最近在统计资产,正好看到了xlsxwriter这个表格生成模块,借此机会,熟悉一下,写点有趣的小案例,一开始想使用C++ QT图形化开发一套自动化运维平台,但后来发现不仅消耗时间而且需
最近在统计资产,正好看到了xlsxwriter这个表格生成模块,借此机会,熟悉一下,写点有趣的小案例,一开始想使用C++ QT图形化开发一套自动化运维平台,但后来发现不仅消耗时间而且需要解决QT Qssh远程模块的一些问题,后来没有使用QT做,xlsxwriter模块来做非常的简单,所以使用它。
上班不能摸鱼,我要努力摸鱼,不不不,学习,不然今天我摸鱼,明天鱼摸我。。
绘制磁盘统计(封装表格)
封装前需要先来找出规律: 先找到表格生成坐标与大小之间的比值关系,这是第一步。
import xlsxwriterworkbook = xlsxwriter.Workbook('chart_line.xlsx')
worksheet3 = workbook.add_worksheet("系统磁盘统计")
merge_format = workbook.add_format({
'bold': True,
'border': 1,
'align': 'center',
'valign': 'vcenter',
'fg_color': '#EEAEEE',
})
worksheet3.merge_range('A9:B12', '192.168.1.1', merge_format)
# -------------------------------------------------------------------------
head = ["IP地址","IP地址","路径","总容量","剩余容量","利用率"]
merge_format1 = workbook.add_format({
'bold': True,
'border': 1,
'align': 'center',#水平居中
'valign': 'vcenter',#垂直居中
'fg_color': '#AEEEEE',#颜色填充
})
worksheet3.write_row("A8:B12",head,merge_format1) #显示表头
worksheet3.merge_range('A8:B8',"IP地址",merge_format1) # 合并表头(合并第一个元素)
data1 = ["/etc/system/winsss/aaa","/proc/","/sys","/abc/lyshark"]
merge_format2 = workbook.add_format\
({'bold': True,'border': 1,'valign': 'vcenter','fg_color': '#D7E4BC','align': 'center'})
worksheet3.write_column("C9",data1,merge_format2)
worksheet3.set_column("C9:C9",30)
data2 = ["1024GG","2048GB","111GB","1111GB"]
merge_format3 = workbook.add_format\
({'bold': True,'border': 1,'valign': 'vcenter','fg_color': '#D7E4BC','align': 'center'})
worksheet3.write_column("D9",data2,merge_format3)
worksheet3.set_column("D9:D9",20)
data3 = ["1024GG","2048GB","111GB","22GB"]
merge_format4 = workbook.add_format\
({'bold': True,'border': 1,'valign': 'vcenter','fg_color': '#D7E4BC','align': 'center'})
worksheet3.write_column("E9",data3,merge_format4)
worksheet3.set_column("E9:E9",20)
data4= ["10%","50%","20%","33%"]
merge_format5 = workbook.add_format\
({'bold': True,'border': 1,'valign': 'vcenter','fg_color': '#D7E4BC','align': 'center'})
worksheet3.write_column("F9",data4,merge_format5)
worksheet3.set_column("F9:F9",20)
'''
val =
[
["IP地址","IP地址","路径","总容量","剩余容量","利用率"],
["/etc/","/proc","/user","/test","lyshark"],
["1GB","2GB","3GB","4GB","5GB"],
["1GB","2GB","3GB","4GB","5GB"],
["10%","10%","10%","10%","10%"]
]
SetDiskTable(address,val)
'''
workbook.close()
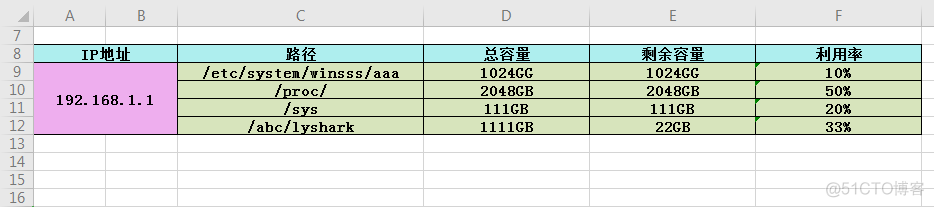
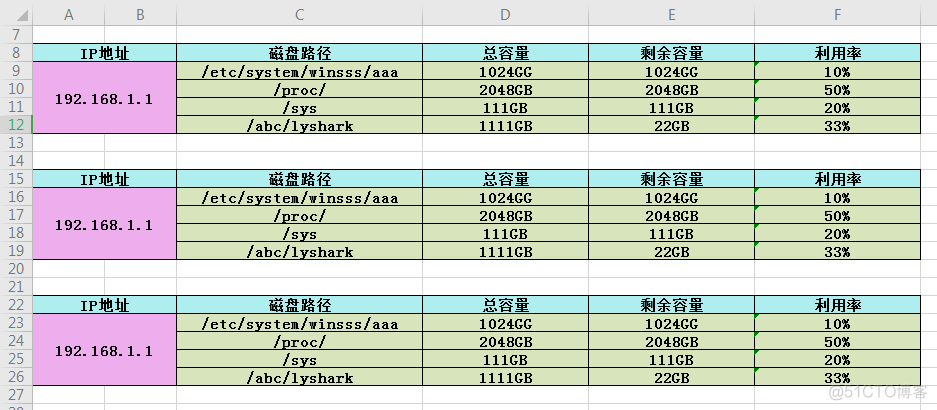
接着对其进行封装:找到规律后就要对其进行封装,封装成一个可直接调用的方法。
import xlsxwriterworkbook = xlsxwriter.Workbook('chart_line.xlsx')
worksheet = workbook.add_worksheet("系统磁盘统计")
def CreateDiskTable(address,data,section):
merge_format = workbook.add_format(
{'bold': True, 'border': 1, 'align': 'center', 'valign': 'vcenter', 'fg_color': '#EEAEEE'})
