学习笔记
PS:为啥这个BLOG是案例2,但是我的BLOG里没有案例1,那是因为BLOG1被锁了。心痛。
爬取新闻标题和链接
我想通过Xpath拿到X凰X闻[http://news.ifeng.com/]里的的3条新闻的标题和新闻详情链接该咋整呢?
我们先看看网页源代码:
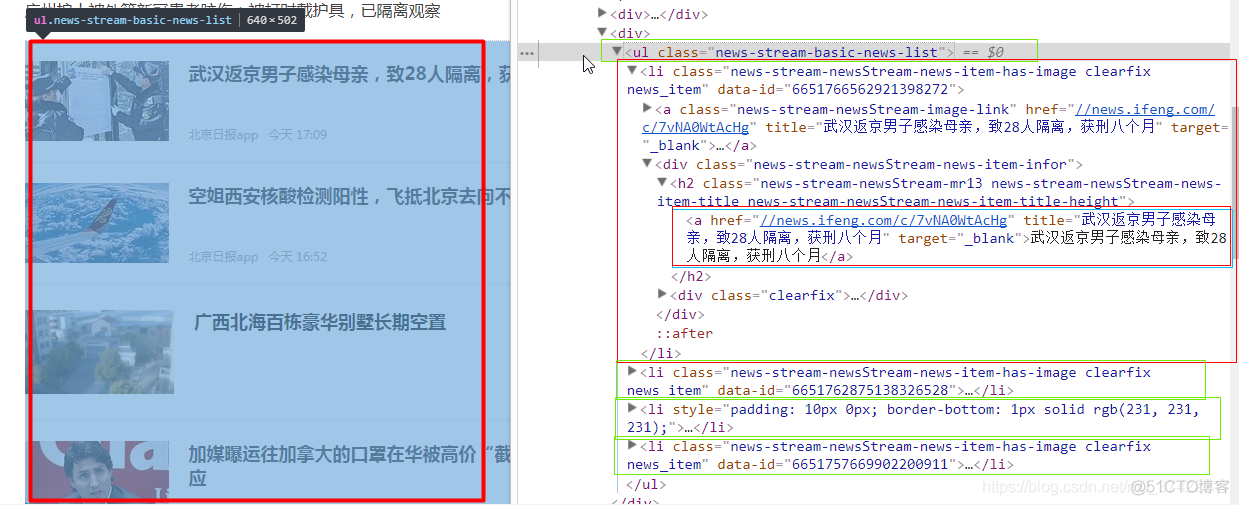
我们看到我们想拿到的3条新闻标题都在一个ul标签中,ul标签有4个li子节点,每个li节点是一个消息块。
注意,这里明明有4个li节点,但为啥我们只爬取3条新闻的信息呢?因为其中有一个li节点包裹的是广告!!

我们看到,这个包裹着广告的li节点的HTML属性值和结构(截图没有体现出来,但大家可以自己去看)和其他包裹着新闻的li节点很不一样。
在包裹新闻的3个li节点中,均有一个a节点,这个a节点里包含着新闻详情链接,以及新闻标题。由此,我们可以通过这些信息,来思考怎么写Xpath语句了。
注意:我们得到的新闻详情链接[//news.ifeng.com/c/7vNA0WtAcHg]依然是不完整的,没有因特网服务类型(http:),所以在之后的python代码中,我们要自己加上去。
这里因为只是学习Xpath匹配,所以就直接把HTML源代码copy下来,放在一个txt文件夹里(html_data.txt),再通过python读取,并匹配,最后将匹配结果存到mysql数据库中。
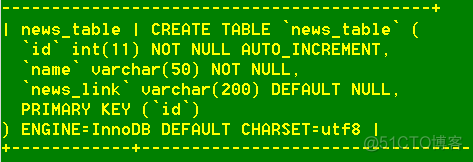
查看我们的mysql数据库中的news_table数据表:
不过多解释了,直接开始编写python代码。但是注意!如果读取数据文件文件时,向下面这样写,可能会报UnicodeDecodeError错误:
with open('html_data.txt', 'r') as f:html = f.read()
这时,我们可以用二进制读取方式进行读取,再用utf-8编码格式,进行解码。
完整代码如下:
# -*- coding: utf-8 -*-from lxml import etree
import pymysql
class FenghuangXpath:
def __init__(self):
self.db = pymysql.connect(host = '127.0.0.1',
port = 3306,
user = 'root',
password = '19970928',
database = 'datacup',
charset = 'utf8')
self.cur = self.db.cursor()
def get_page(self):
with open('html_data.txt', 'rb') as f:
html = f.read().decode('utf-8')
self.parse_page(html)
def parse_page(self, html):
link_xpath = \
'//ul[@class="news-stream-basic-news-list"]/li[@class="news-stream-newsStream-news-item-has-image clearfix news_item"]//h2/a/@href'
name_xpath = \
'//ul[@class="news-stream-basic-news-list"]/li[@class="news-stream-newsStream-news-item-has-image clearfix news_item"]//h2/a/text()'
parse_html = etree.HTML(html)
link_list = parse_html.xpath(link_xpath)
link_list = ['http:{}'.format(i) for i in link_list]
name_list = parse_html.xpath(name_xpath)
data_zip = zip(name_list, link_list)
self.write_data(data_zip)
def write_data(self, data_zip):
sql = 'insert into news_table(name, news_link) \
values(%s, %s);'
try:
self.cur.executemany(sql, data_zip)
self.db.commit()
except Exception as e:
self.db.rollback()
print('错误信息:', e)
def main(self):
self.get_page()
self.cur.close()
self.db.close()
if __name__ == '__main__':
fengh = FenghuangXpath()
fengh.main()
查看news_table数据表内的数据:

很好,都导入了!
但是知道为啥id不是从1开始么?因为我在创建news_table表时,设置id为主键且自动增大。此时,我们就算不传输id值,mysql也会自动帮我们填好id值。那这和id为7有啥关系呢?那是因为博主以为偷懒,在利用python传数据时只传递了name和news_link字段,id字段让mysql自动帮博主填写了。
所以,当3条新闻记录第1次导入news_table时,id的确是从1开始的,但是由于博主是个傻子,代码敲错了n次,导致传入的记录总是不符合要求,所以博主不停的把mysql数据库里news_table表里的数据删了又删,直至第3次,导入的数据终于符合要求了,但是此时mysql给我们传入的id值就是从7开始排列了。悲伤的故事。。。