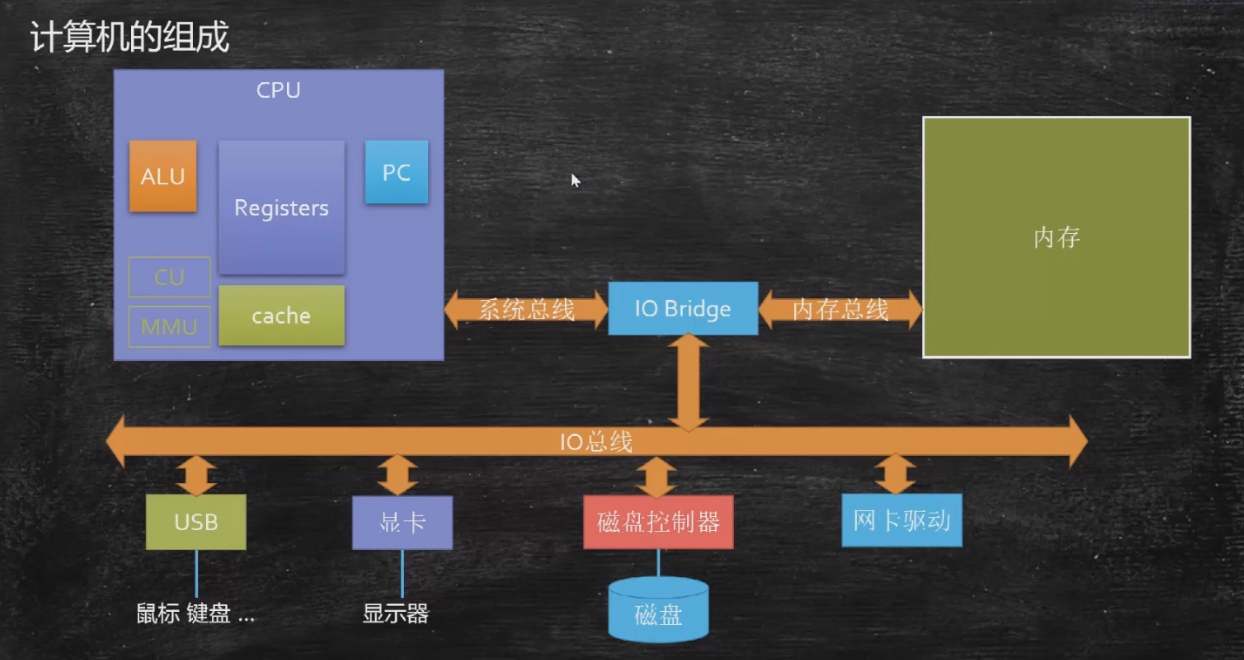
要聊可见性,这事儿还得从计算机的组成开始说起,我们都知道,计算机由CPU、内存、磁盘、显卡、外设等几部分组成,对于我们程序员而言,写代码主要关注CPU和内存两部分。放几张马士兵老师的图:
再说CPU,众所周知,CPU同一时间点,只能执行一个线程,多个线程之间通过争抢CPU资源获得执行权,实现一种伪并发的效果。但这其实说的是上古CPU,那种单核CPU。现在的CPU,其实都是多核了。准确的说法,应该是一个核在同一时间点,只能执行一个线程。(题外话,这句话其实现在来说依然过时了,英特尔公司研发出的“超线程技术”,把一个物理核心模拟成两个逻辑核心,允许在每个内核上运行多个线程,就是我们常听到的什么4核8线程,8核16线程CPU。还有最新的大小核架构,这里不展开了)
CPU的运行速度是非常非常快的,大约是内存的100倍。什么意思呢?如果CPU的一个计算单元,去访问寄存器需要1ns,那么访问内存,就需要100ns。而且根据摩尔定律,CPU的速度每18个月就会翻倍,相当于每年增⻓ 60% 左右,内存的速度当然也会不断增⻓,但是增⻓的速度远小于 CPU,平均每年只增长7%左右。于是,CPU与内存性能的差距不断拉大。
如果我们访问内存中的一个数据A,那么很有可能接下来会再次访问到这个数据A,这叫时间局部性原理。
