link:https://scholar.google.com.hk/scholar_url?url=https://arxiv.org/pdf/1809.02657&hl=zh-TW&sa=X&ei=bSGfYviOJOOEywThnbSYCQ&scisig=AAGBfm0bzwUuDvjnCXStu1Abuajctfd1xw&oi=scholarr
DTDG
Abstract本文通过循环(在文中表示为LSTM)和稠密(在文中表现为autoencoder)网络学习图中的时间变换。
Conclusion本文介绍了动态网络中用于捕获时间模式的dyngraph2vec模型。它学习了单个节点的进化模式,并提供了一种能够更精确地预测未来链接的嵌入方式。基于具有不同功能的架构,提出了模型的三种变体。实验表明,我们的模型可以在合成数据集和真实数据集上捕捉时间模式,并在链接预测方面优于最先进的方法。未来的研究方向如下:(1)通过扩展模型的可解释性,以更好地理解网络和时间的动态变化(2)自动超参数优化,提高精度;(3)通过图卷积学习节点属性,减少参数数量。
Figure and table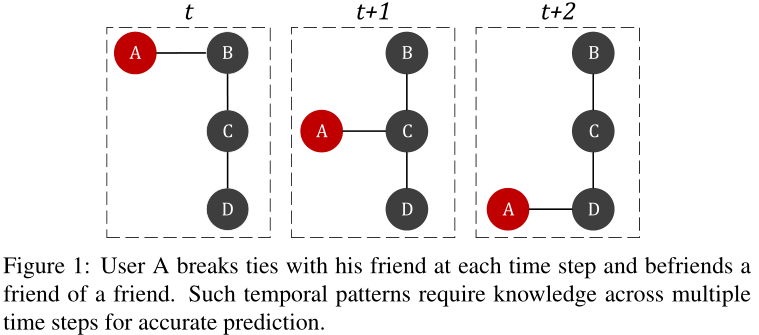
图1 表示用户A在每个时间步下,和上个朋友断交,与朋友的朋友建交(用这个例子说明当A与C建交时,基于静态网络的方法只能观察t + 1时刻的网络,无法确定下一个时间步A是和B还是D成为朋友。相反,观察多个快照可以捕捉网络动态,并高确定性地预测A与D的连接)

图2 不同模型下的社区转移
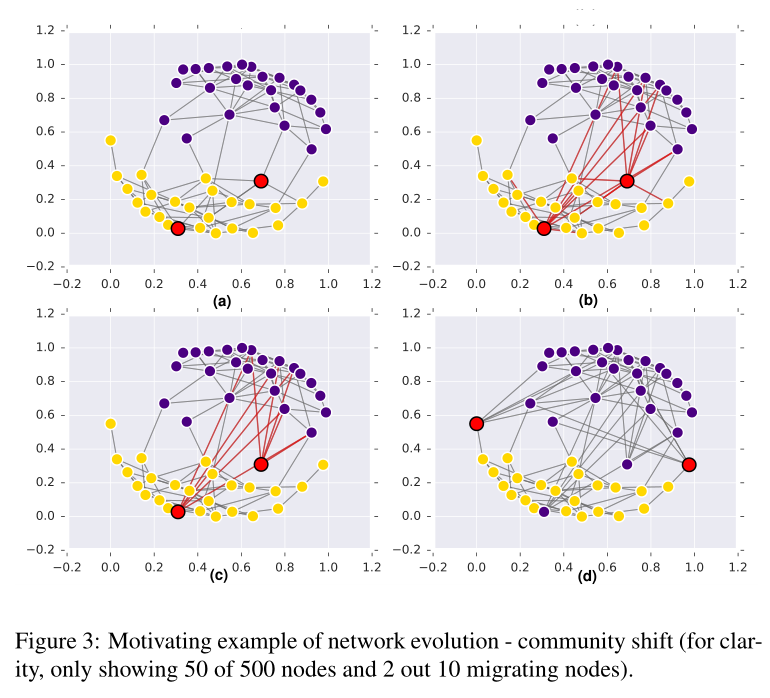
图3 社区转移的具体例子 从500个点中选50个作为样例说明
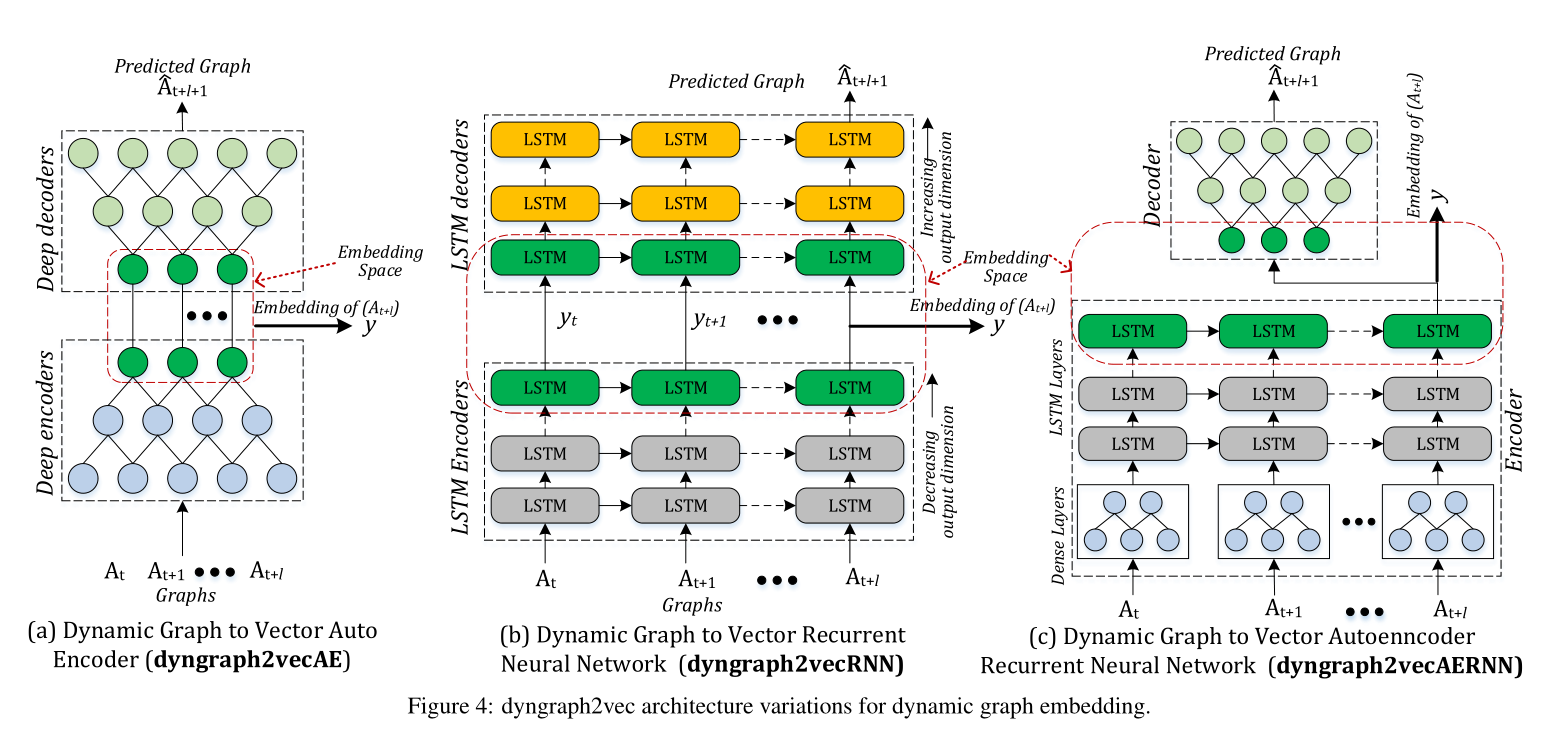
图4 动态图嵌入的Dyngraph2vec模型架构变体。
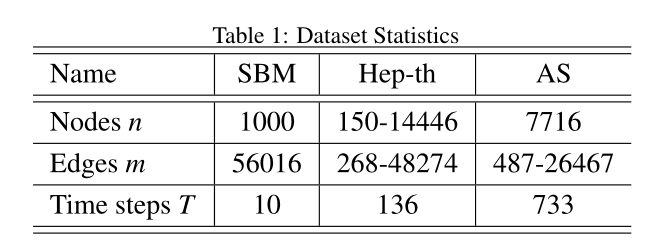
表1 数据集参数
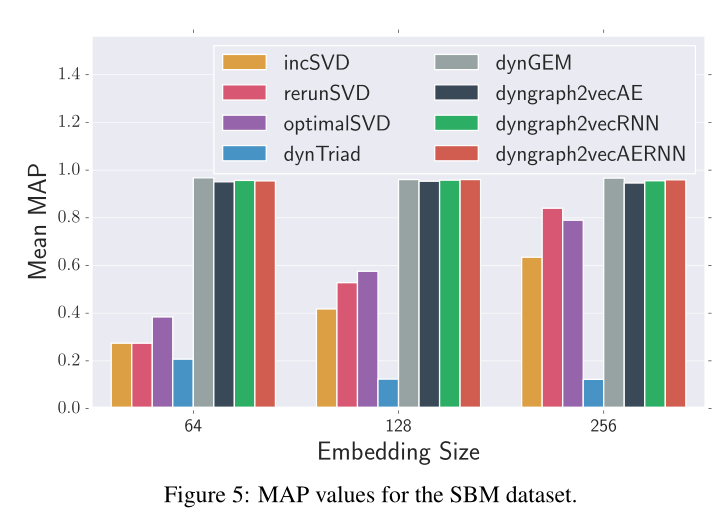
图5 SBM数据集的MAP值。
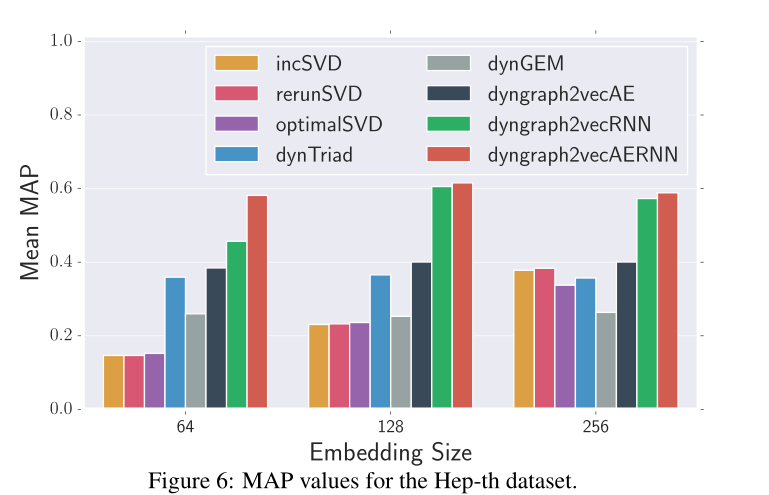
