学习笔记
爬取X讯招聘的小职位们
写个小案例,我们想爬取X讯招聘网站里处于1级页面的职位名称和处于2级页面的工作职责和工作要求。由于这个X讯招聘网站是动态加载的,所以需要抓取我们与网站进行交互时产生的数据包。
爬取步骤
①确定X讯招聘的URL地址(https://careers.tencent.com/search.html)
②在1级页面中抓包,并获取1级页面中的json地址
③在2级页面中抓包,获取2级页面中的json地址
④爬取数据,并将数据存放在mysql数据库中
1级页面抓包
我们打开X讯招聘网站后,右键打开审查元素–>点击Network–>点击XHR(我们要的数据包主要在这里)–>刷新网页,获取多个数据包–>点开preview, 依次判断哪个数据包中有我们要的数据–>确定我们想要数据包
经过这么一堆步骤后,我找到了想要的数据包。
参数RecruitPostName所对应的值,就是我们要爬取的职位名称:
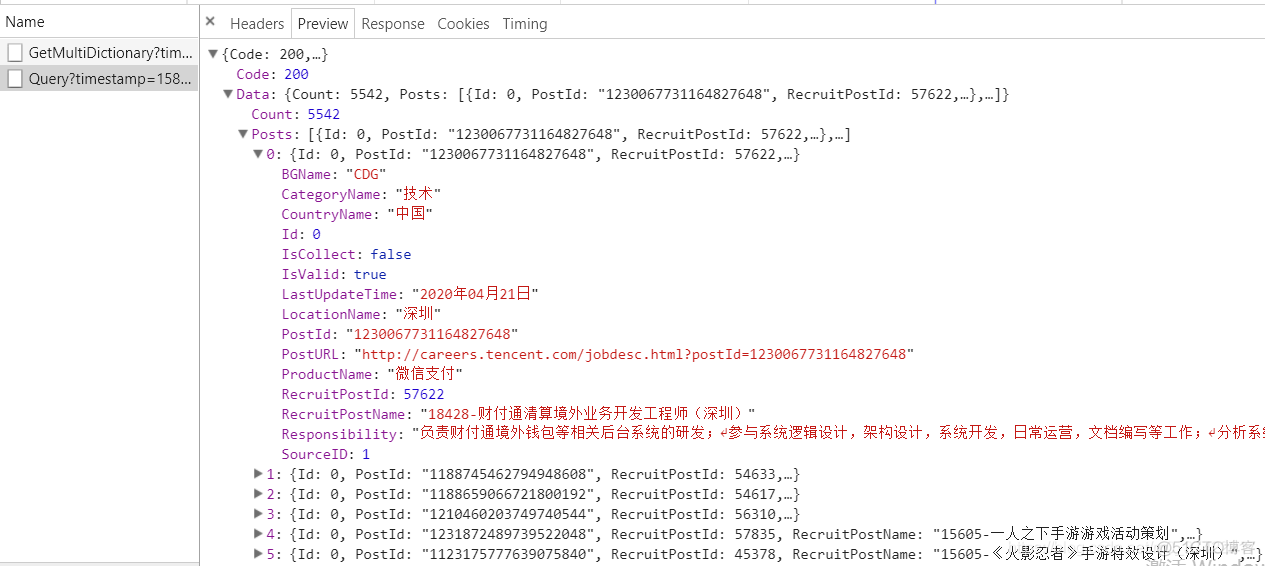
我们点开Headers,查看数据包的头部信息,获取JSON文件的URL地址(Request URL),以及查询参数:
JSON文件的URL地址:
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1587432663964&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn查询参数:
timestamp:1587432663964countryId:
cityId:
bgIds:
productId:
categoryId:
parentCategoryId:
attrId:
keyword:
pageIndex:1
pageSize:10
language:zh-cn
area:cn
我们看到,pageIndex表示的可能表示的是第几页;pageSize表示的可能是一页中有多少职位信息;而timestamp应该是时间戳,我们知道每次发请求时,时间戳肯定都不一样,如果服务端需要时间戳这个查询参数,那么就需要我们在python中自己生成,如果不需要,就可以把这个查询参数从URL中剔除,或者随便写一个整数(比如1)。
2级页面抓包
按照和上面类似的步骤,我们在2级页面中,抓到了想要的数据包。
而参数Requirement和Responsibility所对应的值,就是我们要爬取的工作要求与工作职责:
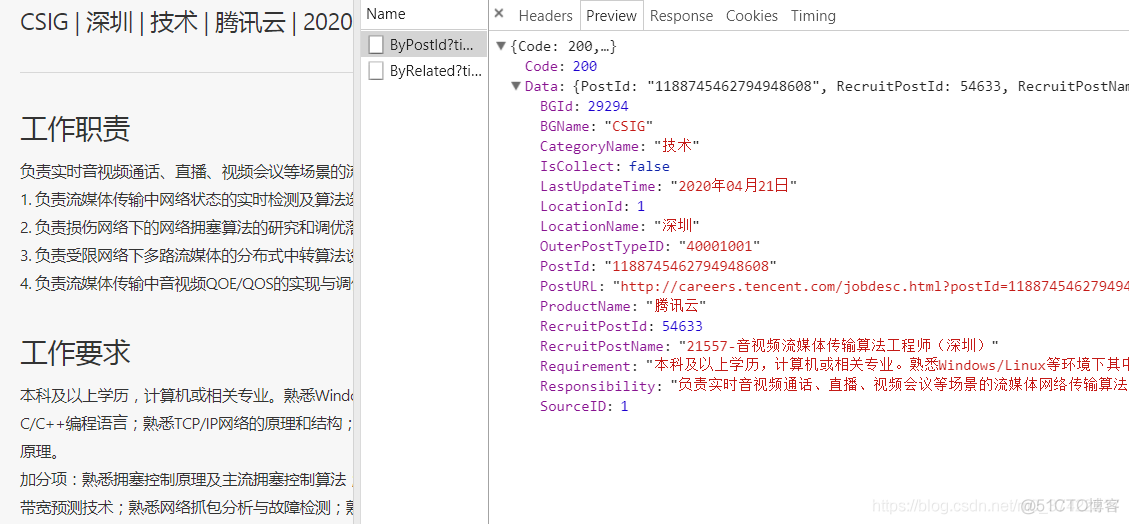
