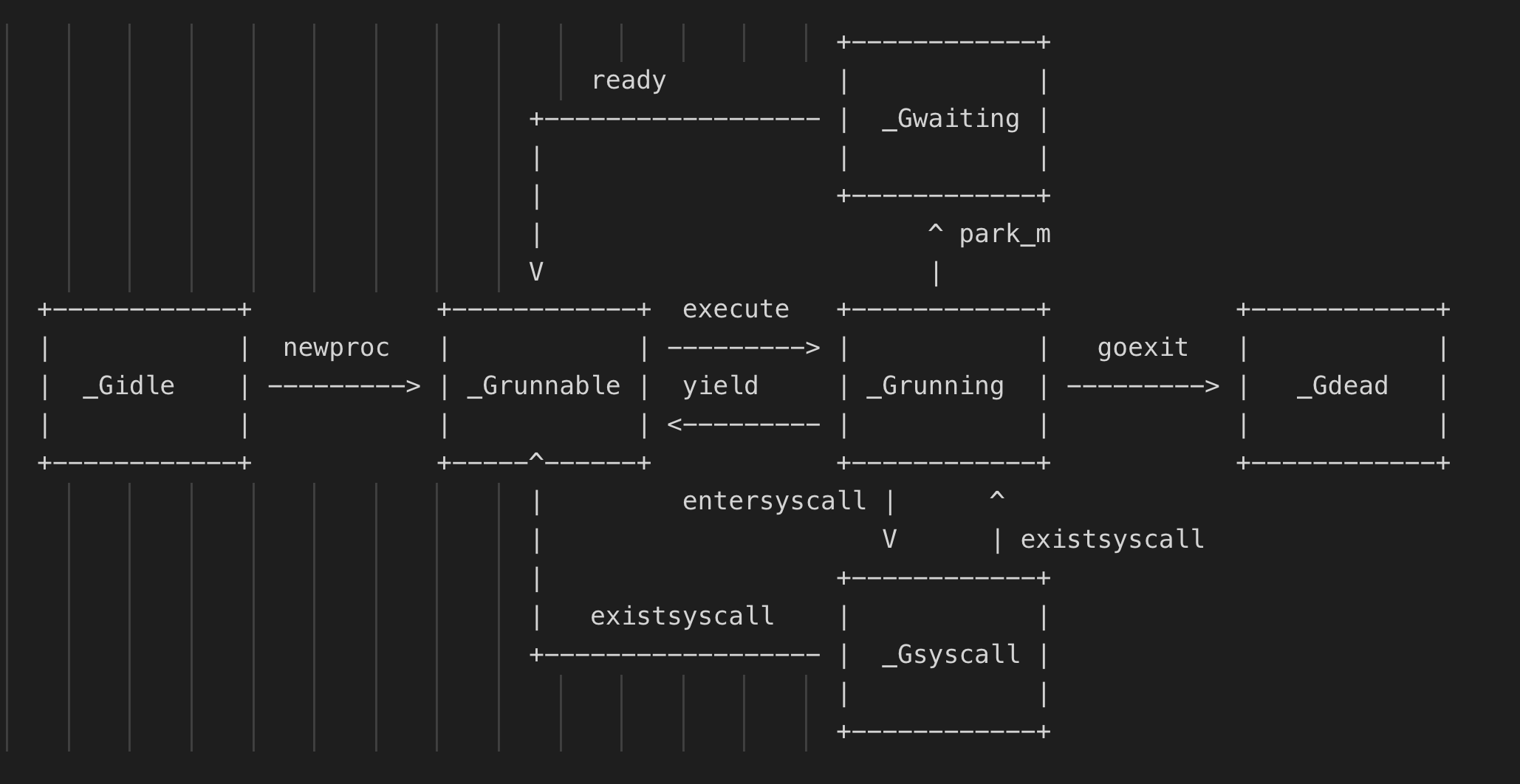
3.1.2 G的状态 就像线程有自己的状态一样,goroutine也有自己的状态,主要记录在atomicstatus字段上:
1 // defined constants 2 const ( 3 // 代表协程刚开始创建时的状态,当新创建的协程初始化后,为变为_Gdead状态,_Gdread也是协程被销毁时的状态; 4 // 刚创建时也被会置为_Gdead主要是考虑GC可以去用去扫描dead状态下的协程栈 5 _Gidle = iota // 0 6 // 代表协程正在运行队列中,等待被运行 7 _Grunnable // 1 8 // 代表当前协程正在被运行,已经被分配了逻辑处理的线程,即p和m 9 _Grunning // 2 10 // 代表当前协程正在执行系统调用 11 _Gsyscall // 3 12 // 表示当前协程在运行时被锁定,陷入阻塞,不能执行用户代码 13 _Gwaiting // 4 14 15 _Gmoribund_unused // 5 16 // 新创建的协程初始化后,或者协程被销毁后的状态 17 _Gdead // 6 18 19 // _Genqueue_unused is currently unused. 20 _Genqueue_unused // 7 21 // 代表在进行协程栈扫描时发现需要扩容或者缩容,将协程中的栈转移到新栈时的状态;这个时候不执行用户代码,也不在p的runq中 22 _Gcopystack // 8 23 24 // 代表g被抢占后的状态 25 _Gpreempted // 9 26 27 // 这几个状态是垃圾回收时涉及,后续文章进行介绍 28 _Gscan = 0x1000 29 _Gscanrunnable = _Gscan + _Grunnable // 0x1001 30 _Gscanrunning = _Gscan + _Grunning // 0x1002 31 _Gscansyscall = _Gscan + _Gsyscall // 0x1003 32 _Gscanwaiting = _Gscan + _Gwaiting // 0x1004 33 _Gscanpreempted = _Gscan + _Gpreempted // 0x1009 34 )
这里是利用常量定义的枚举。 Go的状态变更可以看下图:
 3.1.3 G的创建
当我们使用go关键字新建一个goroutine时,编译器会编译为runtime中对应的函数调用(newproc,而go 关键字后面的函数成为协程的任务函数),进行创建,整体步骤如下:
1. 用 systemstack 切换到系统堆栈,调用 newproc1 ,newproc1 实现g的获取。
2. 尝试从p的本地g空闲链表和全局g空闲链表找到一个g的实例。
3. 如果上面未找到,则调用 malg 生成新的g的实例,且分配好g的栈和设置好栈的边界,接着添加到 allgs 数组里面,allgs保存了所有的g。
4. 保存g切换的上下文,这里很关键,g的切换依赖 sched 字段。
5. 生成唯一的goid,赋值给该g。
6. 调用 runqput 将g插入队列中,如果本地队列还有剩余的位置,将G插入本地队列的尾部,若本地队列已满,插入全局队列。
7. 如果有空闲的p 且 m没有处于自旋状态 且 main goroutine已经启动,那么唤醒或新建某个m来执行任务。
这里对应的是newproc函数:
3.1.3 G的创建
当我们使用go关键字新建一个goroutine时,编译器会编译为runtime中对应的函数调用(newproc,而go 关键字后面的函数成为协程的任务函数),进行创建,整体步骤如下:
1. 用 systemstack 切换到系统堆栈,调用 newproc1 ,newproc1 实现g的获取。
2. 尝试从p的本地g空闲链表和全局g空闲链表找到一个g的实例。
3. 如果上面未找到,则调用 malg 生成新的g的实例,且分配好g的栈和设置好栈的边界,接着添加到 allgs 数组里面,allgs保存了所有的g。
4. 保存g切换的上下文,这里很关键,g的切换依赖 sched 字段。
5. 生成唯一的goid,赋值给该g。
6. 调用 runqput 将g插入队列中,如果本地队列还有剩余的位置,将G插入本地队列的尾部,若本地队列已满,插入全局队列。
7. 如果有空闲的p 且 m没有处于自旋状态 且 main goroutine已经启动,那么唤醒或新建某个m来执行任务。
这里对应的是newproc函数:
1 func newproc(siz int32, fn *funcval) { 2 argp := add(unsafe.Pointer(&fn), sys.PtrSize) 3 gp := getg() 4 // 获取调用者的指令地址,也就是调用newproc时又call指令压栈的函数返回地址 5 pc := getcallerpc() 6 // systemstack的作用是切换到m0对应的g0所属的系统栈 7 // 使用g0所在的系统栈创建goroutine对象 8 // 传递参数包括goroutine的任务函数、argp参数起始地址、siz是参数长度、调用方的pc指针 9 systemstack(func() { 10 newg := newproc1(fn, argp, siz, gp, pc) 11 // 创建完成后将g放到创建者(某个g,如果是进程初始化启动阶段则为g0)所在的p的队列中 12 _p_ := getg().m.p.ptr() 13 runqput(_p_, newg, true) 14 15 if mainStarted { 16 wakep() 17 } 18 }) 19 }其中systemstack是一段汇编代码,位于asm_amd64.s文件中,主要是寄存器指令的操作,笔者不懂汇编这里先不做介绍。 newproc1是获取newg的函数,主要步骤: 1、首先防止当前g被抢占,绑定m 2、对传入的参数占用的内存空间进行对齐处理 3、从p的空闲队列中获取一个空闲的g,如果么有就创建一个g,并在堆上创建协程栈,并设置状态为_Gdead添加到全局allgs中 4、计算整体协程任务函数的参数空间大小,并设置sp指针 5、执行参数从getg的堆栈到newg堆栈的复制 6、设置newg的sched和startpc、gopc等跟上下文相关的字段值 7、设置newg状态为runable并设置goid 8、接触getg与m的防抢占状态 代码注释如下:
1 func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) *g { 2 ..... 3 // 如果是初始化时候这个代表g0 4 _g_ := getg() 5 6 if fn == nil { 7 _g_.m.throwing = -1 // do not dump full stacks 8 throw("go of nil func value") 9 } 10 // 使_g_.m.locks++,来防止这个时候g对应的m被抢占 11 acquirem() // disable preemption because it can be holding p in a local var 12 // 参数的地址,下面一句目的是为了做到内存对齐 13 siz := narg 14 siz = (siz + 7) &^ 7 15 16 // We could allocate a larger initial stack if necessary. 17 // Not worth it: this is almost always an error. 18 // 4*PtrSize: extra space added below 19 // PtrSize: caller's LR (arm) or return address (x86, in gostartcall). 20 if siz >= _StackMin-4*sys.PtrSize-sys.PtrSize { 21 throw("newproc: function arguments too large for new goroutine") 22 } 23 24 _p_ := _g_.m.p.ptr() 25 newg := gfget(_p_) // 首先从p的gfree队列中看看有没有空闲的g,有则使用 26 if newg == nil { 27 // 如果没找到就使用new关键字来创建一个g并在堆上分配栈空间 28 newg = malg(_StackMin) 29 // 将newg的状态设置为_Gdead,因为这样GC就不会去扫描一个没有初始化的协程栈 30 casgstatus(newg, _Gidle, _Gdead) 31 // 添加到全局的allg切片中(需要加锁访问) 32 allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack. 33 } 34 // 下面是检查协程栈的创建情况和状态 35 if newg.stack.hi == 0 { 36 throw("newproc1: newg missing stack") 37 } 38 39 if readgstatus(newg) != _Gdead { 40 throw("newproc1: new g is not Gdead") 41 } 42 // 计算运行空间大小并进行内存对齐 43 totalSize := 4*sys.PtrSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame 44 totalSize += -totalSize & (sys.StackAlign - 1) // align to StackAlign 45 // 计算sp寄存器指针的位置 46 sp := newg.stack.hi - totalSize 47 // 确定参数入栈位置 48 spArg := sp 49 ......... 50 if narg > 0 { 51 // 将参数从newproc函数的栈复制到新的协程的栈中,memove是一段汇编代码 52 // 从argp位置挪动narg大小的内存到sparg位置 53 memmove(unsafe.Pointer(spArg), argp, uintptr(narg)) 54 // 因为涉及到从栈到堆栈上的复制,go在垃圾回收中使用了三色标记和写入屏障等手段,所以这里要考虑屏障复制 55 // 目标栈可能会有垃圾存在,所以设置屏障并且标记为灰色 56 if writeBarrier.needed && !_g_.m.curg.gcscandone { // 如果启用了写入屏障并且源堆栈为灰色(目标始终为黑色),则执行屏障复制。 57 f := findfunc(fn.fn) 58 stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps)) 59 if stkmap.nbit > 0 { 60 // We're in the prologue, so it's always stack map index 0. 61 bv := stackmapdata(stkmap, 0) 62 bulkBarrierBitmap(spArg, spArg, uintptr(bv.n)*sys.PtrSize, 0, bv.bytedata) 63 } 64 } 65 } 66 // 把newg的sched结构体成员的所有字段都设置为0,其实就是初始化 67 memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched)) 68 newg.sched.sp = sp 69 newg.stktopsp = sp 70 // pc指针表示当newg被调度起来时从这个位置开始执行 71 // 这里是先设置为goexit,在gostartcallfn中会进行处理,更改sp为这里的pc,将pc改为真正的协程任务函数fn的指令位置 72 // 这样使得任务函数执行完毕后,会继续执行goexit中相关的清理工作 73 newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function 74 newg.sched.g = guintptr(unsafe.Pointer(newg)) // 保存当前的g 75 gostartcallfn(&newg.sched, fn) // 在这里完成g启动时所有相关上下文指针的设置,主要为sp、pc和ctxt,ctxt被设置为fn 76 newg.gopc = callerpc // 保存newproc的pc,即调用者创建时的指令位置 77 newg.ancestors = saveAncestors(callergp) 78 // 设置startpc为任务函数,主要用于函数调用栈的trackback和栈收缩工作 79 // newg的执行开始位置并不依赖这个字段,而是通过sched.pc确定 80 newg.startpc = fn.fn 81 if _g_.m.curg != nil { 82 newg.labels = _g_.m.curg.labels 83 } 84 // 判断newg的任务函数是不是runtime系统的任务函数,是则sched.ngsys+1; 85 // 主协程则代表runtime.main函数,在这里就为判断为真 86 if isSystemGoroutine(newg, false) { 87 atomic.Xadd(&sched.ngsys, +1) 88 } 89 // Track initial transition? 90 newg.trackingSeq = uint8(fastrand()) 91 if newg.trackingSeq%gTrackingPeriod == 0 { 92 newg.tracking = true 93 } 94 // 更改当前g的状态为_Grunnable 95 casgstatus(newg, _Gdead, _Grunnable) 96 // 设置g的goid,因为p会每次批量生成16个id,每次newproc如果新建一个g,id就会加1 97 // 所以这里m0的g0的id为0,而主协程的goid为1,其他的依次递增 98 if _p_.goidcache == _p_.goidcacheend { 99 // Sched.goidgen is the last allocated id, 100 // this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch]. 101 // At startup sched.goidgen=0, so main goroutine receives goid=1. 102 // 使用原子操作修改全局变量,这里的sched是在runtime2.go中的一个全局变量类型为schedt 103 // 原子操作具有多线程可见性,同时比加锁性能更高 104 _p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch) 105 _p_.goidcache -= _GoidCacheBatch - 1 106 _p_.goidcacheend = _p_.goidcache + _GoidCacheBatch 107 } 108 newg.goid = int64(_p_.goidcache) 109 _p_.goidcache++ 110 if raceenabled { 111 newg.racectx = racegostart(callerpc) 112 } 113 if trace.enabled { 114 traceGoCreate(newg, newg.startpc) 115 } 116 // 释放getg与m的绑定 117 releasem(_g_.m) 118 119 return newg 120 }其中有几个关键地方需要强调 3.1.4 协程栈在堆空间的分配 malg函数,用来创建一个新g和对应的栈空间分配,这个函数主要强调的是栈空间分配部分,通过切换到系统栈上进行空间分配,分配完后设置栈底和栈顶的两个位置的保护字段,当栈上进行分配变量空间发现超过stackguard1时,会进行扩容,同时在某些条件下也会进行缩容
1 // Allocate a new g, with a stack big enough for stacksize bytes. 2 func malg(stacksize int32) *g { 3 newg := new(g) 4 if stacksize >= 0 { 5 stacksize = round2(_StackSystem + stacksize) 6 systemstack(func() { 7 newg.stack = stackalloc(uint32(stacksize)) 8 }) 9 newg.stackguard0 = newg.stack.lo + _StackGuard 10 newg.stackguard1 = ^uintptr(0) 11 // Clear the bottom word of the stack. We record g 12 // there on gsignal stack during VDSO on ARM and ARM64. 13 *(*uintptr)(unsafe.Pointer(newg.stack.lo)) = 0 14 } 15 return newg 16 }stackalloc代码位于runtime/stack.go文件中; 协程栈首先在进程初始化时会创建栈的管理结构: 1、栈池stackpool,这个栈池主要用来对大小为2、4、8kb的小栈做缓存使用,使用的同样是mspan这种结构来存储; 2、为大栈分配的stackLarge
1 OS | FixedStack | NumStackOrders 2 -----------------+------------+--------------- 3 linux/darwin/bsd | 2KB | 4 4 windows/32 | 4KB | 3 5 windows/64 | 8KB | 2 6 plan9 | 4KB | 3 7 8 // Global pool of spans that have free stacks. 9 // Stacks are assigned an order according to size. 10 // order = log_2(size/FixedStack) 11 // There is a free list for each order. 12 var stackpool [_NumStackOrders]struct { 13 item stackpoolItem 14 _ [cpu.CacheLinePadSize - unsafe.Sizeof(stackpoolItem{})%cpu.CacheLinePadSize]byte 15 } 16 17 //go:notinheap 18 type stackpoolItem struct { 19 mu mutex 20 span mSpanList 21 } 22 23 // Global pool of large stack spans. 24 var stackLarge struct { 25 lock mutex 26 free [heapAddrBits - pageShift]mSpanList // free lists by log_2(s.npages) 27 } 28 29 func stackinit() { 30 if _StackCacheSize&_PageMask != 0 { 31 throw("cache size must be a multiple of page size") 32 } 33 for i := range stackpool { 34 stackpool[i].item.span.init() 35 lockInit(&stackpool[i].item.mu, lockRankStackpool) 36 } 37 for i := range stackLarge.free { 38 stackLarge.free[i].init() 39 lockInit(&stackLarge.lock, lockRankStackLarge) 40 } 41 }stackalloc会首先判断栈空间大小,是大栈还是固定空间的小栈, 1、对于小栈,如果是还没有分配栈缓存空间,则进入stackpoolalloc函数进行分配空间(需要加锁),这里最终是从全局的mheap也就是堆空间中获取内存空间;如果有栈缓存空间,则从g对应的mcache中的stackcache上获取内存空间(无锁),如果stackcache上没有足够空间则调用stackcacherefill方法为stackpool进行扩容(也是从mheap中拿取,加锁)然后分配给协程 2、对于大栈,先从stackLarge中获取,如果没有则从mheap中获取,两个步骤都需要加载访问; 3、最后创建stack结构返回给newg
1 func stackalloc(n uint32) stack { 2 // Stackalloc must be called on scheduler stack, so that we 3 // never try to grow the stack during the code that stackalloc runs. 4 // Doing so would cause a deadlock (issue 1547). 5 thisg := getg() 6 ......... 7 8 // Small stacks are allocated with a fixed-size free-list allocator. 9 // If we need a stack of a bigger size, we fall back on allocating 10 // a dedicated span. 11 var v unsafe.Pointer 12 if n < _FixedStack<<_NumStackOrders && n < _StackCacheSize { 13 order := uint8(0) 14 n2 := n 15 for n2 > _FixedStack { 16 order++ 17 n2 >>= 1 18 } 19 var x gclinkptr 20 if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" { 21 // thisg.m.p == 0 can happen in the guts of exitsyscall 22 // or procresize. Just get a stack from the global pool. 23 // Also don't touch stackcache during gc 24 // as it's flushed concurrently. 25 lock(&stackpool[order].item.mu) 26 x = stackpoolalloc(order) 27 unlock(&stackpool[order].item.mu) 28 } else { 29 c := thisg.m.p.ptr().mcache 30 x = c.stackcache[order].list 31 if x.ptr() == nil { 32 stackcacherefill(c, order) 33 x = c.stackcache[order].list 34 } 35 c.stackcache[order].list = x.ptr().next 36 c.stackcache[order].size -= uintptr(n) 37 } 38 v = unsafe.Pointer(x) 39 } else { 40 var s *mspan 41 npage := uintptr(n) >> _PageShift 42 log2npage := stacklog2(npage) 43 44 // Try to get a stack from the large stack cache. 45 lock(&stackLarge.lock) 46 if !stackLarge.free[log2npage].isEmpty() { 47 s = stackLarge.free[log2npage].first 48 stackLarge.free[log2npage].remove(s) 49 } 50 unlock(&stackLarge.lock) 51 52 lockWithRankMayAcquire(&mheap_.lock, lockRankMheap) 53 54 if s == nil { 55 // Allocate a new stack from the heap. 56 s = mheap_.allocManual(npage, spanAllocStack) 57 if s == nil { 58 throw("out of memory") 59 } 60 osStackAlloc(s) 61 s.elemsize = uintptr(n) 62 } 63 v = unsafe.Pointer(s.base()) 64 } 65 66 if raceenabled { 67 racemalloc(v, uintptr(n)) 68 } 69 if msanenabled { 70 msanmalloc(v, uintptr(n)) 71 } 72 if stackDebug >= 1 { 73 print(" allocated ", v, "\n") 74 } 75 return stack{uintptr(v), uintptr(v) + uintptr(n)} 76 }非g0的g为什么要在堆上分配空间? 虽然堆不如栈快,但是goroutine是go模拟的线程,具有动态扩容和缩容的能力,而系统栈是线性空间,在系统栈上发生缩容和扩容会存在空间不足或者栈空间碎片等问题;所以go这里在堆上分配协程栈;因为是在堆空间也就意味着这部分空间也需要进行垃圾回收和释放;所以Go的GC是多线程并发标记时,内存屏障是对整个协程栈标记灰色,来让回收器进行扫描。 3.1.5 G的上下文设置和切换 协程栈的切换主要是在两个地方,由执行调度逻辑的g0切换到执行用户逻辑的g的过程,以及执行用户逻辑的g退出或者被抢占切换为g0执行调度的过程,抢占在下文中介绍 上面代码中当newg被初始化时,会初始化sched中的pc和sp指针,其中会把pc先设置为goexit函数的第二条指令。
