鄙人学习笔记
开发工具:Spyder
文章目录
- 模块 Module
- 导入
- Import
- from import
- from import *
- 举个例子1(导入方法1)
- 举个例子2(导入方法2)
- 举个例子3(导入方法3)
- 举个例子4(就近原则)
- 举个例子5(单下划线开头的成员)
- 模块变量
- 举个例子1(`__all__`)
- 举个例子2(`__doc__`)
- 举个例子3(`__file__`)
- 举个例子4(`__name__`)
- 加载过程
- 分类
- 搜索顺序
- 举个例子
模块 Module
- 定义
模块是包含一系列数据、函数、类的文件,通常以.py结尾
- 作用
让一些相关的数据,函数,类有逻辑的组织在一起,使逻辑结构更加清晰。
导入
Import
- 语法
import 模块名 as 别名
- 使用
- 作用
将某模块整体导入到当前模块中。
from import
- 语法
- 作用
将模块内的一个或多个成员导入到当前模块的作用域中。
from import *
- 语法
- 作用
将某模块的所有成员导入到当前模块。
备注:模块中,以_单下划线开头的,不会被导入,我们称其为隐藏成员。
举个例子1(导入方法1)
创建module01模块,再在同一个文件夹下的另一个模块code02中调用它。
module01.py文件(这个文件在例子1~例子4中都会被调用)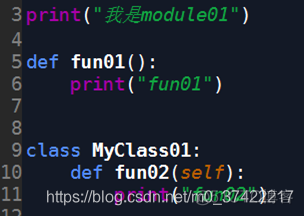
在这里我们先按import的方式,导入模块code02.py
# 导入 模块名称
# 本质:将该模块作用域 赋值给 变量 module01
import module01
#因为module01里的所有内容,都相当于给了变量module01
#则我们想用到module01模块里的成员,就要用module01.变量名 的方法
module01.fun01()
c01 = module01.MyClass01()
c01.fun02()
结果: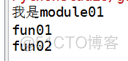
举个例子2(导入方法2)
代码:
以上导入方式的本质是将该模块指定成员 赋值给 变量 fun01,MyClass01
结果:
举个例子3(导入方法3)
代码: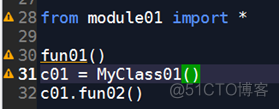
以上导入方式中,因为用了*, 所以就是将module01模块中的成员均放入code02模块中(隐藏成员除外)
结果: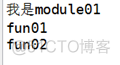
备注1:导入方法3容易造成混乱,比如自己也创建了一个方法fun01但是执行时,我们就很难分清,py到底调用的是导入模块内的fun01方法还是,自己创建的fun01方法了。
备注2:若有两个方法重名,py则会利用就近原则,对函数进行调用。
举个例子4(就近原则)
代码1: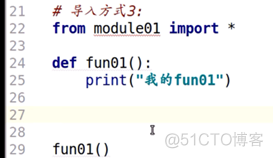
结果1:
代码2: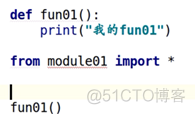
结果2:
举个例子5(单下划线开头的成员)
上面说了,在模块中,以_单下划线开头的成员,不会被导入,那么我们做个实验,看一下,是否真的不能被导入。
若module01.py中添加了一个单下划线开头的变量_fun03,我们再试验一下,是否可以在code02.py中调用。
module01.py文件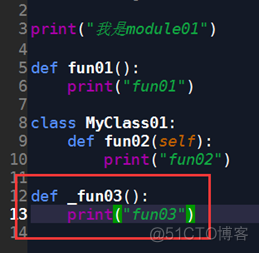
①导入方式1
代码:
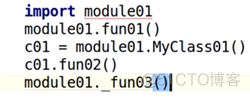
结果: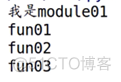
②导入方式2
代码: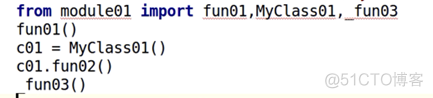
结果: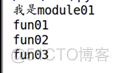
③导入方式3
代码: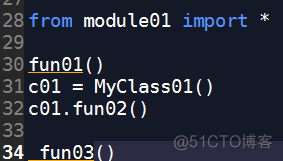
结果: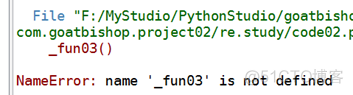
报错!