header_count = len(data[1])
merge_format1 = workbook.add_format(
{'bold': True, 'border': 1, 'align': 'center', 'valign': 'vcenter', 'fg_color': '#AEEEEE'})
# 根据磁盘路径计算出表格大小
header_range = "A{}:B{}".format(section,section+header_count)
worksheet.write_row(header_range, data[0], merge_format1) # 显示表头
# 计算合并表头偏移
header_merge_range = "A{}:B{}".format(section,section)
worksheet.merge_range(header_merge_range, "IP地址", merge_format1) # 合并表头(合并第一个元素)
# 计算出地址所占总单元格大小
address_merge_range = "A{}:B{}".format(section+1,section+header_count)
worksheet.merge_range(address_merge_range, address , merge_format) #需要计算出来,根据传入分区数量
# 通过计算得到磁盘路径所对应到表中的位置
merge_format2 = workbook.add_format(
{'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})
index_range = "C{}".format(section+1)
worksheet.write_column(index_range, data[1], merge_format2)
index_range = "C{}:C{}".format(section+1,section+1)
worksheet.set_column(index_range, 30)
# 计算出总容量对应到表中的位置
merge_format3 = workbook.add_format(
{'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})
index_range = "D{}".format(section + 1)
worksheet.write_column(index_range, data[2], merge_format3)
index_range = "D{}:D{}".format(section + 1, section + 1)
worksheet.set_column(index_range, 20)
# 计算出剩余容量对应到表中的位置
merge_format4 = workbook.add_format(
{'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})
index_range = "E{}".format(section + 1)
worksheet.write_column(index_range, data[3], merge_format4)
index_range = "E{}:E{}".format(section + 1, section + 1)
worksheet.set_column(index_range, 20)
# 计算出利用率对应到表中的位置
merge_format5 = workbook.add_format(
{'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})
index_range = "F{}".format(section + 1)
worksheet.write_column(index_range, data[4], merge_format5)
index_range = "F{}:F{}".format(section + 1, section + 1)
worksheet.set_column(index_range, 20)
# 返回计算后的表格的下两个单元的实际偏移位置
return section + header_count + 3
if __name__ == "__main__":
val = \
[
["IP地址", "IP地址", "磁盘路径", "总容量", "剩余容量", "利用率"],
["/etc/system/winsss/aaa", "/proc/", "/sys", "/abc/lyshark"],
["1024GG", "2048GB", "111GB", "1111GB"],
["1024GG", "2048GB", "111GB", "22GB"],
["10%", "50%", "20%", "33%"]
]
ref = CreateDiskTable("192.168.1.1",val,8)
print(ref)
ref = CreateDiskTable("192.168.1.1", val, ref)
CreateDiskTable("192.168.1.1", val, ref)
workbook.close()
继续更新一下
import xlsxwriterimport json,os,sys,math
import argparse
import paramiko
workbook = xlsxwriter.Workbook('disk.xlsx')
worksheet = workbook.add_worksheet("系统磁盘统计")
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
def BatchCMD(address,username,password,port,command):
try:
ssh.connect(hostname=address,username=username,password=password,port=port,timeout=2)
stdin , stdout , stderr = ssh.exec_command(command)
result = stdout.read()
if len(result) != 0:
result = str(result).replace("\\n", "\n")
result = result.replace("b'", "").replace("'", "")
return result
else:
return None
except Exception:
return None
def GetAllDiskSpace(address,username,password,port):
ref = []
cmd_dict = {"Linux\n" : "df | grep -v 'Filesystem' | awk '{print $6 \":\" $3 \":\" $4 \":\" $5}'",
"AIX\n" : "df | grep -v 'Filesystem' | awk '{print $4 \":\" $7}'"
}
os_version = BatchCMD(address,username,password,port,"uname")
for version,run_cmd in cmd_dict.items():
if(version == os_version):
os_ref = BatchCMD(address,username,password,port,run_cmd)
ref_list= os_ref.split("\n")
for each in ref_list:
if each != "":
ref_list = []
ref_list = str(each.split(":"))
ref.append(eval(ref_list))
return ref
def CreateDiskTable(address,data,section):
merge_format = workbook.add_format(
{'bold': True, 'border': 1, 'align': 'center', 'valign': 'vcenter', 'fg_color': '#EEAEEE'})
header_count = len(data[1])
merge_format1 = workbook.add_format(
{'bold': True, 'border': 1, 'align': 'center', 'valign': 'vcenter', 'fg_color': '#AEEEEE'})
# 根据磁盘路径计算出表格大小
header_range = "A{}:B{}".format(section,section+header_count)
worksheet.write_row(header_range, data[0], merge_format1) # 显示表头
# 计算合并表头偏移
header_merge_range = "A{}:B{}".format(section,section)
worksheet.merge_range(header_merge_range, "IP地址", merge_format1) # 合并表头(合并第一个元素)
# 计算出地址所占总单元格大小
address_merge_range = "A{}:B{}".format(section+1,section+header_count)
worksheet.merge_range(address_merge_range, address , merge_format) #需要计算出来,根据传入分区数量
# 通过计算得到磁盘路径所对应到表中的位置
merge_format2 = workbook.add_format(
{'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})
index_range = "C{}".format(section+1)
worksheet.write_column(index_range, data[1], merge_format2)
index_range = "C{}:C{}".format(section+1,section+1)
worksheet.set_column(index_range, 30)
# 计算出总容量对应到表中的位置
merge_format3 = workbook.add_format(
{'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})
index_range = "D{}".format(section + 1)
worksheet.write_column(index_range, data[2], merge_format3)
index_range = "D{}:D{}".format(section + 1, section + 1)
worksheet.set_column(index_range, 20)
# 计算出剩余容量对应到表中的位置
merge_format4 = workbook.add_format(
{'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})
index_range = "E{}".format(section + 1)
worksheet.write_column(index_range, data[3], merge_format4)
index_range = "E{}:E{}".format(section + 1, section + 1)
worksheet.set_column(index_range, 20)
# 计算出利用率对应到表中的位置
merge_format5 = workbook.add_format(
{'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})
index_range = "F{}".format(section + 1)
worksheet.write_column(index_range, data[4], merge_format5)
index_range = "F{}:F{}".format(section + 1, section + 1)
worksheet.set_column(index_range, 20)
# 返回计算后的表格的下两个单元的实际偏移位置
return section + header_count + 3
if __name__ == "__main__":
'''
val = \
[
["IP地址", "IP地址", "磁盘路径", "总容量", "剩余容量", "利用率"],
["/etc/system/winsss/aaa", "/proc/", "/sys", "/abc/lyshark"],
["1024GG", "2048GB", "111GB", "1111GB"],
["1024GG", "2048GB", "111GB", "22GB"],
["10%", "50%", "20%", "33%"]
]
ref = CreateDiskTable("192.168.1.1",val,3)
ref = CreateDiskTable("192.168.1.2", val, ref)
CreateDiskTable("192.168.1.3", val, ref)
'''
ref = GetAllDiskSpace("192.168.191.4","root","1233",22)
# 恒矩阵转树矩阵
ref_xor = list ( map(list,zip(*ref)) )
header = ["IP地址", "IP地址", "磁盘路径", "已使用", "剩余容量", "利用率"]
ref_xor.insert(0,header)
print(ref_xor)
CreateDiskTable("192.168.191.4", ref_xor, 2)
workbook.close()
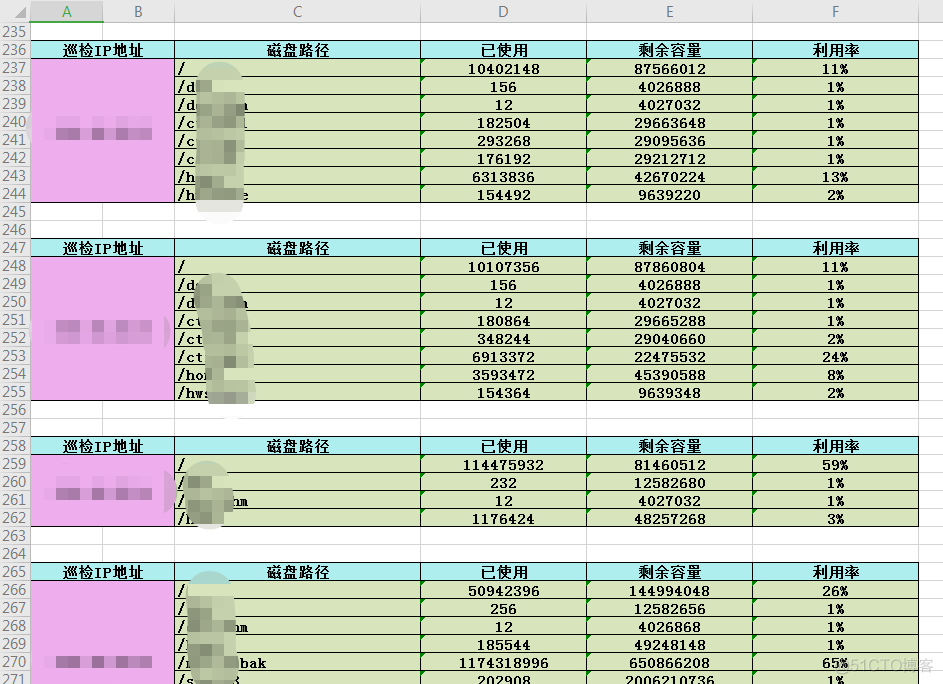
增加SSH功能遵循调用规范:
import xlsxwriterimport paramiko
import os,sys,datetime
disk_name = "disk_" + str(datetime.datetime.now()).split(" ")[0] + ".xlsx"
workbook = xlsxwriter.Workbook(disk_name)
worksheet = workbook.add_worksheet("系统磁盘统计")
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 封装远程命令执行
def BatchCMD(address,username,password,port,command):
try:
ssh.connect(hostname=address,username=username,password=password,port=port,timeout=2)
stdin , stdout , stderr = ssh.exec_command(command)
result = stdout.read()
if len(result) != 0:
result = str(result).replace("\\n", "\n")
result = result.replace("b'", "").replace("'", "")
return result
else:
return None
except Exception:
return None
# 获取磁盘数据
def GetAllDiskSpace(address,username,password,port):
ref = []
cmd_dict = {"Linux\n" : "df | grep -v 'Filesystem' | awk '{print $6 \":\" $3 \":\" $4 \":\" $5}'",
"AIX\n" : "df | grep -v 'Filesystem' | awk '{print $7 \":\" $5 \":\" $3 \":\" $4}'"
}
os_version = BatchCMD(address,username,password,port,"uname")
for version,run_cmd in cmd_dict.items():
if(version == os_version):
os_ref = BatchCMD(address,username,password,port,run_cmd)
ref_list= os_ref.split("\n")
for each in ref_list:
if each != "":
ref_list = str(each.split(":"))
ref.append(eval(ref_list))
return ref
# 封装的绘制主机表格方法
def CreateDiskTable(address,data,section):
merge_format = workbook.add_format(
{'bold': True, 'border': 1, 'align': 'center', 'valign': 'vcenter', 'fg_color': '#EEAEEE'})
header_count = len(data[1])
merge_format1 = workbook.add_format(
{'bold': True, 'border': 1, 'align': 'center', 'valign': 'vcenter', 'fg_color': '#AEEEEE'})
# 根据磁盘路径计算出表格大小
header_range = "A{}:B{}".format(section,section+header_count)
worksheet.write_row(header_range, data[0], merge_format1) # 显示表头
# 计算合并表头偏移
header_merge_range = "A{}:B{}".format(section,section)
worksheet.merge_range(header_merge_range, "巡检IP地址", merge_format1) # 合并表头(合并第一个元素)
# 计算出地址所占总单元格大小
address_merge_range = "A{}:B{}".format(section+1,section+header_count)
worksheet.merge_range(address_merge_range, address , merge_format) #需要计算出来,根据传入分区数量
# 通过计算得到磁盘路径所对应到表中的位置
merge_format2 = workbook.add_format(
{'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC'})
index_range = "C{}".format(section+1)
worksheet.write_column(index_range, data[1], merge_format2)
index_range = "C{}:C{}".format(section+1,section+1)
worksheet.set_column(index_range, 30)
# 计算出总容量对应到表中的位置
merge_format3 = workbook.add_format(
{'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})
index_range = "D{}".format(section + 1)
worksheet.write_column(index_range, data[2], merge_format3)
index_range = "D{}:D{}".format(section + 1, section + 1)
worksheet.set_column(index_range, 20)
# 计算出剩余容量对应到表中的位置
merge_format4 = workbook.add_format(
{'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})
index_range = "E{}".format(section + 1)
worksheet.write_column(index_range, data[3], merge_format4)
index_range = "E{}:E{}".format(section + 1, section + 1)
worksheet.set_column(index_range, 20)
# 计算出利用率对应到表中的位置
merge_format5 = workbook.add_format(
{'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})
index_range = "F{}".format(section + 1)
worksheet.write_column(index_range, data[4], merge_format5)
index_range = "F{}:F{}".format(section + 1, section + 1)
worksheet.set_column(index_range, 20)
# 返回计算后的表格的下两个单元的实际偏移位置
return section + header_count + 3
if __name__ == "__main__":
with open("./unix_disk.db","r") as fp:
fp_file = fp.readlines()
ref_index = 2
for each in fp_file:
data = eval(each)
ref = GetAllDiskSpace(data[0], data[2], data[3], 22)
try:
print("[+] 正在绘制 {} 表格数据,这是一台: {} 主机".format(data[0],data[1]))
# 恒矩阵转树矩阵
ref_xor = list(map(list, zip(*ref)))
header = ["IP地址", "IP地址", "磁盘路径", "已使用", "剩余容量", "利用率"]
# 将表头追加到矩阵头部
ref_xor.insert(0, header)
# 绘制表格,ref_index 递归自身,每次定位到下一个需要更新的表
ref_index = CreateDiskTable(data[0], ref_xor, ref_index)
except Exception:
pass
workbook.close()
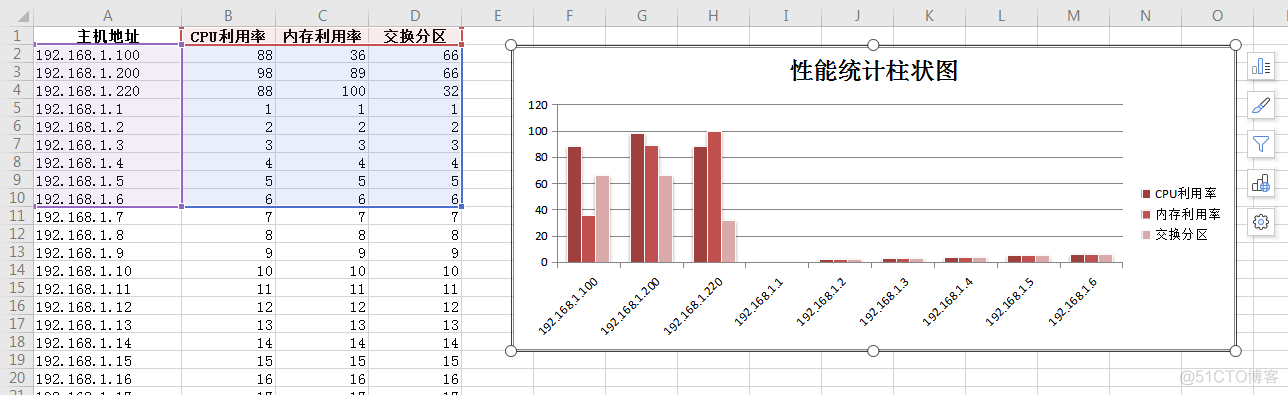
绘制内存统计图(柱状图)
简单的案例: 主要统计前十计数信息,先远程拉取数据,然后内部矩阵排序,关联柱状图前十个元素,即可。
import xlsxwriterworkbook = xlsxwriter.Workbook("xxx.xlsx")
worksheet = workbook.add_worksheet()
headings = ["主机地址", "CPU利用率", "内存利用率","交换分区"]
data = [["192.168.1.100", 88, 36,66], ["192.168.1.200", 98, 89,66], ["192.168.1.220", 88, 100,32]]
# 循环添加模拟数据
for i in range(1,100):
s = ["192.168.1.{}".format(i),i,i,i]
data.append(s)
# 定义表格样式
head_style = workbook.add_format({"bold": True, "align": "center", "font": 13})
# 逐条写入数据
worksheet.write_row("A1", headings, head_style)
for i in range(0, len(data)):
worksheet.write_row("A{}".format(i + 2), data[i])