图6 Hep-th数据集的MAP值
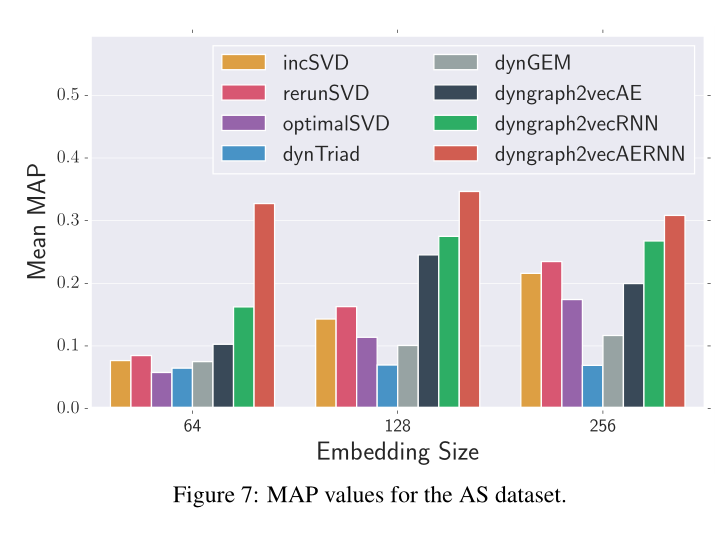
图7 AS数据集的MAP值
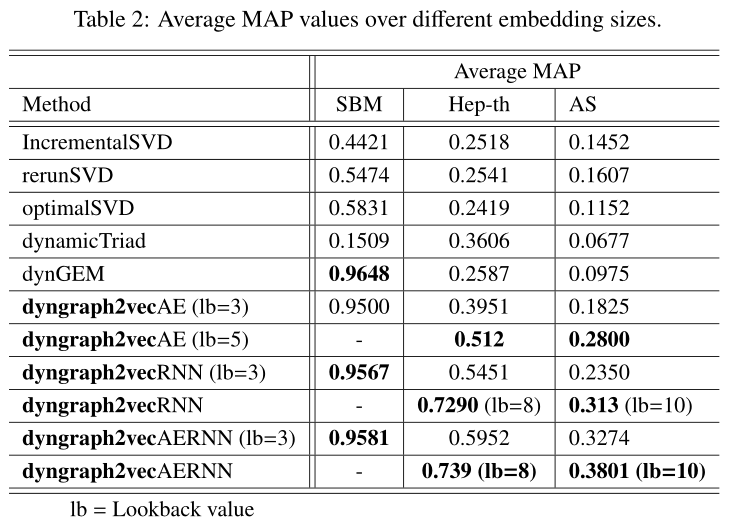
表2 不同嵌入尺寸的平均MAP值
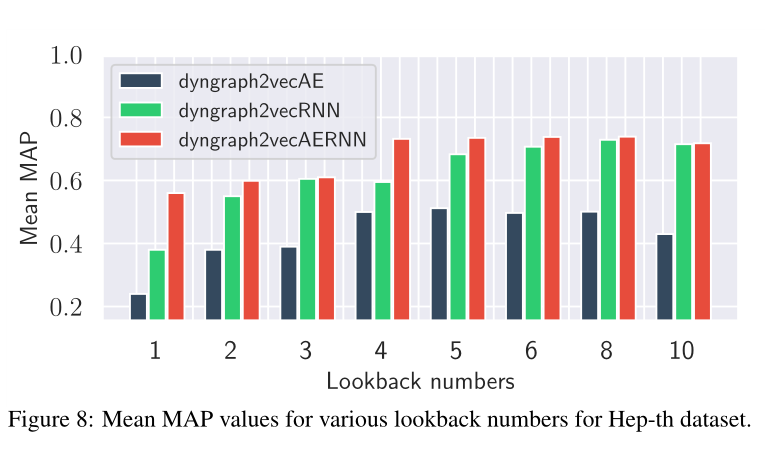
图8 在Hep-th数据集下,各种回看值(由lookback翻译来,下同)的平均MAP值。
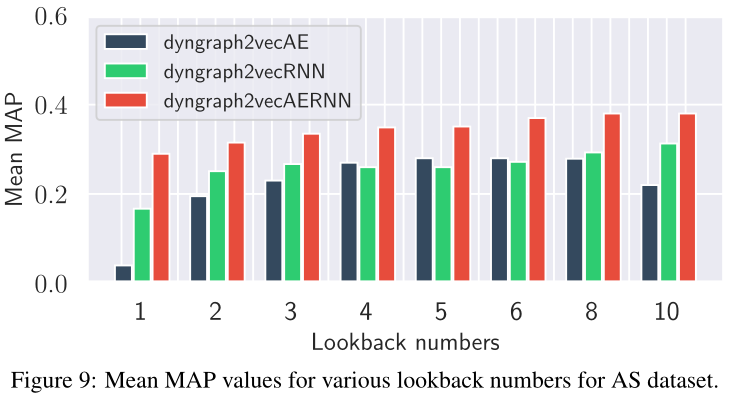
图9 在AS数据集下,各种回看值(由lookback翻译来,下同)的平均MAP值。
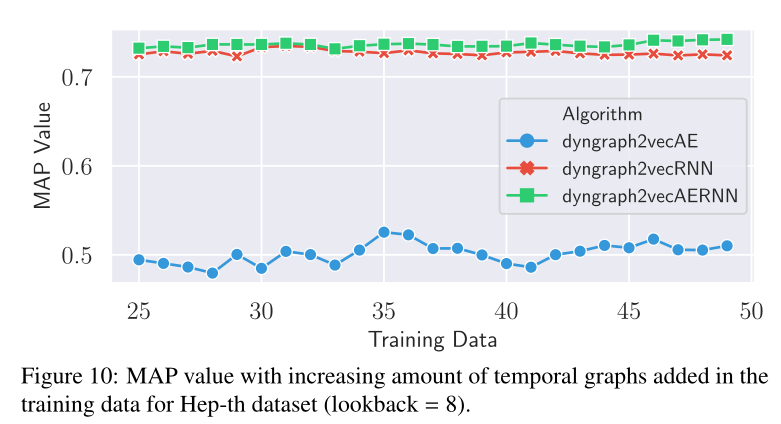
图10 在Hep-th数据集的训练数据中,MAP值随时间图数量(快照数量)的增加而增加
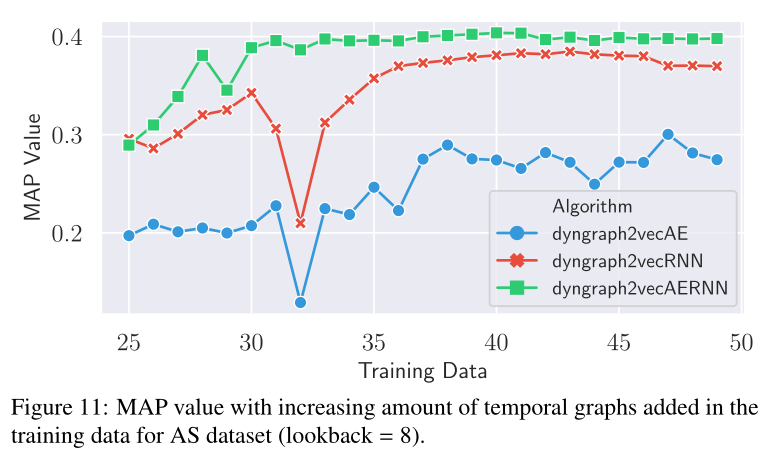
图10 在AS数据集的训练数据中,MAP值随时间图数量(快照数量)的增加
Introduction总结如下
1 静态表示预测能力不如快照下的预测
2 不同的边持续时间不同,DynamicTriad[15]、DynGEM[16]和TIMERS[17]方法假设模式持续时间较短(长度为2)只考虑之前的时间步长图来预测新链接。此外,DynGEM和TIMERS假设变化是平滑的,并使用正则化来禁止快速变化。
3 所以本文提出了Dyngraph2vec,使用多个非线性层来学习每个网络中的结构模式。此外,它利用循环层来学习网络中的时间转换。循环层中的回顾参数控制学习到的时间模式的长度。
本文的4点贡献
1)提出了动态图嵌入模型dyngraph2vec,该模型捕捉时间动态。
2)证明了捕获网络动态可以显著提高链路预测的性能。
3)将展示模型的各种变化,以显示关键的优势和差异。
4)发布了一个库DynamicGEM,实现了dyngraph2vec和最先进的动态嵌入方法的变体