1 // 把newg的sched结构体成员的所有字段都设置为0,其实就是初始化 2 memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched)) 3 newg.sched.sp = sp 4 newg.stktopsp = sp 5 // pc指针表示当newg被调度起来时从这个位置开始执行 6 // 这里是先设置为goexit,在gostartcallfn中会进行处理,更改sp为这里的pc,将pc改为真正的协程任务函数fn的指令位置 7 // 这样使得任务函数执行完毕后,会继续执行goexit中相关的清理工作 8 newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function 9 newg.sched.g = guintptr(unsafe.Pointer(newg)) // 保存当前的g 10 gostartcallfn(&newg.sched, fn) // 在这里完成g启动时所有相关上下文指针的设置,主要为sp、pc和ctxt,ctxt被设置为fn 11 newg.gopc = callerpc // 保存newproc的pc,即调用者创建时的指令位置然后进入gostartcallfn函数,最终是在gostartcall函数中进行处理
1 // gostartcallfn 位于runtime/stack.go中 2 3 func gostartcallfn(gobuf *gobuf, fv *funcval) { 4 var fn unsafe.Pointer 5 if fv != nil { 6 fn = unsafe.Pointer(fv.fn) 7 } else { 8 fn = unsafe.Pointer(funcPC(nilfunc)) 9 } 10 gostartcall(gobuf, fn, unsafe.Pointer(fv)) 11 } 12 13 // gostartcall 位于runtime/sys_x86.go中 14 15 func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) { 16 // newg的栈顶,目前newg栈上只有fn函数的参数,sp指向的是fn的第一个参数 17 sp := buf.sp 18 // 为返回地址预留空间 19 sp -= sys.PtrSize 20 // buf.pc中设置的是goexit函数中的第二条指令 21 // 因为栈是自顶向下,先进后出,所以这里伪装fn是被goexit函数调用的,goexit在前fn在后 22 // 使得fn返回后到goexit继续执行,以完成一些清理工作。 23 *(*uintptr)(unsafe.Pointer(sp)) = buf.pc 24 buf.sp = sp // 重新设置栈顶 25 // 将pc指向goroutine的任务函数fn,这样当goroutine获得执行权时,从任务函数入口开始执行 26 // 如果是主协程,那么fn就是runtime.main,从这里开始执行 27 buf.pc = uintptr(fn) 28 buf.ctxt = ctxt 29 }可以看到在newg初始化时进行的一系列设置工作,将goexit先压入栈顶,然后伪造sp位置,让cpu看起来是从goexit中调用的协程任务函数,然后将pc指针指向任务函数,当协程被执行时,从pc处开始执行,任务函数执行完毕后执行goexit; 这里是设置工作,具体的切换工作,需要经由schedule调度函数选中一个g,进入execute函数设置g的相关状态和栈保护字段等信息,然后进入gogo函数,通过汇编语言,将CPU寄存器以及函数调用栈切换为g的sched中相关指针和协程栈。gogo函数源码如下:
1 // gogo的具体汇编代码位于asm_amd64.s中 2 3 // func gogo(buf *gobuf) 4 // restore state from Gobuf; longjmp 5 TEXT runtime·gogo(SB), NOSPLIT, $0-8 6 // 0(FP)表示第一个参数,即buf=&gp.sched 7 MOVQ buf+0(FP), BX // gobuf 8 // DX = gp.sched.g,DX代表数据寄存器 9 MOVQ gobuf_g(BX), DX 10 MOVQ 0(DX), CX // make sure g != nil 11 JMP gogo<>(SB) 12 13 TEXT gogo<>(SB), NOSPLIT, $0 14 // 将tls保存到CX寄存器 15 get_tls(CX) 16 // 下面这条指令把当前要运行的g(上面第9行中已经把go_buf中的g放入到了DX中), 17 // 放入CX寄存器的g位置即tls[0]这个位置,也就是线程的本地存储中, 18 // 这样下次runtime中调用getg时获取的就是这个g 19 MOVQ DX, g(CX) 20 MOVQ DX, R14 // set the g register 21 // 把CPU的SP寄存器设置为g.sched.sp这样就完成了栈的切换,从g0切换为g 22 MOVQ gobuf_sp(BX), SP // restore SP 23 // 将ret、ctxt、bp分别存入对应的寄存器,完成了CPU上下文的切换 24 MOVQ gobuf_ret(BX), AX 25 MOVQ gobuf_ctxt(BX), DX 26 MOVQ gobuf_bp(BX), BP 27 // 清空sched的值,相关值已经存入到寄存器中,这里清空后可以减少GC的工作量 28 MOVQ $0, gobuf_sp(BX) // clear to help garbage collector 29 MOVQ $0, gobuf_ret(BX) 30 MOVQ $0, gobuf_ctxt(BX) 31 MOVQ $0, gobuf_bp(BX) 32 // 把sched.pc放入BX寄存器 33 MOVQ gobuf_pc(BX), BX 34 // JMP把BX的值放入CPU的IP寄存器,所以这时候CPU从该地址开始继续执行指令 35 JMP BXAX、BX、CX、DX是8086处理器的4个数据寄存器,可以简单认为相当于4个硬件的变量; 上文总体来说,将g存入到tls中(线程的本地存储),设置SP和相关寄存器为g.sched中的字段(SP、ret、ctxt、bp),然后跳转到pc指针位置执行指令 3.1.6 G的退出处理 协程栈的退出需要分为两种情况,即运行main函数的主协程和普通的用户协程; 主协程的fn任务函数位于proc.go中的main函数中,对于主协程g.shched.pc指向的也是这个位置,这里会调用用户的mian函数(main_main),main_main运行完毕后,会调用exit(0)直接退出,而不会跑到goexit函数中。
1 // runtime/proc.go 中的main函数 2 // The main goroutine. 3 func main() { 4 g := getg() 5 6 ................. 7 fn := main_main // make an indirect call, as the linker doesn't know the address of the main package when laying down the runtime 8 fn() 9 .................. 10 .................. 11 exit(0) 12 .................. 13 }用户协程因为将goexit作为协程栈栈底,所以当执行完协程任务函数时,会执行goexit函数,goexit是一段汇编指令:
1 // The top-most function running on a goroutine 2 // returns to goexit+PCQuantum. 3 TEXT runtime·goexit(SB),NOSPLIT|TOPFRAME,$0-0 4 BYTE $0x90 // NOP 5 CALL runtime·goexit1(SB) // does not return 6 // traceback from goexit1 must hit code range of goexit 7 BYTE $0x90 // NOP这里直接调用goexit1,goexit1位于runtime/proc.go中
1 // Finishes execution of the current goroutine. 2 func goexit1() { 3 if raceenabled { 4 racegoend() 5 } 6 if trace.enabled { 7 traceGoEnd() 8 } 9 mcall(goexit0) 10 }通过mcall调用goexit0,mcall是一段汇编代码它的作用是把执行的栈切换到g0的栈
1 TEXT runtime·mcall<ABIInternal>(SB), NOSPLIT, $0-8 2 MOVQ AX, DX // DX = fn 3 4 // save state in g->sched 5 // mcall返回地址放入BX中 6 MOVQ 0(SP), BX // caller's PC 7 // 下面部分是保存g的执行上下文,pc、sp、bp 8 // g.shced.pc = BX 9 MOVQ BX, (g_sched+gobuf_pc)(R14) 10 LEAQ fn+0(FP), BX // caller's SP 11 MOVQ BX, (g_sched+gobuf_sp)(R14) 12 MOVQ BP, (g_sched+gobuf_bp)(R14) 13 14 // switch to m->g0 & its stack, call fn 15 // 将g.m保存到BX寄存器中 16 MOVQ g_m(R14), BX 17 // 这段代码意思是从m结构体中获取g0字段保存到SI中 18 MOVQ m_g0(BX), SI // SI = g.m.g0 19 CMPQ SI, R14 // if g == m->g0 call badmcall 20 // goodm中完成了从g的栈切换到g0的栈 21 JNE goodm 22 JMP runtime·badmcall(SB) 23 goodm: 24 MOVQ R14, AX // AX (and arg 0) = g 25 MOVQ SI, R14 // g = g.m.g0 26 get_tls(CX) // Set G in TLS 27 MOVQ R14, g(CX) 28 MOVQ (g_sched+gobuf_sp)(R14), SP // sp = g0.sched.sp 29 PUSHQ AX // open up space for fn's arg spill slot 30 MOVQ 0(DX), R12 31 // 这里意思是调用goexit0(g) 32 CALL R12 // fn(g) 33 POPQ AX 34 JMP runtime·badmcall2(SB) 35 RETgoexit0代码位于runtime/proc.go中,他主要完成最后的清理工作: 1、把g的状态从——Gruning变为Gdead 2、清空g的一些字段 3、接触g与m的绑定关系,即g.m = nil;m.currg = nil 4、把g放入p的freeg队列中,下次创建g可以直接获取,而不用从内存分配 5、调用schedule进入下一次调度循环