# 添加柱状图
chart = workbook.add_chart({"type": "column"})
chart.add_series({
"name": "=Sheet1!$B$1", # 图例项
"categories": "=Sheet1!$A$2:$A$10", # X轴 Item名称
"values": "=Sheet1!$B$2:$B$10" # X轴Item值
})
chart.add_series({
"name": "=Sheet1!$C$1",
"categories": "=Sheet1!$A$2:$A$10",
"values": "=Sheet1!$C$2:$C$10"
})
chart.add_series({
"name": "=Sheet1!$D$1",
"categories": "=Sheet1!$A$2:$A$10",
"values": "=Sheet1!$D$2:$D$10"
})
# 添加柱状图标题
chart.set_title({"name": "性能统计柱状图"})
chart.set_style(12)
# 在G2处绘制
worksheet.insert_chart("G2", chart)
workbook.close()
先来获取到CPU数据: 通过SSH拉取CPU数据,然后按照最后一个值进行排序,由大到小以此放入二维数组中。
import xlsxwriterimport paramiko
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
def BatchCMD(address,username,password,port,command):
try:
ssh.connect(hostname=address,username=username,password=password,port=port,timeout=2)
stdin , stdout , stderr = ssh.exec_command(command)
result = stdout.read()
if len(result) != 0:
result = str(result).replace("\\n", "\n")
result = result.replace("b'", "").replace("'", "")
return result
else:
return None
except Exception:
return None
def GetMemLoad(address,username,password,port):
ref = []
cmd_dict = {"Linux\n" : "free | grep \"Mem\" | awk '{print $2 \":\" $4}'",
"AIX\n" : "svmon | grep \"memory\" | awk '{print $2 \":\" $4}'"
}
# aix 总大小、剩余大小 需要x4
os_version = BatchCMD(address,username,password,port,"uname")
for version,run_cmd in cmd_dict.items():
if(version == os_version):
os_ref = BatchCMD(address,username,password,port,run_cmd)
ref_list= os_ref.split("\n")
for each in ref_list:
if each != "":
print(each)
return ref
def GetCPULoad(address,username,password,port):
ref = []
# 用户占用,系统占用,空闲
cmd_dict = {"Linux\n" : "vmstat | tail -n 1 | awk '{print $13 \":\" $14 \":\" $15}'",
"AIX\n" : "vmstat | tail -n 1 | awk '{print $14 \":\" $15 \":\" $16}'"
}
os_version = BatchCMD(address,username,password,port,"uname")
for version,run_cmd in cmd_dict.items():
if(version == os_version):
os_ref = BatchCMD(address,username,password,port,run_cmd)
ref_list= os_ref.split("\n")
for each in ref_list:
if each != "":
ref = each.split(":")
ref[2] = str(100 - int(ref[2]))
ref.insert(0,address)
return ref
# 排序函数,以第三列为条件排列
def takeSecond(elem):
return int(elem[3])
if __name__ == "__main__":
workbook = xlsxwriter.Workbook("test1111.xlsx")
worksheet = workbook.add_worksheet()
# 设置头部数据
headings = ["主机地址", "CPU内核态", "CPU用户态", "总利用率"]
head_style = workbook.add_format({"bold": True, "align": "center" ,"fg_color":"#D7E4BC"})
worksheet.write_row("A1", headings, head_style)
# 设置头部列宽
worksheet.set_column("A1:D1",15)
# 统计数据并排序
cpu_data = []
with open("./unix_disk.db","r") as fp:
fp_file = fp.readlines()
for each in fp_file:
try:
data = eval(each)
ref = GetCPULoad(data[0], data[2], data[3], 22)
if(len(ref) !=0):
cpu_data.append(ref)
else:
continue
except Exception:
pass
# 排序,统计第三列数据,将最大的放在最前面,以此向下
cpu_data.sort(key=takeSecond, reverse=True)
print(cpu_data)
for i in range(0, len(cpu_data)):
worksheet.write_row("A{}".format(i + 2), cpu_data[i])
workbook.close()
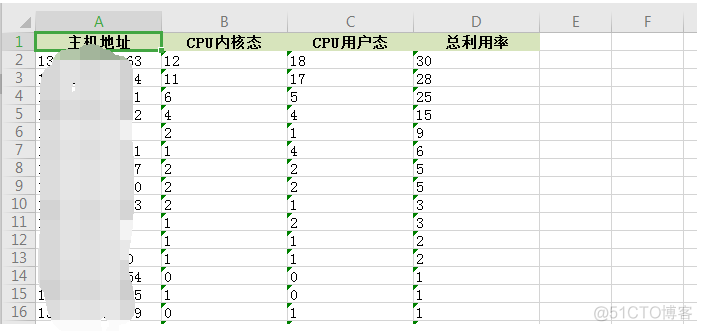
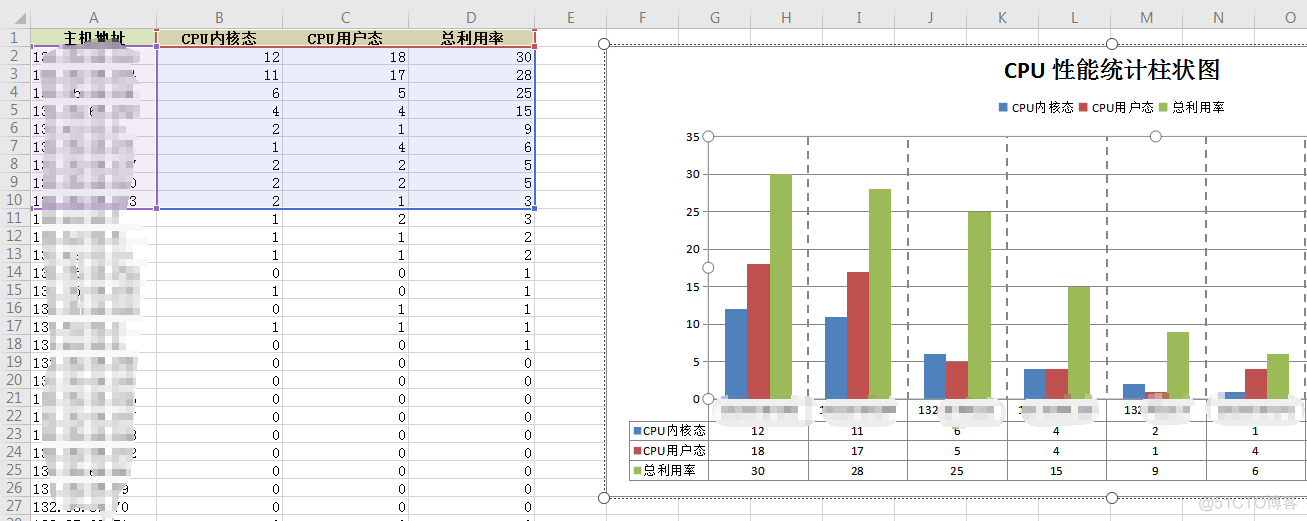
将绘图方法与SSH结合: 运行后即可统计出机器的所有CPU数据,并将排名前十的机器使用情况列出来。
import xlsxwriterimport paramiko
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
workbook = xlsxwriter.Workbook("test333.xlsx")
worksheet = workbook.add_worksheet()
def BatchCMD(address,username,password,port,command):
try:
ssh.connect(hostname=address,username=username,password=password,port=port,timeout=2)
stdin , stdout , stderr = ssh.exec_command(command)
result = stdout.read()
if len(result) != 0:
result = str(result).replace("\\n", "\n")
result = result.replace("b'", "").replace("'", "")
return result
else:
return None
except Exception:
return None
def GetCPULoad(address,username,password,port):
ref = []
# 用户占用,系统占用,空闲
cmd_dict = {"Linux\n" : "vmstat | tail -n 1 | awk '{print $13 \":\" $14 \":\" $15}'",
"AIX\n" : "vmstat | tail -n 1 | awk '{print $14 \":\" $15 \":\" $16}'"
}
os_version = BatchCMD(address,username,password,port,"uname")
for version,run_cmd in cmd_dict.items():
if(version == os_version):
os_ref = BatchCMD(address,username,password,port,run_cmd)
ref_list= os_ref.split("\n")
for each in ref_list:
if each != "":
ref = each.split(":")
ref[2] = str(100 - int(ref[2]))
ref.insert(0,address)
ref[1] = int(ref[1])
ref[2] = int(ref[2])
ref[3] = int(ref[3])
return ref
# 排序函数,以第三列为条件排列
def takeSecond(elem):
return int(elem[3])
# 添加柱状统计图
def AddGraphical():
# 添加柱状图
chart = workbook.add_chart({"type": "column"})
chart.add_series({
"name": "=Sheet1!$B$1", # 图例项(也就是CPU内核态)
"categories": "=Sheet1!$A$2:$A$10", # X轴 Item名称
"values": "=Sheet1!$B$2:$B$10" # X轴Item值
})
chart.add_series({
"name": "=Sheet1!$C$1",
"categories": "=Sheet1!$A$2:$A$10",
"values": "=Sheet1!$C$2:$C$10"
})
chart.add_series({
"name": "=Sheet1!$D$1",
"categories": "=Sheet1!$A$2:$A$10",
"values": "=Sheet1!$D$2:$D$10"
})
# 添加柱状图标题
chart.set_title({"name": "CPU 性能统计柱状图"})
# chart.set_style(8)
chart.set_x_axis({
'major_gridlines': {
'visible': True,
'line': {'width': 1.25, 'dash_type': 'dash'}
},
})
chart.set_size({'width': 900, 'height': 500})
chart.set_legend({'position': 'top'})
chart.set_table({'show_keys': True})
# 在F2处绘制
worksheet.insert_chart("F2", chart)
if __name__ == "__main__":
# 设置头部数据
headings = ["主机地址", "CPU内核态", "CPU用户态", "总利用率"]
head_style = workbook.add_format({"bold": True, "align": "center" ,"fg_color":"#D7E4BC"})
