学习笔记
文章目录
- URL地址编码模块
- 作用
- 常用的方法
- urllib.parse.utlencode({dict})
- urllib.parse.quote(string)编码
- urllib.parse.unquote(string)解码
URL地址编码模块
- 模块
作用
对URL地址中的查询参数进行编码。
比如,我们在百度中查询【垂耳兔】:

可以看到其URL地址(编码前):
https://www.baidu.com/s?wd=垂耳兔&rsv_spt=1&rsv_iqid=0xe5d979f300027bbc&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=cn&tn=baiduhome_pg&rsv_enter=0&rsv_dl=tb&rsv_t=1e54j7VuDW5lTX6%2B7OlhbhlIKUVoVOH%2F2LuYPHgQU46Iab8FfpjQiHRIouHM3DEMCAug&oq=%E5%9E%82%E8%80%B3%E5%85%94&rsv_pq=872089960004898e我们看到了一堆查询参数,太多了!需要注意的是,这里仅有一部分查询参数是我们需要的,而有些则是不需要的。一般来说【wd=垂耳兔】这个参数,我们肯定是需要的,因为这个参数包含了我们要查询的内容。
当我们向网站发起请求时,肯定不能传递这样的URL地址,URL地址需要符合一定的传输协议。此时,我们需要对这个URL地址进行编码,来满足请求规则。
常用的方法
urllib.parse.utlencode({dict})
我们看到urllib.parse utlencode()方法的参数中有一个字典,这个字典里可以放查询参数。
比如,我们可以设置参数为如下字典:
{'wd':'垂耳兔'}urllib.parse utlencode()方法可以对字典中的查询参数进行编码,将其转换成满足请求规则的URL地址。
举个例子
我们设置查询参数,在百度搜索上查询【垂耳兔】:
from urllib import requestfrom urllib import parse
url = 'http://www.baidu.com/s?'
headers = {'User-Agent':'Mozilla/5.0'}
query_string = parse.urlencode({'wd':'垂耳兔'})
url_com = url + query_string
req = request.Request(url = url_com,
headers = headers)
response = request.urlopen(req)
html = response.read().decode('utf-8')
print(html)
部分结果:
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<title>百度安全验证</title>
可以看到,百度返回信息,需要我们进行验证,嘤嘤嘤,可能是我被百度识破了伪装。哎…不管怎样,我们先试着验证一下,再看看有没有拿到查询结果:
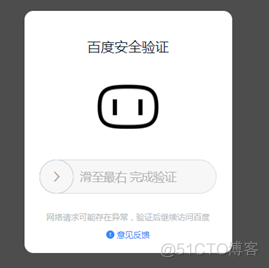
嗯,验证后的确拿到了查询结果:
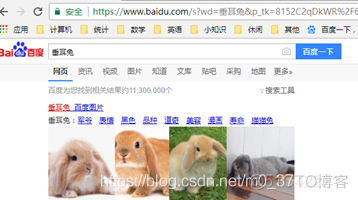
接下来,我们可以在百度中不停的翻页,查看不同页面中的url有什么变化,从而判断各个查询参数有什么作用.
我们发现,当我们翻页到第2页时,pn参数变为10,当我们翻页到第3页时,pn参数变为20:
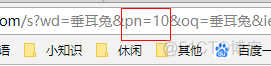
由此,我们发现,pn参数应该可以控制页数。
现在我们再敲一段代码,设置pn查询参数值为20,来指定查询结果页数:
from urllib import requestfrom urllib import parse
my_url = 'http://www.baidu.com/s?'
headers = {'User-Agent':'Mozilla/5.0'}
query_string_dict = {'wd':'垂耳兔',
'pn': 20}
query_string = parse.urlencode(query_string_dict)
url_com = my_url + query_string
req = request.Request(url = url_com,
headers = headers)
response = request.urlopen(req)
html = response.read().decode('utf-8')
print(html)
部分结果:
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<title>百度安全验证</title>
没错,又需要验证,才能获取网页,这个问题,我们之后再解决,现在为了学查询参数这个知识点,我先忍着。
验证后获取的网页:
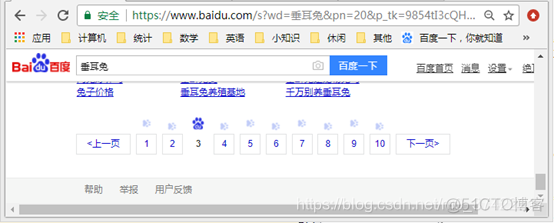
可以看到,我们成功获取了第3页的查询结果。
需要注意的是,我们看到URL中各个查询参数之间都是通过【&】进行拼接的,我们在代码中不手动添加【&】真的可以吗?答案是可以的,在用urllib.parse utlencode()方法进行编码时,它会自动的在各个查询参数之间添加【&】,我们来验证一下:
query_string_dict = {'wd':'垂耳兔','pn': 20}
query_string = parse.urlencode(query_string_dict)
print(query_string)
结果:
wd=%E5%9E%82%E8%80%B3%E5%85%94&pn=20- 案例
在这个案例中,我们要将查询结果存在一个HTML文件中。为了避免,通过程序向百度发送请求,结果要验证的尴尬情景,我们换一个搜索引擎,爬取查询结果,那么就用搜狗吧!