Method 4. Methodology 4.1. Problem Statement对于权重图\(G(V,E)\), \(V\)为顶点集,\(E\)为边集,\(A\)为该图的邻接矩阵,即对于一条边\((i, j)\in E\), \(A_{ij}\)表示其权值,否则\(A_{ij}=0\)。图G的演化记为\(G = \{ G_1,..., G_T \}\),其中\(G_t\)表示图在t时刻的状态。
我们定义我们的问题如下:给定图\(G\)的一个演化\(\mathcal{G}\),目标是通过映射\(f\), 使得图中的节点映射到低位空间中表示为$ { y_{v_1}, . . . y_{v_t}} \(,其中\)y_{v_t}\(表示为节点\)v\(在时间\)t\(的嵌入,具体来说描述为:\)f_t : { V_1, . . . , V_t, E_1, . . . E_t } →R^d\(,\)y_{v_i} = f_i(v_1, . . . , v_i, E_1, . . . E_i)\(,这样\)y_{v_i}\(就能捕捉到预测\)y_{v_{i+1}}$所需的时间模式。换句话说,每个时间步的嵌入函数利用图演化的信息来捕捉网络动态,从而可以更精确地预测链路。
4.2. Dyngraph2vecdyngraph2vec是一个深度学习模型,它将之前的一组图作为输入,并在下一个时间步生成作为输出的图,从而在每个时间步和多个时间步捕获顶点之间高度非线性的相互作用。因为嵌入可以捕获网络的链接时序演化,这使得我们可以去预测链接,模型通过优化以下损失函数学习时间步长t时的网络嵌入:
\[\begin{aligned} L_{t+l} &=\left\|\left(\hat{A}_{t+l+1}-A_{t+l+1}\right) \odot \mathcal{B}\right\|_{F}^{2}, \\ &=\left\|\left(f\left(A_{t}, \ldots, A_{t+l}\right)-A_{t+l+1}\right) \odot \mathcal{B}\right\|_{F}^{2} . \end{aligned}(1) \]\(t+d\)时刻的嵌入是图在\(t,t+1,...,t+l\)时刻的函数,即可写作\(y_{t+l} = f(y_t,y_{t+1},...,y_{t+l})\)(原文这里写的The embedding at time step t+d is a function of the graphs at time steps t, t+1, . . . , t+l where l is the temporal look back)
这里用\(t\)到\(t+l\)时间段的快照来预测\(t+l+1\)的图的情况,\(\mathcal{B}\)作为权重矩阵,给存在的边加权为\(\beta\),即
if (i, j) in E[t+l+1] :
B[i][j] = beta
else:
B[i][j] = beta
其中
\(\beta\)为给定的超参数
\(\odot\)为哈达玛积
基于图4所示的深度学习模型架构,提出了三种模型变体:
(1) dyngraph2vecAE
(2) dyngraph2vecRNN
(3) dyngraph2vecAERNN
三种方法只在映射函数f(.)的表述上有所不同。
如果想把编码器扩展到动态图上使用,一个简单的方法是将关于以前\(l\)个图的快照信息作为输入添加到自动编码器中。
因此,模型dyngraph2vecAE使用多个完全连接的层来对时间内和跨时间的节点互连进行建模。
具体来说,对于节点u的邻居向量集\(u_{1..t} = [a_{u_t}, . . . , a_{u_{t+l}}]\),第一层的隐藏表示为:
\[y_{u_{t}}^{(1)}=f_{a}\left(W_{A E}^{(1)} u_{1 . . t}+b^{(1)}\right)(2) \]其中
\(f_a\)为激活函数
至此我一个一个参数看了一遍,想弄清楚(2)这个式子输入输出的维度,没看懂,他前面说以前\(l\)个图的信息作为输入添加到自动编码器中,在后面实验的分析阶段我看lookback的值\(l\)是大于0的值。也就是说对于上式来说,我想在lookback的值为l的情况下,得到节点u在t时刻的嵌入,我猜测上式的\(u_{1..t}\)应改为\(u_{1..t} = [a_{u_{t-l}}, . . . , a_{u_{t}}]\)(下面的dyngraph2vecRNN和dyngraph2vecAERNN也一样),总不能为了得到\(t\)时刻的嵌入去输入\(t\)到\(t+l\)时刻的状态吧,
(作者原话: 所以我我感觉这个地方应该是他写错了)
所以我我感觉这个地方应该是他写错了)
其中\(a_{u_{t}}\)表示为在\(t\)时刻节点\(u\)的邻接向量,\(a_{u_t} \in \mathbb{R}^n\)
所以这里有几个维度,邻接向量的\(n\)即为\(n\)个节点,回顾值的\(l\),输出维度\(d^{(1)}\),所以\(W_{A E}^{(1)} \in \mathbb{R}^{d^{(1)} \times n l}\)
定义第k层的表示为
\[y_{u_{t}}^{(k)}=f_{a}\left(W_{A E}^{(k)} y_{u_{t}}^{(k-1)}+b^{(k)}\right)(3) \]为了减少模型参数的数量(\(k*n*l*d^{(1)}\)),实现更有效的时序学习,提出了dyngraph2vecRNN和dyngraph2vecAERNN。
dyngraph2vecRNN中引入LSTM的结构,公式模型如下
贴一下知乎大佬关于lstm的解释:https://zhuanlan.zhihu.com/p/463363474
\[\begin{aligned} y_{u_{t}}^{(1)} &=o_{u_{t}}^{(1)} * \tanh \left(C_{u_{t}}^{(1)}\right) \\ o_{u_{t}}^{(1)} &=\sigma_{u_{t}}\left(W_{R N N}^{(1)}\left[y_{u_{t-1}}^{(1)}, u_{1 . . t}\right]+b_{o}^{(1)}\right) \\ C_{u_{t}}^{(1)} &=f_{u_{t}}^{(1)} * C_{u_{t-1}}^{(1)}+i_{u_{t}}^{(1)} * \tilde{C}_{u_{t}}^{(1)} \\ \tilde{C}_{u_{t}}^{(1)} &=\tanh \left(W_{C}^{(1)} \cdot\left[y_{u_{t-1}}^{(1)}, u_{1 . . t}+b_{c}^{(1)}\right]\right) \\ i_{u_{t}}^{(1)} &=\sigma\left(W_{i}^{(1)} \cdot\left[y_{u_{t-1}}^{(1)}, u_{1 . t}\right]+b_{i}^{(1)}\right) \\ f_{u_{t}}^{(1)} &=\sigma\left(W_{f}^{(1)} \cdot\left[y_{u_{t-1}}^{(1)}, u_{1 . . t}+b_{f}^{(1)}\right]\right) \end{aligned} \]其中
\(C_{u_{t}}\)表示为单元记忆存储(cell memory&cell states)
\(f_{u_{t}}\)表示为遗忘门阈值
\(o_{u_{t}}^{(1)}\)表示为输出门阈值
\(i_{u_{t}}^{(1)}\)表示更新门的阈值
\(\tilde{C}_{u_{t}}^{(1)}\)当前时刻的新信息(candidate values)有哪些需要添加到cell states
\(b\)为偏置项
在第一层链接\(l\)个LSTM将\(C_{u_{t}}\)和嵌入以链式的形式从\(t−l\)传递到\(t\)时刻的LSTM那么第\(k\)层的表示如下:
\[\begin{array}{l} y_{u_{t}}^{(k)}=o_{u_{t}}^{(k)} * \tanh \left(C_{u_{t}}^{(k)}\right) \\ o_{u_{t}}^{(k)}=\sigma_{u_{t}}\left(W_{R N N}^{(k)}\left[y_{u_{t-1}}^{(k)}, y_{u_{t}}^{(k-1)}\right]+b_{o}^{(k)}\right) \end{array} \]能看到,如果直接用lstm的架构,但节点u的邻居是一个稀疏向量,就会导致参数量变大,所以作者提出dyngraph2vecAERNN,利用autoencoder去降维表示后再过lstm去做时序的信息捕捉,可写为
\[y_{u_{t}}^{(p)}=f_{a}\left(W_{A E R N N}^{(p)} y_{u_{t}}^{(p-1)}+b^{(p)}\right) \]其中p为全连接编码器的输出层。然后将这个表示传递给LSTM网络
