场景一: 找好目标网站 兴高采烈的打开F12,观察一番 查看network面板,抓请求,简简单单有json返回,So Easy。 代码一顿噼里啪啦,搞定! 场景二: 找好目标网站 兴高采烈的打开F12,观
场景一:
- 找好目标网站
- 兴高采烈的打开F12,观察一番
- 查看network面板,抓请求,简简单单有json返回,So Easy。
- 代码一顿噼里啪啦,搞定!

场景二:
- 找好目标网站
- 兴高采烈的打开F12,观察一番
- 网站没有直接返回数据,而是html啥的,简单,解析html呗。
- xpath,css selector ,re给我盘他。
- 代码一顿噼里啪啦,搞定!

场景三:
- 找好目标网站
- 兴高采烈的打开F12,观察一番
- 请求只返回了js,然后js动态加载到网页中。
- 上家伙,selenium,puppeteer,phanotomjs,给我盘他。
- 代码一顿噼里啪啦,搞定!

到这里就已经能应对90%的情况了。
- 跑着跑着,因为数据格式原因或者其他,程序运行终止了…
- 网站的html不按套路出牌,正则写了半天…
- 速度太快,ip被封了,突然爬不到了…
- 数据需要登录才能获取,模拟登录又是一番功夫。
- 即使用模拟浏览器,依然获取不到数据。

其实写爬虫就像回合制游戏,你一直面对这个boss,用各种办法升级你的爬虫,最后搞定他。
A:网站,B:你
