鄙人学习笔记
开发工具:Spyder
文章目录
- 生成器generator
- 生成器函数
- 举个例子1(迭代器-->过渡-->生成器)
- 举个例子2
- 内置生成器
- 举个例子1
- 举个例子2
- 枚举函数enumerate
- zip
- 生成器表达式
- 举个例子1
- 举个例子2
生成器generator
- 定义
能够动态(循环一次计算一次返回一次)提供数据的可迭代对象。
- 作用
在循环过程中,按照某种算法推算数据,不必创建容器,存储完整的结果,从而节省内存空间。数据量越大,优势越明显。
备注:以上生成器的操作,也称为惰性操作/延迟操作,通俗的讲就是在需要的时候才计算结果,而不是一次构建出所有结果。
生成器函数
- 定义
生成器函数是含有yield语句的函数,生成器函数的返回值为生成器对象。只要我们的函数中有yield,那么这个函数就是生成器函数。
- 语法
创建生成器函数:
def 生成器函数名():...
yield 数据
...
调用生成器函数:
my_iter = 生成器函数名()for 变量名 in my_iter:
语句
- 说明
①调用生成器函数将返回一个生成器对象my_iter时,不执行生成器函数体。在for循环内,调用__next__()方法时,才执行函数体。
②yield翻译为”产生”或”生成”。
举个例子1(迭代器–>过渡–>生成器)
我们看一下,下面几行代码:

- 运行说明
首先,当程序执行第24行代码,即调用生成器函数my_range()时,它不会去执行my_range()函数体里的内容,而是先返回给变量iter01一个生成器对象,之后程序会继续向下执行for循环语句:
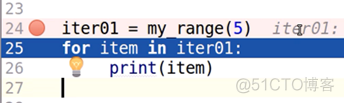
当执行第25行语句时,for循环内部调用了__next__()方法,这时才开始执行my_range()函数体里的内容: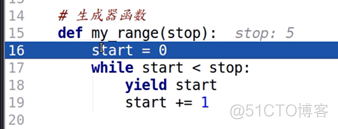
当执行到yield语句时,程序又返回了,程序将yield右边的start作为__next__()方法的返回值,给了变量item:


之后的程序运行内容,不言而喻。就不一一赘述了,有机会可以自己在python里,断点调试,观察一下~
举个例子2
我想在列表[1, 2, 5, 4, 6, 7, 9]中选出所有偶数,并且通过生成器函数来实现。
创建生成器函数:
def get_even(target):for item in target:
if item % 2 == 0:
yield item
备用1:我们每次写生成器函数时,都要思考yield要返回什么内容.
备用2:我们什么时候使用生成器函数呢?在我们的方法/函数需要向外返回多个结果时,可以使用生成器函数.
调用生成器函数:
list01 = [1, 2, 5, 4, 6, 7, 9]iter01 = get_even(list01)
for item in iter01:
print(item)
结果:
我们其实不用生成器函数,也可以拿到这个结果,比如以下代码。
创建函数:
def get_even01(target):result = []
for item in target:
if item %2 == 0:
result.append(item)
return result
调用函数:
list01 = [1, 2, 5, 4, 6, 7, 9]iter01 = get_even01(list01)
for item in iter01:
print(item)
结果: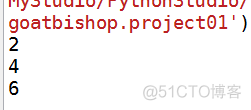
这个结果,同上面利用生成器函数,得到的结果一样。
那么我们为啥要用生成器函数呢?他的优势是啥呢?
因为,如果调用get_even01()方法,则会执行get_even01()方法体,将所有结果存在内存中。但是,如果调用生成器函数get_even(), 则不会执行方法体,在内存中不会存储数据。我们用for循环,循环一次,也就是__next__()一次,计算一次,返回一次。即,需要一次,做一次。这种生成器函数的操作就叫做:惰性操作/延迟操作。
所以,在数据量非常大的情况下,如果不用生成器函数进行操作,则,我们的内存很快就会被占满。
内置生成器
我们先举两个例子。
举个例子1
我们看一段代码:

结果: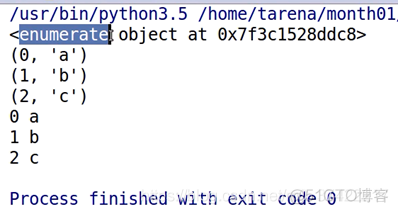
我们再写一个自定义函数my_enumerate,具有和上述例子中,enumerate函数所演示出来的相同的功能:

for循环测试一下:

结果:
嗯!一毛一样~
举个例子2
我们再看一段代码:
list01 = [0, 6, 7]list02 = ["小白", "小黄", "大白"]
for item in zip(list01, list02):
print(item)
结果:
若我们在列表list02中再加一个元素,使两个列表元素不相同: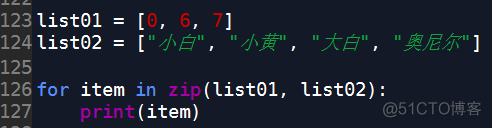
结果:

我们再写一个自定义函数my_zip,具有和上述例子中,zip函数所演示出来的相同的功能(不考虑两个列表元素不相同的情况):
for index in range(len(list01)):
yield (list01[index], list02[index])
for循环测试一下:
list01 = [0, 6, 7]list02 = ["小白", "小黄", "大白"]
for item in my_zip(list01, list02):
print(item)
结果:
注意:我们称这种必须由__next__()驱动的函数(enumerate() / zip()),叫做内置生成器。
枚举函数enumerate
- 语法
语句
for 索引, 元素 in enumerate(可迭代对象):
语句
- 作用
遍历可迭代对象时,可以将索引与元素组合为一个元组。
zip
- 语法
语句
- 作用
将多个可迭代对象中对应的元素组合成一个个元组,生成的元组个数由元素数量最小的可迭代对象决定。
生成器表达式
- 定义
用推导式形式创建生成器对象。
- 语法
举个例子1
如果我们有一个列表list01=[2,3,4,6], 如下图所示:
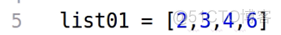
我们想得到列表内的每个元素的平方,该咋整呢?
方式1:

方式2(列表推导式):

我们print一下result得到结果: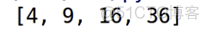
备注1:方式1的代码是列表推导式的传统写法。
备注2:对于推导式,我们还学习了字典推到式,集合推导式。但是没有元组推导式,这是为什么捏?这是因为,列表、字典、集合都是可变对象,可以不断增加元素。而元组是不可变的。
我们再写一段代码:
这个可不是”元组推导式”(压根没有元组推导式),这是生成器表达式。
这时,我们再print一下result: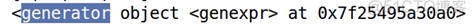
得到一个生成器对象。生成器的本质是一个惰性查找机制,要调用它,就要用__next__(), 也就是可以用for循环:
得到结果:
我们可以写一个与这个生成器表达式功能相同的生成器函数: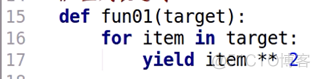
for循环:
得到结果:
嗯!与利用生成器表达式运行的结果相同。
这时候我们就想问:列表推导式和生成器表达式有啥区别?这个问题就相当于问:列表推导式的传统写法与生成器函数有啥不同?
答:区别就是列表推导式的传统写法会用一个列表result存储所有结论,占用内存。而生成器函数是惰性操作,被调用一次__next__(), 才会计算并返回一次。
举个例子2
分别使用列表推导式和生成器表达式,获取列表[2, 3, 4, 5, 6]中,大于3的数据。
代码:
list01 = [2, 3, 4, 5, 6]result01 = [item for item in list01 if item > 3]
result02 = (item for item in list01 if item > 3)
for item in result01:
print(item)
print("---------")
for item in result02:
print(item)
结果:
备注:别看列表推导式和生成器表达式的代码极其相似,但是他们内部却大有不同,【result01 = [item for item in list01 if item > 3]】是执行所有操作,保存所有结果;【result02 = (item for item in list01 if item > 3】是返回了一个生成器对象 。我们也可以通过断点调试,去加深理解。