一、字节编码的基础知识
一、计算机基础知识
#1 我们的程序都是运行在特定的操作系统内,例如window,linux,mac等等#2 运行应用程序,需要要操作系统发出请求,我们双击运行的时候会向操作系统提供应用程序的路径
#3 操作系统根据提供的路径,向磁盘寻找此应用程序,然后把该应用程序加载到内存中,到达内存后,程序代码就会进入CPU。
#4 应用程序的操作都需要向操作系统发起系统调用,然后由操作系统进行相关的硬件操作
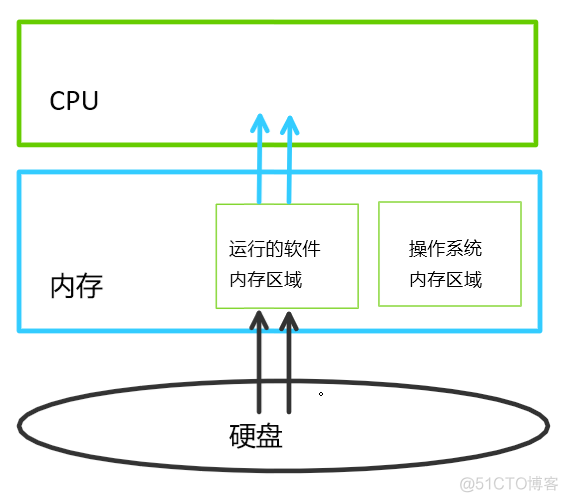
二、计算机存取文件的过程(以巨硬公司的word编辑器为例)
#Stage2 当我们完成文档内容,点击保存,这时word的文档的内容就会会从内存存到硬盘中
#Stage3 内存中的数据断电后,就消失了,但是数据写入硬盘之后,即使断电,仍然在。
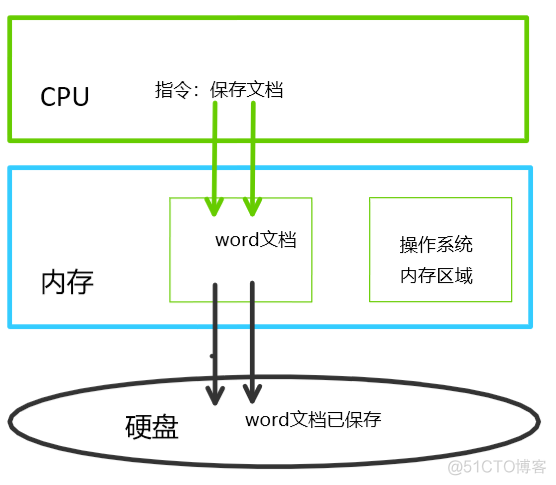
三、Python解释器执行py文件的原理(以执行hello.py为例)
#Stage 2:python解释器相当于文本编辑器,当我们要运行hello.py文件,操作系统会从硬盘上将hello.py的文件内容读入到内存中
#Stage 3:python解释器解释执行刚刚加载到内存中hello.py的代码
** 无论是从内存储存到硬盘,还是从硬盘加载到内存准备给CPU运行,相互传输的都是硬件层面的010101010101机器码,硬件层面的都是由操作系统执行的**
二、字节编码的介绍
一、什么是字节编码
我们都知道计算机是机器,机器之间的通讯会使用机器特定的语言,沟通的方式和人类社会一样,有着特定的规则和方式。计算机遵循二进制原理,采用电平高低分别对应二进制中的0和1,磁盘比较特殊,采用磁极的正负极代替1和0。对于我们一般来说,使用计算机都是图形和文字界面,都是人类可以直接看懂的。但是人类和计算机交流,是通过工具转换成0101,让计算机懂人类的语言。
这个流程,一般来说和翻译一样,人类的字节--->>>通过各种输入设备翻译--->>>计算机能够懂的2进制01010。
***这个翻译过程就是人类的字节,对应计算机特定的数字,这个过程我们称之为字节编码。***
二、Python运行过程中过涉及的字节编码
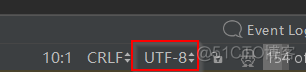
请仔细查看pycharm右下角,我们的.py文件都是按照特定的编码格式保存起来的,见下图,我们使用的是UTF-8编码
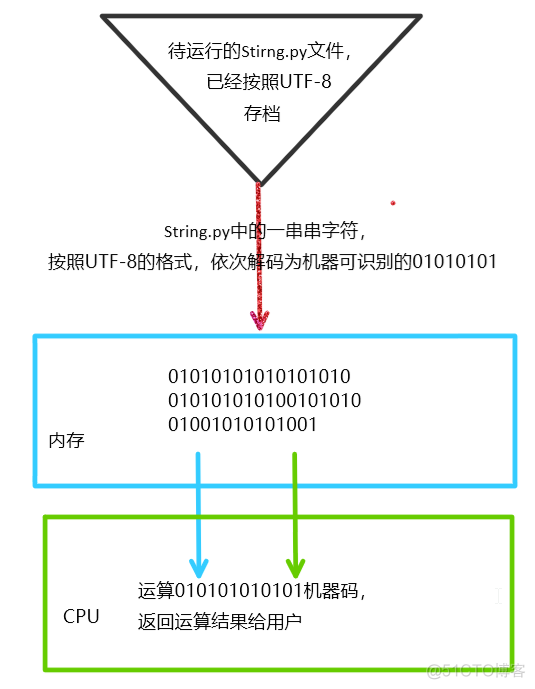
#2 Python中的数据类型String字节串,都是由字节组成的,
当我们运行时,String字节串会按照.py文件存档的格式(UTF-8)依次转换为Unicode,变成了机器可以识别的01010101指令。
三、 字节编码的发展历史和分类
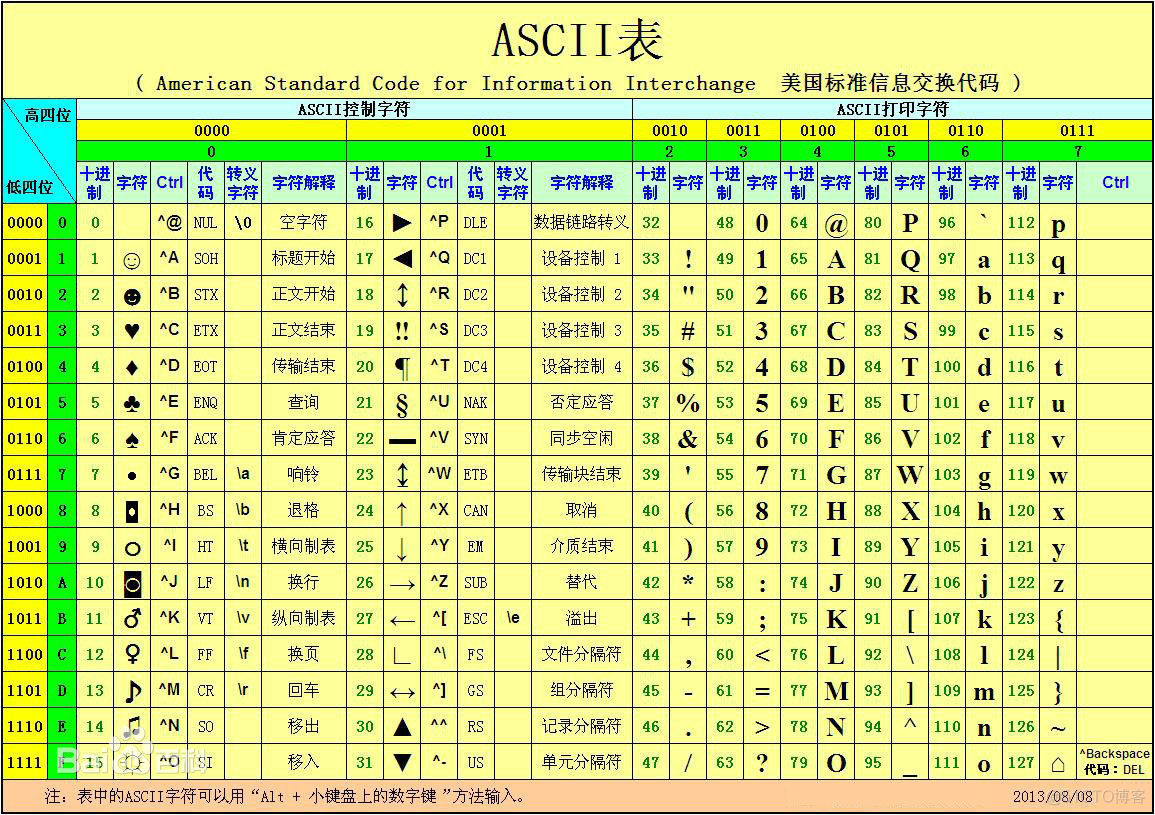
计算机最早是由使用英语的的美国人发明的,美国人为了方便了计算机沟通,创建了最初的人机交互翻译用的字节编码表ASCII,规定了ASCII表中特殊数字与26个英语字母,0-9阿拉伯数字,标点符号和一些特殊字节的一一对应关系。计算机刚刚开始的时候,最多只能用8个2进制的数来表示一个字节,就是我们说的8bit(s)=1Byte

请看上图,有8个bits组成了一个1Byte,我们知道1bit只有两个状态,要么是0,要么是1,但是要是他们8个合在一起,能有多少变化呢?根据我们所学的数学知识,应该是2x2x2x2x2x2x2x2,即2的8次方,一共有256种不同的状态,所以说ASCII码最多只能表示为256个字节。
在英语的世界,256种特殊字节,足以覆盖英语的各种字节,再用字节组成单词,单词再组成句子,让人们能够和计算机无障碍的交流。
但是随着全球化的发展和科学技术的传播,地球上讲“非英语”的国家和人民也需要使用计算机,各个国家根据自己的语言,仿照美国人创建ASCII的方法,把本国语言的字节分别对应特殊的数字。
拿中文举例,我们国家指定的标准是gb2312编码,规定了中文中的各个汉字和特殊数字一一对应的关系。
但是中文博大精深,汉字个数比较多,2的8次方256种变化,根本无法覆盖所有的中文字节。所以我们采用了2个字节(2 Bytes = 8bits + 8bits)来表示一个汉字,总共使用了16bits。2的16次方是65536,那就是说gb2312编码表可以对应65536个汉字,我们日常汉字也就三千多个,gb2312编码足够我们使用。
同理,日本指定的是Shift_JIS编码,韩国人使用的是Euc-kr编码。
但是结合实际使用,我们的文档中不止中文字节,有时候会有英文字节,日文字节或者韩文字节。那么这篇文档,无论按照哪国的标准,都会出现乱码(因为此刻的各种标准都只是规定了自己国家的文字在内的字节跟数字的对应关系,如果单纯采用一种国家的编码格式,那么其余国家语言的文字在解析时就会出现乱码)
