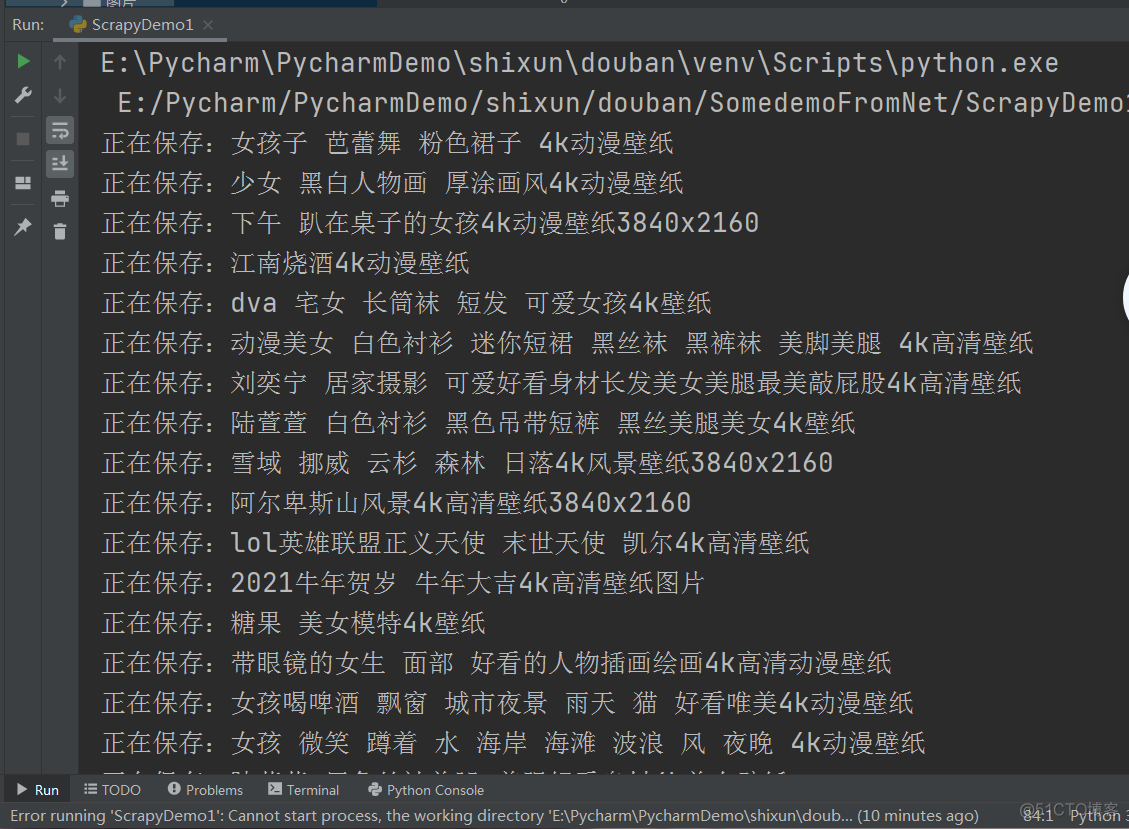
注意:本次爬虫仅为入门实战,爬取对象为彼岸图网,爬取图的分辨率大概都为1202✖️676 本次爬取采用的是requests+BeautifulSoup 1.爬取结果(话不多说,上图) 以上只是两张图片,更多就
注意:本次爬虫仅为入门实战,爬取对象为彼岸图网,爬取图的分辨率大概都为1202✖️676
本次爬取采用的是requests+BeautifulSoup
1.爬取结果(话不多说,上图)

以上只是两张图片,更多就不一一放出来了。代码中只是爬取了4页图片,小伙伴们可以爬取更多内容。
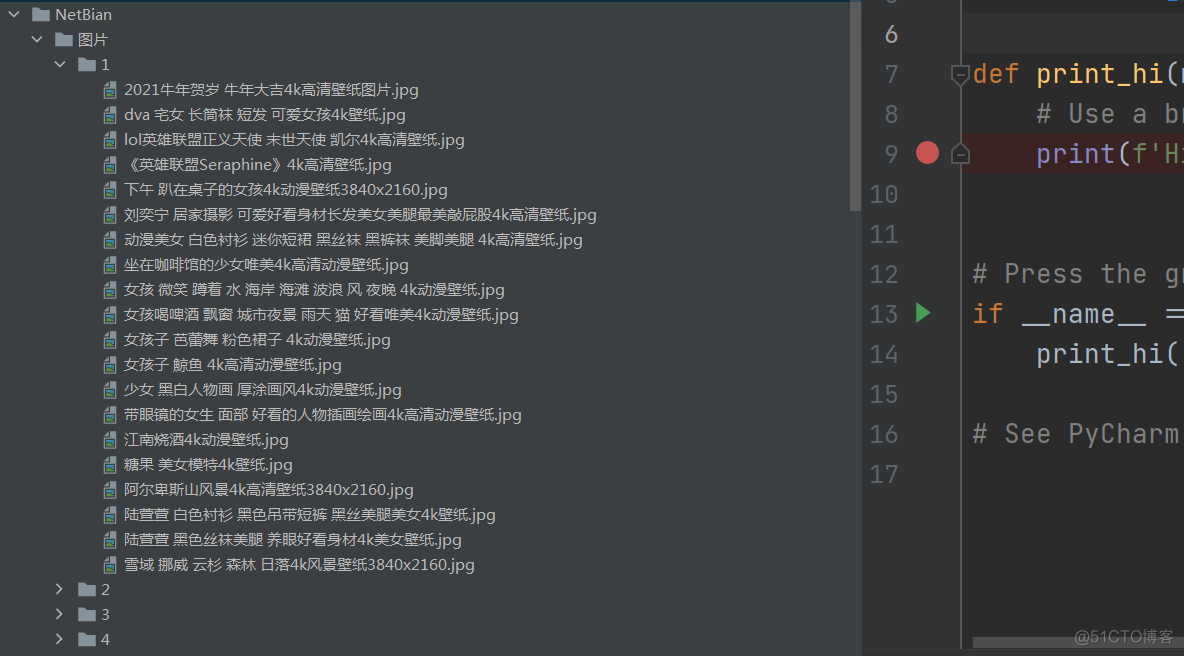
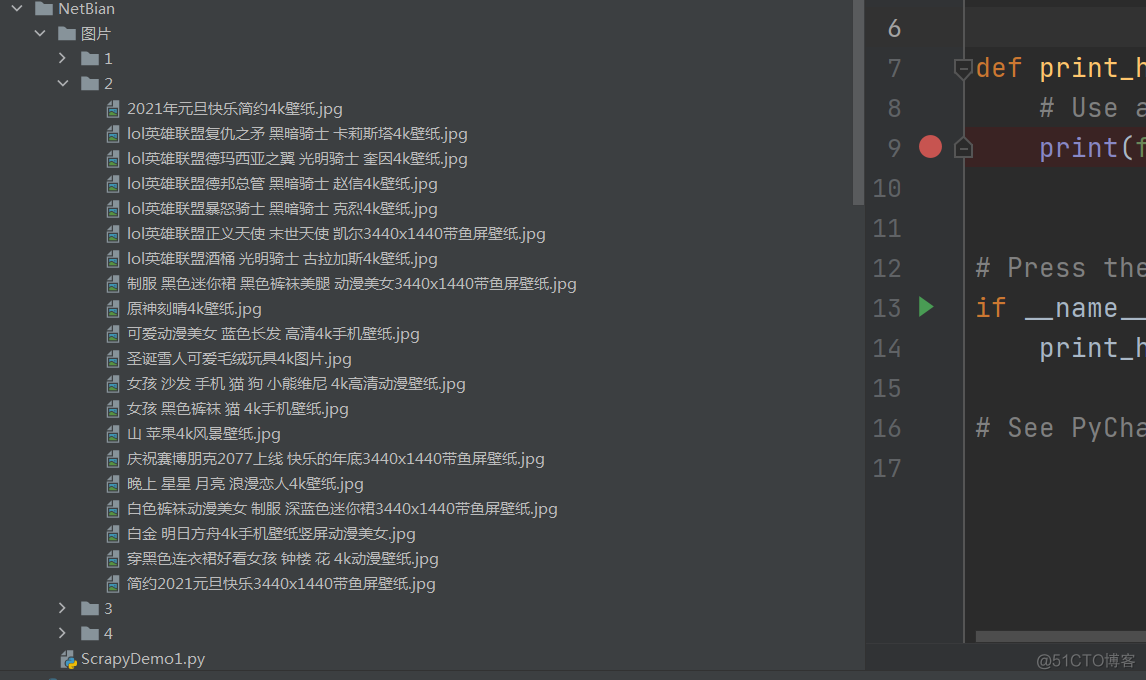
第一页所有详情页图片如下

2.网页查看
彼岸图网:http://pic.netbian.com/
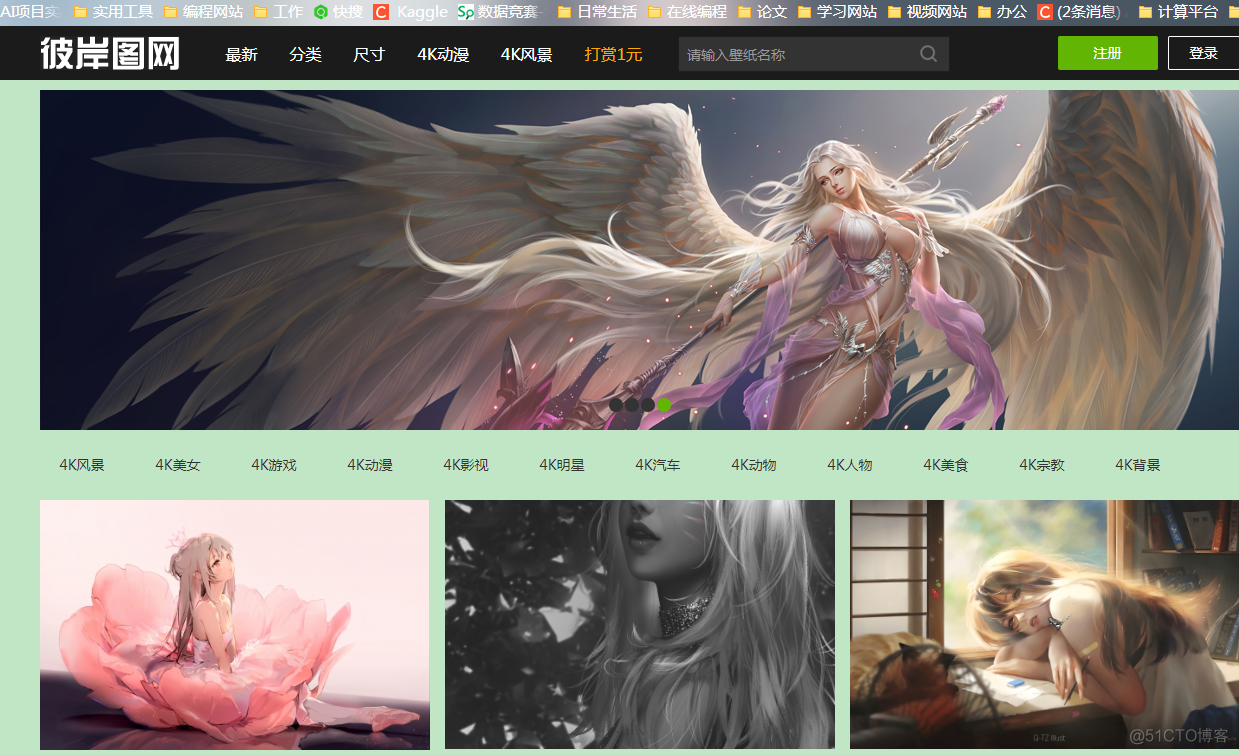
可以看见,如下有着很多页数的图片,待会我们会实现多页爬取功能
不同页数的请求链接分析
另外,由于当前页中的图片分辨率没有其详情页(也就是点击图片进去的页面)分辨率高,
所以咋们还是获取详情页中图片比较好一点。话不多说,咋们直接上代码分析
3、完整代码及注释分析
代码如下:
import requestsfrom bs4 import BeautifulSoup
import os
# 请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36"
}
# 找到并保存图片
def download(path, data):
