学习笔记 文章目录 requests模块 requests常用方法 requests.get() requests模块 关于requests模块的安装 进入cmd,输入以下代码,即可安装: pip install requests requests常用
学习笔记
文章目录
- requests模块
- requests常用方法
- requests.get()
requests模块
- 关于requests模块的安装
进入cmd,输入以下代码,即可安装:
pip install requestsrequests常用方法
requests.get()
- 作用
向网站发起请求,并获取响应对象。
- 语法
#url :需要抓取的URL地址
#headers : 请求头
#timeout : 超时时间,超过时间会抛出异常
- 响应对象(res)属性
res.encoding
#res.encoding = 'utf-8'
# 字符串
res.text
#字节流
res.content
#HTTP响应码
res.status_code
#实际数据的URL地址
res.url
- 举个例子1
我们访问测试网站(http://httpbin.org/get).当我们访问这个网站时,网站会返回我们的请求头。
代码:
import requestsimport random
from my_user_agent_list import user_agent
url = 'http://httpbin.org/get'
headers = {'User-Agent':random.choice(user_agent)}
#创建请求对象
res = requests.get(url, headers = headers)
#得到html字符串
html = res.text
print(html)
备注:my_user_agent_list模块,是我自定义的模块。模块里放着一个列表user-agent, 列表里包含了各种User-Agent字符串。
控制台输出结果:
{"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1",
"X-Amzn-Trace-Id": "Root=1-5e867a3e-79e73bc2a78fb809260d2b4e"
},
"origin": "183.164.105.16",
"url": "http://httpbin.org/get"
}
我们看到,测试网站返回给我们一个json格式的字符串。在这些字符串中我们可以观察到我们发送请求的请求头。
- 举个例子2(指定响应编码)
在我们向一个网站发起请求时,如果不指定编码形式, 则requests会根据网站的响应,猜测网站的编码。
①不指定编码
代码:
import requestsimport random
from my_user_agent_list import user_agent
url = 'http://www.baidu.com/'
headers = {'User-Agent':random.choice(user_agent)}
res = requests.get(url, headers = headers)
print('响应编码:', res.encoding)
控制台输出结果:
响应编码: utf-8②指定编码
代码:
import requestsimport random
from my_user_agent_list import user_agent
url = 'http://www.baidu.com/'
headers = {'User-Agent':random.choice(user_agent)}
res = requests.get(url, headers = headers)
res.encoding = 'gbk'
print('响应编码:', res.encoding)
控制台输出结果:
响应编码: gbk- 举个例子3(抓取北极兔图片)
对于非结构化数据(比如:音频,视频,图片),采用二进制的形式抓取。
我们在百度图片里搜索到要抓取的北极兔图片,并检查元素,获取图片地址:
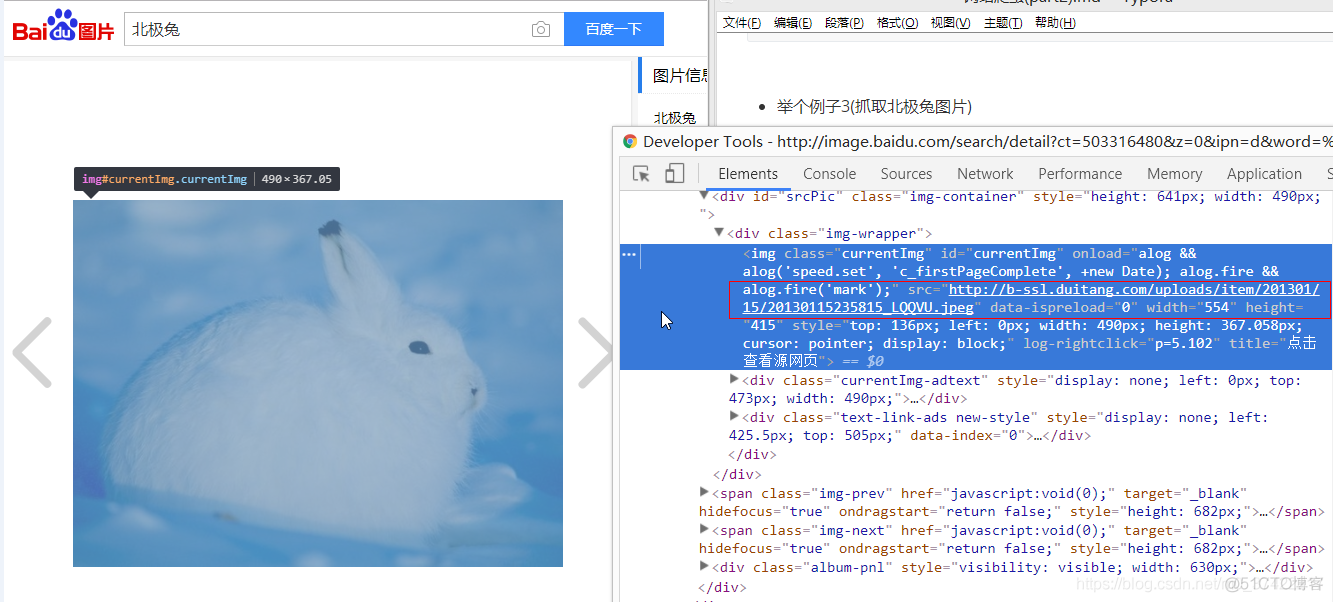
代码:
import requestsimport random
from my_user_agent_list import user_agent
url = 'http://b-ssl.duitang.com/uploads/item/201301/15/20130115235815_LQQVU.jpeg'
headers = {'User-Agent':random.choice(user_agent)}
html = requests.get(url, headers = headers).content
#将图片保存到本地
with open('test/北极兔.jpg', 'wb') as f:
f.write(html)
查看爬取到的图片: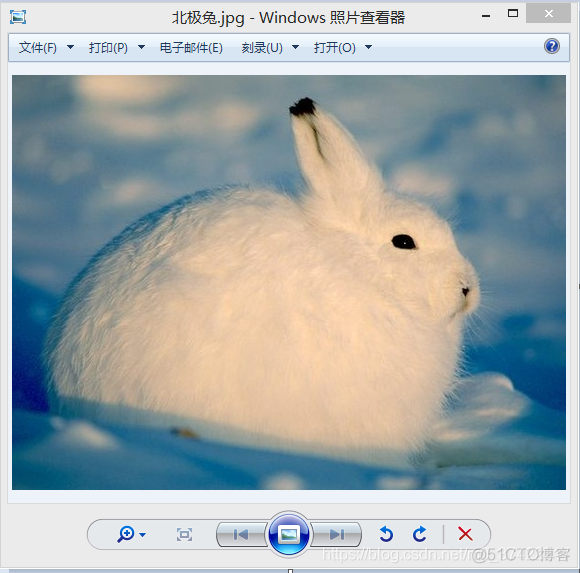
OK!
- 举个例子4(查看HTTP响应码和实际数据URL地址)
代码:
import requestsimport random
from my_user_agent_list import user_agent
url = 'http://www.baidu.com/'
headers = {'User-Agent':random.choice(user_agent)}
res = requests.get(url, headers = headers)
print('HTTP响应码:', res.status_code)
print('URL地址:', res.url)
控制台输出结果:
HTTP响应码: 200URL地址: https://www.baidu.com/
未完待续。。。 明天再写requests模块的其他方法。