我们首先在浏览器中查询【垂耳兔】:
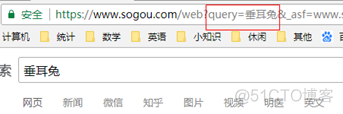
我们看到,貌似需要用到query查询参数。
我们在浏览器中翻到第3页: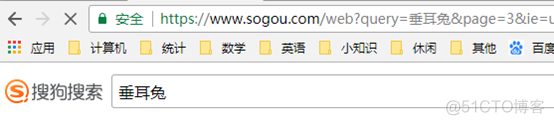
可以看到,page查询参数变为了3,由此我们判断,这个page参数可以控制页数。
接下来,我们通过程序来查询【垂耳兔】,并查看第3页的查询结果:
from urllib import requestfrom urllib import parse
my_url = 'https://www.sogou.com/web?'
headers = {'User-Agent':'Mozilla/5.0'}
query_string_dict = {'query':'垂耳兔',
'page':3}
query_string = parse.urlencode(query_string_dict)
url_com = my_url + query_string
req = request.Request(url = url_com,
headers = headers)
response = request.urlopen(req)
html = response.read().decode('utf-8')
print(html)
部分结果:
<div class="str_info_div"><p class="str_info"><span class="str-c-txt blue-color" style ="display:none" id="sogou_vr_30000909_pink_1">
<strong>[</strong><i>图文</i><strong>]</strong></span> <em><!--red_beg-->垂耳兔<!--red_end--></em>是宠物兔中非常流行的品种,它最大的特点就是有着一对垂着的耳朵。其可爱萌萌的样子实在让人忍不住想要马上把它抱回家饲养。在饲养<em><!--red_beg-->垂耳兔<!--red_end--></em>之前,了解一些相关知...
</p>
<div class="fb" >
<cite id="cacheresult_info_1">
太平洋时尚网 - pet.pclady.com.cn/1... - 2016-8-1</cite> - <!--resultsnap_beg--><a target="_blank" style="color: #666666;" href="http://snapshot.sogoucdn.com/websnapshot?ie=utf8&url=http%3A%2F%2Fpet.pclady.com.cn%2F155%2F1554499.html&did=c103019d5b6c85bf-a459bc045d54e056-6e9a7b6e8e4014d44eeae2ab2434a020&k=d03273cdb123cc84b7d5ef1b12c8f90c&encodedQuery=%E5%9E%82%E8%80%B3%E5%85%94&query=%E5%9E%82%E8%80%B3%E5%85%94&&w=01020400&m=0&st=1" id="sogou_snapshot_1"><!--resultsnap_end-->快照</a></div>
可以看到,我们的确获取到了查询页面。
接下来我们将查询到的页面,用gb18030编码格式,保存成HTML文件:
#gbk-gb2312-gb18030with open('ChuiRr.html', 'w', encoding = 'gb18030') as f:
f.write(html)
我们用Sublime检查一下,刚刚创建的ChuiEr.html文件:
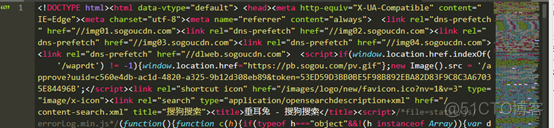
再用Chrome浏览器打开这个HTML文件:
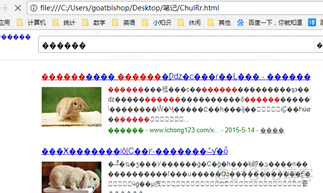
虽然打开了,但是乱码了~ 这个问题依然留下来,以后解决。
urllib.parse.quote(string)编码
urllib.parse.quote()方法可以对字符串进行编码。
举个例子1
代码:
from urllib import parsestring = '黑白道奇'
print(parse.quote(string))
结果:
%E9%BB%91%E7%99%BD%E9%81%93%E5%A5%87举个例子2
代码:
from urllib import parsemy_url = 'https://www.sogou.com/web?query={}'
word = input('请输入搜索内容:')
query_string = parse.quote(word)
print(my_url.format(query_string))
控制台输出:

urllib.parse.unquote(string)解码
举个例子
代码:
from urllib import parseword = input('请输入搜索内容:')
query_string = parse.quote(word)
result = parse.unquote(query_string)
print(result)
结果:
