文章目录 re模块使用 finditer 举个例子 fullmatch 举个例子 match 举个例子 search 举个例子 re模块使用 findi
文章目录
- re模块使用
- finditer
- 举个例子
- fullmatch
- 举个例子
- match
- 举个例子
- search
- 举个例子
re模块使用
finditer
re.finditer(pattern,string,flags = 0)功能: 根据正则表达式匹配目标字符串内容
参数: pattern 正则表达式
string 目标字符串
flags 功能标志位,扩展正则表达式的匹配
返回值: 匹配结果的迭代器,注意是迭代器,不是被迭代对象!
举个例子
代码1: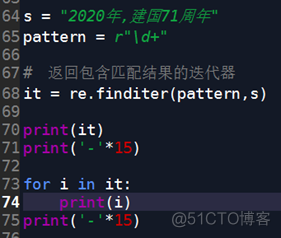
输出结果1: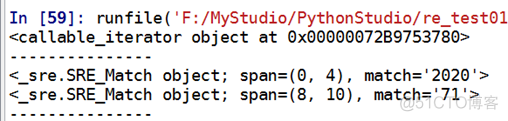
由以上结果可知,我们迭代出来的两个元素是对象,那么这个对象是啥呢?这个对象就是match对象,它是对匹配结果的一种表达。
我们看一下示意图: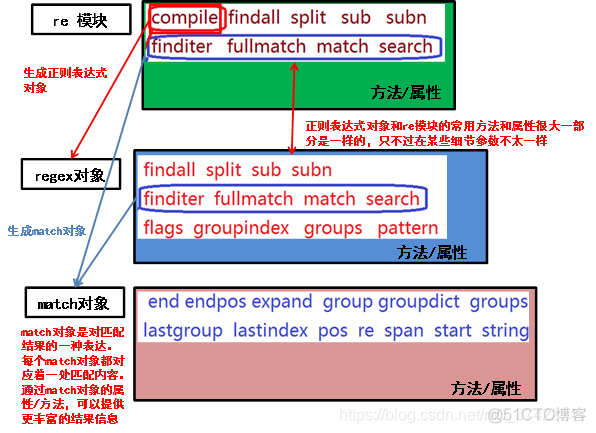
这里,我们利用match对象的group方法,取出结果。
代码2(使用for循环):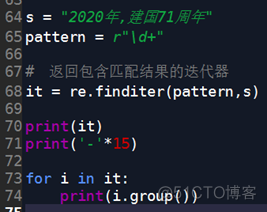
输出结果2: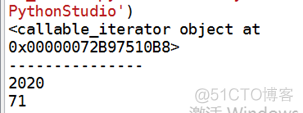
代码3(使用__next__()):
输出结果3: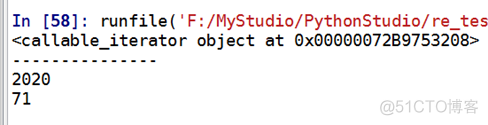
fullmatch
re.fullmatch(pattern,string,flags=0)功能:完全匹配某个目标字符串
参数:pattern 正则
string 目标字符串
返回值:匹配内容match object
备注:完全匹配意思是指正则表达式必须将目标字符串的全部字符匹配出来,如果不能匹配全部字符,则就算没有匹配到。换句话说。当我们使用完全匹配时,就相当于人为的在正则表达式之前加^, 之后加$.
举个例子
代码1(未完全匹配到):
输出结果1:
没有完全匹配到,就会报错。
代码2(完全匹配到了):
输出结果2: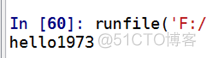
match
re.match(pattern,string,flags=0)功能:匹配某个目标字符串开始位置
参数:pattern 正则
string 目标字符串
返回值:匹配内容match object
举个例子
代码:
我们想匹配,以大写字母开头的单词,且从字符串的开始位置进行匹配。
输出结果: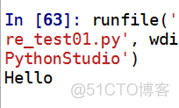
嗯!果然匹配结果只有Hello.
search
re.search(pattern,string,flags=0)功能:匹配目标字符串第一个符合内容(即只能匹配一处)
参数:pattern 正则
string 目标字符串
返回值:匹配内容match object
举个例子
代码:
结果:
嗯!只匹配了第一个符合要求的内容,就不进行匹配了。