前言
‘红学会’研究红楼梦,是因为红楼梦的内容本身具有研究意义。
对于金庸的武侠小说,其内容本身并无太大研究意义——知道何人会何武功显然并不重要。
但是,金庸的小说具有一个性质,是其他绝大多数小说所不具有的,那就是金庸的每本小说前后经历过两次大的修改。这在小说界,乃至文学界都具有特殊意义——金庸做了那些修改?为什么要这么修改?修改的效果如何?修改文学原因何在?时代、局势原因何在?这是值得研究的。
早在此之前,已经有很多金庸小说爱好者,乃至一些颇有名气的文学家都曾经研究过这个问题。但是他们的研究方式都是通读三个版本,然后在头脑中对比、分析。这种研究方法显然是可行且有效的。 但是,金庸小说十五本,短者几十万字,长者逾百万,总字数更是远超千万。如此庞大的数据规模,若能佐以计算机的算力,想必能够得到一些比大脑对比更精准、更全面的结果。
于是我便开始思考能否使用一些计算机方法来研究这一问题。
目录
1、爬虫部分(性能在爬取网址更新前应该比较稳定,但写的很菜,连bs和re都不会用的蒟蒻属于是)
2、数据处理部分
2.1 相似度
2.2 最长公共子序列
2.3 优化——分治
2.3.1 如何分
2.3.2 失灵与处理
3、成果
part1 爬虫部分
想要分析小说,首先需要获得全套金庸小说,因为后期的分析需要本地的小说的格式配合,所以选择自己爬取。
注意到几个能够下载金庸数据的网址,下载速度快的数据不全,数据全的下载慢,所以使用多网址结合下载,网址为:
http://www.jinyongwuxia.cc/
http://www.jinyongshuwu.com/
http://www.jinyongwuxia.com/
第一个爬的快,第三个数据全,第二个的源代码排版和第一个差不多。三个网址的反爬都很弱,至多一个headers就能搞定(你管这叫反爬?逃)。
在从网页源代码里提取出了小说正文,我在每一章的章节名前面加了一个‘\t \t’字符,作为章节分割标志。
这部分没什么难度,代码贴在后面一起。
part2 数据处理部分
接下来是数据处理部分。从大学生完成大作业的角度出发,这一部分可以写的功能有很多,关键词搜索呀、词频呀、云图呀 ...... All kinds of these things.这些内容大多基于已经形成的理论,或是直接调用现成的库。爱找事儿的我却希望能够通过我学过的知识,对一个问题提出一些可行的解决方法。
很快我就确定了一个问题,并将其作为了我这次大作业的主要卖点——相似度对比。
2.1 相似度
对于两本完全不同的小说,相似度对比并没有什么意义(除非一方被告侵犯知识产权要查重),但是对于一本小说的几个修改版,它的意义不彰自明——作者修改力度的重要指标。
但是第一问题来了,如何刻画两本小说的相似度?角度有很多,例如情节重合度、人物形象相似度、写作手法、具体部分的详略等等。也很难说哪种角度更重要。我选择的刻画指标是最长公共子序列(Longest Common Sequence,缩写LCS),它是编辑距离的一种,也是我认为能够比较好地刻画“相似度”的一种指标。因为我们可以将相似度简单地定量地定义为:
相似度=(2*相同的部分) / 总共的部分
而对于两串字符串,其中的“相同的”那一部分,拿LCS来表示显然再好不过了。
这样我们也可以规定我们的程序用以计算两串字符串的相似度的公式为:
similarity(str1,str2) = 2*LCS(str1,str2) /( len(str1)+len(str2) )
2.2 最长公共子序列
众所周知,小说都是字符串,而任何两串字符串我们都可以找到它们的最长公共子序列(这是高中信息竞赛的经典问题)。经典的(应该也是最快的 就我所知)求LCS的算法来自动态规划,时间和空间复杂度都是O(n*m),n、m为两串字符串各自的长度。因为我们的研究对象是一本小说的两个版本,其长度显然不会相差太大,所以不妨都看成N,于是时空复杂度简单表示为O(N*N)。然后我在洛谷与CSDN上找了一下有关求动态规划求LCS算法优化的方法,参考:
1、P1439 【模板】最长公共子序列 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
2、 动态规划解最长公共子序列(LCS)(附详细填表过程)_z-k的博客-CSDN博客_最长公共子序列
3、最长公共子序列_百度百科 (baidu.com) (百科大法好)
我简单总结一下我看到的内容。
对于平凡的字符串(即没有什么特殊性质),该算法时间上没找到什么优化的方法,而空间可以通过滚动数组从O(N*N)优化为O(N)。
对于各元素出现次数不超过一次的字符串,一种方法是通过将求LCS的问题转化为求最大上升(单调)子序列(LIS),然后使用树状数组或是线段树动态维护已有最大值信息并完成logn的单点修改和区间查询,最终将时间复杂度优化为O(NlogN)。(这也就是我A掉洛谷P1439的方法)
显然,小说不符合第二优化的条件——5000常用字却组成了几百万字的小说,显然元素不会只出现一次。所以求LCS只能用最朴素的动态规划,顶多加个滚动数组优化一下空间,时间还是O(N*N)。
假设一本小说长度就为100万字,还不算标点,那么对这本小说的两个版本跑一遍LCS大概需要106*106即1012次运算。折合成python秒大约C*105秒,更直观地——60个小说左右,还只是一本小说的对比时间!Pure disaster...
这个问题让我致郁了很长时间(思而不学则殆啊),直到我的舍友的大作业遇到了类似的问题......
(对了,到这里已经基本确定大作业里求LCS的算法使用的是最朴素的动态规划了,随便哪里都能找到代码,就把我的代码贴一贴,不解释了,尚不懂的可先移步我上面贴的LCS讲解网址,如果是和我同上python课程的同学前来拜访而不想了解动态规划也没关系,只用知道有这么一种方法,能把你喂给他的两个字符串的最长公共子序列的长度告诉你,但要消耗n*n的运行时间就行了)
def LCS(a:str,b:str)->int: if len(a)<len(b): a,b=b,a f=[0 for i in range(len(b)+1)] ans=0 for i in range(1,len(a)+1): for j in range(len(b),0,-1): if a[i-1]==b[j-1]: f[j]=max(f[:j])+1 ans=max(ans,f[j]) return ans
2.3 优化——分治
书接上回,话说我的舍友在其python大作业中也遇到了问题,他的问题是这样的:
给你n个对象,这些对象有的具有相同的种类,有的不然,希望你判断有多少种类,每个种类包含多少个对象。大部分人可能现在都想到了并查集,我当时也是如此,但不同的是,并没有一组现成的is_same_class关系来让我们进行并类。
相反,在他的问题中,你有一个函数,这个函数可以以一定的时间为代价,告诉你你扔给它的两个对象是否是同类(具有相同的种类),你可以任意选择n个对象中的两个对象来询问这个函数。
这是一个时间很依赖测试点的问题,如果这n个对象两两线性无关不同类(想歪了,但插一嘴,线性无关和同不同类还是不一样的,A、B、C两两不同类,那肯定有3类,但是A、B、C两两线性无关它们的秩可不一定为3,很显然的结论却又很容易错),那么你必须通过n*n数量级的判断才能得出它们完全不同类的结论。而另一个极端是它们全部同类,那么你只需n-1次判断便可得出它们属于同一类这一结论。
我舍友数据规模中n达到了10万,而那个告诉他是否同类的函数需要的时间复杂度也相当高,当时他拿3000个点试跑了一下,跑了五分钟,而十万的点所需要的时间更是平方扩大。我当时就问他,能不能把10万个点分成几个3000,然后分别跑之,再将每个3000跑出来的种类组中每种取一个对象组成新的组并再跑一边,进一步地,可以不按3000来分,而按照一个更合适的k,而且也不用只分一次,新形成的组还可以再分,这样是不是可以大幅优化呢?
我的舍友听完深然其说,而这也给我的大作业提供里解决思路——分而治之,逐个击破。
优化的核心是:有一个函数,能以O(n*n)得出关于长度为n的序列的一个你想要的答案。而我们有一个长度为N的序列,我们嫌它太长,N*N太慢,于是我们考虑将这长为N的序列切为k段,为了简单起见,假设这k段一样长(其实并非如此,而且某一个太长的子段会带来严重的后果,详见2.3.1失灵与处理),那么,该函数处理任意一段所花费的时间为O((N*N)/(k*k)),处理所有k个字符串的时间就为O((N*N)/k),当k较大时,这优化效果将会是非常可观的。
注意这种优化方式并不是对所有的O(n*n)算法都可行,在这种优化下,我们得到的不是对整个长度为N的序列的我们想要的答案,而是对每个子段得出了我们想要的答案,这种优化有效的前提是,通过这些子段的答案,能够并且能够以更少的时间得出总序列的我们想要的答案。那么对于我们想要解决的问题——小说相似度对比,是否满足这一性质呢?答案是肯定的,解释请看下一部分——如何分。
2.3.1 如何分
之前我们指出,一本小说中仅设涉及5000常用字,却长达数百万字,显然同一个字重复着数矣。而且5000个字中大约2000个字占据了全部小说的大部分内容。平均下来,一个字大概出现了500遍。但是,如果我们随机从一本小说中取两个字,我们会发现它们的平均重复次数下降到了约10到20次,如果随机取3个字,这时平均重复次数降到了4次以下,当我们一次取一句话或是一段话时,除非是很特殊的句或段,我们是几乎无法在整本小说中找到第二个一样的句子或是段落的。
换言之,我们可以在非常小的反例出现概率下认为,小说对于句或者段落是单调的,小说中的一个句子在小说中具有一个独一无二的位置。(那些非常小概率的反例也会在2.3.2中考虑)
那么现在,如果我告诉你,A小说中的一个段落在B小说中出现过,并且A小说中该段落前后的部分和B小说该段落前后的部分对于的相似度我们已近知道了,那么,我们能够据此比较有把握地给出A和B小说的整体相似度吗?对于同一本小说的两个修改版本,完全可以。
这就是我们分治划分的依据——两版本中匹配的位置,我们在程序中通过match_pointl与match_pointr列表来储存这些位置。这是一种启发式的划分,因为划分的方法有很多种,我们也很难说谁更好,这取决于测试点。但是从结果上看,划分的越均匀的划分方式显然会更好,因为前面已经提到,某个分的过长的子序列会消耗大量的时间,且远大于由于该序列变长而使得其他序列变短所能缩短的时间。
接下来的问题就是如何找到足够多的match_point来使得k大到能够把100万*100万优化到一个可接受的范围内。想要找到一个match_point我们首先要找到一个match_range,这个match_range的首和尾就是两个match_point。对一个字符串,其最大的range显然就是它自己,对于一本书的两个版本,我们可以先从该书一个版本的字符串中选取一系列range(子列),然后在该书另一个版本的字符串查找是否存在一样的部分,如若存在,则记录match_point。
那么如何从一个版本的字符串中选择合适的match_range呢?这也是一种启发式选取。我们在前面提到过matchrange的不重复性可能会有少量失灵的情况,注意到match_range越长,失灵的可能性越小——如果版本一的一整章都可以在版本而中得到匹配,那么显然它的首位会构成严格的match_point,相反,如果match_range缩小为一个字,那么它失灵的概率将会非常得高。
此外,从时间复杂度上看,在一个字符串中使用find函数的时间复杂度也是线性的,其数量级也大约为O(n),当我们划分较多的match_range时,寻找所花费的时间会比较高。
因此,我们的原则是从大往小找,并且根据之前找到的match_range来缩小find的区间。具体实现如下:
首先,我们要以一定的数据结构来储存整本小说。鉴于python没有结构体这种数据类型,我们定义应该class来实现这一效果。在该class中,我们加工并填充如下变量:bookstr,储存整本小说,chapter_str[i],储存小说第i章,chapter_begin_index[i],储存小说第i章开始位置在bookstr中的下标,同理,paragraph_str[i][j],第i章第j段,sentence_str[i][j][k],第i章j段k句。具体代码如下。
class Book: def __init__(self, bookname:str,bookstr:str,edition:int):#传入小说名、小说字符串和版本号 self.name=bookname.replace('doc.','') self.edition=edition self.book_str=bookstr print('开始预处理',self.name,':') #开始划分并储存章节信息 print('正在划分小说第一层...') t1=time.time() chapter_str=bookstr.split('\t \t') self.chapter_str=[]#一维数组,记录每一章内容 self.chapter_begin_index=[]#一维数组,记录每一章开始下标(后面有用) index=0 for i in chapter_str: if i!='': self.chapter_str.append(i) index=self.book_str.find(i,index,len(bookstr)) self.chapter_begin_index.append(index) t2=time.time() print('第一层划分并储存完成,该层用时',t2-t1,'秒') #开始划分并储存段落信息 print('开始划分小说第二层...') t1=time.time() paragraph_str=[i.split('\n\t') for i in self.chapter_str] self.paragraph_str=[[] for i in self.chapter_str] for i in range(len(paragraph_str)):#过滤坏点 for j in range(len(paragraph_str[i])): if paragraph_str[i][j]!='': sign=0 for k in paragraph_str[i][j]: if ouf.IsChinese(k): sign=1 break if sign: self.paragraph_str[i].append(paragraph_str[i][j]) self.paragraph_begin_index=[[] for i in self.chapter_str] for i in range(len(self.paragraph_str)): index=self.chapter_begin_index[i] for j in self.paragraph_str[i]: index=self.book_str.find(j,max(0,index-1),len(bookstr)) self.paragraph_begin_index[i].append(index) t2=time.time() print('第二层划分并储存完成,该层用时',t2-t1,'秒') #开始分句子 print('开始处理第三层...') t1=time.time() sentence_str=[[j.split('。') for j in i] for i in self.paragraph_str]#三维数组,储存第i章第j段第k句 self.sentence_str=[[[] for j in i] for i in self.paragraph_str] for i in range(len(sentence_str)): for j in range(len(sentence_str[i])):#过滤坏点 for k in sentence_str[i][j]: for l in k: if ouf.IsChinese(l): self.sentence_str[i][j].append(k) break self.sentence_begin_index=[[[] for j in i] for i in self.paragraph_str] for i in range(len(self.sentence_str)): for j in range(len(self.sentence_str[i])): index=self.paragraph_begin_index[i][j] for k in self.sentence_str[i][j]: index=self.book_str.find(k,index,len(bookstr)) self.sentence_begin_index[i][j].append(index)#同样记录开始位置 t2=time.time() print('第三层划分并处理完成,该层用时',t2-t1,'秒') print('预处理完成!')