我们上面说CPU比内存速度要快太多了,要是CPU每次都是去内存取数据A,其实有99%的时间是等待浪费了。再由于时间局部性原理,数据A之后还可能会被访问很多次,这个时间浪费就不可接受了,那么我们该如何提高性能呢?编程思想万变不离其宗,既然一个数据可能会被频繁使用,而每次去内存取数据太慢,那就加缓存好了。
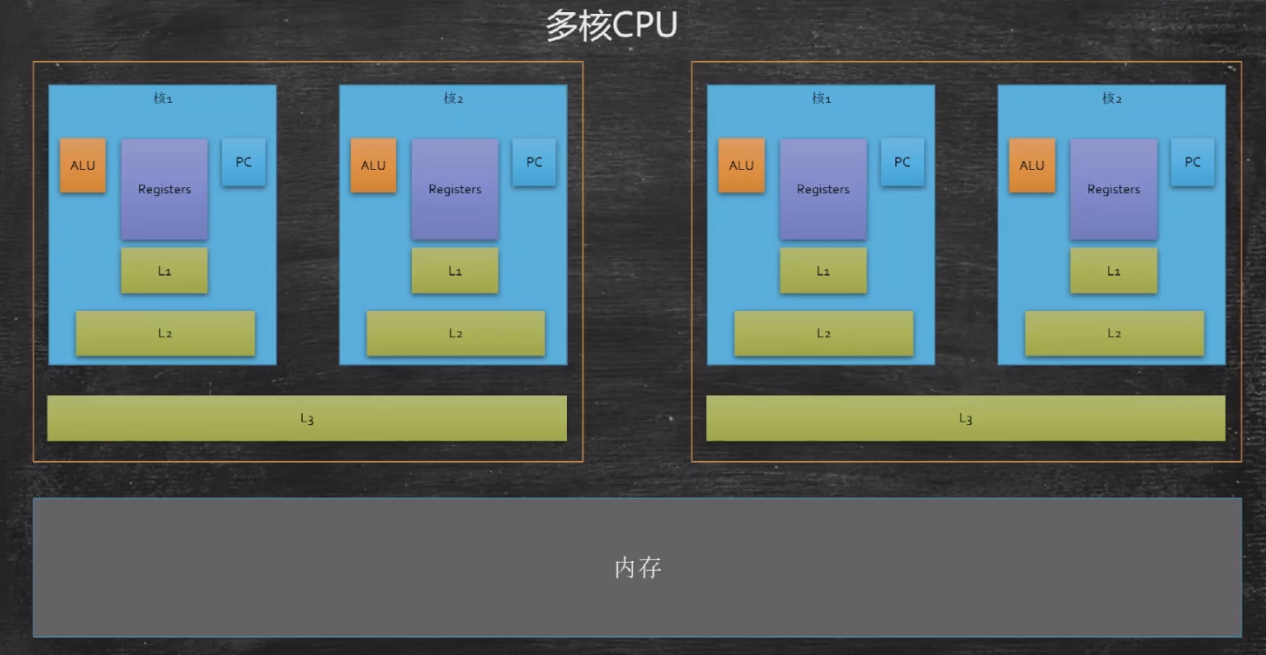
现代CPU为了增加CPU读写内存性能,就在CPU和内存之间增加了多级cache,也称高速缓存L1、L2、L3,其中L3是多个核心共享的。这其实就是我们常听说的,CPU三级缓存。
CPU读内存时首先从L1找起(这里有个很细的细节,有的时候会直接去L2找,跳过L1),能找到直接返回,否则就要在L2中找,找不到就到L3中找,还找不到就去内存中找了(内存还没有的话就去磁盘找)。找到之后,会把找到的数据放到L3、L2、L1里,下次再找,直接就在L1里找到了。
至于为什么是三级缓存,而不是两级四级呢?其实很简单,越往上,虽然存储介质速度越快,但造价越高容量也越小;越往下,虽然存储介质速度越慢,但造价越低容量也越大。三级缓存,是一个工业实践后,平衡经济与效率的最佳方案。
这里就有个问题了,如果CPU每次要取数据,都要走一遍上面这个流程,明显效率也不高啊。比如我要访问一个数组的数据,对数组做个遍历,去拿第一数据,走一遍上面的流程,去拿第二个,又走一遍,这太麻烦了。也许我们平时使用redis等缓存的时候,会觉得这么做没什么毛病,但CPU是要追求极致的性能的,这点性能损耗就是不能接受的。(类似懒汉式,用到的时候才去查,然后放到缓存里,第一次执行效率不高)
那么我们想提高效率又该怎么办呢?