# 参考图片辅助分析——图1,之后我就直接说参考图几了,小伙伴们注意点喽
ul = data.find(class_="slist").find_all("li")
# 遍历li标签
for li in ul:
# 使用BeautifulSoup进行解析
li_data = BeautifulSoup(str(li), "html.parser")
# 参考图2
# 详情页url,注意获取的url不是全路径,我们还要拼接下前面的域名
page_url = "http://pic.netbian.com/" + li_data.find("a")['href']
# 图片名称
title = li_data.find("img")['alt']
# 对详情页发起请求
page_data = requests.get(url=page_url, headers=headers)
# 解析
response_data = BeautifulSoup(page_data.text, "html.parser")
# 获取详情页图片url,参考图3,注意拼接域名
img_url = "http://pic.netbian.com" + response_data.find(class_="photo-pic").find("img")['src']
# 对图片URL发起请求 注意: .content使用二进制数据,不使用就会报错
img_res = requests.get(url=img_url, headers=headers).content
# 保存图片
with open(path + "/" + title + ".jpg", "wb") as f:
print("正在保存:" + title)
f.write(img_res)
# 开始
if __name__ == '__main__':
# 定义保存文件夹路径
path = "./图片"
# 如果不存在
if not os.path.exists(path):
# 创建该文件夹
os.mkdir(path)
# 多页爬取,这里爬取的是4页
for i in range(1, 5):
# 这里我们做精细一点,再对图片进行不同页数的区分
data_path = path + "/" + str(i)
if not os.path.exists(data_path):
os.mkdir(data_path)
# 第一页比较特殊,我们进行if判断
if i == 1:
url = "http://pic.netbian.com/index.html"
else:
#其他的页数直接拼接就好,注意 i 要为str类型
url = "http://pic.netbian.com/index_" + str(i) + ".html"
# 发起请求
response = requests.get(url=url, headers=headers)
# 注意设置编码,不然都是一堆乱码
response.encoding = 'gbk'
# 使用BeautifulSoup进行解析
data = BeautifulSoup(response.text, "html.parser")
# 将保存路径和请求后的数据传给 download
download(data_path, data)
4.图片辅助分析
图1
图2
图3
5.运行结果: