学习笔记
开发工具:Spyder
文章目录
- 封装
- 定义
- 私有成员
- 举个例子1
- 举个例子2
- 举个例子3
- `__slots__`属性
- 属性`@property`
- 案例(可读、可写)
- 发现问题
封装
定义
- 从数据角度来说
封装是将一些基本数据类型复合成一个自定义类型,即将数据与对数据的操作封装起来。
- 从行为角度讲
封装是向类外提供功能,隐藏实现的细节;将复杂的东西藏起来,只给别人提供一种调用。
- 从设计的角度讲
①分而治之
将一个大的需求分为许多类,每个类处理一个独立的功能。
拆分的好处:便于分工,便于复用,可扩展性强。
②封装变化
对变化的地方(行为上的变化点)独立封装(独立的放到一个类中),避免影响其他类。
③高内聚
类中各个方法都在完成一项任务(单一职责的类),即一个类可以有多个方法,每个方法都在做一个小功能,但是这些小功能都是在做同一项任务
④低耦合
类与类的关联性与依赖性要低(每个类独立),即当一个类改变时,对其他类的影响要尽量低。
(最好的低耦合是:一个类被抛弃,其他的类不受其影响)
备注1:最高的内聚,莫过于类中仅包含1个方法,但是将会导致高内聚高耦合。最低的耦合,莫过于类中包含所有方法,但是将会导致低内聚低耦合。
备注2:举个例子,电脑硬件(鼠标、键盘、内存条…)就具有高度集成化(高内聚),又可插拔(低耦合)的特点。
私有成员
- 作用
私有成员为无需向类外提供访问的成员,可以通过私有化对成员进行屏蔽。但是在python中,并不是真正的实现了屏蔽,这只是一种障眼法(解释器会改变双下划线开头的变量名),我们可以通过【_类名__成员名】对私有成员进行访问。
- 做法
在想要被私有的成员开头,加上双下划线【__】。
举个例子1
代码:
class Bunny:def __init__(self, name = "", age = 0):
self.name = name
self.__age = age
w01 = Bunny()
print(w01.__age)
结果: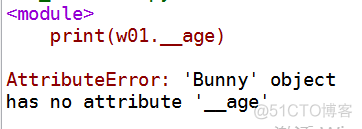
报错!由报错信息可知,并不存在变量【__age】,这是因为解释器改变了【__age】的变量名。
举个例子2
代码:
class Bunny:def __init__(self, name = "", age = 0):
self.name = name
self.__age = age
w01 = Bunny()
print(w01._Bunny__age)
print(w01.__dict__)
结果:
举个例子3
我们再举一个例子,不仅实现成员的私有,而且在创建实例对象时,对参数进行判断。
代码:
class Bunny:def __init__(self, name, age):
self.set_name(name)
self.set_age(age)
def set_name(self, value):
self.__name = value
def get_name(self):
return self.__name
def set_age(self, value):
if 0<= value < 7:
self.__age = value
else:
self.__age = 0
print("输入错误")
def get_age(self):
return self.__age
b01 = Bunny("大白", 5)
b01.set_name("小黄")
b01.set_age(10)
b01.set_age(4)
print(b01.get_name())
print(b01.get_age())
结果:
__slots__属性
- 作用
限定一个类创建的实例,只能有固定的实例变量,不能再额外添加。
- 语法
- 说明
含有__slots__属性的类所创建的对象没有__dict__属性, 即此实例不用字典来存储对象的实例属性。
- 优缺点
优点:访止用户因错写属性的名称而发生程序错误。
缺点:丧失了动态语言可以在运行时为对象添加变量的灵活性。
- 例子(不使用__slots__)
代码:
class Bunny:def __init__(self, name, age):
self.name = name
self.age = age
w01 = Bunny("小黄", 6)
w01.sex = "公"
print(w01.__dict__)
结果:
- 例子(使用__slots__将实例变量数固定)
代码:
class Bunny:__slots__ = ("name", "age")
def __init__(self, name, age):
self.name = name
self.age = age
w01 = Bunny("小黄", 6)
w01.sex = "公"
结果:
由结果可知可知,当我们自己多增加一个实例变量时,报错了,python提示我们,Bunny类中没有属性sex.
