B 树是一种自平衡的查找树,能够保持数据有序。这种数据结构能够让查找数据、顺序访问、插入数据及删除数据的动作,都能在对数时间内完成。
同一般的二叉查找树不同,B 树是一棵多路平衡查找树,其特性是:结点的孩子结点数可以多于两个,且每一个结点处可以存储多个元素。
在 B 树中,非叶子结点可以拥有可变数量的子结点,为了维持在预先设定的数量范围内,通常是对非叶子结点进行合并和分离。其优势是不需要像其他自平衡查找树那样频繁地重新保持平衡,其劣势是结点未被完全填充时会浪费一些空间。
特性通常,我们会在 B 树的名称前添加阶数以示说明,如 m 阶 B 树。一个 m 阶的 B 树具有以下特性:
- 任意结点最多有 m 个孩子结点
- 任意除根结点以外的非叶子结点最少有 \(\frac{m}{2}\) 个子结点
- 如果根结点不是叶子结点,那么它至少有 2 个孩子结点
- 有 k 个孩子结点的非叶子结点有 k-1 个键
- 所有的叶子结点都在同一层,B 树也是通过此约束来保持树的平衡
下述展示的是一个 3 阶 B 树:
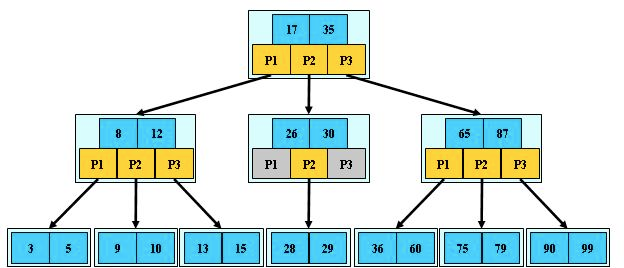
B 树可以指一个特定的树形结构,也可以指大体上的一类树形结构。
对于 B 树这一类树形结构,还包括了 B+ 树和 B* 树等结构,它们的简单定义如下:
对于 B+ 树,关键字只存储在叶子结点,非叶子结点存储的是叶子结点所存储关键字的部分拷贝,所有的叶子结点也都在相同的高度,叶子结点本身按关键字大小从小到大链接。
B* 树是 B+ 树的变体,在 B+ 树的基础上,非叶子结点(除根结点外)会增加指向同一层兄弟的指针,且非叶子结点关键字个数至少为 \(\frac{2m}{3}\),即块的最低使用率为 \(\frac{2}{3}\)(B+ 树为 \(\frac{1}{2}\))。
下面为 B* 树的结构:
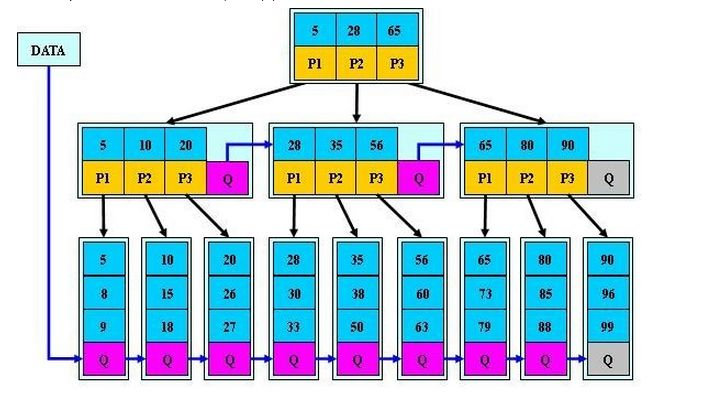
其实,B 树就是一种为磁盘而设计的树形结构,主要是降低其他树形结构访问磁盘的 IO 次数。
磁盘读取从磁盘读取数据的时间主要涉及到“寻道时间”和“旋转延迟”:
- 寻道时间指的是磁盘接收到系统指令后,磁头从头开始移动到数据所在磁道所需要的时间,可能是 0 到 20 毫秒甚至更久
- 旋转延迟指的是寻道结束后,磁盘将对应的扇区旋转到磁头下所需要的时间,其平均时间大约在旋转周期的 50% 左右,对于一个 7200 转的磁盘,采用 60×1000÷7200 的公式计算得知一次旋转周期事件为 8.33 毫秒左右
磁盘的顺序读写会比随机读写快也是这个原因,在顺序读写时,磁头不需要再做寻道,仅需很少的旋转时间,而随机读写则需要不停地移动磁头寻找对应的磁道。
磁盘预读为了尽量减少 IO 操作,计算机系统一般采取预读的方式,预读的长度一般为页(Page)的整数倍。
页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(多数操作系统页的大小为 4k),主存和磁盘以页为单位交换数据。
计算机系统是分页读取和存储的,每次读取和存取的最小单元为一页,而磁盘预读时通常会读取页的整数倍。
索引结构对于文件系统和数据库系统的索引,通常以文件的形式存储在磁盘上,因此查找索引也会执行磁盘 IO 操作,如果查找过程中磁盘 IO 的存取次数过多会影响索引的效率。