这时候问题出现了,精通18国语言的小周同学谦虚的用8国语言写了一篇文档,那么这篇文档,按照哪国的标准,都会出现乱码(因为此刻的各种标准都只是规定了自己国家的文字在内的字节跟数字的对应关系,如果单纯采用一种国家的编码格式,那么其余国家语言的文字在解析时就会出现乱码)
所以迫切需要一个世界的标准(能包含全世界的语言)于是unicode应运而生
ASCII用1个字节(8位二进制)代表一个字节
unicode常用2个字节(16位二进制)代表一个字节,生僻字需要用4个字节
例:
字母“x”,用ascii表示是十进制的120,二进制0111 1000
汉字“中”已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
字母”x“,用unicode表示二进制0000 0000 0111 1000,所以unicode兼容ascii,也兼容万国,是世界的标准
这时候乱码问题消失了,所有的文档我们都使用。但是新问题也出现了,如果我们的文档通篇都是英文,你用unicode会比ascii耗费多一倍的空间,在存储和传输上效率也低。
本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字节根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字节才会被编码成4-6个字节。如果你要传输的文本包含大量英文字节,用UTF-8编码就能节省空间:
字节
ASCII
Unicode
UTF-8
A
01000001
00000000 01000001
01000001
中
x
01001110 00101101
11100100 10111000 10101101
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
如下是基本编码的种类和情况:
ASCII 占1个字节 只支持英文
GB2312 占2个字节 只支持6700+汉字
GBK 占2个字节 支持21000+汉字 GB2312的升级
Shift-JS 日本字符字节
ks_c_5601-1987 韩国编码
TIS-620 泰国编码
由于每个国家都有自己的编码,所以其对应关系也涵盖了自己国家的字符,但是以上编码都存在国家和地域局限性,仅涵盖本国字符,无法和他国字符形成对应关系。
这时候该Unicode出马了!-----“我Unicode不是针对某个编码,我是说地球上所有的国家编码都是辣鸡!”