属性@property
- 定义及调用

- 说明
①通过两个公开的属性,保护一个私有的变量。
②@property负责读取,@属性名.setter负责写入
案例(可读、可写)
在做这个案例之前我们先回顾一个知识点:
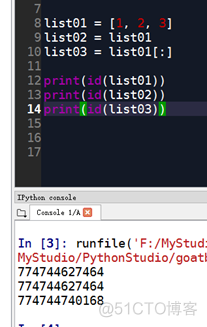
代码第9行:若直接将list01赋值给list02,则list02得到的是list01所指的对象的地址。
代码第10行:若将list01[:]赋值给list03,则list03得到的是list01新创建的对象的地址。
若每次通过切片返回新对象(即第10行的操作),都会另外开辟空间,创建新对象,占用过多内存。
我们看以下代码:
class Bunny:def __init__(self, name):
self.name = name
self.__foods = []
self.__weight = 7
def name(self):
return self.__name
.setter
def name(self, value):
self.__name = value
def weight(self):
return self.__weight
b01 = Bunny("小白")
print(b01.name, b01.weight)
结果:
在代码中,我们设置变量name为可读可写,而变量weight设置为只读(即只可读取不可以更改),如果我们试图更改weight则会报错。
发现问题
备注:我发现在可读可写的情况下(如变量name),在__init__()方法中,变量(name)前可以不加双下划线,即可以写成【self.name = name】,而只读情况下(如变量weight),在__init__()方法中,变量(weight)前要加双下划线,即可以写成【self.__weight = 7】,若不加双下划线则会报错【AttributeError: can’t set attribute】。这是为啥呢?
比如:
代码1:
class Bunny:#__slots__ = ("__name", "__weight")
def __init__(self, name):
self.name = name
self.weight = 7
def name(self):
return self.__name
.setter
def name(self, value):
self.__name = value
def weight(self):
return self.__weight
b01 = Bunny("小白")
print(b01.name, b01.weight)
结果1: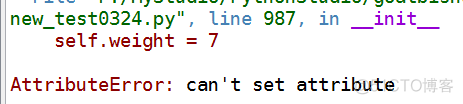
代码2:
class Bunny:#__slots__ = ("__name", "__weight")
def __init__(self, name):
self.name = name
self.__weight = 7
def name(self):
return self.__name
.setter
def name(self, value):
self.__name = value
def weight(self):
return self.__weight
b01 = Bunny("小白")
print(b01.name, b01.weight)
结果2: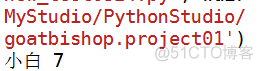
代码3:
class Bunny:#__slots__ = ("__name", "__weight")
def __init__(self, name):
self.name = name
self.weight = 7
def name(self):
return self.__name
.setter
def name(self, value):
self.__name = value
def weight(self):
return self.__weight
.setter
def weight(self, value):
self.__weight = value
b01 = Bunny("小白")
print(b01.name, b01.weight)
结果3:
我们改一下weight试试:
代码:
class Bunny:def __init__(self, name):
self.name = name
self.__foods = []
self.__weight = 7
def name(self):
return self.__name
.setter
def name(self, value):
self.__name = value
def weight(self):
return self.__weight
b01 = Bunny("小白")
b01.weight = 10
结果: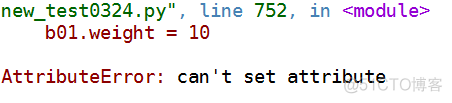
报错了!
接下来,我们把foods设置为只读,并试着更改一下foods:
class Bunny:def __init__(self, name):
self.name = name
self.__foods = ["提草", "兔粮"]
self.__weight = 7
def name(self):
return self.__name
.setter
def name(self, value):
self.__name = value
def weight(self):
return self.__weight
def foods(self):
return self.__foods
b01 = Bunny("小白")
b01.foods = ["提草", "兔粮", "白菜"]
结果: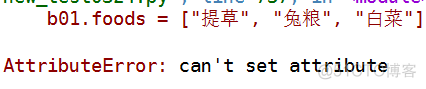
嗯!报错了。
但在只读情况下真的不可以更改么?我们看一下以下这段代码:
class Bunny:def __init__(self, name):
self.name = name
self.__foods = ["提草", "兔粮"]
self.__weight = 7
def name(self):
return self.__name
.setter
def name(self, value):
self.__name = value
def weight(self):
return self.__weight
def foods(self):
return self.__foods
b01 = Bunny("小白")
b01.foods.append("白菜")
print(b01.name, b01.weight, b01.foods)
结果:

惊!不仅没有报错,而且真的修改了b01.foods所关联的列表。
我们画一个简易内存图来解释一下:
①当执行【b01 = Bunny("小白")】时: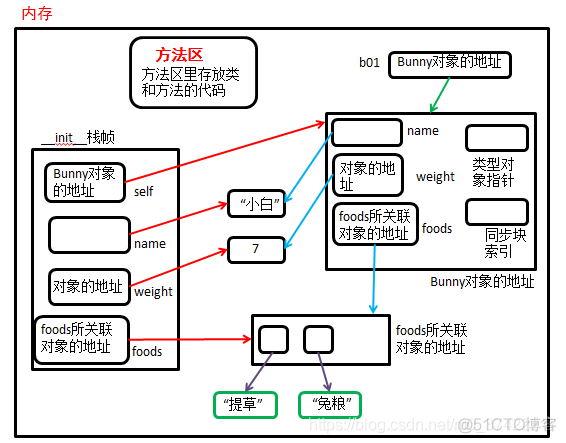
②当执行【b01.foods.append("白菜")】时,【b01.foods】返回了【self.__foods】,【self.__foods】提供了可变对象的地址(foods关联的是列表对象,列表是可变类型),通过地址,我们找到了列表对象,并对列表对象进行修改。但是在Bunny实例对象内部,存放的foods所关联对象的地址没有变,改变的只是列表对象本身,这种情况满足只读属性的性质: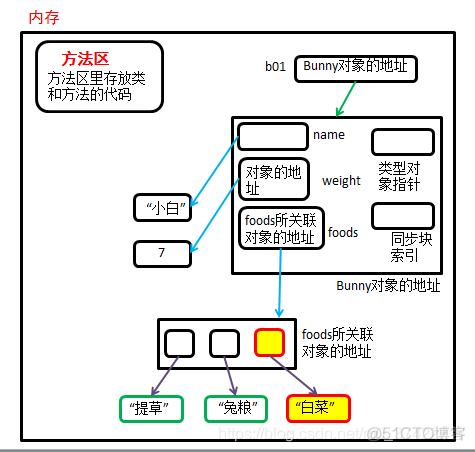
但是如果直接用【b01.foods = ["提草", "兔粮", "白菜"]】的方式对变量foods进行更改,则在内存中会创建新的列表对象,Bunny实例对象内部所存储的foods所关联对象的地址则会改变,则不满足只读属性的性质。
但如果我们再更改一下代码,返回foods列表的切片:
class Bunny:def __init__(self, name):
self.name = name
self.__foods = ["提草", "兔粮"]
self.__weight = 7
def name(self):
return self.__name
.setter
def name(self, value):
self.__name = value
def weight(self):
return self.__weight
def foods(self):
return self.__foods[:]
b01 = Bunny("小白")
b01.foods.append("白菜")
print(b01.name, b01.weight, b01.foods)
结果: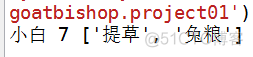
由结果可知,b01.foods并没有被更改。这是为啥呢?
这是因为我们在执行【b01.foods.append("白菜")】时,【b01.foods】返回的是【self.__foods[:]】,也就是说,返回了【self.__foods】的切片,即返回了一个新创建的列表对象的地址。则,我们通过这个新地址找到的新列表对象,并不是【self.__foods】所关联的列表对象,所以就无法对b01.foods所关联的原列表对象进行修改。