1 // 这段代码执行在g0的栈上,gp是我们要处理退出的g的结构体指针 2 // goexit continuation on g0. 3 func goexit0(gp *g) { 4 _g_ := getg() // 获取g0 5 // 更改g的状态为_Gdead 6 casgstatus(gp, _Grunning, _Gdead) 7 if isSystemGoroutine(gp, false) { 8 atomic.Xadd(&sched.ngsys, -1) 9 } 10 // 清空g的一些字段 11 gp.m = nil 12 locked := gp.lockedm != 0 13 gp.lockedm = 0 14 _g_.m.lockedg = 0 15 gp.preemptStop = false 16 gp.paniconfault = false 17 gp._defer = nil // should be true already but just in case. 18 gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data. 19 gp.writebuf = nil 20 gp.waitreason = 0 21 gp.param = nil 22 gp.labels = nil 23 gp.timer = nil 24 25 if gcBlackenEnabled != 0 && gp.gcAssistBytes > 0 { 26 // Flush assist credit to the global pool. This gives 27 // better information to pacing if the application is 28 // rapidly creating an exiting goroutines. 29 assistWorkPerByte := float64frombits(atomic.Load64(&gcController.assistWorkPerByte)) 30 scanCredit := int64(assistWorkPerByte * float64(gp.gcAssistBytes)) 31 atomic.Xaddint64(&gcController.bgScanCredit, scanCredit) 32 gp.gcAssistBytes = 0 33 } 34 // 接触g与m的绑定关系 35 dropg() 36 37 if GOARCH == "wasm" { // no threads yet on wasm 38 gfput(_g_.m.p.ptr(), gp) 39 schedule() // never returns 40 } 41 42 if _g_.m.lockedInt != 0 { 43 print("invalid m->lockedInt = ", _g_.m.lockedInt, "\n") 44 throw("internal lockOSThread error") 45 } 46 // 将g加入p的空闲队列 47 gfput(_g_.m.p.ptr(), gp) 48 if locked { 49 // The goroutine may have locked this thread because 50 // it put it in an unusual kernel state. Kill it 51 // rather than returning it to the thread pool. 52 53 // Return to mstart, which will release the P and exit 54 // the thread. 55 if GOOS != "plan9" { // See golang.org/issue/22227. 56 gogo(&_g_.m.g0.sched) 57 } else { 58 // Clear lockedExt on plan9 since we may end up re-using 59 // this thread. 60 _g_.m.lockedExt = 0 61 } 62 } 63 // 执行下一轮调度 64 schedule() 65 }
3.2 P源码部分 3.2.1 P的结构
1 // runtime/runtime2.go 2 3 type p struct { 4 // 全局变量allp中的索引位置 5 id int32 6 // p的状态标识 7 status uint32 // one of pidle/prunning/... 8 link puintptr 9 // 调用schedule的次数,每次调用schedule这个值会加1 10 schedtick uint32 // incremented on every scheduler call 11 // 系统调用的次数,每次进行系统调用加1 12 syscalltick uint32 // incremented on every system call 13 // 用于sysmon协程记录被监控的p的系统调用时间和运行时间 14 sysmontick sysmontick // last tick observed by sysmon 15 // 指向绑定的m,p如果是idle状态这个值为nil 16 m muintptr // back-link to associated m (nil if idle) 17 // 用于分配微小对象和小对象的一个块的缓存空间,里面有各种不同等级的span 18 mcache *mcache 19 // 一个chunk大小(512kb)的内存空间,用来对堆上内存分配的缓存优化达到无锁访问的目的 20 pcache pageCache 21 raceprocctx uintptr 22 23 deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go) 24 deferpoolbuf [5][32]*_defer 25 26 // Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen. 27 // 可以分配给g的id的缓存,每次会一次性申请16个 28 goidcache uint64 29 goidcacheend uint64 30 31 // Queue of runnable goroutines. Accessed without lock. 32 // 本地可运行的G队列的头部和尾部,达到无锁访问 33 runqhead uint32 34 runqtail uint32 35 // 本地可运行的g队列,是一个使用数组实现的循环队列 36 runq [256]guintptr 37 // 下一个待运行的g,这个g的优先级最高 38 // 如果当前g运行完后还有剩余可用时间,那么就应该运行这个runnext的g 39 runnext guintptr 40 41 // Available G's (status == Gdead) 42 // p上的空闲队列列表 43 gFree struct { 44 gList 45 n int32 46 } 47 48 ............ 49 // 用于内存对齐 50 _ uint32 // Alignment for atomic fields below 51 ....................... 52 // 是否被抢占 53 preempt bool 54 55 // Padding is no longer needed. False sharing is now not a worry because p is large enough 56 // that its size class is an integer multiple of the cache line size (for any of our architectures). 57 }通过这里的结构可以看出,虽然P叫做逻辑处理器Processor,实际上它更多是资源的管理者,其中包含了可运行的g队列资源、内存分配的资源、以及对调度循环、系统调用、sysmon协程的相关记录。通过P的资源管理来尽量实现无锁访问,提升应用性能。 3.2.2 P的状态 当程序刚开始运行进行初始化时,所有的P都处于_Pgcstop状态,随着的P的初始化(runtime.procresize),会被设置为_Pidle状态。 当M需要运行时会调用runtime.acquirep来使P变为_Prunning状态,并通过runtime.releasep来释放,重新变为_Pidele。 当G执行时需要进入系统调用,P会被设置为_Psyscall,如果这个时候被系统监控抢夺(runtime.retake),则P会被重新修改为_Pidle。 如果在程序中发生GC,则P会被设置为_Pgcstop,并在runtime.startTheWorld时重新调整为_Prunning。
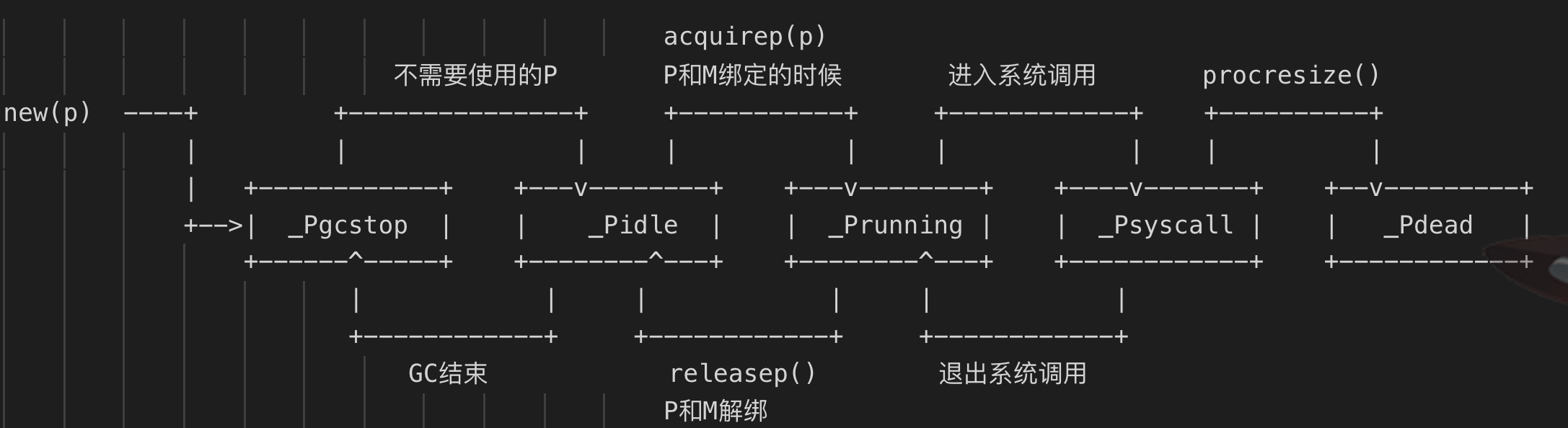 (这部分文字来自《Go程序员面试宝典》,图片来自这里)
3.2.3 P的创建
P的初始化是在schedinit函数中调用的,schedinit函数是在runtime的汇编启动代码里调用的。
(这部分文字来自《Go程序员面试宝典》,图片来自这里)
3.2.3 P的创建
P的初始化是在schedinit函数中调用的,schedinit函数是在runtime的汇编启动代码里调用的。
1 ........................... 2 CALL runtime·args(SB) 3 CALL runtime·osinit(SB) 4 CALL runtime·schedinit(SB) 5 ...........................shcedinit中通过调用procresize进行P的分配。P的个数默认等于CPU核数,如果设置了GOMAXPROCS环境变量,则会采用设置的值来确定P的个数。所以runtime.GOMAXPROCS是限制的并行线程数量,而不是系统线程即M的总数,M是按需创建。
1 func schedinit() { 2 ................. 3 lock(&sched.lock) 4 sched.lastpoll = uint64(nanotime()) 5 procs := ncpu 6 if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 { 7 procs = n 8 } 9 if procresize(procs) != nil { 10 throw("unknown runnable goroutine during bootstrap") 11 } 12 unlock(&sched.lock) 13 14 // World is effectively started now, as P's can run. 15 worldStarted() 16 ..................... 17 }上面获取ncpu的个数,然后传递给procresize函数。 无论是初始化时的分配,还是后期调整,都是通过procresize来创建p以及初始化
1 func procresize(nprocs int32) *p { 2 ............................. 3 old := gomaxprocs 4 ...................... 5 if nprocs > int32(len(allp)) { 6 // Synchronize with retake, which could be running 7 // concurrently since it doesn't run on a P. 8 lock(&allpLock) 9 if nprocs <= int32(cap(allp)) { 10 // 如果需要的p小于allp这个全局变量(切片)的cap能力,取其中的一部分 11 allp = allp[:nprocs] 12 } else { 13 // 否则创建nprocs数量的p,并把allp的中复制给nallp 14 nallp := make([]*p, nprocs) 15 // Copy everything up to allp's cap so we 16 // never lose old allocated Ps. 17 copy(nallp, allp[:cap(allp)]) 18 allp = nallp 19 } 20 .................................... 21 unlock(&allpLock) 22 } 23 24 // 进行p的初始化 25 for i := old; i < nprocs; i++ { 26 pp := allp[i] 27 if pp == nil { 28 pp = new(p) 29 } 30 pp.init(i) 31 atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp)) 32 } 33 ............................... 34 return runnablePs 35 }在启动时候会根据CPU核数和runtime.GOMAXPROCS来设置p的个数,并由一个叫做allp的切片来为主,后期可以通过设置GOMAXPROCS来调整P的个数,但是性能消耗很大,会进行STW; 3.3 M源码部分 3.3.1 M的结构 M即Machine,代表一个进程中的工作线程,结构体m保存了M自身使用的栈信息、当前正在M上执行的G,以及绑定M的P信息等。 我们来看下m的结构体:
1 type m struct { 2 // 每个m都有一个对应的g0线程,用来执行调度代码, 3 // 当需要执行用户代码的时候,g0会与用户goroutine发生协程栈切换 4 g0 *g // goroutine with scheduling stack 5 morebuf gobuf // gobuf arg to morestack 6 ........................ 7 // tls作为线程的本地存储 8 // 其中可以在任意时刻获取绑定到当前线程上的协程g、结构体m、逻辑处理器p、特殊协程g0等信息 9 tls [tlsSlots]uintptr // thread-local storage (for x86 extern register) 10 mstartfn func() 11 // 指向正在运行的goroutine对象 12 curg *g // current running goroutine 13 caughtsig guintptr // goroutine running during fatal signal 14 // 与当前工作线程绑定的p 15 p puintptr // attached p for executing go code (nil if not executing go code) 16 nextp puintptr 17 oldp puintptr // the p that was attached before executing a syscall 18 id int64 19 mallocing int32 20 throwing int32 21 // 与禁止抢占相关的字段,如果该字段不等于空字符串,要保持curg一直在这个m上运行 22 preemptoff string // if != "", keep curg running on this m 23 // locks也是判断g能否被抢占的一个标识 24 locks int32 25 dying int32 26 profilehz int32 27 // spining为true标识当前m正在处于自己找工作的自旋状态, 28 // 首先检查全局队列看是否有工作,然后检查network poller,尝试执行GC任务 29 //或者偷一部分工作,如果都没有则会进入休眠状态 30 spinning bool // m is out of work and is actively looking for work 31 // 表示m正阻塞在note上 32 blocked bool // m is blocked on a note 33 ......................... 34 doesPark bool // non-P running threads: sysmon and newmHandoff never use .park 35 // 没有goroutine需要运行时,工作线程睡眠在这个park成员上 36 park note 37 // 记录所有工作线程的一个链表 38 alllink *m // on allm 39 schedlink muintptr 40 lockedg guintptr 41 createstack [32]uintptr // stack that created this thread. 42 ............................. 43 }3.3.2 M的状态 M的状态并没有向P和G那样有多个状态常量,它只有自旋和非自旋两种状态
1 mstart 2 | 3 v 4 +------+ 找不到可执行任务 +-------+ 5 |unspin| ----------------------------> |spining| 6 | | <---------------------------- | | 7 +------+ 找到可执行任务 +-------+ 8 ^ | stopm 9 | wakep v 10 notewakeup <------------------------- notesleep当M没有工作时,它会自旋的来找工作,首先检查全局队列看是否有工作,然后检查network poller,尝试执行GC任务,或者偷一部分工作,如果都没有则会进入休眠状态。当被其他工作线程唤醒,又会进入自旋状态。 3.3.3 M的创建 runtime/proc.go中的newm函数用来新建m,而最终是根据不同的系统,通过系统调用来创建线程。
1 // newm创建一个新的m,将从fn或者调度程序开始执行 2 func newm(fn func(), _p_ *p, id int64) { 3 // 这里实现m的创建 4 mp := allocm(_p_, fn, id) 5 mp.doesPark = (_p_ != nil) 6 mp.nextp.set(_p_) 7 mp.sigmask = initSigmask 8 if gp := getg(); gp != nil && gp.m != nil && (gp.m.lockedExt != 0 || gp.m.incgo) && GOOS != "plan9" { 9 // 我们处于锁定的M或可能由C启动的线程。此线程的内核状态可能很奇怪(用户可能已将其锁定为此目的)。 10 // 我们不想将其克隆到另一个线程中。相反,请求一个已知良好的线程为我们创建线程。 11 lock(&newmHandoff.lock) 12 if newmHandoff.haveTemplateThread == 0 { 13 throw("on a locked thread with no template thread") 14 } 15 mp.schedlink = newmHandoff.newm 16 newmHandoff.newm.set(mp) 17 if newmHandoff.waiting { 18 newmHandoff.waiting = false 19 notewakeup(&newmHandoff.wake) 20 } 21 unlock(&newmHandoff.lock) 22 return 23 } 24 // 这里分配真正的的操作系统线程 25 newm1(mp) 26 }allocm函数中实现m的创建,以及对应的g0协程的设置
1 func allocm(_p_ *p, fn func(), id int64) *m { 2 // 获取当前运行的g 3 _g_ := getg() 4 // 将_g_对应的m的locks加1,防止被抢占 5 acquirem() // disable GC because it can be called from sysmon 6 if _g_.m.p == 0 { 7 acquirep(_p_) // temporarily borrow p for mallocs in this function 8 } 9 10 // 检查是有有空闲的m可以释放,主要目的是释放m上的g0占用的系统栈 11 if sched.freem != nil { 12 lock(&sched.lock) 13 var newList *m 14 for freem := sched.freem; freem != nil; { 15 if freem.freeWait != 0 { 16 next := freem.freelink 17 freem.freelink = newList 18 newList = freem 19 freem = next 20 continue 21 } 22 // stackfree must be on the system stack, but allocm is 23 // reachable off the system stack transitively from 24 // startm. 25 systemstack(func() { 26 stackfree(freem.g0.stack) 27 }) 28 freem = freem.freelink 29 } 30 sched.freem = newList 31 unlock(&sched.lock) 32 } 33 // 创建一个m结构体 34 mp := new(m) 35 mp.mstartfn = fn // 将fn设置为m启动后执行的函数 36 mcommoninit(mp, id) 37 38 // In case of cgo or Solaris or illumos or Darwin, pthread_create will make us a stack. 39 // Windows and Plan 9 will layout sched stack on OS stack. 40 if iscgo || mStackIsSystemAllocated() { 41 mp.g0 = malg(-1) 42 } else { 43 // 设置m对应的g0,并设置对应大小的g0协程栈,g0是8kb 44 mp.g0 = malg(8192 * sys.StackGuardMultiplier) 45 } 46 // 设置g0对应的m 47 mp.g0.m = mp 48 49 if _p_ == _g_.m.p.ptr() { 50 releasep() 51 } 52 // 解除_g_的m的禁止抢占状态。 53 releasem(_g_.m) 54 55 return mp 56 }为什么m.locks加1可以禁止抢占,防止GC;因为判断是否可以抢占,其中一个因素就是要m.locks=0
1 func canPreemptM(mp *m) bool { 2 return mp.locks == 0 && mp.mallocing == 0 && mp.preemptoff == "" && mp.p.ptr().status == _Prunning 3 }allocm函数实现了m的创建,但是这只是runtime层面的一个数据结构,还并没有在系统中有真正的线程。再来看newm1函数:
1 func newm1(mp *m) { 2 .............. 3 execLock.rlock() // Prevent process clone. 4 // 创建一个系统线程,并且传入该 mp 绑定的 g0 的栈顶指针 5 // 让系统线程执行 mstart 函数,后面的逻辑都在 mstart 函数中 6 newosproc(mp) 7 execLock.runlock() 8 }实际是通过newostproc来创建系统线程;
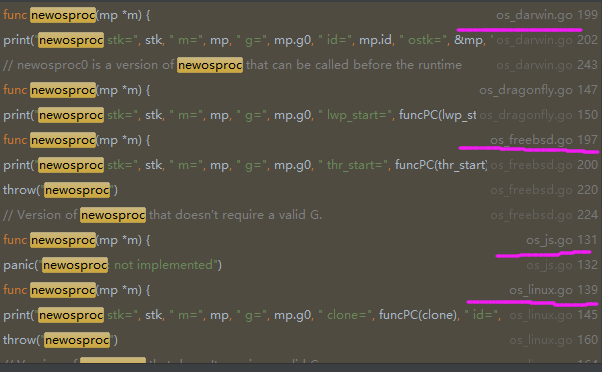 可以看到这个函数在不同的系统中有不同的实现,我们主要看linux系统,即os_linux.go文件代码:
可以看到这个函数在不同的系统中有不同的实现,我们主要看linux系统,即os_linux.go文件代码:
1 func newosproc(mp *m) { 2 stk := unsafe.Pointer(mp.g0.stack.hi) 3 ......................... 4 var oset sigset 5 sigprocmask(_SIG_SETMASK, &sigset_all, &oset) 6 ret := clone(cloneFlags, stk, unsafe.Pointer(mp), unsafe.Pointer(mp.g0), unsafe.Pointer(funcPC(mstart))) 7 sigprocmask(_SIG_SETMASK, &oset, nil) 8 ......................... 9 }在linux平台,是通过clone这个系统调用来创建的线程;值得注意的是,这个系统线程的栈是在堆上;因为其中的stk指向mp.go.stack.hi,所以g0的堆栈也就是这个系统线程的堆栈。 3.3.4 M的休眠 M的自旋指的是m.spining为true,这个时候它会在P的本地G队列、全局G队列、nerpoller、偷其他P的G,一直循环找可运行的G的过程中。 自旋状态用 m.spinning 和 sched.nmspinning 表示。其中 m.spinning 表示当前的M是否为自旋状态,sched.nmspinning 表示runtime中一共有多少个M在自旋状态。 当自旋了一段时间后,发现仍然找不到工作,就会进入stopm函数中,使M对应的线程进行休眠。
1 func stopm() { 2 _g_ := getg() 3 ..................... 4 lock(&sched.lock) 5 // 首先将m放到全局空闲链表中,这里要加锁访问全局链表 6 mput(_g_.m) 7 unlock(&sched.lock) 8 // 进入睡眠状态 9 mPark() 10 // 将m与p解绑 11 acquirep(_g_.m.nextp.ptr()) 12 _g_.m.nextp = 0 13 } 14 15 func mPark() { 16 g := getg() 17 for { 18 // 使工作线程休眠在park字段上 19 notesleep(&g.m.park) 20 noteclear(&g.m.park) 21 if !mDoFixup() { 22 return 23 } 24 } 25 }实际将线程进行休眠的代码,是通过汇编语言进行Futex系统调用来事项的。Futex机制是Linux提供的一种用户态和内核态混合的同步机制。Linux底层也是使用futex机制实现的锁。
1 //uaddr指向一个地址,val代表这个地址期待的值,当*uaddr==val时,才会进行wait 2 int futex_wait(int *uaddr, int val); 3 //唤醒n个在uaddr指向的锁变量上挂起等待的进程 4 int futex_wake(int *uaddr, int n);可以看到在futex_wait中当一个地址等于某个期待值时,就会进行wait;所以当m中的park的key等于某个值时则进入休眠状态。 3.3.5 M的唤醒 M的唤醒是在wakep函数中处理的。当一个新的goroutine创建或者有多个goroutine进入_Grunnable状态时,会先判断是否有自旋的M,如果有则不会唤醒其他的M而使用自旋的M,当没有自旋的M,但m空闲队列中有空闲的M则会唤醒M,否则会创建一个新的M
1 // Tries to add one more P to execute G's. 2 // Called when a G is made runnable (newproc, ready). 3 func wakep() { 4 if atomic.Load(&sched.npidle) == 0 { 5 return 6 } 7 // be conservative about spinning threads 8 // 如果有其他的M处于自旋状态,那么就不管了,直接返回,因为自旋的M会拼命找G来运行的 9 if atomic.Load(&sched.nmspinning) != 0 || !atomic.Cas(&sched.nmspinning, 0, 1) { 10 return 11 } 12 startm(nil, true) 13 }startm先判断是否有空闲的P,如果没有则返回,如果有空闲的P,在尝试看看有没有空闲的M,有则唤醒该M来工作。如果没有空闲M,则新建一个M,然后也进入唤醒操作。
1 func startm(_p_ *p, spinning bool) { 2 // 禁止抢占,防止GC垃圾回收 3 mp := acquirem() 4 lock(&sched.lock) 5 // 如果P为nil,则尝试获取一个空闲P 6 if _p_ == nil { 7 _p_ = pidleget() 8 if _p_ == nil { // 没有空闲的P,则解除禁止抢占,直接返回 9 unlock(&sched.lock) 10 if spinning { 11 if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 { 12 throw("startm: negative nmspinning") 13 } 14 } 15 releasem(mp) 16 return 17 } 18 } 19 // 获取一个空闲的M 20 nmp := mget() 21 if nmp == nil { 22 // 如果没有空闲的m则新建一个 23 id := mReserveID() 24 unlock(&sched.lock) 25 26 var fn func() 27 if spinning { 28 // The caller incremented nmspinning, so set m.spinning in the new M. 29 fn = mspinning 30 } 31 newm(fn, _p_, id) 32 // Ownership transfer of _p_ committed by start in newm. 33 // Preemption is now safe. 34 releasem(mp) 35 return 36 } 37 unlock(&sched.lock) 38 ...................... 39 //标记该M是否在自旋 40 nmp.spinning = spinning 41 // 暂存P 42 nmp.nextp.set(_p_) 43 // 唤醒M 44 notewakeup(&nmp.park) 45 // Ownership transfer of _p_ committed by wakeup. Preemption is now 46 // safe. 47 releasem(mp) 48 }唤醒线程的底层操作同样是依赖futex机制
1 //唤醒n个在uaddr指向的锁变量上挂起等待的进程 2 int futex_wake(int *uaddr, int n);4 启动过程 4.1 Go scheduler结构 在runtime中全局变量sched代表全局调度器,数据结构为schedt结构体,保存了调度器的状态信息、全局可运行G队列
1 type schedt struct { 2 // 用来为goroutine生成唯一id,需要以原子访问形式进行访问 3 // 放在struct顶部,以便在32位系统上可以进行对齐 4 goidgen uint64 5 ................... 6 lock mutex 7 // 空闲的m组成的链表 8 midle muintptr // idle m's waiting for work 9 // 空闲的工作线程数量 10 nmidle int32 // number of idle m's waiting for work 11 // 空闲的且被lock的m的数量 12 nmidlelocked int32 // number of locked m's waiting for work 13 mnext int64 // number of m's that have been created and next M ID 14 // 表示最多能够创建的工作线程数量 15 maxmcount int32 // maximum number of m's allowed (or die) 16 nmsys int32 // number of system m's not counted for deadlock 17 nmfreed int64 // cumulative number of freed m's 18 // 整个goroutine的数量,能够自动保持更新 19 ngsys uint32 // number of system goroutines; updated atomically 20 // 由空闲的p结构体对象组成的链表 21 pidle puintptr // idle p's 22 // 空闲的p结构体对象的数量 23 npidle uint32 24 // 自旋的m的数量 25 nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go. 26 27 // Global runnable queue. 28 // 全局的的g的队列 29 runq gQueue 30 runqsize int32 31 32 disable struct { 33 // user disables scheduling of user goroutines. 34 user bool 35 runnable gQueue // pending runnable Gs 36 n int32 // length of runnable 37 } 38 39 // Global cache of dead G's. 40 // 空闲的g队列,这里面g的状态为_Gdead 41 gFree struct { 42 lock mutex 43 stack gList // Gs with stacks 44 noStack gList // Gs without stacks 45 n int32 46 } 47 ................. 48 // 空闲的m队列 49 freem *m 50 ..................... 51 // 上次修改gomaxprocs的时间 52 procresizetime int64 // nanotime() of last change to gomaxprocs 53 ...................... 54 }这里面大部分是记录一些空闲的g、m、p等,在runtime2.go中还有很多相关的全局变量:
1 // runtime/runtime2.go 2 var ( 3 // 保存所有的m 4 allm *m 5 // p的最大个数,默认等于cpu核数 6 gomaxprocs int32 7 // cpu的核数,程序启动时会调用osinit获取ncpu值 8 ncpu int32 9 // 调度器结构体对象,记录了调度器的工作状态 10 sched schedt 11 newprocs int32 12 13 allpLock mutex 14 // 全局的p队列 15 allp []*p 16 ) 17 18 // runtime/proc.go 19 var ( 20 // 代表进程主线程的m0对象 21 m0 m 22 // m0的g0 23 g0 g 24 // 全局的mcache对象,管理各种类型的span队列 25 mcache0 *mcache 26 raceprocctx0 uintptr 27 )4.2 启动流程 调度器的初始化和启动调度循环是在进程初始化是处理的,整个进程初始化流程如下:
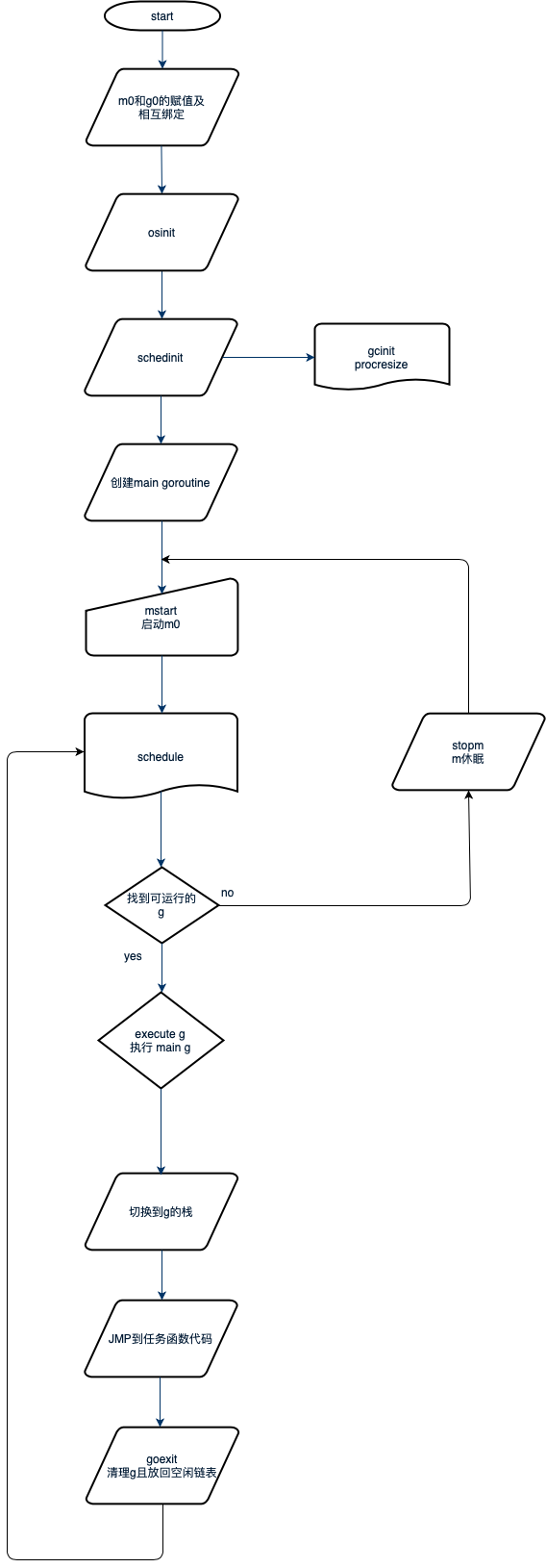 Go 进程的启动是通过汇编代码进行的,入口函数在asm_amd64.s这个文件中的runtime.rt0_go部分代码;
Go 进程的启动是通过汇编代码进行的,入口函数在asm_amd64.s这个文件中的runtime.rt0_go部分代码;
1 // runtime·rt0_go 2 3 // 程序刚启动的时候必定有一个线程启动(主线程) 4 // 将当前的栈和资源保存在g0 5 // 将该线程保存在m0 6 // tls: Thread Local Storage 7 // set the per-goroutine and per-mach "registers" 8 get_tls(BX) 9 LEAQ runtime·g0(SB), CX 10 MOVQ CX, g(BX) 11 LEAQ runtime·m0(SB), AX 12 13 // m0和g0互相绑定 14 // save m->g0 = g0 15 MOVQ CX, m_g0(AX) 16 // save m0 to g0->m 17 MOVQ AX, g_m(CX) 18 // 处理args 19 CALL runtime·args(SB) 20 // os初始化, os_linux.go 21 CALL runtime·osinit(SB) 22 // 调度系统初始化, proc.go 23 CALL runtime·schedinit(SB) 24 25 // 创建一个goroutine,然后开启执行程序 26 // create a new goroutine to start program 27 MOVQ $runtime·mainPC(SB), AX // entry 28 PUSHQ AX 29 PUSHQ $0 // arg size 30 CALL runtime·newproc(SB) 31 POPQ AX 32 POPQ AX 33 34 // start this M 35 // 启动线程,并且启动调度系统 36 CALL runtime·mstart(SB)可以看到通过汇编代码: 1、将m0与g0互相绑定,然后调用runtime.osinit函数,这个函数不同的操作系统有不同的实现; 2、然后调用runtime.schedinit进行调度系统的初始化; 3、然后创建主协程;主goroutine创建完成后被加入到p的运行队列中,等待调度; 4、在g0上启动调用runtime.mstart启动调度循环,首先可以被调度执行的就是主goroutine,然后主协程获得运行的cpu则执行runtime.main进而执行到用户代码的main函数。 初始化过程和堆栈图可以参考下图:
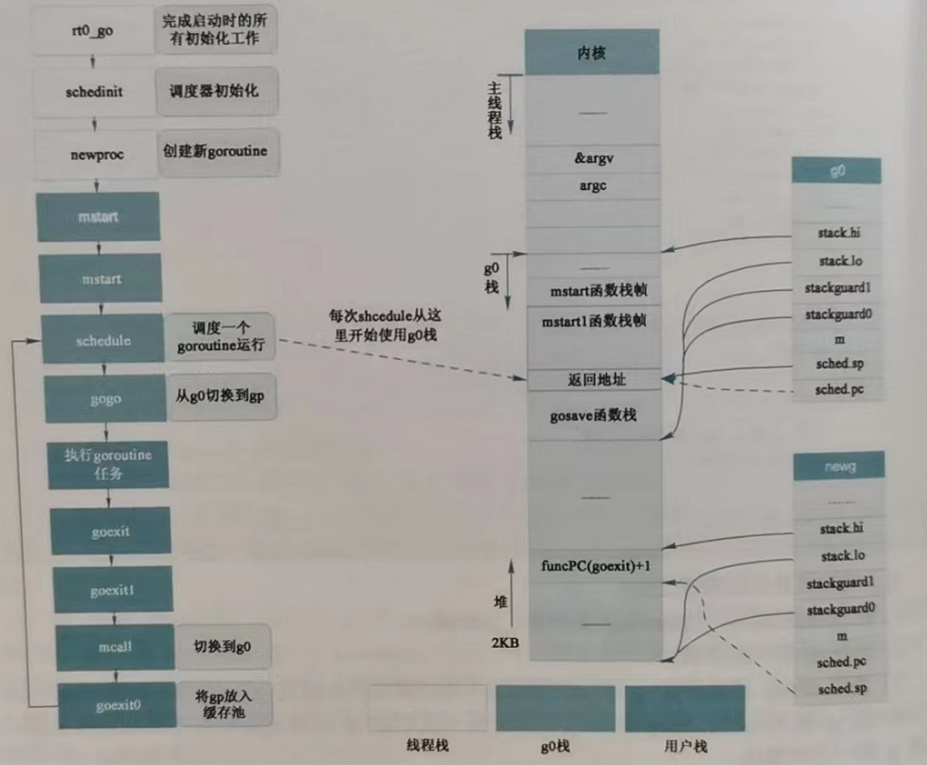 堆栈上,g0、m0、p0与主协程关系如图所示:
堆栈上,g0、m0、p0与主协程关系如图所示:
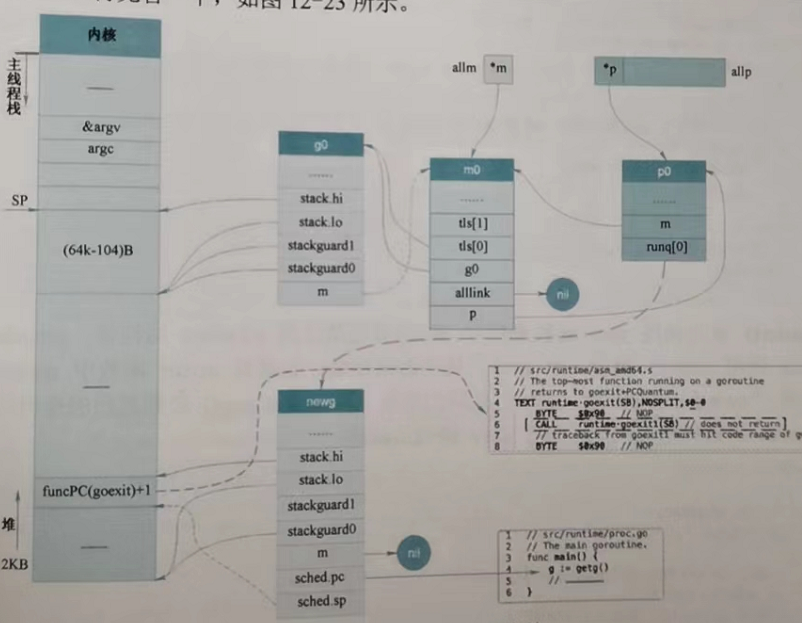 4.3 调度器初始化
调度器初始化
4.3 调度器初始化
调度器初始化
1 func schedinit() { 2 ................ 3 // g0 4 _g_ := getg() 5 if raceenabled { 6 _g_.racectx, raceprocctx0 = raceinit() 7 } 8 // 最多启动10000个工作线程 9 sched.maxmcount = 10000 10 11 // The world starts stopped. 12 worldStopped() 13 14 moduledataverify() 15 // 初始化协程堆栈,包括专门分配小栈的stackpool和分配大栈的stackLarge 16 stackinit() 17 // 整个堆内存的初始化分配 18 mallocinit() 19 fastrandinit() // must run before mcommoninit 20 // 初始化m0 21 mcommoninit(_g_.m, -1) 22 cpuinit() // must run before alginit 23 alginit() // maps must not be used before this call 24 modulesinit() // provides activeModules 25 typelinksinit() // uses maps, activeModules 26 itabsinit() // uses activeModules 27 28 sigsave(&_g_.m.sigmask) 29 initSigmask = _g_.m.sigmask 30 31 if offset := unsafe.Offsetof(sched.timeToRun); offset%8 != 0 { 32 println(offset) 33 throw("sched.timeToRun not aligned to 8 bytes") 34 } 35 36 goargs() 37 goenvs() 38 parsedebugvars() 39 gcinit() 40 // 这部分是初始化p, 41 // cpu有多少个核数就初始化多少个p 42 lock(&sched.lock) 43 sched.lastpoll = uint64(nanotime()) 44 procs := ncpu 45 if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 { 46 procs = n 47 } 48 if procresize(procs) != nil { 49 throw("unknown runnable goroutine during bootstrap") 50 } 51 unlock(&sched.lock) 52 53 // World is effectively started now, as P's can run. 54 worldStarted() 55 }4.4 启动调度系统 调度系统时在runtime.mstart0函数中启动的。这个函数是在m0的g0上执行的。
1 func mstart0() { 2 // 这里获取的是g0在系统栈上执行 3 _g_ := getg() 4 ............. 5 mstart1() 6 ............. 7 } 8 9 func mstart1(dummy int32) { 10 _g_ := getg() 11 // 确保g是系统栈上的g0 12 // 调度器只在g0上执行 13 if _g_ != _g_.m.g0 { 14 throw("bad runtime·mstart") 15 } 16 ... 17 // 初始化m,主要是设置线程的备用信号堆栈和信号掩码 18 minit() 19 // 如果当前g的m是初始m0,执行mstartm0() 20 if _g_.m == &m0 { 21 // 对于初始m,需要一些特殊处理,主要是设置系统信号量的处理函数 22 mstartm0() 23 } 24 // 如果有m的起始任务函数,则执行,比如 sysmon 函数 25 // 对于m0来说,是没有 mstartfn 的 26 if fn := _g_.m.mstartfn; fn != nil { 27 fn() 28 } 29 if _g_.m.helpgc != 0 { 30 _g_.m.helpgc = 0 31 stopm() 32 } else if _g_.m != &m0 { // 如果不是m0,需要绑定p 33 // 绑定p 34 acquirep(_g_.m.nextp.ptr()) 35 _g_.m.nextp = 0 36 } 37 // 进入调度循环,永不返回 38 schedule() 39 }4.5 runtime.main函数 当经过初始的调度,主协程获取执行权后,首先进入的就是runtime.main函数:
1 // The main goroutine. 2 func main() { 3 // 获取 main goroutine 4 g := getg() 5 ... 6 // 在系统栈上运行 sysmon 7 systemstack(func() { 8 // 分配一个新的m,运行sysmon系统后台监控 9 // (定期垃圾回收和调度抢占) 10 newm(sysmon, nil) 11 }) 12 ... 13 // 确保是主线程 14 if g.m != &m0 { 15 throw("runtime.main not on m0") 16 } 17 // runtime 内部 init 函数的执行,编译器动态生成的。 18 runtime_init() // must be before defer 19 ... 20 // gc 启动一个goroutine进行gc清扫 21 gcenable() 22 ... 23 // 执行init函数,编译器动态生成的, 24 // 包括用户定义的所有的init函数。 25 // make an indirect call, 26 // as the linker doesn't know the address of 27 // the main package when laying down the runtime 28 fn := main_init 29 fn() 30 ... 31 // 真正的执行main func in package main 32 // make an indirect call, 33 // as the linker doesn't know the address of 34 // the main package when laying down the runtime 35 fn = main_main 36 fn() 37 ... 38 // 退出程序 39 exit(0) 40 // 为何这里还需要for循环? 41 // 下面的for循环一定会导致程序崩掉,这样就确保了程序一定会退出 42 for { 43 var x *int32 44 *x = 0 45 } 46 }runtime.main函数中需要注意的是在系统栈上创建了一个新的m,来执行sysmon协程,这个协程是用来定期执行垃圾回收和调度抢占。 其中可以看到首先获取了main_init函数,来执行runtime包中的init函数,然后是获取main_main来执行用户的main函数。 接着main函数执行完成后,调用exit让主进程退出,如果进程没有退出,就让for循环一直访问非法地址,让操作系统把进程杀死,这样来确保进程一定会退出。 5 协程的调度策略 调度循环启动之后,便会进入一个无限循环中,不断的执行schedule->execute->gogo->goroutine任务->goexit->goexit1->mcall->goexit0->schedule; 其中调度的过程是在m的g0上执行的,而goroutine任务->goexit->goexit1->mcall则是在goroutine的堆栈空间上执行的。 5.1 调度策略 其中schedule函数处理具体的调度策略;execute函数执行一些具体的状态转移、协程g与结构体m之间的绑定;gogo函数是与操作系统相关的函数,执行汇编代码完成栈的切换以及CPU寄存器的恢复。 先来看下schedule的代码:
1 func schedule() { 2 _g_ := getg() 3 ... 4 top: 5 // 如果当前GC需要停止整个世界(STW), 则调用gcstopm休眠当前的M 6 if sched.gcwaiting != 0 { 7 // 为了STW,停止当前的M 8 gcstopm() 9 // STW结束后回到 top 10 goto top 11 } 12 ... 13 var gp *g 14 var inheritTime bool 15 ... 16 if gp == nil { 17 // 为了防止全局队列中的g永远得不到运行,所以go语言让p每执行61调度, 18 // 就需要优先从全局队列中获取一个G到当前P中,并执行下一个要执行的G 19 if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 { 20 lock(&sched.lock) 21 gp = globrunqget(_g_.m.p.ptr(), 1) 22 unlock(&sched.lock) 23 } 24 } 25 if gp == nil { 26 // 从p的本地队列中获取 27 gp, inheritTime = runqget(_g_.m.p.ptr()) 28 if gp != nil && _g_.m.spinning { 29 throw("schedule: spinning with local work") 30 } 31 } 32 if gp == nil { 33 // 想尽办法找到可运行的G,找不到就不用返回了 34 gp, inheritTime = findrunnable() // blocks until work is available 35 } 36 ... 37 // println("execute goroutine", gp.goid) 38 // 找到了g,那就执行g上的任务函数 39 execute(gp, inheritTime) 40 }findrunnalbe中首先还是从本地队列中检查,然后从全局队列中寻找,再从就绪的网络协程,如果这几个没有就去其他p的本地队列偷一些任务。
1 func findrunnable() (gp *g, inheritTime bool) { 2 _g_ := getg() 3 4 top: 5 ............................ 6 // 本地队列中检查 7 if gp, inheritTime := runqget(_p_); gp != nil { 8 return gp, inheritTime 9 } 10 // 从全局队列中寻找 11 if sched.runqsize != 0 { 12 lock(&sched.lock) 13 gp := globrunqget(_p_, 0) 14 unlock(&sched.lock) 15 if gp != nil { 16 return gp, false 17 } 18 } 19 // 从就绪的网络协程中查找 20 if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 { 21 if list := netpoll(0); !list.empty() { // non-blocking 22 gp := list.pop() 23 injectglist(&list) 24 casgstatus(gp, _Gwaiting, _Grunnable) 25 if trace.enabled { 26 traceGoUnpark(gp, 0) 27 } 28 return gp, false 29 } 30 } 31 32 // 进入自旋状态 33 procs := uint32(gomaxprocs) 34 if _g_.m.spinning || 2*atomic.Load(&sched.nmspinning) < procs-atomic.Load(&sched.npidle) { 35 if !_g_.m.spinning { 36 _g_.m.spinning = true 37 atomic.Xadd(&sched.nmspinning, 1) 38 } 39 // 从其他p的本地队列中偷工作 40 gp, inheritTime, tnow, w, newWork := stealWork(now) 41 .............................. 42 } 43 }整个调度的优先级如下:
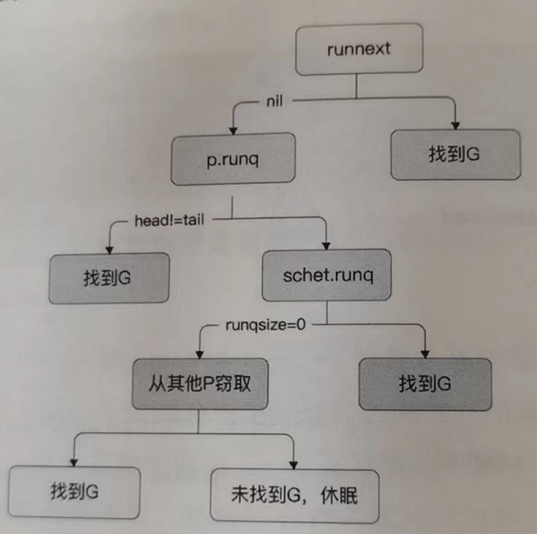 5.2 调度时机
5.1讲了调度的策略,什么时机发生调度呢,主要有三种方式,主动调度、被动调度、抢占式调度。
5.2.1 主动调度
协程可以选择主动让渡自己的执行权利,大多数情况下不需要这么做,但通过runtime.Goched可以做到主动让渡。