如果我们访问内存中的一个数据A,还很有可能访问与数据A相邻的数据B、数据C,这叫空间局部性原理。那所幸我们在取A的时候,就把A周围的数据一次都取回来,一次取一批数据。这解决方案又是一个编程思想,批处理。也可以说是饿汉式,提前把可能要用到的数据一起加载到CPU缓存里。
既然是批处理,那就会有个问题,这个“一批”,多大合适呢?是 5 bytes,10 bytes,还是多少?很明显,大了不合适,浪费缓存空间,小了也不合适,缓存命中率不高。所以同样是经过大量工业实践,最终确定了一个最佳大小,64 bytes(最常见的大小,小部分cpu可能是别的大小)。我们把这一次读取的 64 bytes 数据,称之为 Cache Line(缓存行)(也有文章称之为缓存段,缓存块的)。CPU每次从内存中读取数据,会一次将 64 bytes 的数据一起读回去,并放到三级缓存中,这样就可以解决上面的问题,大大提高了CPU读取数据的性能。
缓存一致性到目前为止,为了尽可能的提高CPU读内存的性能,我们引入了三级缓存,引入了缓存行,但还有一个问题没有解决,那就是写缓存会导致的缓存一致性问题。
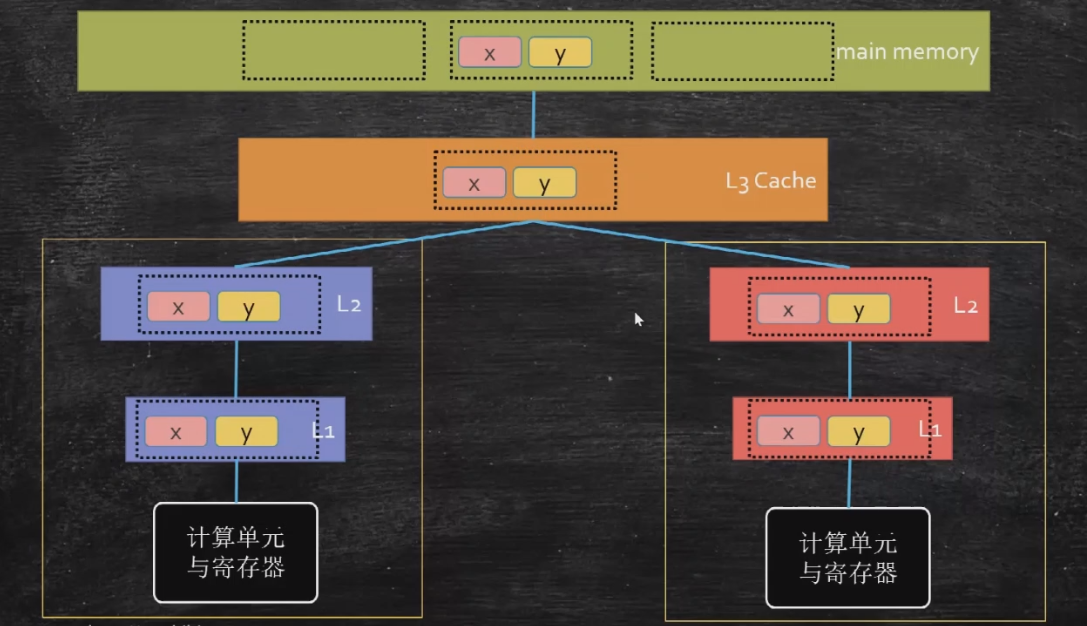
最开始的时候我们就说了,线程和CPU的核,在同一时间点是一一对应的。如上图, X 和 Y 在内存里是挨着的,在多核情况下,或者叫多线程情况下,如果左边的核去获取内存中的数据 X=0,右边的去获取数据 Y=0 ,因为读取数据会将整个缓存行都读回来,所以两个核内的L1、L2缓存里,都会缓存 X 和 Y 的值。
这个时候我们想一下,如果在左边的核里,我们将 X 的值给改成了1,右边的核它不知道啊,右边核的L1、L2里 X 的值还是0,这就会产生数据的不一致,这就是线程的可见性问题。当然即便不考虑缓存行,两个线程同时读写同一个数据,也会有可见性问题。所以一定要有一种机制,一个核将数据修改了,要通知其他核做相应的修改,这个机制我们就叫做缓存一致性协议。缓存一致性协议有好多种,每种CPU不一样,其中最著名的是英特尔的MESI,其他厂商的CPU用的未必是这个。
