学习笔记
编辑器:Sublime
PS:因为爬虫接触Xpath,由于HTML的语法和XML很类似,所以这里想把Xpath都应用在HTML中。注意,这里我们用python进行分析,会使用lxml模块。
注意:这里的理论部分是关于XML文档的,但是介于HTML和XML的相似性,大家可以自行做类比,有的地方我也会用HTML和XML做类比。
文章目录
- Xpath简介
- Node节点
- 节点之间的关系
- 节点的类型
- 节点的名字与值
Xpath简介
Xpath语言的核心是给出用于从XML文档中查找标记的语法规则,即编写Xpath路径表达式,以便使应用程序更加方便、快捷地从XML文件中检索到所需要的的数据。
- Xpath路径表达式
一个Xpath路径表达式,简称Xpath表达式,由若干"定位步"所构成。Xpath路径表达式的核心是给出一个匹配XML文件中标记的模式,也可以说Xpath路径表达式的核心是满足一定条件的标记所组成的集合。
这里我们结合一个简单的HTML文档,来了解一下Xpath路径表达式:
<!DOCTYPE html><html lang="en">
<head>
<meta charset="UTF-8">
<title>title</title>
</head>
<body>
<div class="animal">
<p class="name">
<a title="Tiger"></a>
</p>
<p class="content">
Two tigers two tigers run fast
</p>
</div>
<div class="animal">
<p class="name">
<a title="Rabbit"></a>
</p>
<p class="content">
Small white rabbit white and white
</p>
</div>
</body>
</html>
Xpath路径表达式:
/html/body/div[1]/following::div/p/a/@title这个表达式是啥意思呢?注意!!它表示:返回test10.html文件中html根标记下,body子节点的第一个div子节点的div弟节点中,p子节点的a子节点的属性节点。。。。嗯,感觉这样表达不是很清晰。。。所以还是继续学后续知识点吧,学了就差不多明白了
python代码:
from lxml import etreewith open('test10.html', 'rb') as f:
html = f.read().decode('utf-8')
#print(html)
parse_html = etree.HTML(html)
title_list = parse_html.xpath('/html/body/div[1]/following::div/p/a/@title')
print(title_list)
Sublime输出:
['Rabbit'][Finished in 0.4s]
可以!我们匹配到了。
Node节点
Xpath语言把XML文件中的标记、标记所包含的文本等组成的数据结构看做是一个树形结构,即将XML文件看做是由Node类型节点构成的树。Node节点又可以细分为Document、Element、Text、Attribute等节点。
节点之间的关系
Xpath语言经常用表面节点之间的关系术语:子节点、父节点、子孙节点、兄节点、弟节点、兄弟节点等。
一个节点的子节点也称为1级子节点,节点的1级子节点的子节点称为该节点的2级父节点,以此类推,节点的任何级别的子节点被称为该节点的子孙节点。
一个节点的父节点也称为1级父节点,节点的1级父节点的父节点称为该节点的2级父节点,以此类推,节点的任何级别的父节点被称为该节点的祖先节点。
一个节点的兄节点,是指和该节点具有相同级别,并且是该节点之前的某个节点;而一个节点的弟节点,则是与该节点具有相同级别,并且是该节点之后的某个节点;一个节点的兄弟节点是指和该节点具有相同级别的某个节点。
节点的类型
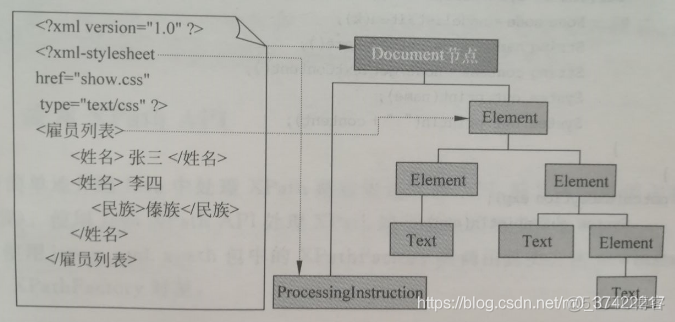
Xpath将XML文件看做是由Node类型节点构成的树。Node节点可以细分为Document、Element、Text、Attribute等节点。下面我们先看一张XML文件的结构图:
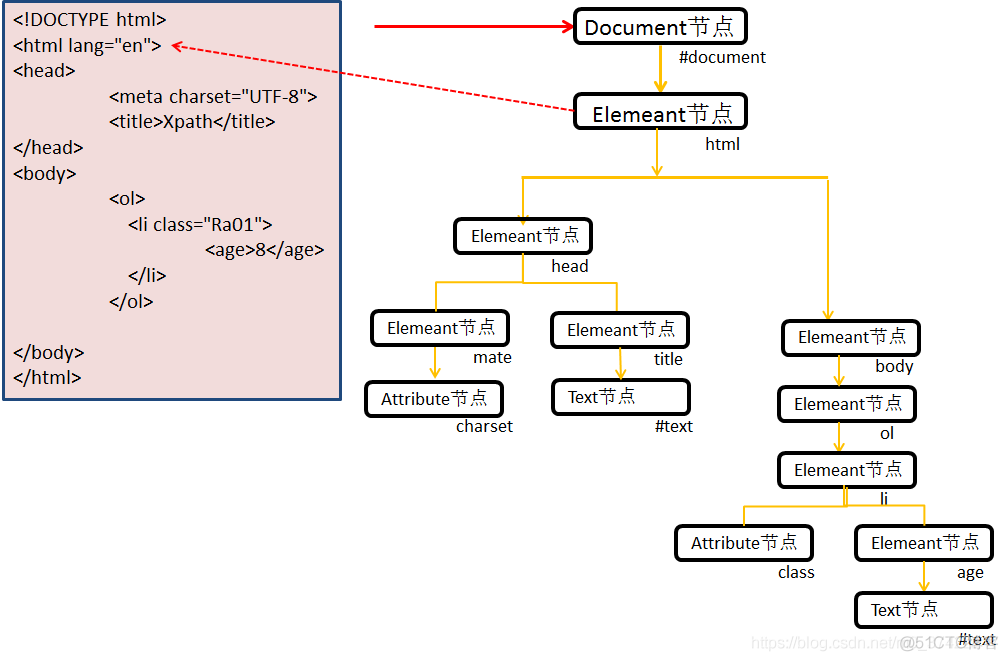
类比于HTML(方便之后用Xpath匹配HTML文件):
- Document节点
Xpath语言将整个XML文件看成一个树形结构数据,并把XML文件作为该树的根节点,而这个根节点是Document类型的节点。Xpath将整个XML文件中的处理指令、根标记、根标记的子孙标记以及标记包含的文本看做是Document根节点的子孙节点。
- Element节点
Xpath语言将XML文件中的每个标记看做是一个Element节点。
- Text节点
Xpath语言将XML文件的标记中包含的文本看做一个Text节点,且该Text节点包含的文本内容就是它所对应的文本。
- Attribute节点
Xpath语言将XML文件中标记含有的属性看做一个Attribute节点。由于XML文件中的标记和属性是关联关系,因此Attribute节点不是Element节点的子节点,但是Attribute节点将与其关联的Element节点看成自己的父节点。
- Comment节点
Xpath语言将XML文件中的注释看做一个Comment节点,注释节点所包含的文本内容就是注释中的内容。
节点的名字与值
节点类型
节点名字
节点的值
Document
#document
null
Element
标记的名字
null
Text
#text
节点在XML中对应的文本
Attribute
属性的名字
属性的值
Comment
#comment
注释的内容
自学笔记,有错请求指出!
【文章转自阿里云服务器代理商 http://www.558idc.com/aliyun.html 复制请保留原URL】