数据库系统普遍使用 B 树或者 B+ 树作为索引结构,其巧妙地利用了磁盘预读原理,将一个结点设置为一个页的大小,这样每个结点只需要一次 IO 就可以完全载入。
同时,在使用过程中还运用了以下技巧:
- 每次新建结点时,直接申请一个页的空间,实现一个结点只需一次 IO
- 将根结点常驻内存,在实际使用时可以减少 1 次 IO
使用 B 树作为索引结构时,由于结点的大小等于一个页的大小,通常阶会比较大,因此树的深度较浅(通常不超过 3),查找效率非常高。
缺点虽然数据库系统普遍使用 B 树作为索引结构,但是仍然有以下缺点:
- 非叶子结点直接存储数据,同一结点存储的索引数会比较少
- 数据即可能存储在叶子结点,也可能存储在非叶子结点,查询效率相对不稳定
- 在同层结点之间没有指针相邻,不适合做一些数据遍历操作
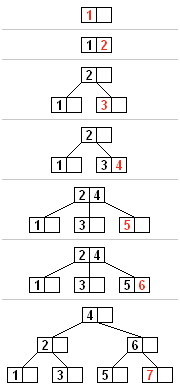
B 树所有的插入过程都以根结点起始,首先是要查找到新元素所要存储的结点,然后判断插入结点的元素数量:
-
如果结点存储的元素数量小于最大值,那么有空间容纳新的元素,直接插入并保持结点内部有序即可;
-
如果结点存储的元素数量大于等于最大值,将它平均地分裂成 2 个结点:
- 从该结点的原有元素和新的元素中选择出中位数(按顺序排列的一组数据中居于中间位置的数);
- 小于中位数的元素放入左边结点,大于中位数的元素放入右边结点,中位数作为分隔值;
- 将分隔值插入到父结点中,这也可能会造成父结点发生分裂,父结点的分裂也可能会造成它的父结点分裂,以此类推;如果没有父结点,就创建一个新的父结点。
删除 B 树中的结点有两种常用的策略:
- 定位并删除元素,然后调整树使它满足约束条件
- 从上到下处理这棵树,在进入一个结点之前,调整树使得其之后一旦遇到要删除的键,可以被直接删除而不需要再进行调整
对于前一种删除策略,其删除流程如下:
- 如果删除叶子结点中的元素,将它直接删除,如果结点中的元素数量小于最小值,则进行重新平衡操作;
- 如果删除非叶子结点中的元素,选择一个新的分隔值(左子树中最大的元素或右子树中最小的元素),将它从叶子结点中移除,替换掉被删除的元素作为新的分隔值,如果该叶子结点中的元素数量小于最小值,则进行重新平衡操作;
- 重新平衡操作从叶子结点开始,向根结点进行,直到树重新平衡。
在删除结点中,使 B 树重新平衡主要会有以下情况:
-
如果缺少元素结点的右兄弟结点存在且拥有多余的元素,那么向左旋转:
- 将父结点的分隔值移动到左子树中最大元素处;
- 将右兄弟结点的最小元素移动到原父结点的分隔值处;
-
如果缺少元素结点的左兄弟结点存在且拥有多余的元素,那么向右旋转:
- 将父结点的分隔值移动到右子树中最小元素处;
- 将左兄弟结点的最大元素移动到原父结点的分隔值处;
-
如果缺少元素结点的两个直接兄弟结点都只有最小数量的元素,那么将它与左兄弟结点以及它们在父结点中的分隔值合并:
- 将分隔值复制到左边的结点;
- 将此缺少元素结点中的所有元素移动到左边结点;
- 将缺少元素的结点移除;
- 如果父结点是根结点且没有元素,则释放它并让合并后的结点成为新的根结点;如果父结点的元素数量小于最小值,重新平衡父结点。
对 B 树做删除元素的操作比较复杂,但仍然是以保持 B 树平衡为主,并且不使其导致特性失效。