注意,这是硬件级别的机制,和软件层面无关,和 volatile 无关。以后要是有人和你聊缓存一致性协议,跟 volatile 一起聊,你心里一定要清楚,这事儿是不对的。关于 volatile 关键字,下一章讲有序性的时候再聊。
总结来说,本文要说的可见性问题,就是在多核CPU中,同一个数据存在于多个核内的缓存中,一个CPU核修改了自己内部缓存的数据,其他CPU核内的缓存是否知道的问题。
缓存行填充的编程技巧我们来看个小程序:
public class CacheLine {
static class T {
// long p1, p2, p3, p4, p5, p6, p7;
long x = 0L; // 8 bytes
// long p9, p10, p11, p12, p13, p14, p15;
}
static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws InterruptedException {
CountDownLatch cdl = new CountDownLatch(2);
Thread t0 = new Thread(() -> {
for (long i = 0L; i < 10_0000_0000L; i++) {
arr[0].x = i;
}
cdl.countDown();
});
Thread t1 = new Thread(() -> {
for (long i = 0L; i < 10_0000_0000L; i++) {
arr[1].x = i;
}
cdl.countDown();
});
long nanoTime = System.nanoTime();
t0.start();
t1.start();
cdl.await();
System.out.println((System.nanoTime() - nanoTime) / 1000000);
}
}
我来解释下这个小程序是干什么的,很简单。有个静态内部类 T,其中有一个 long 类型的成员变量 x,占了8个bytes。然后我构建了一个 T 对象的 arr 数组,数组长度是2,数组里面放了两个 T 对象实例,数据准备完毕。现在我起了两个线程,第一个线程将 arr 数组中的第一个 T 对象的成员变量 x 修改10亿次。第二个线程将 arr 数组中的第二个 T 对象的成员变量 x 修改10亿次。然后统计两个线程改完共耗时多久。(注意下此处是两个T对象,也就分别有两个成员变量x,两个线程改的x不是同一个)
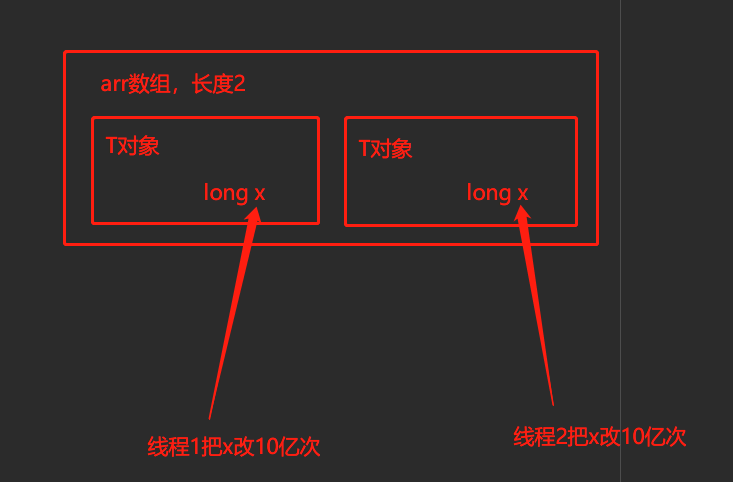
看结果:
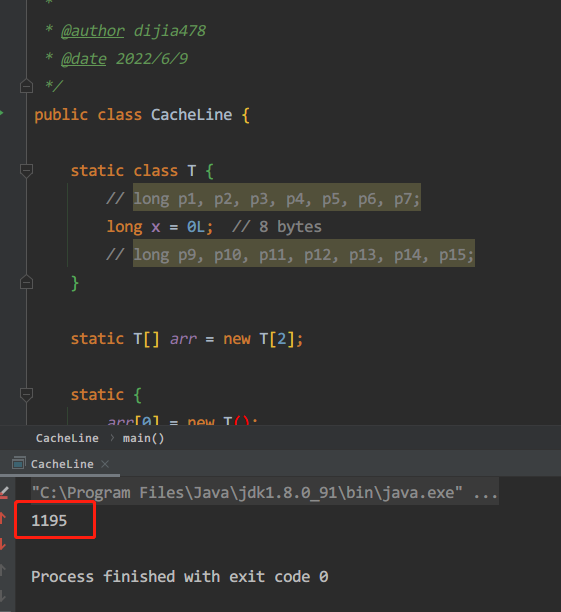
耗时1195毫秒。
现在我们修改下程序,将上面静态内部类 T 中注释掉的那两行代码放开:
static class T {
long p1, p2, p3, p4, p5, p6, p7;
long x = 0L; // 8 bytes
long p9, p10, p11, p12, p13, p14, p15;
}
现在和之前的区别是,之前静态内部类 T 中只有一个 long 类型的成员变量 x,占了8个bytes。现在静态内部类 T 中成员变量 x 前面有7个 long 类型的成员变量,共56个bytes,后面也有7个 long 类型的成员变量,共56个bytes,除此以外没有差别。第二种修改后的情况下,T 对象内部大概是长这样的:

我们再运行一下程序看结果:
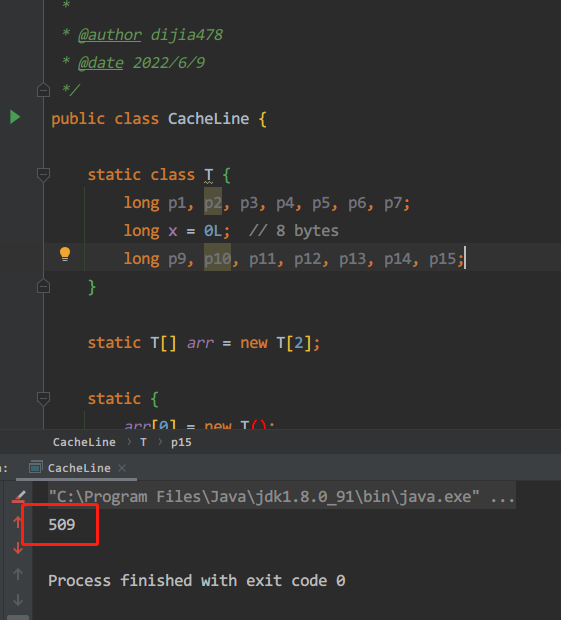
耗时509毫秒!速度居然快了1倍,神奇不。第二种情况只是在 x 前后各放了56个bytes的数据,效率就提高,而没放数据,效率就变低。大家想想这是为什么呢?
我们想一下,在我们前后没放 56 bytes 数据的时候,一个 x 占 8 bytes 空间,数组中有两个 T 对象,那么两个 x 在内存中大概率是挨在一起的。而我们说由于缓存行的存在,一个缓存行是 64 bytes,装两个 8 bytes 肯定没问题,两个 x 也就大概率位于同一个缓存行内。这就意味着,线程1在取其中一个 T1.x 的时候,会将整行数据都读回来,线程2也是同理。两个线程都会将整行数据读到自己的L1、L2缓存中。
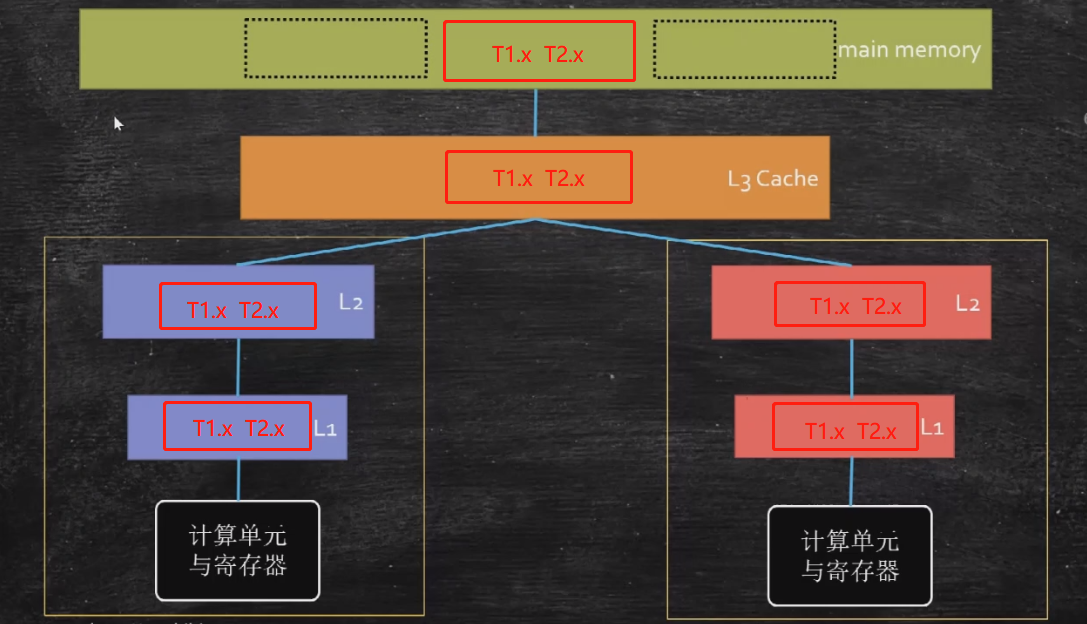
那么线程1在修改 T1.x 的时候,由于缓存一致性协议,就要通知线程2,T1.x 已经被修改了,这肯定需要时间,效率就低了。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这被称之为伪共享。
而当我在 x 的前后各加了 56 bytes 数据时,那么两个 x ,就绝对不会位于同一个缓存行内了。

既然两个 x 不会位于同一个缓存行内,那么两个线程分别修改两个 x ,每个 x 只会在自己线程的缓存内,也就不会有缓存一致性问题,也就不需要互相通知,效率就高了,避免了伪共享导致的性能损耗。这和编程语言没关系,什么语言测试都是如此,因为缓存一致性协议是硬件级别的机制。

问个问题,我要是只在 x 前面加 56 bytes 的数据,后面不加行不行?貌似这样两个 x 也不会在同一缓存行内啊?在这个demo小程序中是可以的,但如果我不是两个 x ,而是一个 x,一个 y 呢?你只在x前面加 56 bytes 数据,y 依然有可能和 x 位于同一缓存行,那一个线程修改 x ,一个线程修改 y ,就还是会有上面的问题了。所以,为了保证任何时候 x 都不会有这种问题,最好是在前后都加上 56 bytes 的数据,就可以保证万无一失。我们把这个编程技巧叫做缓存行填充,主要适用于频繁写的共享数据上。
(题外话,Java8 之前可以给变量前后分别填充7个long类型进行缓存行填充,而 Java 8 中已经提供了官方的解决方案,Java 8 中新增了一个注解: @sun.misc.Contended。加上这个注解的字段会自动补齐缓存行,需要注意的是此注解默认是无效的,需要在 jvm 启动时设置 -XX:-RestrictContended 才会生效。)
肯定有人要说了,这也太底层了太细节了,感觉没必要啊,实际开发中真的有人这么用吗?
有一款开源软件,叫Disruptor,是一个高性能的异步处理框架,能够在无锁的情况下实现队列的并发操作,号称能够在一个线程里每秒处理6百万笔订单,可以说是单机最快的MQ。Disruptor中的一个核心结构,就是环形缓冲区,RingBuffer。我们去看下它的源码:
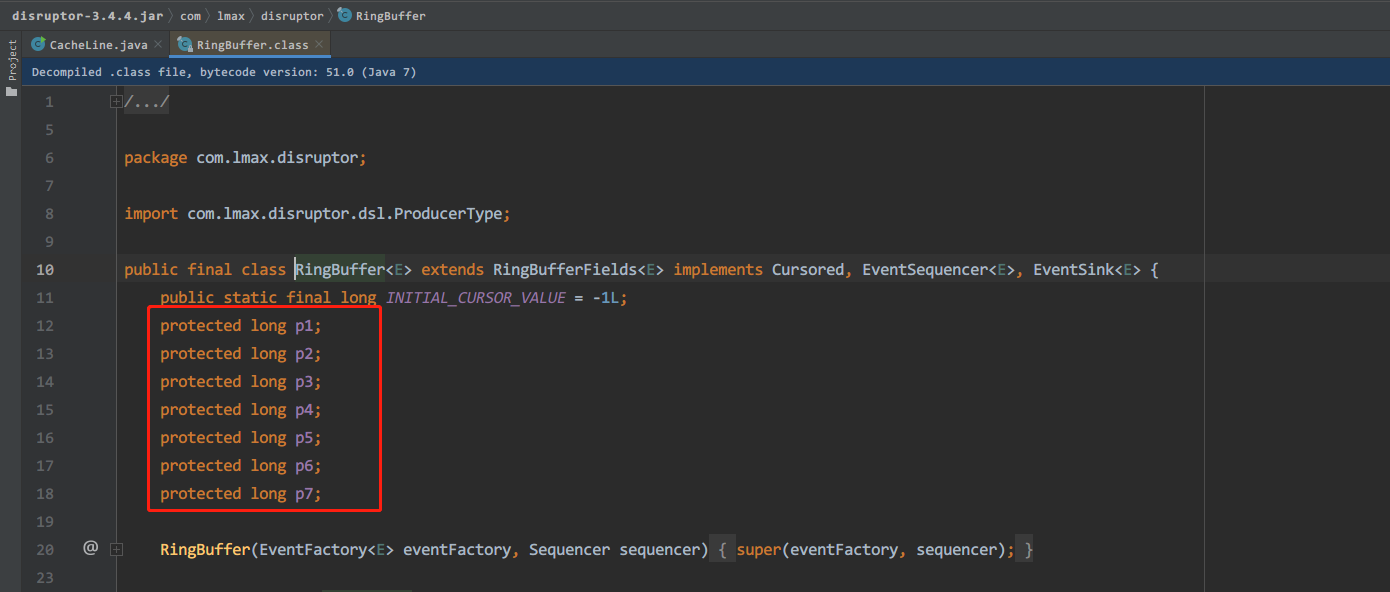
来,看到了什么,知道这7个变量是干啥的吗,如果没有上面的知识,你肯定看不懂,是不是就有人在实际开发中用到了呢。最上面的INITIAL_CURSOR_VALUE变量,就是环形缓冲区的指针起始位置。有人说不对啊,只有后面 56 bytes,没有前面的 56 bytes 呀。别急,这个类叫 RingBuffer ,它的父类叫 RingBufferFields,RingBufferFields 还有个父类叫 RingBufferPad,点进去看看:
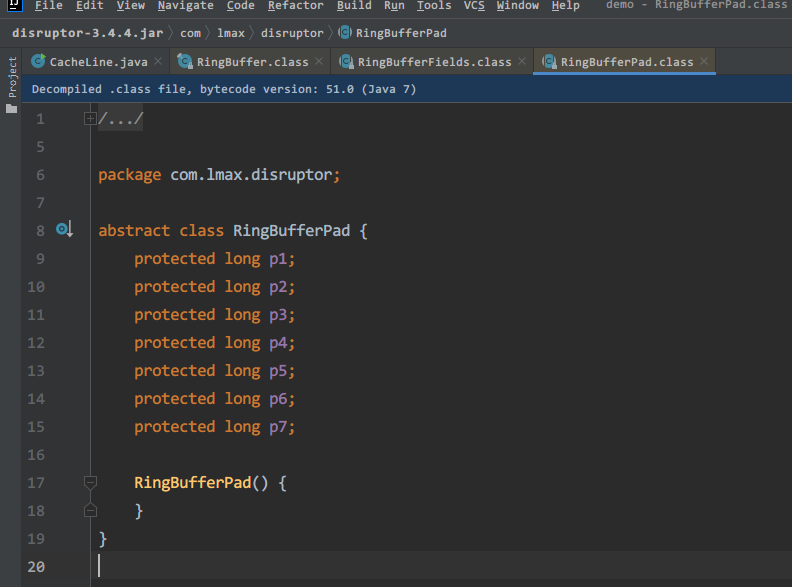
RingBuffer 的爷爷类里,还有7个long类型数据,占了 56 bytes,所以INITIAL_CURSOR_VALUE变量的前面有 56 bytes 数据,后面也有 56 bytes 数据,所以这也是 Disruptor 性能非常高的原因之一。另一个原因是 Disruptor 底层用的是CAS自旋锁,这个这次就不展开了,后面讲原子性的时候再说。