Unicode占用2-4个字符,已经收录了136690个字符,并且在一直扩张中。
Unicode起到了两个作用:
1. 直接支持全球所有语言,全球各个国家的编码表可以丢掉了。
2. Unicode包含了全球所有国家编码的映射关系。
Unicode解决了字符和二进制的对应关系,但是使用Unicode表示一个字符,太浪费空间了。
在Python中,字符串是按unicode处理的,因为现在计算机的内存都超大,区区字符串可以轻松解决。
但是在网络传输和硬盘储存中,数据量增加1-3倍是无法容忍的。
为了解决储存和网络传输的问题,出现了UTF-8,对unicode进行转换压缩,以便节省硬盘储存和网络传输的空间。
1. UTF-8 使用1-4个字节动态表示所有字符;优先使用一个字符,如果无法满足就增加一个字符。其中英文占1个字符,欧洲语系占2个字符,东亚占3个字符,其他特殊字符占4个。
2. UTF-16 使用2或4个字节表示所有字符,优先使用2个字符,不够就用4个字符。
3 UTF-32 统一使用4个字节表示所有字符
总结: UTF是Unicode编码的一种在储存和网络传输中节省空间的编码方案
Unicode包含了跟全球所有国家编码的映射关系,你可以在Unicode编码表中找到全球任何国家的任何二进制对应的文字;
无论你法语,英文,汉语的软件,加载到内存中统统都是Unicode的格式。
四、Python3的执行过程中的编码
在Python3种执行代码的过程:
1. 解释器找到代码文件,把代码字符串按照文件定义的编码加载到内存,转成unicode;
2. 把代码字符串按照语法规则进行解释
3. 所有的变量字符都会一unicode的编码声明
但是在Python2中,它的默认编码不是unicode,而是ASCII。。。
为什么呢,因为unicode是从1994年才出生,而python作者鬼畜,在1989年就开始造出了Python。
unicode是晚辈啊,没办法,先用祖先ASCII编码吧,直到Python3,unicode晚辈才取代了ASCII。
Python2中有专门的unocide类型,作为区分和ASCII祖先区分;
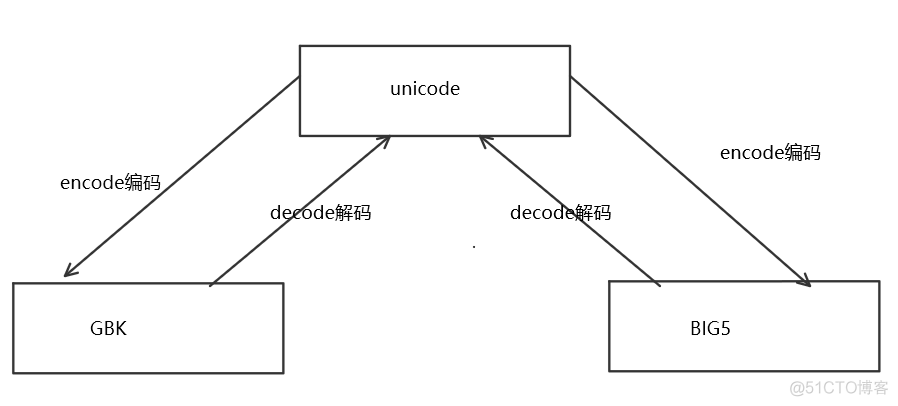
unicode和各种字符的关系如下,unicode到字符串是编码,字符串到unicode是解码。
五、Python中的bytes类型
bytes是字节类型,它把8个bits组成一个byte,把2进制的形式转化成16进制表示,这个转换只是让人类更加好读罢了。
Python2中的字符串更应该被叫做字节串,bytes == str,而Python3中是unicode == str。
Python中特有的Unicode类型,通过解码后,会变为unicode。
Python3中把字符串str规定为unocide,文件的默认编码是utf-8。
Pyhton3中除了把字符串的编码改成unicode,还把str和byte做了区别,str就是unicode格式的字符串,bytes是单纯的二进制字符。