\[\begin{array}{l} y_{u_{t}}^{(p+1)}=o_{u_{t}}^{(p+1)} * \tanh \left(C_{u_{t}}^{(p+1)}\right) \\ o_{u_{t}}^{(p+1)}=\sigma_{u_{t}}\left(W_{A E R N N}^{(p+1)}\left[y_{u_{t-1}}^{(p+1)}, y_{u_{t}}^{(p)}\right]+b_{o}^{(p+1)}\right) \end{array} \]然后将LSTM网络生成的隐藏表示传递给全连接解码器。
4.3 Optimization使用随机梯度下降和(Adam)对模型进行优化。
Experiment 5. Experiments 5.1 Datasets数据集
5.2 baselineOptimal Singular Value Decomposition (OptimalSVD):
Incremental Singular Value Decomposition (IncSVD):
Rerun Singular Value Decomposition (RerunSVD or TIMERS):
Dynamic Embedding using Dynamic Triad Closure Process(dynamicTriad) :
Deep Embedding Method for Dynamic Graphs(dynGEM) :
5.3. Evaluation Metrics
在我们的实验中,我们通过使用时间步长t之前的所有图来评估我们的模型在时间步长t + 1的链路预测。评估方法为MAP
6.Results and Analysissota情况见图5,6,7
超参数(lookback value and length of training sequence)影响见图8,9,10,11
Summary读下来感觉下标和参数解释不太清楚,尤其是对于时序下标的编写,读起来要比较费劲甚至去猜作者什么意思,这篇论文告诉我在问题定义小节应该尽可能的把除了模型的其他参数解释明白(比如对邻居集的定义)。再回过来说模型,autoencoder+lstm的组合效果看起来还不错,感觉算是一种处理非欧时序结构的基础模型。