在完成小说预处理后,我们就已经将该小说按整本、章节、段落、句子四层分层储存,其中第 i 的相关信息层由i-1维数组记录。预处理的时空复杂度都是O(4*n)。
一本书的每一章、每一段、每一句都是天然的、从长到短的match_range,所以我们可以直接按照章、段、句的顺序进行比对。具体操作为:
如果一个match_range在两个版本中同时出现,那么我们将其在两个版本中各自出现的位置(头和尾)各自加到match_pointl与match_pointr的尾部。
这里有一个优化的技巧:利用到match_point的一个性质。match_pointl和match_pointr的意义是在两个版本的字符串上标记了一系列对应的点,如果我们每一层都新开一个对match_point,并按照从前往后选取match_range的方式,那么如果不出现失灵的情况,所有的每两个对应的点之间的连线应该是互不相交的。这就意味着,如果我在小说字符串A中有两个match_point:x1,x2,它们分别在字符串B中对应y1,y2,那么,如果存在x满足x1<x<x2,那么如果x可以在B中找到对应点y,那么一定有y1<y<y2。在刚刚的预处理的代码中,细心的同学可以发现我开了chapter、paragraph、sentence的begin_index数组,通过这三个数组,我们可以找到在我们目前使用的启发发下所确定的所有match_range的开始下标,记之index,然后我们在已经有的match_pointl中寻找第一个小于index的数的下标作为left,第一个大于index的数的下标作为right,根据前面的推断,index如果有对应的match_point,一定在match_point[left]和match_point[right]之间。然后,我们在第二个版本的小说字符串中试图寻找这个match_range时,就不用遍历整个字符串,而只用遍历match_point[left]和match_point[right]之间的部分,这大大优化了时间复杂度。同时,由于我们分层并从前往后比对,match_pointl一定是单调的,所以想要找到index的位置,我们可以使用二分查找实现log(n)级的查找而不必遍历一遍。二分查找的代码(这也是经典问题,在C++STL中有一个函数lower_bound就是这个功能):
def lower_bound(cur:int,a:list,x:int,y:int): if y<0: return -1 l=x r=y while(r-l): mid=(r+l)>>1 if a[mid]==cur: l=r=mid if a[mid]<cur: l=mid if a[mid]>cur: r=mid if r-l==1: if a[l]<cur: if a[r]<cur: return r return l else: return l-1 if a[l]<=cur: return l else: return l-1
下面是获取match_point的代码:
def find_dif(bookl,bookr,is_manual_op): match_pointl=[];s=0 match_pointr=[] book=[0 for i in range(len(bookl.book_str)+10)] chapter_unmatch_list=[] t1=time.time() for i in range(len(bookl.chapter_str)): #按章对比 l=ouf.lower_bound(bookl.chapter_begin_index[i],match_pointl,0,len(match_pointl)-1)#上面提到的优化之处,ouf是自己写模块,lowerbound上面已经贴出来了 r=l+1 if l==-1: l=0 else: l=match_pointr[l] if r==len(match_pointl): r=len(bookr.book_str) else: r=match_pointr[r] pos=bookr.book_str.find(bookl.chapter_str[i],l,r) if pos==-1: chapter_unmatch_list.append(i) else: for l in range(bookl.chapter_begin_index[i],bookl.chapter_begin_index[i]+len(bookl.chapter_str[i])): book[l]=1 s+=1 match_pointl.append(bookl.chapter_begin_index[i]) match_pointr.append(pos) match_pointl.append(bookl.chapter_begin_index[i]+len(bookl.chapter_str[i])) match_pointr.append(pos+len(bookl.chapter_str[i])) t2=time.time() print('第一层比对完成,该层用时',t2-t1,'秒') chapter_num = [str(i+1) for i in chapter_unmatch_list] chapter_num = list(map(eval, chapter_num)) for i in range(len(chapter_num)): chapter_num[i]-=1 chapter_num.sort() paragraph_unmatch_list=[[] for i in range(max(chapter_unmatch_list)+1)] t1 = time.time() for i in chapter_num: #按段对比 for j in range(len(bookl.paragraph_str[i])): l = ouf.lower_bound(bookl.paragraph_begin_index[i][j], match_pointl, 0, len(match_pointl) - 2) r = l + 1 if l == -1: l = 0 else: l = match_pointr[l] if r >= len(match_pointl)-1: r = len(bookr.book_str) else: r = match_pointr[r] pos = bookr.book_str.find(bookl.paragraph_str[i][j], l, r) if pos == -1: paragraph_unmatch_list[i].append(j) else: if (not len(match_pointr)) or pos>match_pointr[-1]: match_pointl.append(bookl.paragraph_begin_index[i][j]) match_pointr.append(pos) match_pointl.append(bookl.paragraph_begin_index[i][j] + len(bookl.paragraph_str[i][j])-1) match_pointr.append(pos + len(bookl.paragraph_str[i][j])-1) for l in range(bookl.paragraph_begin_index[i][j],bookl.paragraph_begin_index[i][j]+len(bookl.paragraph_str[i][j])): book[l]=1 s+=1 elif pos>match_pointr[-2]: match_pointl.pop() match_pointr.pop() match_pointr.pop() match_pointl.pop() t2 = time.time() print('第二层比对完成,该层用时', t2 - t1, '秒') new_match_pointl=[] #按句对比 new_match_pointr=[] sentence_unmatch_list=[[[] for j in i] for i in bookl.sentence_str]#j为在paragraph_unmatch_list中的下标,paragraph_unmatch_list中才存的是章号 for i in range(len(paragraph_unmatch_list)): if len(sentence_unmatch_list[i])<len(paragraph_unmatch_list[i]): print(i) t1=time.time() for i in chapter_num: for j in paragraph_unmatch_list[i]: for k in range(len(bookl.sentence_str[i][j])): l1=ouf.lower_bound(bookl.sentence_begin_index[i][j][k],match_pointl,0,len(match_pointl)-1) l2=-1 if l1>=l2: l=l1 r=l+1 if l == -1: l = 0 else: l = match_pointr[l] if r == len(match_pointl): r = len(bookr.book_str) else: r = match_pointr[r] else: l=l2 r=l+1 if l==-1: l=0 else: l=new_match_pointr[l] if r>=len(new_match_pointl)-1: r=len(bookr.book_str) else: r=new_match_pointr[r] pos = bookr.book_str.find(bookl.sentence_str[i][j][k], l, r) if pos == -1: sentence_unmatch_list[i][j].append(k) else: if (not len(new_match_pointr)) or pos > new_match_pointr[-1]: new_match_pointl.append(bookl.sentence_begin_index[i][j][k]) new_match_pointr.append(pos) new_match_pointl.append(bookl.sentence_begin_index[i][j][k] + len(bookl.sentence_str[i][j][k])) new_match_pointr.append(pos + len(bookl.sentence_str[i][j][k])) for l in range(bookl.sentence_begin_index[i][j][k],bookl.sentence_begin_index[i][j][k]+len(bookl.sentence_str[i][j][k])): book[l]=1 s+=1 elif pos > new_match_pointr[-2]: new_match_pointl.pop() new_match_pointr.pop() new_match_pointr.pop() new_match_pointl.pop() t2=time.time() print('第三层对比完成,该层用时',t2-t1,'秒') if is_manual_op: return match_pointl1=copy.deepcopy(match_pointl) #双有序列表合并,o(n),写的有点拖沓 match_pointr1=copy.deepcopy(match_pointr) match_pointl2=copy.deepcopy(new_match_pointl) match_pointr2=copy.deepcopy(new_match_pointr) del new_match_pointr del new_match_pointl match_pointl=[] match_pointr=[] top1=top2=0 while top1<len(match_pointl1) and top2<len(match_pointl2): if match_pointl1[top1]<match_pointl2[top2]: match_pointl.append(match_pointl1[top1]) match_pointr.append(match_pointr1[top1]) top1+=1 else: match_pointl.append(match_pointl2[top2]) match_pointr.append(match_pointr2[top2]) top2+=1 while top1<len(match_pointl1): match_pointl.append(match_pointl1[top1]) match_pointr.append(match_pointr1[top1]) top1 += 1 while top2<len(match_pointl2): match_pointl.append(match_pointl2[top2]) match_pointr.append(match_pointr2[top2]) top2 += 1 return match_pointl,match_pointr,book
在找到match_point后,剩下的内容就已经比较容易了,我们根据match_point来划分并进行对比。代码如下:
def get_match_degree(bookl,bookr): match_pointl,match_pointr,book=find_dif(bookl,bookr,0) s_all=s_match=r=0 singular_point=0 t_start=time.time() for i in range(len(match_pointl)): l=r r=match_pointl[i] sign=0 for j in range(l,r): if not book[j]: sign=1 break if sign: l2=0 if not i else match_pointr[i-1] r2=match_pointr[i] s_all+=r-l+r2-l2 t1=time.time() if r2-l2 and (r-l)/(r2-l2)<5 and (r-l and (r2-l2)/(r-l)<5): s_match+=ouf.LCS(bookl.book_str[l:r],bookr.book_str[l2:r2])<<1 t2=time.time() if (r-l)*(r2-l2)>500000: singular_point+=1 #这就是之前提到的分的太长划分子串 print(i,len(match_pointl)) t_ter=time.time() print('用时',t_ter-t_start,'秒') print('两版本相似度',(s_match/s_all)*100,'%') return (s_match/s_all),singular_point
这样我们就完成了分治部分,用这样的分治法,像射雕、天龙这样的长篇小说大约30到40秒可以完成对比,而比较短的小说数秒即可完成。
到这里我的大作业的核心思想已经介绍完毕了,下面从另一个角度来总结一下:
我们刚刚说到对于两串平凡的字符串,求其LCS时间复杂度无法优化。如果想要优化,字符串本身必须具有某些性质。而我们在生活中遇到的,或是有研究价值的字符串,大多会是内蕴一定规律的,洛谷P1439的“不重复出现”便是一种规律,并最终成就了它的nlogn优化。在本问题中,字符串的规律在于人类语言表达的多样性——可以看到,除非是直接引用,否则即便是长达几百万的字符串中也很难找到两串一样的、长度超过10字符的子串,这为我的分治提供了可能,并且最终被证明是成功的。并且,对于其它类型的字符串,这种性质很容易失灵,看来,上帝如果关上了一扇门,确实通常会打开一扇窗啊。
下面一节内容,是对前面提到的两种“失灵”的应对,主要是机械打表和面向特定对象的修改,若只是想阅读本文以了解主要想法的同学,至此足矣,可以直接跳到“3、成果”部分去查看成果展示。
2.3.2 失灵与处理
由于我使用了启发式划分,所以失灵是不可避免的。而在整个编写代码的过程中,失灵主要来两方面问题:一个版本中选取的match_range在另一个版本中有多处对应,以及即使经过match_point的划分,个别子串依然过长(我称这种子串为“跃点”,因为它一下跳了很长的距离,好笑的是,我在英语里找不到很好的对“跃点”的翻译(hop_point?有点怪),所以在代码里我名之“singular_point,形容它就像空间中的黑洞一样要消耗很长的时间”)。
对于第一个问题,我可以举个例子:试试在《射雕》中搜索‘郭靖点了点头’。你会发现,第一个版本第十几章的句子,在第二个版本第三十几章得到了匹配。结果显然是灾难性的,不仅多出了一个长达20万字的跃点,而且还让得出的相似度谬以千里。
解决方法很简单:能够一对多的“海王”match_range很少,所以我们只用会到下载的小说的文本中将其一个一个地“教其善良”即可。
对于第二个问题,当第一个问题得到解决后,那种长达十几二十万的跃点已经不复存在了,剩下的跃点有两种情况:1、金庸在某一个版本中加入或删除了一大段话。2、金庸在两个版本同一位置做了大量修改。
对于第一种情况,很简单,这种情况的一个特点就是两个版本划分出来的要扔进LCS函数的子串一个几万字,另一个几百字(这是因为这个问题是因为加入或删除了一大段话),那几百字的字符和几万字的字符能有什么相似度,跑一遍LCS确实能得到公共子序列——无非是‘的的的的你你你的的是是我的我我’这些超级常用字组成的序列。若是把这些序列纳入计算,非但不会加强准确度,反而会降低对相似度的衡量的准确性。所以,加个特判:
if r2-l2 and (r-l)/(r2-l2)<5 and (r-l and (r2-l2)/(r-l)<5): s_match+=ouf.LCS(bookl.book_str[l:r],bookr.book_str[l2:r2])<<1
只有在两对比子串长度差不超过五倍时,我们才会把他们丢进LCS函数。这样就避免了情况1。
对于情况二,它是能够通过上面的特判的,在这种情况下,我们也只能硬着头皮去跑一跑LCS了,因为字符串很长,直接忽略可能会导致结果的精确性大幅下降。好在情况二的跃点大都可以在一秒左右跑完,没有超过10秒的,所以零星几个无法避免的跃点对总时间的影响不大。
Part3 成果
成果包括各金庸小说修订版和新修版相似度图表以及数据,不同小说跃点统计(跃点用来指示金庸大幅修改之处)。以及每本小说每一章对应的相似度关系。
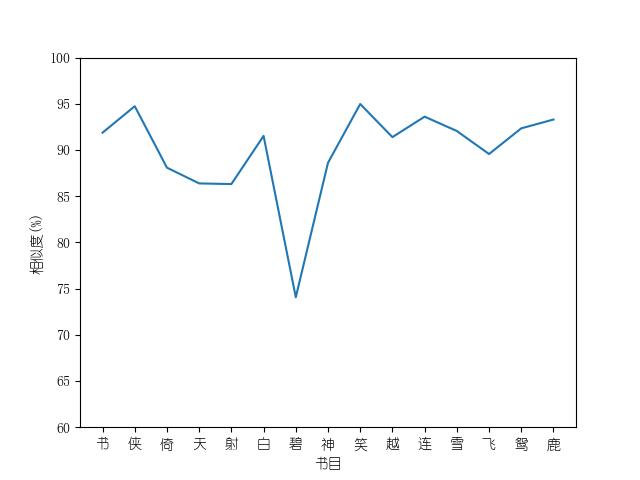
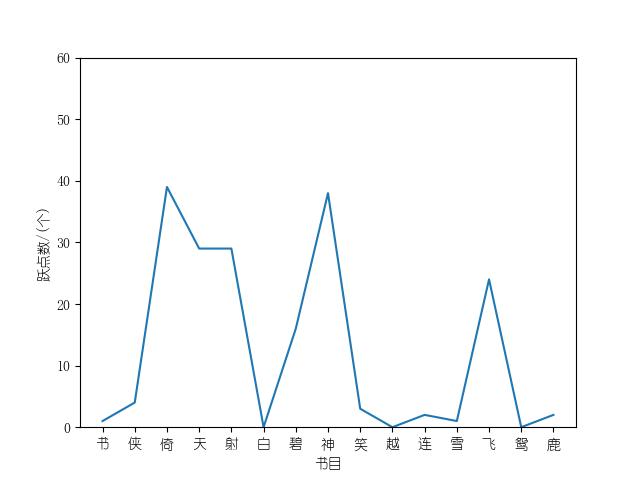
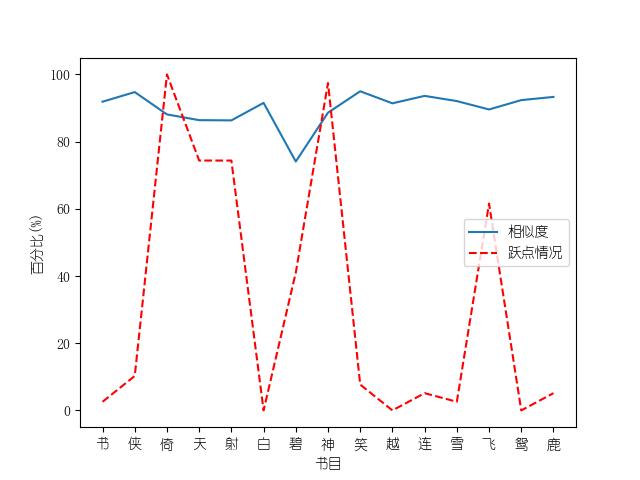
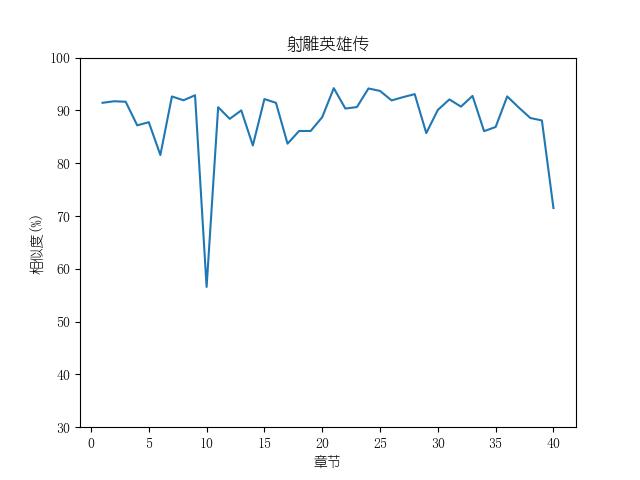
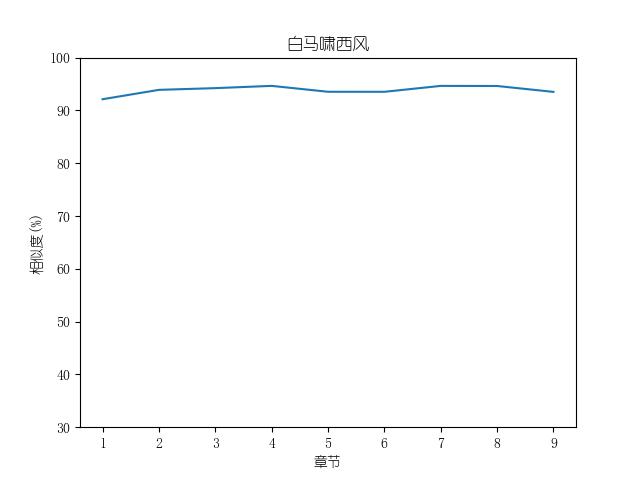
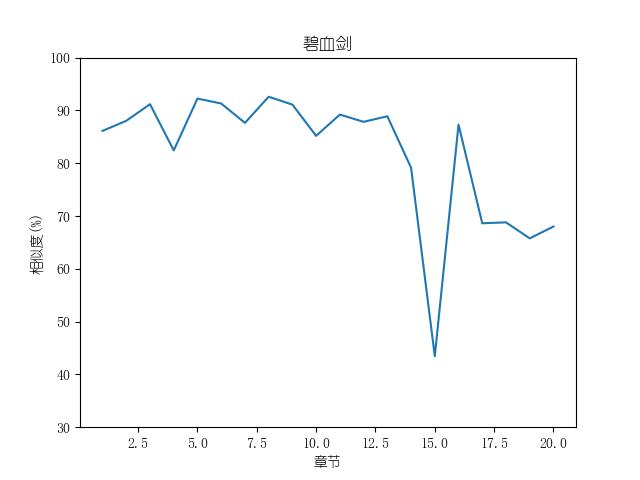
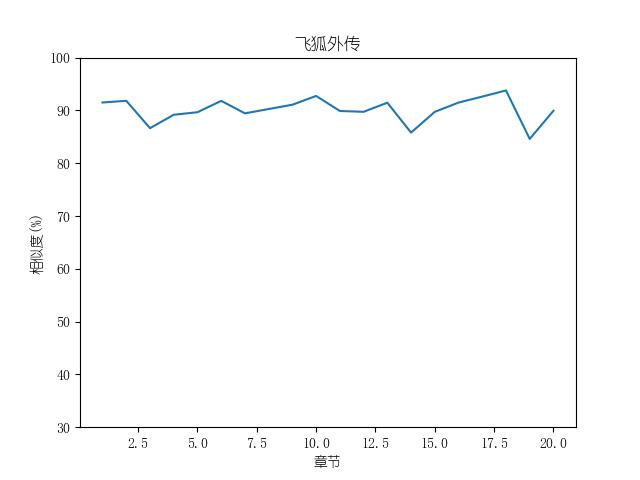
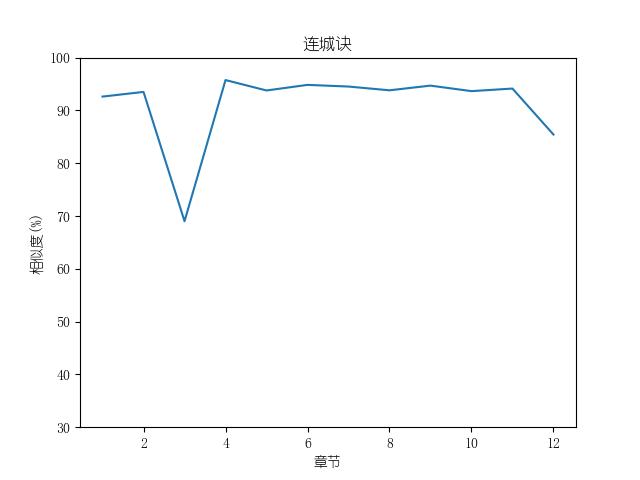
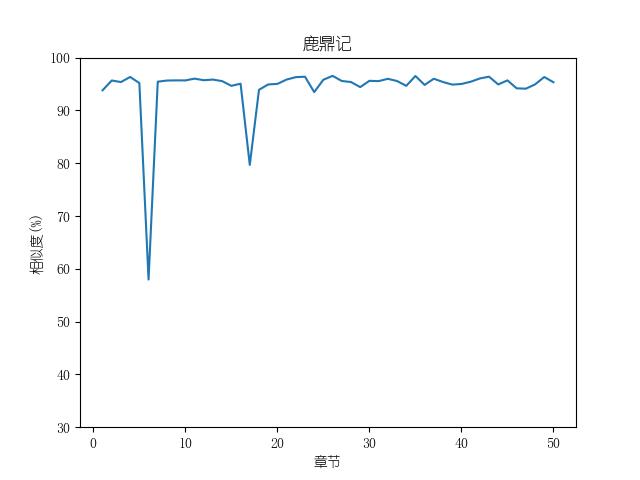
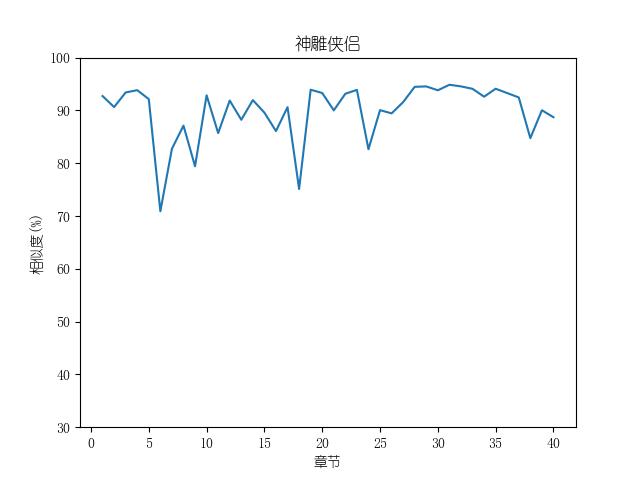
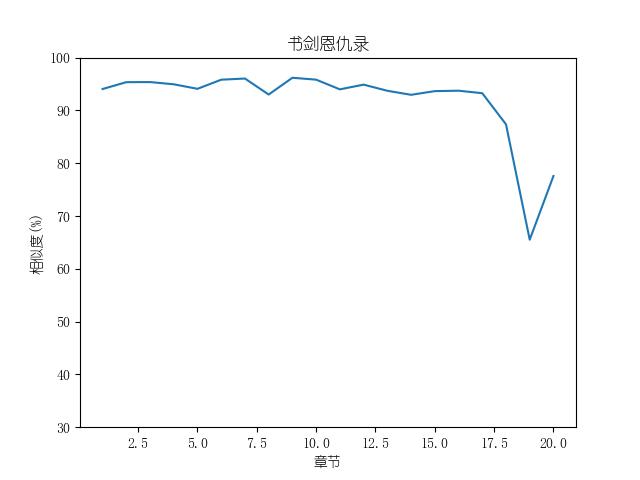
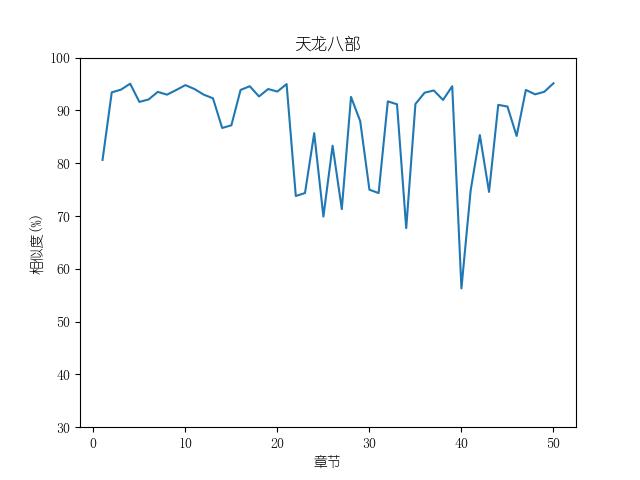
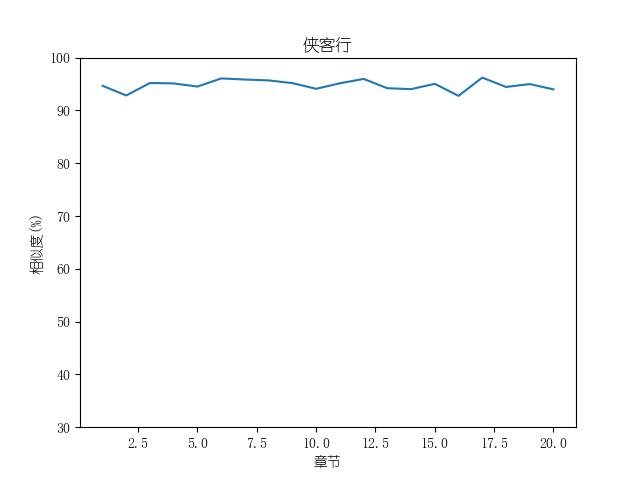
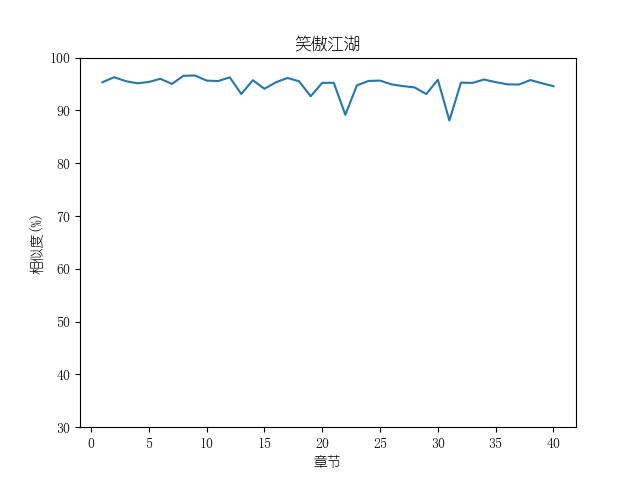
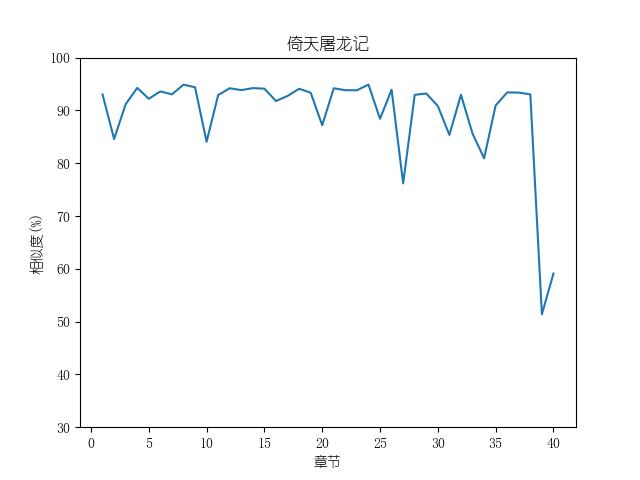
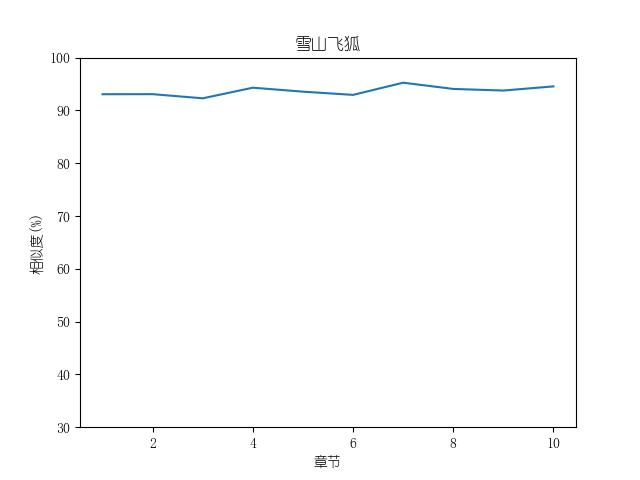
最后附全部代码:
模块1:main
import CrawlAndRefine as cr import OftenUsedFunctions as ouf import OpertionEdge as oe judge=ouf.JudgeValid sign=1 while sign: print('请输入您要爬取的网址:') url=input() print('加载中...') if judge.Is_Website(judge,url): oristr=cr.crif(url) print('网址爬取成功!') sign=0 else: print(url,'不是网址。') oe.basic_operation_choice(oristr,url) #http://www.jinyongshuwu.com/ #http://www.jinyongwuxia.cc/ #http://www.jinyongwuxia.com/
模块2:OpertionEdge:
import time #网络模块 import os import copy import CrawlAndRefine as cr #自建模块 import OftenUsedFunctions as ouf import GetInformation as gf def crawl_but_with_stable_insurance(url:str,ischapter:bool,name:str)->tuple:#为增强下载稳定性而编写的加强代码;对于金庸小说的爬取, # 有三样不稳定因素,在流水线的下载模式下会使得下载不完整 #它们分别是:urllib的不稳定性、单个金庸小说网址存在严重数据不全(表现为某些章节404了) #以及网络连接的不稳定性(这一点在大量、长时间的流水下载中更严重) #本函数不能避免这些不稳定性,但分别都做了一些缓解措施来尽量保证流畅和完整性, #措施为: # 1、单次urlopen失败后并不立刻认定为无效网址,而是重试来排出抽风问题 # 2、多源爬取,即并不是单独从一个网址爬取,当一个网址失效时,将会换源,共两个备用源 #措施虽然简单,但是考虑到不同网址的正文格式和网址结构不同、分页呈现,还有反爬的处理等因素,而我又是手写的re, #所以代码长度还是上来了 s=0 sign=1 while s <= 2 and sign: sign = 0 oristr = cr.crif(url) if 'com' in url and 'wuxia' in url and ischapter: url=list(url) url[-5:-5]='_2' url=''.join(url) neworistr=cr.crif(url) ct=0 while neworistr=='爬取失败4329840' and ct<3: print('准备重试...\n第',ct+1,'次尝试...') neworistr=cr.crif(url) ct+=1 pg=2 oristr=cr.get_passage(oristr,url) while not neworistr=='爬取失败4329840': oristr+=cr.get_passage(neworistr,url) pg+=1 url=url.replace('_'+str(pg-1),'_'+str(pg))#;print(url) neworistr=cr.crif(url) print('第二次换源成功奏效!\n刚才显示的网址进入失败是正常现象,请勿担心。') oristr=('<p>'+'\t \t'+name+oristr+'</p>').replace('真武侠迷一秒记住金庸武侠网址,<span style="color:#4876FF">www.jinyongwuxia.com</span>,为防被/转/码/无法阅读,请直接在浏览器中输入网址访问本站,你记住了吗?','').replace('<div class="m-post">','') if oristr == '爬取失败4329840': t = 1 s += 1 time.sleep(0.5) print('准备重试:') while oristr == '爬取失败4329840' and t < 3: t += 1 print('第', t, '次尝试...', sep='') oristr = cr.crif(url) if not oristr == '爬取失败4329840' and t < 3: print('重试成功!') else: print('重试失败!\n该网址数据丢失!') time.sleep(0.5) print('准备换源:','第',s,'个(共2个)备用源',sep='') if s==1: if 'com' in url: url = url.replace('com', 'cc').replace('html','htm').replace('shuwu','wuxia') sign = 1 elif 'cc' in url: if 'html' in url: url = url.replace('cc', 'com').replace('wuxia','shuwu') else: url=url.replace('cc','com').replace('wuxia','shuwu')+'l' sign = 1 if sign: print('换源成功!准备再次尝试...') else: print('换源失败!') elif s==2: url=url.replace('shuwu','wuxia').replace('cc','com') if 'html' not in url: url+='l' if ischapter: url=list(url) pos=-9 for i in range(len(url)): if url[i]=='/': pos=i+1 url[pos:]='index.html' url=''.join(url) oristr=cr.crif(url) chapter=cr.get_hyper_links(oristr,url) if not chapter==[]: name=name.replace(' ',' ').replace(' ',' ').replace(' ',' ').replace(' ',' ') for i in chapter: i[1]=i[1].replace(' ',' ').replace(' ',' ').replace(' ',' ') if name in i[1]: l=0 for j in range(len(i[0])): if i[0][j]=='/': l=j+1 url=url.replace('index.html',i[0][l:]) sign=1 else: print('换源失败!') url='' return oristr,url def download_chosen_list(book_list:list,url:str,edition:int): edit_list=['','','n','o']; #超链接网址格式化 for i in range(len(book_list)): book_list[i][0]=url+edit_list[edition]+book_list[i][0] name_list=['','修订版','新修版','旧版'] try: #先检查目标路径是否存在,若不存在则创建 os.mkdir('D:\\大学\\金庸小说') except: pass try: os.mkdir('D:\\大学\\金庸小说\\'+name_list[edition]) except: pass for i in book_list: #开始下载传入的书单 print('尝试下载',i[1]) oristr,i[0]=crawl_but_with_stable_insurance(i[0],0,i[1]) chapter_list=cr.get_chapter_links(oristr,i[0]) if edition==1 and '射雕英雄传' in i[1] or edition==1 and '雪山飞狐' in i[1]: chapter_list.reverse() for j in range(len(chapter_list)): chapter_list[j][0]=i[0].replace('index.html',chapter_list[j][0]).replace('index.htm',chapter_list[j][0]) if