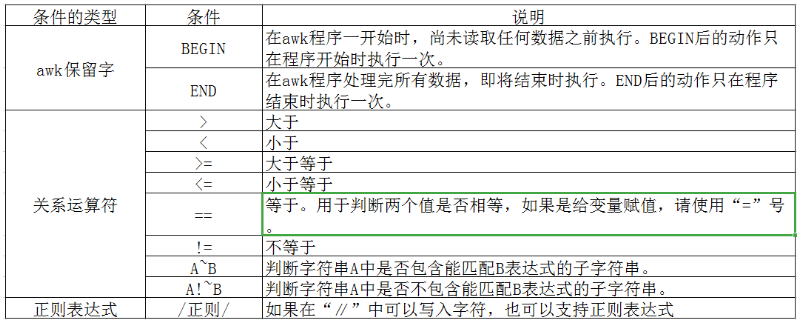
- 1、AWK的条件表达
- 2、条件表达式说明
- (1)BEGIN
- (2)END
- (3)关系运算符
- (4)说明AWK中条件表达式的执行过程
- (5)AWK中使用正则表达式
- (6)
A~B练习
如下图所示:
以下练习使用如下文本:
ID Name Python Linux MySQL Java
1 Tangs 88 87 86 85.55
2 Sunwk 99 98 97 96,66
3 Zhubj 77 76 75 74.44
4 Shahs 66 65 64 63.33
BEGIN是AWK的保留字,是一种特殊的条件类型。
BEGIN的执行时机是在AWK程序一开始时,尚未读取任何数据之前执行。
BEGIN后的动作只执行一次,因为当AWK开始从文件中读入数据,BEGIN的条件就不再成立,所以BEGIN定义的动作只能被执行一次。
练习:执行命令查看BEGIN作用:
执行命令:awk 'BEGIN{print "This is BEGIN action"} {printf $2 "\t" $3 "\t" $6 "\t" "\n"}' student.txt
[root@localhost tmp]# awk 'BEGIN{print "This is BEGIN action"} {printf $2 "\t" $3 "\t" $6 "\t" "\n"}' student.txt
This is BEGIN action
Name Python Java
Tangs 88 85.55
Sunwk 99 96.66
Zhubj 77 74.44
Shahs 66 63.33
(2)END说明:
- AWK命令只要检测不到完整的单引号不会执行,所以这个命令的换行不用加入
\,就是一行命令- 上边命令定义了两个动作:
第一个动作使用BEGIN条件,所以会在读入文件数据前打印“This is BEGIN action”(只会执行一次)
第二个动作会打印文件中的对应文本。
END也是AWK保留字,不过刚好和BEGIN相反。
END是在AWK程序处理完所有数据,即将结束时执行。END后的动作只在程序结束时执行一次。
练习:执行命令查看END作用:
执行命令:awk 'END{print "This is END action"} {printf $2 "\t" $3 "\t" $6 "\t" "\n"}' student.txt
[root@localhost tmp]# awk 'END{print "This is END action"} {printf $2 "\t" $3 "\t" $6 "\t" "\n"}' student.txt
Name Python Java
Tangs 88 85.55
Sunwk 99 96.66
Zhubj 77 74.44
Shahs 66 63.33
This is END action
(3)关系运算符说明:在输出结尾输入“This is END action”,这并不是文档本身的内容,而且只会执行一次。
假设我想看看Java绩大于等于80分的学员是谁,就可以这样输入命令:
grep -v "Name" student.txt | awk '$6>=80 {printf $2 "\n"}'
# 判断第六字段(Java成绩)大于等于80分的行,如果判断式成立,则打印第2列(学员名)
[root@localhost tmp]# grep -v "Name" student.txt | awk '$6>=80 {printf $2 "\n"}'
Tangs
Sunwk
(4)说明AWK中条件表达式的执行过程
grep -v "Name" student.txt是把标题过滤掉。
要先说明一下,虽然AWK是列提取命令,但是也要按行来读入的。
在AWK处理一个文本文件的时候:
- 先判断表达式中有没有
BEGIN。
如果有,就先执行BEGIN定义的操作,且执行一次。 - 如果没有
BEGIN或者BEGIN定义的动作执行完成之后,会把文本中的第一行数据读入AWK中,
把该行的整行数据赋予$0变量中,
把该行数据的第一列赋值在$1变量中,第二列赋值在$2变量中,以此类推。 - 例如
awk '{printf $2 "\n"}' student.txt,意思是打印文本中的第二列姓名。
我们先忽略掉条件,流程是:
AWK读取第一行数据(上面一步),然后执行动作输出第二列信息,也就是输出第一行的第二列信息。
然后开始读取第二行数据,然后再执行动作,输出第二行的第二列信息,
然后再读取第三行数据,之后执行动作,输出第三行的第二列信息,
以此类推,基本上就是这样的一个过程。 - 然后在加上条件
awk '$6>=80 {printf $2 "\n"}' student.txt
判断第六列Java的成绩大于80分,才输出。
还是和上边一样,先是AWK读取第一行数据完成之后,就要处理动作了,
但是在处理动作之前,先要判断一下动作前面的条件是否成立,
如果成立,则执行后边的动作。
如果不成立,则不执行跟在后边的动作。
然后在开始读取第二行数据,重复上边的流程,以此类推。
总结一下就是:加入了条件之后,只有条件成立动作才会执行,如果条件不满足,则动作则不运行。 - 最后如果有
END,则把END中定义的动作执行一次。
以上就是AWK的执行流程。
(5)AWK中使用正则表达式如果要想让AWK识别字符串,必须使用//包含,//中识别的就是正则表达式规则匹配的字符串。
例如:
# 输出打印Sunwk的成绩
# awk会匹配有Sunwk符号的行,并输出
[root@localhost tmp]# awk '/Sunwk/ {print}' student.txt
2 Sunwk 99 98 97 96.66
(6)注意:这里要注意在AWK中,使用
//包含的字符串,AWK命令才会查找。也就是说字符串必须用//包含,AWK命令才能正确识别。
A~B练习
A~B是A包含B的意思。
练习:查看Sunwk用户的Java成绩。
# 匹配第二字段中包含有“Sun”字符,则打印第六字段数据
[root@localhost tmp]# awk '$2 ~ /Sun/ {printf $6 "\n" }' student.txt
96.66
提示:(6)练习的方式,是在某一列中查找是否包含一个字符串。而上面(5)的写法,是在一行数据当中匹配是否包含一个字符串,根据需求灵活使用。
注意:
~两边有无空格都可以。
拓展练习:
当使用df命令查看分区使用情况时,如果我只想查看真正的系统分区的使用状况,而不想查看光盘和临时分区的使用状况,则可以执行如下:
# 查询包含有sda+数字的行,并打印第一字段和第五字段
[root@localhost tmp]# df -h | awk '/sda[0-9]/ {printf $1 "\t" $5 "\t" "\n"}'
/dev/sda3 12%
/dev/sda1 15%