点开Headers,获取JSON文件的URL地址(Request URL),以及查询参数:
JSON文件的URL地址:
https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1587434334600&postId=1188745462794948608&language=zh-cn查询参数:
timestamp:1587434334600postId:1188745462794948608
language:zh-cn
我们看到, 有个查询参数叫postId,这个参数我们应该是需要的,关键是,我们如何获取这个查询参数值,或者找到这个查询参数的规律呢?
不像之前遇到pageIndex查询参数,我们一看就知道是表示页数的,但是这个postId参数貌似没啥规律可循啊…陷入僵局.JPG
这可咋整?
不要惊慌!这个值不可能凭空出现。此时,我们可以把之前获取的新信息撸一遍,看一看有没有这个查询参数的线索。什么新信息?哪来的新信息?有鸭,就是在1级页面中抓取到的JSON文件
这时,我们可以回到1级页面,看一看在1级页面中抓取到的JSON文件里,里是否有关于这个查询参数的线索:
{Id: 0,
PostId: "1188745462794948608",
RecruitPostId: 54633,
RecruitPostName: "21557-音视频流媒体传输算法工程师(深圳)",
CountryName: "中国",
LocationName: "深圳",
BGName: "CSIG",
ProductName: "腾讯云",
CategoryName: "技术",
Responsibility: "负责实时音视频通话、直播、视频会议等场景的流媒体网络传输算法的预研和开发,包括但不限于: 1. 负责流媒体传输中网络状态的实时检测及算法选型和集成; 2. 负责损伤网络下的网络拥塞算法的研究和调优落地; 3. 负责受限网络下多路流媒体的分布式中转算法设计和实现; 4. 负责流媒体传输中音视频QOE/QOS的实现与调优。",
LastUpdateTime: "2020年04月21日",
PostURL: "http://careers.tencent.com/jobdesc.html?postId=1188745462794948608",
SourceID: 1,
IsCollect: false,
IsValid: true
},
有了!PostId: "1188745462794948608"和我们的postId查询参数值一毛一样!
所以,我们拿到1级页面的JSON文件时,除了要获取每一个职位的RecruitPostName,还需要获取每一个职位的PostId
开始敲代码吧
首先我们创建一个mysql数据表用于存储数据:
CREATE TABLE tencent_career(id int NOT NULL AUTO_INCREMENT,recruitpostname varchar(50) NOT NULL,
requirement varchar(500) NOT NULL,
responsibility varchar(500) NOT NULL,
PRIMARY KEY (id));
敲python代码:
# -*- coding: utf-8 -*-import requests
import json
import time
import random
import pymysql
class CareerSpider:
def __init__(self):
self.headers = self.headers = {'Accept':'application/json, text/javascript, */*; q=0.01',
'User-Agent':'Mozilla/5.0'}
self.url01 = 'https://careers.tencent.com/tencentcareer/api/post/Query?countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
self.url02 = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?postId={}&language=zh-cn'
self.db = pymysql.connect(host = '127.0.0.1',
port = 3306,
user = 'root',
password = '19970928',
database = 'datacup',
charset = 'utf8')
self.cur = self.db.cursor()
#请求函数
def get_page(self, url):
res = requests.get(url, headers=self.headers)
#res.encoding = 'utf-8'
#将得到的JSON类型的字符串,转换成python数据类型
print('status_code:', res.status_code)
#print('url:', res.url)
return json.loads(res.text)
def get_data(self, json_dict):
job_data = []
job_list = json_dict['Data']['Posts']
for item in job_list:
recruitpostname = item['RecruitPostName']
print(recruitpostname)
postId = item['PostId']
url02 = self.url02.format(postId)
responsibility, requirement = self.get_data_two(url02)
job_data.append([recruitpostname, requirement, responsibility])
self.write_data(job_data)
def get_data_two(self, url):
json_dict = self.get_page(url)
responsibility = json_dict['Data']['Responsibility']
requirement = json_dict['Data']['Requirement']
return (responsibility, requirement)
def write_data(self, data_list):
sql = 'insert into tencent_career(recruitpostname, requirement, responsibility) \
values(%s, %s, %s);'
try:
self.cur.executemany(sql, data_list)
self.db.commit()
except Exception as e:
self.db.rollback()
print('错误信息:', e)
def main(self):
for index in range(1, 3):
url01 = self.url01.format(index)
one_json_dict = self.get_page(url01)
self.get_data(one_json_dict)
time.sleep(random.uniform(0.5, 1.5))
self.cur.close()
self.db.close()
if __name__ == '__main__':
start = time.time()
spider = CareerSpider()
spider.main()
end = time.time()
print('执行时间:%.2f' % (end-start))
控制台部分输出(共20条):
status_code: 20032032-PC客户端高级工程师(深圳)
status_code: 200
15573-天天爱消除动画设计师(上海)
status_code: 200
执行时间:8.40
查询mysql数据库
我们先检验一下数据是否导入到tencent_career表里:
SELECT * FROM tencent_career;语句执行记录:
11:33:17 SELECT * FROM tencent_career LIMIT 0, 1000 20 row(s) returned 0.000 sec / 0.000 sec查询的部分结果:
# id, recruitpostname, requirement, responsibility'1', '35595-信息流内容策略高级产品经理', '1)三年及以上信息流内容推荐策略相关工作经验;\n2)有数据分析、信息流推荐产品经验者优先考虑;\n3)具有强推进能力,并有强烈的责任心和自驱力。 ', '1)对腾讯信息流产品大盘内容现状进行分析,寻找在内容建设方向和推荐策略方向的优化空间; \n2)问题驱动进行内容和推荐全链路的分析、优化,包括内容建设、内容理解、用户画像等环节; \n3)分析挖掘不同用户场景和不同用户群体的内容需求,建立可行的产品和内容策略并推动落地;\n4)负责跟踪内容策略的数据效果并持续分析,为大盘各核心指标的正向增长,提供内容侧支持;\n5)定期对竞品的内容策略进行测评,输出有价值的内容策略优化方案和建议,并负责推动落地。\n'
'2', '30361-SLAM算法工程师', '1. 熟悉单目、双目或深度的SLAM算法; \n2. 有较强的工程开发能力,能独立完成算法移植和优化; \n3. 在SLAM或者计算机视觉方向发过高质量论文的优先; \n4. 熟悉Android/IOS 开发的优先。\n5. 具备良好的敬业精神和团队合作精神,善于分析和解决问题,富有想象力和学习能力。', '1. 负责移动端增强现实引擎开发和优化 \n2. 负责SLAM前沿技术研发及相关产品实现 '
很好!20条职位信息都导入数据库了。
这时,我想查看工作要求里有"硕士"两个字的职位信息:
SELECT * FROM tencent_career WHERE requirement REGEXP '硕士';查询的部分结果:
# id, recruitpostname, requirement, responsibility'3', 'TEG16-高级秘书(深圳)', '硕士,英语能力强,有一定的海外工作经验更佳;\n有3-7年大型企业相关助理工作经验本科也可以考虑;\n有大型项目或活动组织经验,沟通协调能力强;\n踏实、稳重,灵活,有服务意识及全局观。', '为GM提供高效专业的助理支持服务,协助高管进行各项日常工作管理,安排和落实高管参与的内外部各项会议、活动、差旅行程等;\n跟进领导交付的各项任务,保证事务的顺利落实;\n在业务侧协助高管推进业务或项目,配合协调与维护内外部公共关系;\n协助安排和组织高管团队的各项会议、活动等;\n负责组织活动和文化落地,活跃部门组织氛围;及系统级节庆、拓展活动组织;\n担任部门内各项行政人事工作接口人,包括行政、人事、资产、费用、合同、文档、资料管理等;\n部门财务预算制定管理工作;协助制定并实施部门的管理规章制度及各项流程;\n组织和维护所在秘书团队的日常事务运作及大型项目活动。'
'11', 'WXG10-企业微信音视频引擎开发(成都)', '音视频相关专业硕士及以上学历;\n熟悉c\\c++,熟悉网络,精通信号处理相关知识,了解深度学习相关技能;\n有5年以上音视频引擎优化的相关工作经验;', '负责企业微信音频或视频功能的引擎研发工作;\n音频方向主要为负责语音编解码性能优化,降噪rnn算法优化,语音fec优化,会议室回声处理,语音网络策略算法优化等算法工作;\n视频方向主要为负责H265的视频会议算法优化,超分辨率算法优化,高清会议室视频算法优化等工作;'
很好,查到了,貌似一个职位是高级秘书,一个职位是引擎开发。
后记:在写这个案例的过程中,出现过两次小意外。
第一个小意外:我一开始把由浏览器向服务端发送的请求头信息,都写在python程序里了,结果导致由python程序访问服务端出现404错误,后来我在python代码中删除了一些请求头信息,只留下了User-Agent和Accept,程序就正常访问了。
第二个小意外:最开始在创建mysql数据表时,我将requirement和responsibility字段设置为varchar(200)结果报出错误信息"Data too long for column 'requirement' at row 8", 并且由于设置了回滚rollback,所以,报错之前的职位信息全部都没有存入数据库,只有报错后的职位信息存入了数据库。后来,我设置varchar(500)就没有出现该问题了。