not chapter_list==[]: print('目录信息提取成功!') with open('D:\\大学\\金庸小说\\'+name_list[edition]+'\\'+i[1]+'.doc','wb') as fp:#保存小说的文件和路径 cha='目录:\n' for j in chapter_list: cha+=(j[1]+'\n') cha+='\n\n\n\n\n' fp.write(cha.encode()) for j in chapter_list: print('尝试下载',j[1]) oristr,j[0] = crawl_but_with_stable_insurance(j[0],1,j[1]) passage=cr.get_passage(oristr,j[0]) if passage=='': print(j[1]+'下载失败') passage+=(j[1]+'网页数据丢失') else: print(j[1], '下载成功!') fp.write(passage.encode()) def download_novels(oristr:str,url:str): link_list=cr.get_hyper_links(oristr,url) book_list=[[]] for i in range(len(link_list)): if ('小说' in link_list[i][1] and link_list[i+1][1]=='修订版'): book_list.append(link_list[i]) for i in range(1,len(book_list)): book_list[i][1]=book_list[i][1][:len(book_list[i][1])-2] book_list.append(['','全部小说']) print('请选择您想要下载的版本:\n1、修订版\n2、新修版\n3、旧版\n4、全部\n5、返回上一步') edition = '' while (not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid, edition)) or not 0 < eval(edition) <6: edition = input('请输入您的选择:\n') edition=eval(edition) if edition==5: basic_operation_choice(oristr,url) return 0 print('请选择您想要下载的书目:') time.sleep(0.3) for i in range(1,len(book_list)): print(i,'、',book_list[i][1],sep='') sign=1 while sign: book_num=input('请输入书目号(可多选,输入在一行,用空格隔开):\n').split() sign=0 for i in book_num: if not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid,i) or not 0<int(i)<17: print(i,'是不合法输入,请重试') sign=1 book_num=list(map(eval,book_num)) to_download_list=[] if 16 in book_num: to_download_list=book_list[1:len(book_list)-1] else: for i in book_num: if not book_list[i] in to_download_list: to_download_list.append(book_list[i]) if edition==4: for i in range(1,edition): substitude=copy.deepcopy(to_download_list)#列表方法List.copy()是伪复制,极不安全,使用deepcopy,这个UE我花了半个小说才调出来 download_chosen_list(substitude,url,i) else: download_chosen_list(to_download_list,url,edition) return 1 def get_and_downoad_selected_passage(passage_list:list,url:str,edition:int): name_list=['','金庸相关','角色点评','金书赏析','征文撷萃'] try: #先检查目标路径是否存在,若不存在则创建 os.mkdir('D:\\大学\\金庸小说') except: pass try: os.mkdir('D:\\大学\\金庸小说\\文章资讯') except: pass try: os.mkdir('D:\\大学\\金庸小说\\文章资讯\\'+name_list[edition]) except: pass for i in passage_list: print('尝试下载',i[1]) i[0]='http://www.jinyongwuxia.cc/news/'+i[0].replace('../','') oristr=cr.crif(i[0]) passage=cr.get_sub_passage(oristr,url) if passage!='': with open('D:\\大学\\金庸小说\\文章资讯\\' + name_list[edition] + '\\' + i[1] + '.doc', 'wb') as fp: fp.write(passage.encode()) print(i[1],'下载成功!') else: print(i[1],'下载失败') def download_jyw_passage(oristr:str,url:str): print('‘金庸网’有如下四种文章资讯:金庸相关 角色点评 金书赏析 征文撷萃') print('您有如下选择:\n1、金庸相关\n2、角色点评\n3、金书赏析\n4、征文撷萃\n5、返回上一步') edition = '' while (not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid, edition)) or not 0 < eval(edition) < 6: edition = input('请输入您的选择:\n') edition = eval(edition) if edition == 5: basic_operation_choice(oristr, url) return 0 urlist = ['', 'http://www.jinyongwuxia.cc/news/xinwen/index.htm', 'http://www.jinyongwuxia.cc/news/pingdian/index.htm', 'http://www.jinyongwuxia.cc/news/shangxi/index.htm', 'http://www.jinyongwuxia.cc/news/zhengwen/index.htm'] url=urlist[edition] oristr = cr.crif(url) all_hyper_links = cr.get_hyper_links(oristr,url) pg=2 url=list(url) url[-10:-10]='/2' url=''.join(url) oristr=cr.crif(url) all_hyper_links.extend(cr.get_hyper_links(oristr,url)) while oristr!='爬取失败4329840': url=url.replace(str(pg),str(pg+1)) pg+=1 oristr=cr.crif(url) s=1 while oristr=='爬取失败4329840' and s<3: print('重试中,第',s,'次...',sep='') oristr=cr.crif(url) s+=1 all_hyper_links.extend(cr.get_hyper_links(oristr,url)) if all_hyper_links!=[]: print('资讯源目录获取成功!\n刚才显示的“爬取失败”是正常现象,不必担心。') selected_hyper_links=[[]] for i in all_hyper_links: if (i[0][:3]=='../' or '../../' in i[0]) and i[0][-5:]=='.html' \ and i[1]!='' and not 'data' in i[0] and not i in selected_hyper_links: selected_hyper_links.append(i) print('访问到如下文章:') time.sleep(0.5) for i in range(1,len(selected_hyper_links)): print(i,'、',selected_hyper_links[i][1],sep='') sign = 1 while sign: book_num = input('请选择您想要下载的文章,按照序号选择,在一行输入,空格隔开。若要全部下载,请输入"all":\n').split() sign = 0 for i in book_num: if i=='all': book_num=[str(i) for i in range(1,len(selected_hyper_links))] break elif not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid, i) or not 0 < eval(i) < len(selected_hyper_links): print(i, '是不合法输入,请重试') sign = 1 book_num = list(map(eval, book_num)) to_download_list=[] for i in book_num: if selected_hyper_links[i] not in to_download_list: to_download_list.append(selected_hyper_links[i]) get_and_downoad_selected_passage(to_download_list,url,edition) return 1 def down_load_data(data_list:list,url:str,edition:int): name_list = ['', '人物', '武功', '门派'] try: # 先检查目标路径是否存在,若不存在则创建 os.mkdir('D:\\大学\\金庸小说') except: pass try: os.mkdir('D:\\大学\\金庸小说\\金庸网数据库') except: pass try: os.mkdir('D:\\大学\\金庸小说\\金庸网数据库\\' + name_list[edition]) except: pass def visit_data_base(oristr:str,url:str): oro=oristr;oru=url print('金庸网数据库有三类数据:人物数据、武功数据、门派数据') print('您有如下选择:\n1、访问人物数据\n2、访问武功数据\n3、访问门派数据\n4、返回上一步') edition = '' while (not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid, edition)) or not 0 < eval(edition) < 5: edition = input('请输入您的选择:\n') edition = eval(edition) if edition == 4: basic_operation_choice(oro, oru) return 0 urlist=['','http://www.jinyongwuxia.cc/data/renwu/index.htm', 'http://www.jinyongwuxia.cc/data/wugong/index.htm', 'http://www.jinyongwuxia.cc/data/menpai/index.htm'] url=urlist[edition] rurl='http://www.jinyongwuxia.cc/data/index.html' oristr=cr.crif(url) datalist=cr.get_hyper_links(oristr,url) selected_list=[[]] for i in datalist: sign=0;cur='' for j in i[0]: if '0'<=j<='9': cur+=j sign=1 if sign and len(cur)>1: selected_list.append([rurl.replace('index',cur),i[1]]) print('访问到如下数据:') for i in range(1,len(selected_list)): print(i,'、',selected_list[i][1],sep='',end=' ') print('选项可能有些多,现在为您提供三种操作:\n1、输入序号,访问序号对应的数据(一次可多选)\n2、输入您想要访问的数据名称(如“全真派”),我们将为您检索相关资料(一次可多选)\n3、返回') op = '' while (not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid, op)) or not 0 < eval(op) < 4: op = input('请输入您的选择:\n') op = eval(op) if op==3: basic_operation_choice(oro,oru) return 0 if op==1: sign=1 while sign: book_num = input('请选择您想要下载的文章,按照序号选择,在一行输入,空格隔开。若要全部下载,请输入"all":\n').split() sign = 0 for i in book_num: if i == 'all': book_num = [str(i) for i in range(1, len(selected_list))] break elif not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid, i) or not 0 < eval(i) < len(selected_list): print(i, '是不合法输入,请重试') sign = 1 book_num = list(map(eval, book_num)) to_download_list=[] for i in book_num: if selected_list[i] not in to_download_list: to_download_list.append(selected_list[i]) elif op==2: sign=1 to_download_list=[] while sign: print('请输入您要查询的关键词,若有多个关键词,请用空格隔开:') query_list=input().split() name_set={selected_list[i][1] for i in range(1,len(selected_list))} name_dic=dict({(selected_list[i][1],i) for i in range(1,len(selected_list))}) # print(name_set); print(name_dic) for i in query_list: for j in range(len(i)): for k in range(j+1,len(i)+1): #print(i,i[j:k],i[j:k] in name_set) if i[j:k] in name_set: to_download_list.append(selected_list[name_dic[i[j:k]]]) print('我们从您的输入中提取到了如下在库关键词:') for i in range(len(to_download_list)): print(i+1,'、',to_download_list[i][1]) down_load_data(to_download_list,url,edition) return 1 def analysis_entry(oristr:str,url:str): print('在进行小说分析之前,您需要先下载相应版本的小说到相应的位置。\n请检查是否下载。') #time.sleep(0.5) print('请回答是否下载(若未下载将返回上一步,可在该步选择下载):') if not ouf.ask_yes_no(): basic_operation_choice(oristr,url) return 0 print('目前支持如下几种分析模式:\n1、单版本多书分析\n2、多版本单书分析') mode = '' while (not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid, mode)) or not 0 < eval(mode) < 3: mode = input('请输入您的选择:\n') mode = eval(mode) mode_dic={1:gf.one_edition_multi_books,2:gf.multi_editions_one_book} mode_dic.get(mode)(oristr,url) return 1 def go_back(void1,void2): judge = ouf.JudgeValid print('请输入您要爬取的网址:') url = input() if judge.Is_Website(judge, url): oristr = cr.crif(url) print('网址爬取成功!') else: print(url, '不是网址。') a = cr.get_hyper_links(oristr, url) for i in a: print(i) basic_operation_choice(oristr, url) return 0 def show_or_visit_hyper_links(oristr:str,url:str): selected_hyper_links=[[]] selected_hyper_links+=cr.get_hyper_links(oristr,url) print('该网站有如下超链接:') for i in range(1,len(selected_hyper_links)): print(i,'、',selected_hyper_links[i][1],':',selected_hyper_links[i][0],sep='') sign = 1 while sign: book_num = input('请选择您想要访问的超链接,按照序号选择,在一行输入,空格隔开。若要全部访问,请输入"all":\n').split() sign = 0 for i in book_num: if i == 'all': book_num = [str(i) for i in range(1, len(selected_hyper_links))] break elif not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid, i) or not 0 < eval(i) < len(selected_hyper_links): print(i, '是不合法输入,请重试') sign = 1 book_num = list(map(eval, book_num)) for i in book_num: oristr=cr.crif(selected_hyper_links[i]) if oristr=='爬取失败4329840': oristr=cr.crif(url+selected_hyper_links[i]) basic_operation_choice(oristr,url+selected_hyper_links[i]) else: basic_operation_choice(oristr,selected_hyper_links[i]) def get_photos(oristr:str,url:str): print('该功能尚未开发') pass def get_videos(oristr:str,url:str): print('该功能尚未开发') pass def basic_operation_choice(oristr:str,url:str): print('您可以对该网页进行如下操作:') if url=='http://www.jinyongshuwu.com/' or url=='http://www.jinyongwuxia.cc/': print('1、下载小说\n2、下载相关文章资讯\n3、访问网站自带的金庸数据库\n4、使用本程序的数据分析功能分析金庸小说\n5、获得分析报告\n6、建立词库\n7、返回上一步') opdic={1:download_novels,2:download_jyw_passage,3:visit_data_base,4:analysis_entry,5:gf.get_report,6:gf.get_word_base,7:go_back} command='' while (not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid,command)) or not 0<eval(command)<7: command=input('请输入您的选择:\n') opdic.get(eval(command))(oristr,url) print('是否想要继续操作?') if ouf.ask_yes_no(): basic_operation_choice(oristr,url) else: print('1、获取或访问网页中的超链接\n2、爬取或下载网页正文\n3、下载网页中的图片\n4、下载网页中的视频\n5、返回上一步') opdic={1:show_or_visit_hyper_links,2:download_jyw_passage,3:get_photos,4:get_videos,5:go_back} command = '' while (not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid, command)) or not 0 < eval(command) < 6: command = input('请输入您的选择:\n') if opdic.get(eval(command))(oristr,url): print('是否想要继续操作?') if ouf.ask_yes_no(): basic_operation_choice()
模块3:CrawlAndRefine:
import urllib.request import OftenUsedFunctions as ouf def crif(url:str)->str: headers = {'User-Agent': 'Mozilla/5.0 3578.98 Safari/537.36'}#目标网站反爬不是很强,加个headers就够了 try: url=urllib.request.Request(url,headers=headers) with urllib.request.urlopen(url,timeout=15) as fp: return fp.read().decode() except: print(url,'网址进入失败') return '爬取失败4329840' def get_chapter_links(oristr:str,url:str)->list: ans=[] sign=0 for i in range(len(oristr)): if 'class="mlist"' in oristr[i:i+13]: l=r=i sign=1 if not sign: return [] while not '</ul>' in oristr[r:r+5]: r+=1 oristr=oristr[l:r]#;print(oristr) return get_hyper_links(oristr,url) def get_hyper_links(oristr:str,url: str) -> list: ans = [] for i in range(len(oristr)): sign=1 if oristr[i:i + 5] == 'href=': l = r = i + 6; while not oristr[r] == '"': r += 1; if r>=len(oristr): sign=0 break x = r + 1; while not oristr[x] == '>': x += 1 if x>=len(oristr): sign=0 break y = x = x + 1 while not oristr[y:y+4]=='</a>':# and not oristr[y:y+2]=='/>': y+=1;#print(y) if y>=len(oristr)-1: sign=0 break x=y; while not oristr[x]=='>': x-=1 if not x+1==y and sign and '/' or '.' in oristr[l:r]: ans.append([oristr[l:r], oristr[x+1:y]]) return ans def get_passage(oristr: str, url: str) -> str: replace_list = [['<p>', '\n\t'], ['</p>', '\n\t'], ['”', '”'], ['“', '“'],['<br>', ''],['<br/>', ''], ['<strong>', ''], ['</strong>', ''], ['…', '......'], ['<span>', ''], ['</span>', ''], ['—','————'],[' ',' ']] ans='';sign=0 for i in range(len(oristr)): if 'class="mbtitle"' in oristr[i:i+15]: l=r=i+16 sign=1 while sign and not oristr[r]=='<': r+=1 if sign: ans+=('\t \t'+oristr[l:r]+'\n')#'\t \t'是自定义的章节分隔符,为后续的数据处理提供便利 sign=0;mark=0 for i in range(len(oristr)): if '<p>' in oristr[i:i+3]: r=i+3 if not sign: sign = 1 l = i if '</p>' in oristr[i:i+4]: r=i+4 if not sign: return '' ans+=oristr[l:r] for i in replace_list: ans=ans.replace(i[0],i[1]) return ans def get_sub_passage(oristr:str,url:str)->str: replace_list = [['<p>', ''], ['</p>', '\n\t'], ['”', '”'], ['“', '“'], ['<br>', ''], ['<br/>', '\n'], ['<strong>', ''], ['</strong>', ''], ['…', '......'], ['<span>', ''], ['</span>', ''], ['—', '————'],[' ',' '],['</a>',''],['&','&']] ans = '' sign = 0 for i in range(len(oristr)): if '<title>' in oristr[i:i + 7]: l = r = i + 8 sign = 1 break while sign and not oristr[r:r+8] == '</title>': r += 1 if r>=len(oristr): r=l break if sign: ans += (oristr[l:r] + '\n') sign=0 for i in range(len(oristr)): if not sign and '<div class="txt"' in oristr[i:i+16]: l=i sign=1 if sign and '</div>' in oristr[i:i+6]: r=i+6 break if not sign: return '' sign = 0 mark = 0 for i in range(l,r): if '<p>' in oristr[i:i + 3]: r = i + 3 if not sign: sign = 1 l = i if '</p>' in oristr[i:i + 4]: r = i + 4 if not sign: return '' ans += oristr[l:r] for i in replace_list: ans = ans.replace(i[0], i[1]) for i in range(len(ans)): if ans[i:i+1]=='<': l=i sign=0 for j in range(l,len(ans)): if ans[j]=='>': r=j sign=1 break if sign: ans=ans[:l]+ans[r+1:] return ans