- B:请求网站失败
- B:数据解析有问题
- B:分析哪里有问题,爬的过程有问题,还是洗的过程有问题(不断反复调试,直到ok为止)
- B:速度太慢,上多线程,协程。
- A:速度太快,被干掉。
- B:上代理,代理呢免费的又层次不齐,是不是要考虑整个代理池,付费的又没钱。
- 最后就是程序的健壮性问题,还有根据一些功能定制化了。
那有没有什么好的插件可以帮帮我呢,毕竟我只是想要简单爬点数据呀!!!

2.干货环节
简单思考下:用浏览器爬数据,那当然要用浏览器插件才靠谱呀。
那接下来推荐几款我用的比较舒服的插件。
Web Scaper
这真的是个好东西,免费还好用
免费的,但只有一个线程,但也够用了。如果需要更多的服务,比如代理呀,并发也,可以去注册个账号,购买套餐。
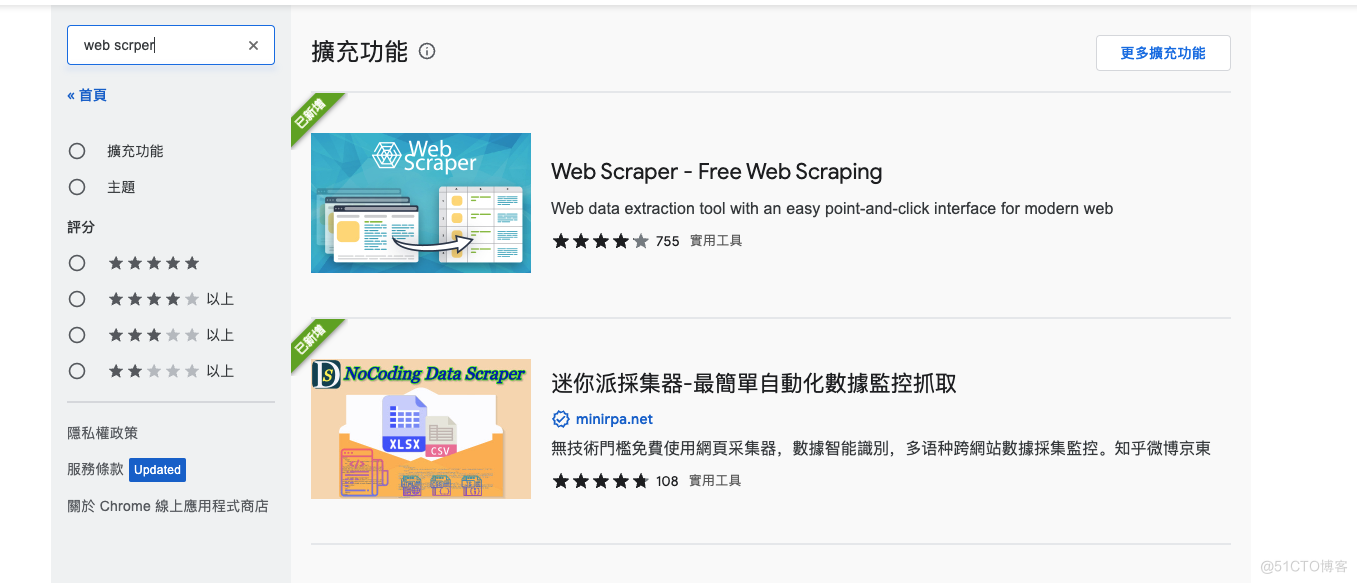
- 打开F12,可以看到多了一个web scraper,这里以acg动漫网为例。
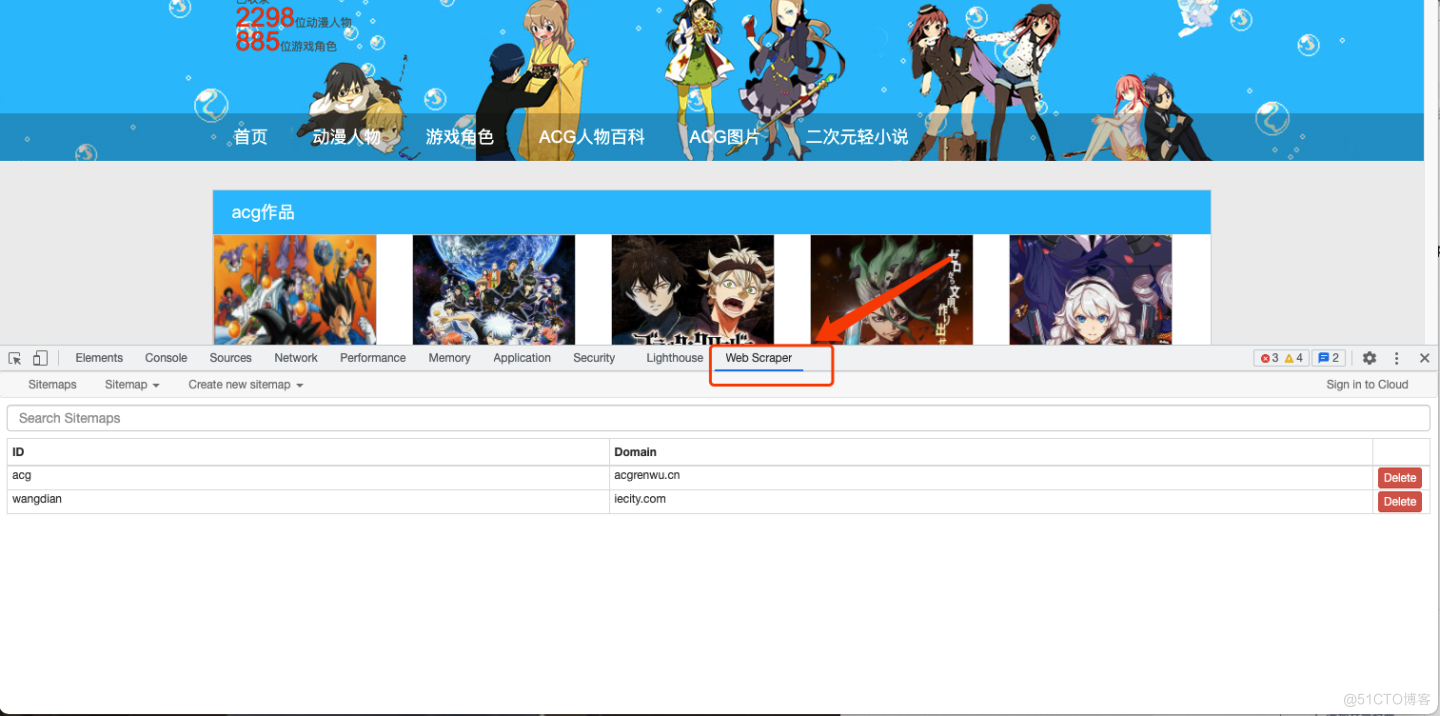
- create new sitemap ,创建一个网站地图
- 配置规则
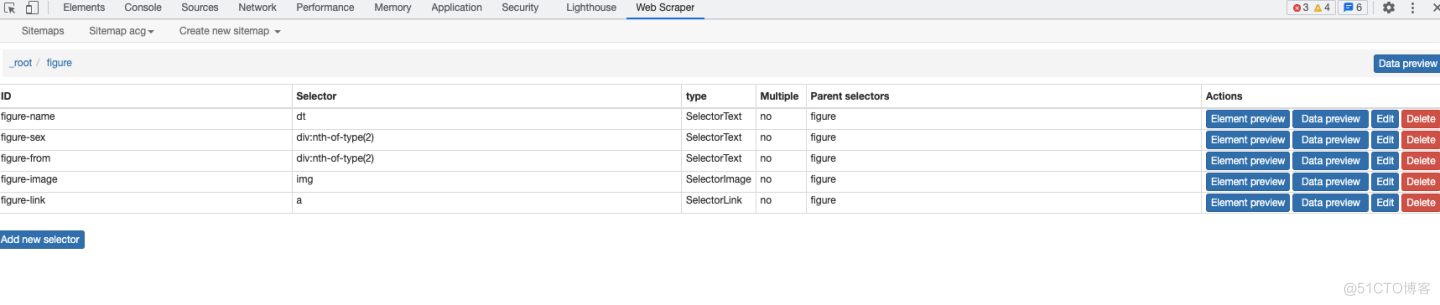
- 预览数据
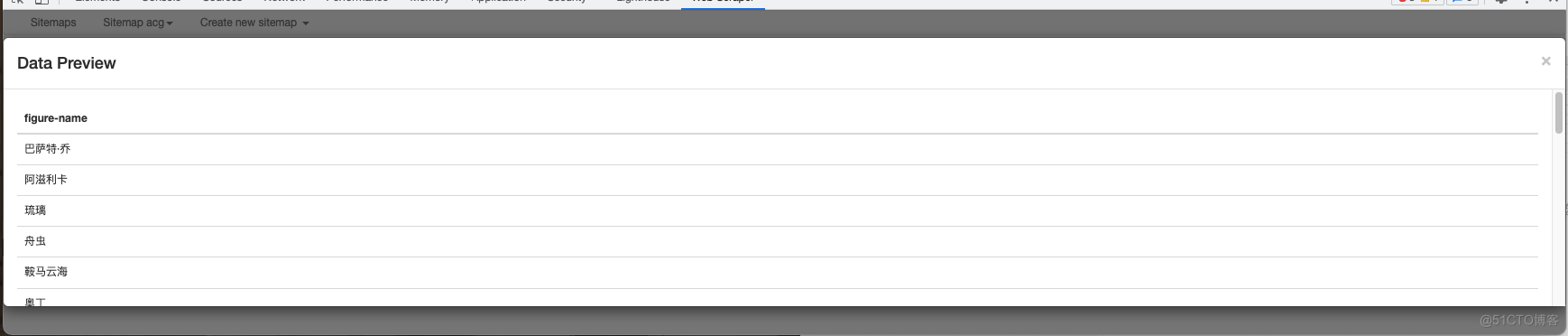
添加图片注释,不超过 140 字(可选)