可以看到用前两种导入方式,没有报错,成功导入了;但是用第3种导入方式,却报错了。
模块变量
__all__ 变量:定义可以导出成员,仅对from XX import *语句有效
__doc__变量:获取文档字符串
__file__变量:获取模块对应的文件路径名。
__name__变量:获取模块自身名字,由此可以判断是否为主模块。当此模块作为主模块(第一个运行的模块)运行时,__name__绑定__main__。如果它不是主模块,而是被其他模块导入时,则会存储模块名。
举个例子1(__all__)
我们可以在module01.py中敲入以下代码:
# 可以导出__all__ = ["fun01","MyClass01", "fun04"]
# 只在第一次被导入时执行
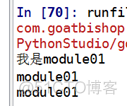
print("我是module01")
def fun01():
print("fun01")
class MyClass01:
def fun02(self):
print("fun02")
def _fun03():
print("fun03")
def fun04():
print("fun04")
在code03.py中调用:
from module01 import *fun01()
fun04()
结果: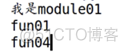
若我们将module01.py的__all__中的fun04()方法删除呢?
__all__ = ["fun01","MyClass01"]
# 只在第一次被导入时执行
print("我是module01")
def fun01():
print("fun01")
class MyClass01:
def fun02(self):
print("fun02")
def _fun03():
print("fun03")
def fun04():
print("fun04")
在code03.py中调用:
from module01 import *fun01()
fun04()
结果: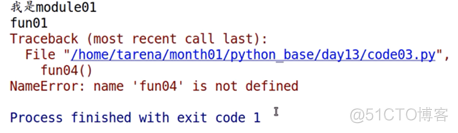
报错了!
举个例子2(__doc__)
①读本模块的文档字符串
代码: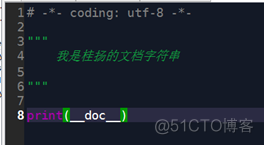
结果: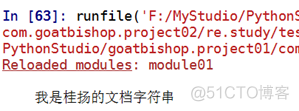
②读其他模块的文档字符串
代码: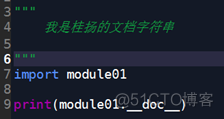
结果: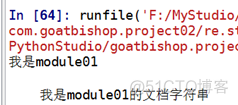
举个例子3(__file__)
①读本模块的路径
代码: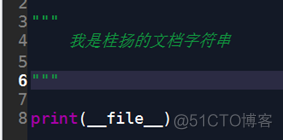
结果: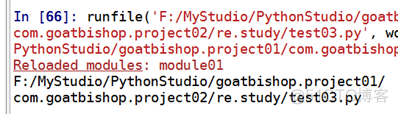
②读其他模块的路径
代码: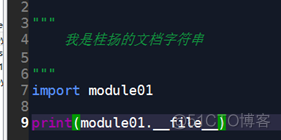
结果:
举个例子4(__name__)
①读本模块的名字
代码:
结果:
②读其他模块的名字
代码: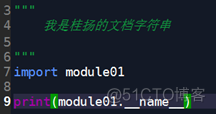
结果: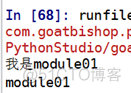
我们更改一下module01.py,在其中增加__name__:
print("我是module01")print(__name__)
def fun01():
print("fun01")
class MyClass01:
def fun02(self):
print("fun02")
def _fun03():
print("fun03")
运行module01.py模块,得到结果为:
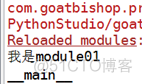
我们再用另一个模块(test03.py)调用module01.py模块: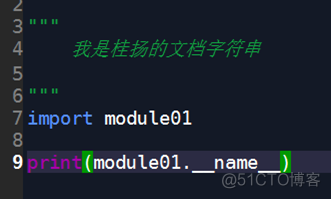
结果:
加载过程
在模块导入时,模块内的所有语句会被执行。
如果一个模块已经导入,则再次导入时不会重新执行模块内的语句。
分类
①内置模块(builtins),在解析器的内部可以直接使用。
②标准库模块,安装Python时已安装且可直接使用。
③第三方模块(通常为开源),需要自己安装。
④用户自己编写的模块(可以作为其他人的第三方模块)
搜索顺序
导入一个模块,首先搜索是否是内建模块(builtins),如果这个模块不是内建模块, sys.path(这个【模块.属性】记载着我们导包时,所要使用的路径)会提供路径,python则会在这些路径中查找, 查看是否有我们想要加载的模块。
举个例子
我们创建test04.py,并进行测试: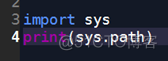
结果: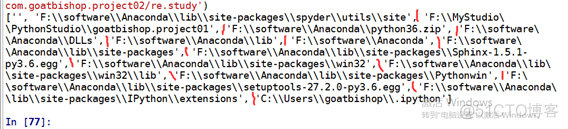
备注:我们可以看到,sys.path储存的是一个装有路径的列表,意味着它可变,我们也可以通过某种方式,向其中添加路径。
在我们安装第3方模块时,python会将这些第3方模块,放到一些路径中。比如,在某些使用Linux系统的小伙伴的电脑里,如果他使用的是python3.5版本,则我们可以看到python把下载的第3方模块放到了如下路径中:
这样我们就可以直接调用这些第3方模块了。