模块4:GetIinformation
import os #外部库 import time import copy import urllib.request import matplotlib import matplotlib.pyplot as plt import CrawlAndRefine as cr #自建模块 import OftenUsedFunctions as ouf import OpertionEdge as oe matplotlib.use('TkAgg') matplotlib.rc("font",family='YouYuan') class Book: def __init__(self, bookname:str,bookstr:str,edition:int):#传入小说名、小说字符串和版本号 self.name=bookname.replace('doc.','') self.edition=edition self.book_str=bookstr print('开始预处理',self.name,':') #开始划分并储存章节信息 print('正在划分小说第一层...') t1=time.time() chapter_str=bookstr.split('\t \t') self.chapter_str=[]#一维数组,记录每一章内容 self.chapter_begin_index=[]#一维数组,记录每一章开始下标(后面有用) index=0 for i in chapter_str: if i!='': self.chapter_str.append(i) index=self.book_str.find(i,index,len(bookstr)) self.chapter_begin_index.append(index) t2=time.time() print('第一层划分并储存完成,该层用时',t2-t1,'秒') #开始划分并储存段落信息 print('开始划分小说第二层...') t1=time.time() paragraph_str=[i.split('\n\t') for i in self.chapter_str] self.paragraph_str=[[] for i in self.chapter_str] for i in range(len(paragraph_str)):#过滤坏点 for j in range(len(paragraph_str[i])): if paragraph_str[i][j]!='': sign=0 for k in paragraph_str[i][j]: if ouf.IsChinese(k): sign=1 break if sign: self.paragraph_str[i].append(paragraph_str[i][j]) self.paragraph_begin_index=[[] for i in self.chapter_str] for i in range(len(self.paragraph_str)): index=self.chapter_begin_index[i] for j in self.paragraph_str[i]: index=self.book_str.find(j,max(0,index-1),len(bookstr)) self.paragraph_begin_index[i].append(index) t2=time.time() print('第二层划分并储存完成,该层用时',t2-t1,'秒') #开始分句子 print('开始处理第三层...') t1=time.time() sentence_str=[[j.split('。') for j in i] for i in self.paragraph_str]#三维数组,储存第i章第j段第k句 self.sentence_str=[[[] for j in i] for i in self.paragraph_str] for i in range(len(sentence_str)): for j in range(len(sentence_str[i])):#过滤坏点 for k in sentence_str[i][j]: for l in k: if ouf.IsChinese(l): self.sentence_str[i][j].append(k) break self.sentence_begin_index=[[[] for j in i] for i in self.paragraph_str] for i in range(len(self.sentence_str)): for j in range(len(self.sentence_str[i])): index=self.paragraph_begin_index[i][j] for k in self.sentence_str[i][j]: index=self.book_str.find(k,index,len(bookstr)) self.sentence_begin_index[i][j].append(index)#同样记录开始位置 t2=time.time() print('第三层划分并处理完成,该层用时',t2-t1,'秒') print('预处理完成!') def deep_processing(self):#实际实现时发现代码难度太大(需要手动操作五维数组),而且成效甚微,于大作业的主目标不符,故搁置 self.partial_sentence_str=partial_sentence_str=[] for i in range(len()): pass def get_match_degree(bookl,bookr): match_pointl,match_pointr,book=find_dif(bookl,bookr,0) s_all=s_match=r=0 singular_point=0 t_start=time.time() for i in range(len(match_pointl)): l=r r=match_pointl[i] sign=0 for j in range(l,r): if not book[j]: sign=1 break if sign: l2=0 if not i else match_pointr[i-1] r2=match_pointr[i] s_all+=r-l+r2-l2 t1=time.time() if r2-l2 and (r-l)/(r2-l2)<5 and (r-l and (r2-l2)/(r-l)<5): s_match+=ouf.LCS(bookl.book_str[l:r],bookr.book_str[l2:r2])<<1 t2=time.time() if (r-l)*(r2-l2)>500000: singular_point+=1 print(i,len(match_pointl)) t_ter=time.time() print('用时',t_ter-t_start,'秒') print('两版本相似度',(s_match/s_all)*100,'%') return (s_match/s_all),singular_point def find_dif(bookl,bookr,is_manual_op): match_pointl=[];s=0 match_pointr=[] book=[0 for i in range(len(bookl.book_str)+10)] chapter_unmatch_list=[] t1=time.time() for i in range(len(bookl.chapter_str)): l=ouf.lower_bound(bookl.chapter_begin_index[i],match_pointl,0,len(match_pointl)-1)#记忆化 r=l+1 if l==-1: l=0 else: l=match_pointr[l] if r==len(match_pointl): r=len(bookr.book_str) else: r=match_pointr[r] pos=bookr.book_str.find(bookl.chapter_str[i],l,r) if pos==-1: chapter_unmatch_list.append(i) else: for l in range(bookl.chapter_begin_index[i],bookl.chapter_begin_index[i]+len(bookl.chapter_str[i])): book[l]=1 s+=1 match_pointl.append(bookl.chapter_begin_index[i]) match_pointr.append(pos) match_pointl.append(bookl.chapter_begin_index[i]+len(bookl.chapter_str[i])) match_pointr.append(pos+len(bookl.chapter_str[i])) t2=time.time() #print(match_pointl) print('第一层比对完成,该层用时',t2-t1,'秒') if is_manual_op: if len(match_pointl)==0: print(bookl.name,'每一章都有所修改') else: print(bookl.name,'有部分章节有所修改') print('它们分别为:',sep='') for i in range(len(chapter_unmatch_list)): print(i+1,'、',bookl.paragraph_str[chapter_unmatch_list[i]][0].split('\n')[0].strip(':'),sep='') sign = 1 while sign: if is_manual_op: chapter_num = input('请选择您想要深入对比的章节,按照序号选择,在一行输入,空格隔开。全选请输入"all":\n').split() else: chapter_num=['all'] sign = 0 for i in chapter_num: if i == 'all': chapter_num = [str(i+1) for i in chapter_unmatch_list] break elif not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid, i) or not 0 < eval(i) <=max(chapter_unmatch_list): print(i, '是不合法输入,请重试') sign = 1 chapter_num = list(map(eval, chapter_num)) for i in range(len(chapter_num)): chapter_num[i]-=1 chapter_num.sort() paragraph_unmatch_list=[[] for i in range(max(chapter_unmatch_list)+1)] t1 = time.time() for i in chapter_num: for j in range(len(bookl.paragraph_str[i])): l = ouf.lower_bound(bookl.paragraph_begin_index[i][j], match_pointl, 0, len(match_pointl) - 2) r = l + 1 if l == -1: l = 0 else: l = match_pointr[l] if r >= len(match_pointl)-1: r = len(bookr.book_str) else: r = match_pointr[r] pos = bookr.book_str.find(bookl.paragraph_str[i][j], l, r) if pos == -1: paragraph_unmatch_list[i].append(j) else: if (not len(match_pointr)) or pos>match_pointr[-1]: match_pointl.append(bookl.paragraph_begin_index[i][j]) match_pointr.append(pos) match_pointl.append(bookl.paragraph_begin_index[i][j] + len(bookl.paragraph_str[i][j])-1) match_pointr.append(pos + len(bookl.paragraph_str[i][j])-1) for l in range(bookl.paragraph_begin_index[i][j],bookl.paragraph_begin_index[i][j]+len(bookl.paragraph_str[i][j])): book[l]=1 s+=1 elif pos>match_pointr[-2]: match_pointl.pop() match_pointr.pop() match_pointr.pop() match_pointl.pop() t2 = time.time() #print(match_pointl) print('第二层比对完成,该层用时', t2 - t1, '秒') new_match_pointl=[] new_match_pointr=[] sentence_unmatch_list=[[[] for j in i] for i in bookl.sentence_str]#j为在paragraph_unmatch_list中的下标,paragraph_unmatch_list中才存的是章号 for i in range(len(paragraph_unmatch_list)): if len(sentence_unmatch_list[i])<len(paragraph_unmatch_list[i]): print(i) t1=time.time() for i in chapter_num: for j in paragraph_unmatch_list[i]: for k in range(len(bookl.sentence_str[i][j])): l1=ouf.lower_bound(bookl.sentence_begin_index[i][j][k],match_pointl,0,len(match_pointl)-1) l2=-1#ouf.lower_bound(bookl.sentence_begin_index[i][j][k],new_match_pointl,0,len(new_match_pointl)-2) if l1>=l2: l=l1 r=l+1 if l == -1: l = 0 else: l = match_pointr[l] if r == len(match_pointl): r = len(bookr.book_str) else: r = match_pointr[r] else: l=l2 r=l+1 if l==-1: l=0 else: l=new_match_pointr[l] if r>=len(new_match_pointl)-1: r=len(bookr.book_str) else: r=new_match_pointr[r] pos = bookr.book_str.find(bookl.sentence_str[i][j][k], l, r) if pos == -1: sentence_unmatch_list[i][j].append(k) else: if (not len(new_match_pointr)) or pos > new_match_pointr[-1]: new_match_pointl.append(bookl.sentence_begin_index[i][j][k]) new_match_pointr.append(pos) new_match_pointl.append(bookl.sentence_begin_index[i][j][k] + len(bookl.sentence_str[i][j][k])) new_match_pointr.append(pos + len(bookl.sentence_str[i][j][k])) for l in range(bookl.sentence_begin_index[i][j][k],bookl.sentence_begin_index[i][j][k]+len(bookl.sentence_str[i][j][k])): book[l]=1 s+=1 elif pos > new_match_pointr[-2]: new_match_pointl.pop() new_match_pointr.pop() new_match_pointr.pop() new_match_pointl.pop() t2=time.time() # for i in range(1,len(new_match_pointr)): # if new_match_pointr[i]-new_match_pointr[i-1]>10000: # print(i) # print(bookr.book_str[new_match_pointr[i-1]:new_match_pointr[i-1]+100]) # print('1111') # print(bookr.book_str[new_match_pointr[i]:new_match_pointr[i]+100]) # print('md') # print(bookl.book_str[new_match_pointl[i-1]:new_match_pointl[i-1]+100]) # print('2222') # print(bookl.book_str[new_match_pointl[i]:new_match_pointl[i]+100]) # print('mmmmd') print('第三层对比完成,该层用时',t2-t1,'秒') if is_manual_op: return match_pointl1=copy.deepcopy(match_pointl) #双有序列表合并,o(n) match_pointr1=copy.deepcopy(match_pointr) match_pointl2=copy.deepcopy(new_match_pointl) match_pointr2=copy.deepcopy(new_match_pointr) del new_match_pointr del new_match_pointl match_pointl=[] match_pointr=[] top1=top2=0 while top1<len(match_pointl1) and top2<len(match_pointl2): if match_pointl1[top1]<match_pointl2[top2]: match_pointl.append(match_pointl1[top1]) match_pointr.append(match_pointr1[top1]) top1+=1 else: match_pointl.append(match_pointl2[top2]) match_pointr.append(match_pointr2[top2]) top2+=1 while top1<len(match_pointl1): match_pointl.append(match_pointl1[top1]) match_pointr.append(match_pointr1[top1]) top1 += 1 while top2<len(match_pointl2): match_pointl.append(match_pointl2[top2]) match_pointr.append(match_pointr2[top2]) top2 += 1 #done # for i in range(1,len(match_pointr)): # if match_pointr[i]-match_pointr[i-1]>10000: # print(i) # print(bookr.book_str[match_pointr[i-1]:match_pointr[i-1]+100]) # print('1111') # print(bookr.book_str[match_pointr[i]:match_pointr[i]+100]) # print('md') # print(bookl.book_str[match_pointl[i-1]:match_pointl[i-1]+100]) # print('2222') # print(bookl.book_str[match_pointl[i]:match_pointl[i]+100]) # print('mmmmmmmmd') #print(match_pointl[0],bookl.book_str[match_pointl[0]:match_pointl[0]+100]) #print(match_pointr[0],bookr.book_str[match_pointr[0]:match_pointr[0]+100]) return match_pointl,match_pointr,book def one_edition_multi_books(oristr:str,url:str): print('请输入您要分析的版本或返回上一步:\n1、修订版\n2、新修版\n3、旧版\n4、返回') edition = '' while (not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid, edition)) or not 0 < eval(edition) < 5: edition = input('请输入您的选择:\n') edition = eval(edition) edition_list=['','修订版','新修版','旧版'] if edition==4: oe.basic_operation_choice(oristr,url) return editioname=['','修订版','新修版','旧版'] book_list=list(os.listdir('D:\\大学\\金庸小说done\\'+editioname[edition])) for i in range(len(book_list)): print(i+1,'、',book_list[i].replace('.doc',''),sep='') sign = 1 while sign: book_num = input('请选择您想要分析的书目,按照序号选择,在一行输入,空格隔开。若要全部下载,请输入"all":\n').split() sign = 0 for i in book_num: if i == 'all': book_num = [str(i) for i in range(1, len(selected_list))] break elif not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid, i) or not 0 < eval(i) <=len(book_list): print(i, '是不合法输入,请重试') sign = 1 book_num = list(map(eval, book_num)) book_inf=[] for i in range(len(book_num)): try: with open('D:\\大学\\金庸小说done'+'\\'+edition_list[edition]+'\\'+book_list[book_num[i]-1],'rb') as fp: bookstr=fp.read().decode() except: print(edition_list[edition],book_list[book_num[i]-1],'未下载!\n请返回下载...') oe.basic_operation_choice(oristr,url) info=Book(book_list[book_num[i]-1],bookstr,edition) book_inf.append(info) sign=0 while sign: print('对于单版本多书,我们支持如下功能:\n1、关键词搜索\n2、关键词频次统计与分布\n3、尚待开发,敬请期待') def multi_editions_one_book(oristr:str,url:str): book_list = list(os.listdir('D:\\大学\\金庸小说done\\' + '修订版')) for i in range(len(book_list)): print(i + 1, '、', book_list[i].replace('.doc', ''), sep='') print(len(book_list)+1,'、','返回上一步',sep='') booknum='' while (not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid,booknum)) or not 0<eval(booknum)<len(book_list)+2: booknum=input('请输入书目号:\n') booknum=eval(booknum) print('请输入您要分析的版本(请键入两个版本)或返回:\n1、修订版\n2、新修版\n3、旧版') edition1 = '' while (not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid, edition1)) or not 0 < eval(edition1) < 4: edition1 = input('请输入第一个版本的版本号:\n') edition1 = eval(edition1) edition2 = '' while (not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid, edition2)) or not 0 < eval(edition2) < 4: edition2 = input('请输入第二个版本的版本号:\n') edition2 = eval(edition2) edition_list = ['', '修订版', '新修版', '旧版'] book_inf=[] try: with open('D:\\大学\\金庸小说done' + '\\' + edition_list[edition1] + '\\' + book_list[booknum- 1], 'rb') as fp: bookstr = fp.read().decode() except: print(edition_list[edition1], book_list[booknum - 1], '未下载!\n请返回下载...') oe.basic_operation_choice(oristr, url) info = Book(book_list[booknum-1], bookstr,edition1) book_inf.append(info) try: with open('D:\\大学\\金庸小说done' + '\\' + edition_list[edition2] + '\\' + book_list[booknum- 1], 'rb') as fp: bookstr = fp.read().decode() except: print(edition_list[edition2], book_list[booknum - 1], '未下载!\n请返回下载...') oe.basic_operation_choice(oristr, url) info = Book(book_list[booknum-1], bookstr,edition2) book_inf.append(info) sign=0 while not sign: print('对于多版本单书,我们支持如下功能:\n1、相似度分析\n2、修改部分对比\n3、敬请期待') op='' while not ouf.JudgeValid.Is_Int_Num(ouf.JudgeValid,op) or not 0<eval(op)<3: op=input('请输入您的选择:\n') op=eval(op) if op==1: get_match_degree(book_inf[0],book_inf[1]) else: find_dif(book_inf[0],book_inf[1],1) print('是否想要继续操作?') sign=ouf.ask_yes_no() oe.analysis_entry(oristr,url) def get_report(oristr:str,url:str): book_list = list(os.listdir('D:\\大学\\金庸小说done\\' + '修订版')) #print(book_list) match_inf=[] book_inf=[] for i in book_list: with open('D:\\大学\\金庸小说done' + '\\修订版'+ '\\'+i, 'rb') as fp: bookstr=fp.read().decode() info1=Book(i,bookstr,1) with open('D:\\大学\\金庸小说done' + '\\新修版'+ '\\'+i, 'rb') as fp: bookstr=fp.read().decode() info2=Book(i,bookstr,2) book_inf.append([info1,info2]) match_inf.append(get_match_degree(info1,info2)) whole_match=[] singular_point=[] for i in match_inf: whole_match.append(i[0]*100) singular_point.append(i[1]) to_show_book_list=[] for i in book_list: to_show_book_list.append(i[0]) plt.plot(to_show_book_list,whole_match) plt.xlabel('书目') plt.ylabel('相似度(%)') plt.ylim((60,100)) plt.savefig('D:\\大学\\金庸小说done\\分析报告\\相似度(修订版VS新修版).jpg') #plt.show() plt.figure() plt.plot(to_show_book_list,singular_point) plt.xlabel('书目') plt.ylabel('跃点数/(个)') plt.ylim((0,60)) plt.savefig('D:\\大学\\金庸小说done\\分析报告\\跃点数(修订版VS新修版).jpg') #plt.show() ma=max(singular_point) singular_point_percent=list(map(lambda x:(x/ma)*100,singular_point)) plt.figure() l1,=plt.plot(to_show_book_list,whole_match,label='相似度') plt.xlabel('书目') l2,=plt.plot(to_show_book_list,singular_point_percent,color='red',linestyle='--',label='跃点情况') plt.ylabel('百分比(%)') plt.legend(handles=[l1, l2],labels=['相似度', '跃点情况']) plt.savefig('D:\\大学\\金庸小说done\\分析报告\\相似度&跃点数对比图(修订版VS新修版).jpg') #plt.show() #按章处理 major_chapter_num=[20,20,40,50,40,9,20,40,40,1,12,10,20,1,50] book_chapter_num=dict(zip(book_list,major_chapter_num)) chapter_inf=[[] for i in book_list]#内部的括号储存若干个元组,每个元组中包含两个元素,分别为修订版和新修版的第i本书第j章按照Book结构体储存的信息 chapter_match=[[] for i in book_list] chapter_to_show_name=[[j for j in range(1,i+1)] for i in major_chapter_num] for i in range(len(book_list)):#获得每本书每一章的分层处理信息 for j in range(1,major_chapter_num[i]+1): print(book_list[i],len(book_inf[i][0].paragraph_str),len(book_inf[i][1].paragraph_str)) info1=Book(book_inf[i][0].paragraph_str[j][0],book_inf[i][0].chapter_str[j],1) info2=Book(book_inf[i][1].paragraph_str[j][0],book_inf[i][1].chapter_str[j],2) #print(info1.paragraph_begin_index) chapter_inf[i].append((info1,info2)) chapter_match[i].append(100*get_match_degree(info1,info2)[0]) plt.figure() plt.plot(chapter_to_show_name[i],chapter_match[i]) plt.xlabel('章节') plt.ylabel('相似度(%)') plt.ylim((30,100)) plt.title(book_list[i].replace('.doc','')) plt.savefig('D:\\大学\\金庸小说done\\分析报告\\'+book_list[i].replace('.doc','')+'章节相似度.jpg') # plt.show() def get_word_base(oristr:str,url:str): urlist = [ 'http://www.jinyongwuxia.cc/data/renwu/index.htm', 'http://www.jinyongwuxia.cc/data/wugong/index.htm', 'http://www.jinyongwuxia.cc/data/menpai/index.htm'] selected_list = [] for url in urlist: rurl = 'http://www.jinyongwuxia.cc/data/index.html' oristr = cr.crif(url) datalist = cr.get_hyper_links(oristr, url) for i in datalist: sign = 0; cur = '' for j in i[0]: if '0' <= j <= '9': cur += j sign = 1 if sign and len(cur) > 1: selected_list.append([rurl.replace('index', cur), i[1]]) wordset=set() for i in selected_list: wordset.add(i[1]) inf=' '.join(wordset) with open('D:\\大学\\金庸小说done\\wordbase.txt','w') as fp: fp.write(inf) print('词库创建完成!')
模块5:OftenUsedFunctions:
import time import urllib.request def ask_yes_no()->bool: yes=['yes','Yes','YES','1','是'] no=['no','No','NO','0','否'] s=input('请回答是或否(可用yes/no、0/1代替):') if s in yes: return 1 if s in no: return 0 print('读不懂,请重试:') return ask_yes_no() def IsChinese(ch:str)->bool: if '\u4e00' <= ch <= '\u9fff': return 1 return 0 def IsNum(ch:str)->bool: if '0'<=ch<='9': return 1 return 0 def IsPounctuation(ch:str)->bool: pouncuation = {',', ',', '。', '.', '!', '!', '?', '?', '/', '"', "'", '“', '”', '《', '》', '\n', '○', ':', ':'} if ch in pouncuation: return 1 return 0 class JudgeValid(): def Is_Int_Num(self,ch)->bool: if type(ch)==int: return 1 try: ch=eval(ch) if type(ch)==int: return 1 return 0 except: return 0 def Is_Website(self,ch)->bool: if 'https://' in ch or 'http://' in ch: return 1 else: return 0 class heap: def __init__(self,a:list,cmp): self.raw=a a.append(a[0])#为了利用完全二叉树父子下标两倍的大小关系带来的编程便利,这里的堆数组h下标从1开始 a[0]=0 self.h=h for i in range(len(self.h)-1,0,-1): self.shiftdown(i,cmp) def shiftdown(self,root:int,cmp): top=len(self.h)-1 if root<<1>top: return if (root<<1)+1>top: if cmp(self.h[root<<1],self.h[root]): self.h[root<<1],self.h[root]=self.h[root],self.h[root<<1] self.shiftdown(root<<1,cmp) return if cmp(self.h[root<<1],self.h[root]) or cmp(self.h[(root<<1)+1],self.h[root]): if cmp(self.h[root<<1],self.h[(root<<1)+1]): self.h[root<<1],self.h[root]=self.h[root],self.h[root<<1] self.shiftdown(root<<1,cmp) else: self.h[(root<<1)+1],self.h[root]=self.h[root],self.h[(root<<1)+1] shiftdown((root<<1)+1,cmp) def add(self,cur:int,cmp): top=len(self.h)-1 self.h.append(self.h[1]) self.h[1]=cur self.shiftdown(1,cmp) def lower_bound(cur:int,a:list,x:int,y:int): if y<0: return -1 l=x r=y while(r-l): mid=(r+l)>>1 if a[mid]==cur: l=r=mid if a[mid]<cur: l=mid if a[mid]>cur: r=mid if r-l==1: if a[l]<cur: if a[r]<cur: return r return l else: return l-1 if a[l]<=cur: return l else: return l-1 def LCS(a:str,b:str)->int: if len(a)<len(b): a,b=b,a f=[0 for i in range(len(b)+1)] ans=0 for i in range(1,len(a)+1): for j in range(len(b),0,-1): if a[i-1]==b[j-1]: f[j]=max(f[:j])+1 ans=max(ans,f[j]) return ans