- 下载导出数据
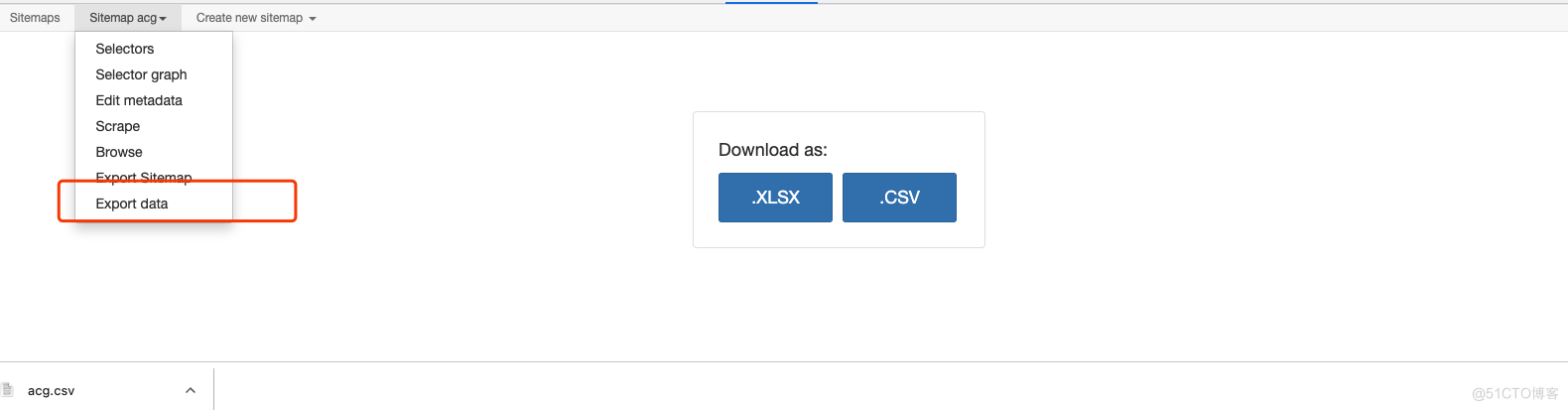
如果有人愿意看的话,下一期我可以出一份详细教程。

这真的是爬取图片神器,不是我吹。
网站直接右键,提取图片!!!就是怎么方便。
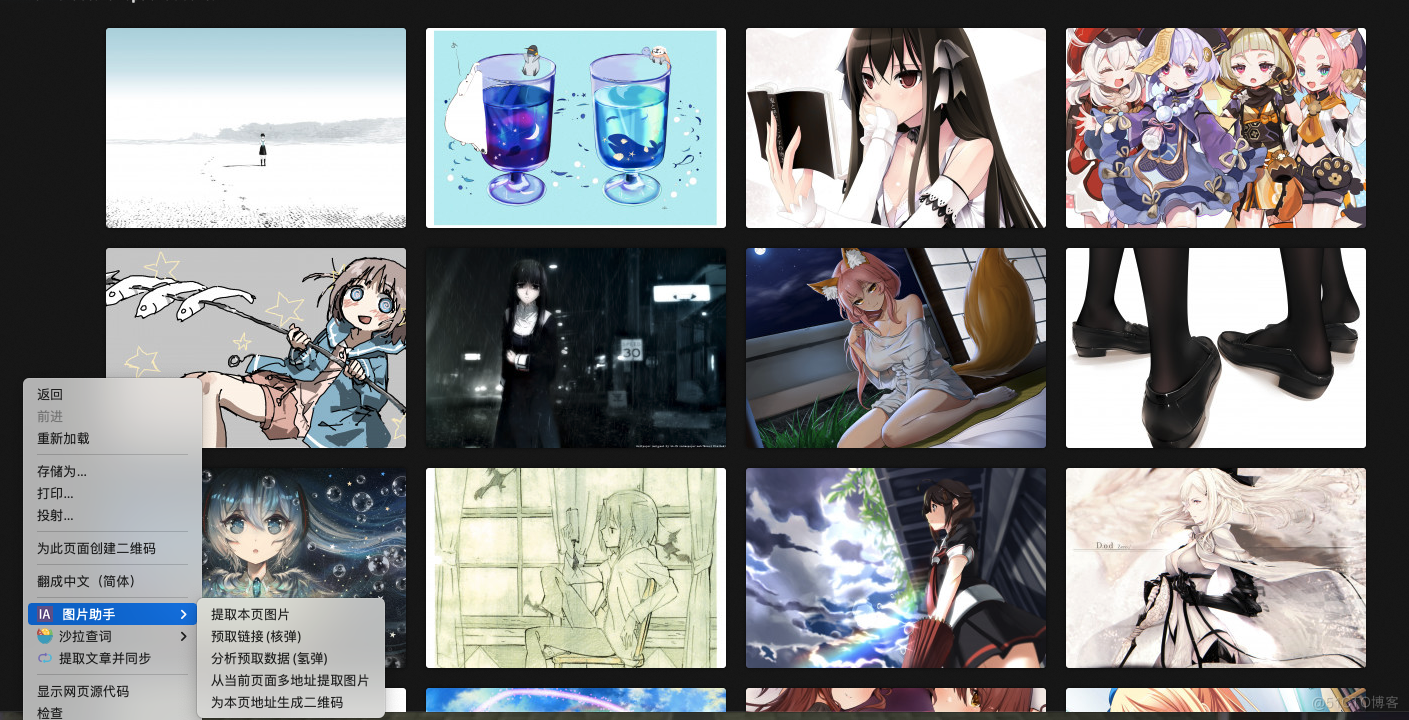
提取的图片可以自行筛选,选择下载。
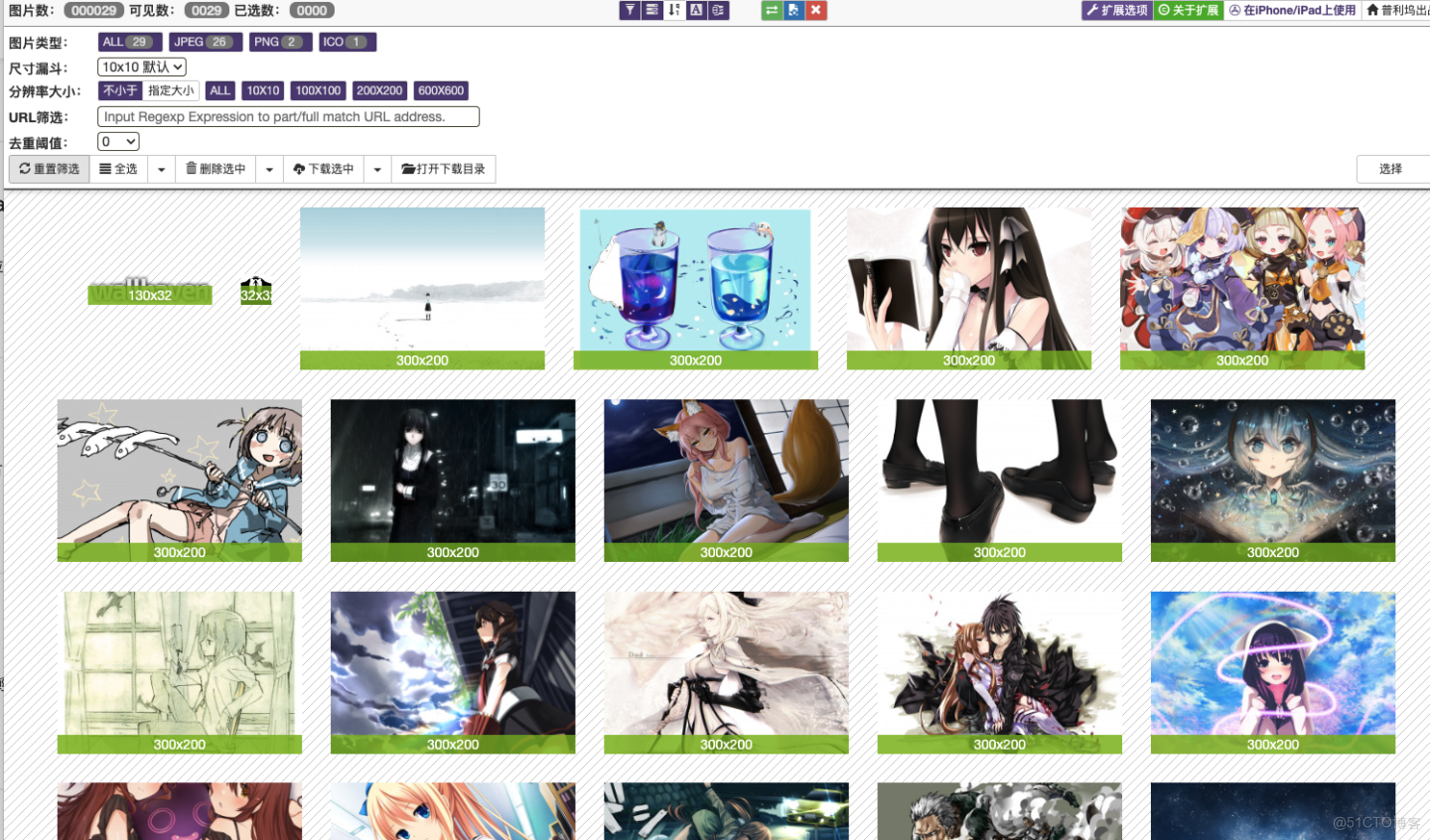
然后点击下载就能全下载下来啦!
3.最后的最后
有个这两个工具,相信一般网站已经难不倒你了,即使不会写代码也不要紧!

文章知识点与官方知识档案匹配,可进一步学习相关知识