5.2 调度时机
5.1讲了调度的策略,什么时机发生调度呢,主要有三种方式,主动调度、被动调度、抢占式调度。
5.2.1 主动调度
协程可以选择主动让渡自己的执行权利,大多数情况下不需要这么做,但通过runtime.Goched可以做到主动让渡。
1 func Gosched() { 2 checkTimeouts() 3 mcall(gosched_m) 4 } 5 6 // Gosched continuation on g0. 7 func gosched_m(gp *g) { 8 if trace.enabled { 9 traceGoSched() 10 } 11 goschedImpl(gp) 12 } 13 14 func goschedImpl(gp *g) { 15 status := readgstatus(gp) 16 if status&^_Gscan != _Grunning { 17 dumpgstatus(gp) 18 throw("bad g status") 19 } 20 // 更改g的运行状态 21 casgstatus(gp, _Grunning, _Grunnable) 22 // 接触g和m的绑定关系 23 dropg() 24 // 将g放入全局队列中 25 lock(&sched.lock) 26 globrunqput(gp) 27 unlock(&sched.lock) 28 29 schedule() 30 }5.2.2 被动调度 大部分情况下的调度都是被动调度,当协程在休眠、channel通道阻塞、网络IO阻塞、执行垃圾回收时会暂停,被动调度可以保证最大化利用CPU资源。被动调度是协程发起的操作,所以调度时机相对明确。 首先从当前栈切换到g0协程,被动调度不会将G放入全局运行队列,所以被动调度需要一个额外的唤醒机制。 这里面涉及的函数主要是gopark和ready函数。 gopark函数用来完成被动调度,有_Grunning变为_Gwaiting状态;
1 func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) { 2 if reason != waitReasonSleep { 3 checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy 4 } 5 // 禁止抢占和GC 6 mp := acquirem() 7 gp := mp.curg // 过去当前m上运行的g 8 status := readgstatus(gp) 9 if status != _Grunning && status != _Gscanrunning { 10 throw("gopark: bad g status") 11 } 12 // 设置相关的wait字段 13 mp.waitlock = lock 14 mp.waitunlockf = unlockf 15 gp.waitreason = reason 16 mp.waittraceev = traceEv 17 mp.waittraceskip = traceskip 18 releasem(mp) 19 // can't do anything that might move the G between Ms here. 20 mcall(park_m) 21 } 22 23 // park continuation on g0. 24 func park_m(gp *g) { 25 _g_ := getg() 26 // 变更g的状态 27 casgstatus(gp, _Grunning, _Gwaiting) 28 // 接触g与m的绑定关系 29 dropg() 30 // 根据被动调度不同原因,执行不同的waitunlockf函数 31 if fn := _g_.m.waitunlockf; fn != nil { 32 ok := fn(gp, _g_.m.waitlock) 33 _g_.m.waitunlockf = nil 34 _g_.m.waitlock = nil 35 if !ok { 36 if trace.enabled { 37 traceGoUnpark(gp, 2) 38 } 39 casgstatus(gp, _Gwaiting, _Grunnable) 40 execute(gp, true) // Schedule it back, never returns. 41 } 42 } 43 // 进入下一轮调度 44 schedule() 45 }当协程要被唤醒时,会进入ready函数中,更改协程状态由_Gwaiting变更为_Grunnable,放入本地运行队列等待被调度。
1 func ready(gp *g, traceskip int, next bool) { 2 .............. 3 status := readgstatus(gp) 4 5 // Mark runnable. 6 _g_ := getg() 7 mp := acquirem() // disable preemption because it can be holding p in a local var 8 ............... 9 // 变更状态之后,放入p的局部运行队列中 10 casgstatus(gp, _Gwaiting, _Grunnable) 11 runqput(_g_.m.p.ptr(), gp, next) 12 wakep() 13 releasem(mp) 14 }5.2.3 抢占式调度 如果一个g运行时间过长就会导致其他g难以获取运行机会,当进行系统调用时也存在会导致其他g无法运行情况;当出现这两种情况时,为了让其他g有运行机会,则会进行抢占式调度。 是否进行抢占式调度主要是在sysmon协程上判断的。sysmon协程是一个不需要p的协程,它作用主要是运行后台监控,进行netpool(获取fd事件)、retake(抢占式调度)、forcegc(按时间强制执行GC)、scavenge heap(强制释放闲置堆内存,减少内存占用) 其中与抢占式调度相关的就是retake函数, 这里我们需要知道的是连续运行10ms则认为时间过长,进行抢占 发生系统调用时,当前正在工作的线程会陷入等待状态,等待内部完成系统调用并返回,所以也需要让渡执行权给其他g,但这里当只有满足几种情况才会进行调度: 1、如果p的运行队列中有等待运行的g则抢占 2、如果没有空闲的p则进行抢占 3、系统调用时间超过10ms则进行抢占
1 func retake(now int64) uint32 { 2 n := 0 3 lock(&allpLock) 4 // 遍历所有的P 5 for i := 0; i < len(allp); i++ { 6 _p_ := allp[i] 7 if _p_ == nil { 8 // This can happen if procresize has grown 9 // allp but not yet created new Ps. 10 continue 11 } 12 pd := &_p_.sysmontick 13 s := _p_.status 14 sysretake := false 15 16 if s == _Prunning || s == _Psyscall { 17 // 判断如果g的运行时间过长则抢占 18 t := int64(_p_.schedtick) 19 if int64(pd.schedtick) != t { 20 pd.schedtick = uint32(t) 21 pd.schedwhen = now 22 } else if pd.schedwhen+forcePreemptNS <= now { 23 // 如果连续运行10ms则进行抢占 24 preemptone(_p_) 25 sysretake = true 26 } 27 } 28 // 针对系统调用情况进行抢占 29 // 如果p的运行队列中有等待运行的g则抢占 30 // 如果没有空闲的p则进行抢占 31 // 系统调用时间超过10ms则进行抢占 32 if s == _Psyscall { 33 // Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us). 34 t := int64(_p_.syscalltick) 35 if !sysretake && int64(pd.syscalltick) != t { 36 pd.syscalltick = uint32(t) 37 pd.syscallwhen = now 38 continue 39 } 40 // On the one hand we don't want to retake Ps if there is no other work to do, 41 // but on the other hand we want to retake them eventually 42 // because they can prevent the sysmon thread from deep sleep. 43 if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now { 44 continue 45 } 46 // Drop allpLock so we can take sched.lock. 47 unlock(&allpLock) 48 // Need to decrement number of idle locked M's 49 // (pretending that one more is running) before the CAS. 50 // Otherwise the M from which we retake can exit the syscall, 51 // increment nmidle and report deadlock. 52 incidlelocked(-1) 53 if atomic.Cas(&_p_.status, s, _Pidle) { 54 if trace.enabled { 55 traceGoSysBlock(_p_) 56 traceProcStop(_p_) 57 } 58 n++ 59 _p_.syscalltick++ 60 handoffp(_p_) 61 } 62 incidlelocked(1) 63 lock(&allpLock) 64 } 65 } 66 unlock(&allpLock) 67 return uint32(n) 68 }在进行抢占式调度,Go还涉及到利用操作系统信号方式来进行抢占,这里就不在介绍,感兴趣可以自己去研究。 另外,本文图片没有一张原创,画图非常耗费时间,我没有那么多时间,所以只能到处借用大家的图片,侵权请联系。 6 参考资料
- Go语言的调度模型:https://www.cnblogs.com/lvpengbo/p/13973906.html
- 深度揭秘Go语言 sync.Pool:https://www.cnblogs.com/qcrao-2018/p/12736031.html
- https://toutiao.io/posts/2gic8x/preview
- 万字长文深入浅出go runtime:https://zhuanlan.zhihu.com/p/95056679
- 深入go runtime的调度:https://zboya.github.io/post/go_scheduler/
- 字节Go面试:https://leetcode-cn.com/circle/discuss/A0YstA/
- golang调度学习-调度过程:https://blog.csdn.net/diaosssss/article/details/93066804
- Go调度器中的三种结构:G、P、M:https://blog.csdn.net/chenxun_2010/article/details/103696394
- Go语言的调度模型:https://www.cnblogs.com/lvpengbo/p/13973906.html
- Go GMP的调度模型:https://zhuanlan.zhihu.com/p/413970952
- 详细剖析Go语言调度模型的设计:https://www.elecfans.com/d/1670400.html
- Go的核心goroutine sysmon:https://blog.csdn.net/RA681t58CJxsgCkJ31/article/details/108633220
- 一文教你搞懂Go中栈操作:https://zhuanlan.zhihu.com/p/364813527
- 详解Go语言调度循环代码实现:https://www.luozhiyun.com/archives/448
- goroutine的创建、休眠与恢复:https://zhuanlan.zhihu.com/p/386595432
您可以考虑给树发个小额微信红包以资鼓励