worksheet.write_row("A1", headings, head_style)
# 设置头部列宽
worksheet.set_column("A1:D1",15)
# 统计数据并排序
cpu_data = []
with open("./unix_disk.db","r") as fp:
fp_file = fp.readlines()
for each in fp_file:
try:
data = eval(each)
ref = GetCPULoad(data[0], data[2], data[3], 22)
if(len(ref) !=0):
print(ref)
cpu_data.append(ref)
else:
continue
except Exception:
pass
# 排序,统计第三列数据,将最大的放在最前面,以此向下
cpu_data.sort(key=takeSecond, reverse=True)
print(cpu_data)
# 将数据批量添加到表格中
for i in range(0, len(cpu_data)):
worksheet.write_row("A{}".format(i + 2), cpu_data[i])
# 开始绘图
AddGraphical()
workbook.close()
收集主机负载(条形图)
制作Excel绘图:
import xlsxwriterworkbook = xlsxwriter.Workbook("xxx.xlsx")
worksheet = workbook.add_worksheet()
headings = ["获取时间", "1分钟负载", "5分钟负载","15分钟负载"]
data = [["12:01", 0.05, 0.7,0.006], ["12:02", 0.5, 0.08,0.06], ["12:03", 0.7, 1,2.1]]
# 定义表格样式
head_style = workbook.add_format({"bold": True, "align": "center" ,"fg_color":"#D7E4BC"})
worksheet.set_column("A1:D1",15)
# 逐条写入数据
worksheet.write_row("A1", headings, head_style)
for i in range(0, len(data)):
worksheet.write_row("A{}".format(i + 2), data[i])
# 添加条形图,显示前十个元素
chart = workbook.add_chart({"type": "line"})
chart.add_series({
"name": "=Sheet1!$B$1", # 图例项
"categories": "=Sheet1!$A$2:$A$10", # X轴 Item名称
"values": "=Sheet1!$B$2:$B$10" # X轴Item值
})
chart.add_series({
"name": "=Sheet1!$C$1",
"categories": "=Sheet1!$A$2:$A$10",
"values": "=Sheet1!$C$2:$C$10"
})
chart.add_series({
"name": "=Sheet1!$D$1",
"categories": "=Sheet1!$A$2:$A$10",
"values": "=Sheet1!$D$2:$D$10"
})
# 添加柱状图标题
chart.set_title({"name": "负载统计条形图"})
# chart.set_style(8)
chart.set_size({'width': 1000, 'height': 500})
chart.set_legend({'position': 'top'})
# 在F2处绘制
worksheet.insert_chart("F2", chart)
workbook.close()
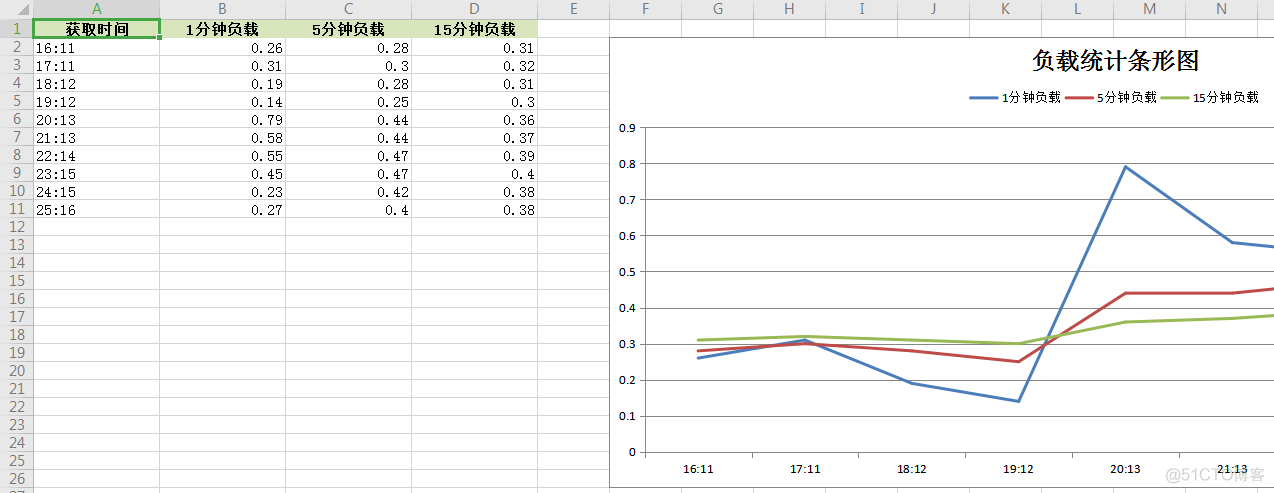
封装SSH执行模块: 封装上方的绘图模块,与SSH模块实现图形绘制,收集十分钟负载。
import xlsxwriterimport paramiko
import datetime
import time
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
workbook = xlsxwriter.Workbook("load_avg.xlsx")
worksheet = workbook.add_worksheet()
def BatchCMD(address,username,password,port,command):
try:
ssh.connect(hostname=address,username=username,password=password,port=port,timeout=2)
stdin , stdout , stderr = ssh.exec_command(command)
result = stdout.read()
if len(result) != 0:
result = str(result).replace("\\n", "\n")
result = result.replace("b'", "").replace("'", "")
return result
else:
return None
except Exception:
return None
def GetCPUAvg(address,username,password,port):
ref = []
cmd_dict = {"Linux\n" : "cat /proc/loadavg | awk '{print $1 \":\" $2 \":\" $3}'",
"AIX\n" : "vmstat | tail -n 1 | awk '{print $14 \":\" $15 \":\" $16}'"
}
os_version = BatchCMD(address,username,password,port,"uname")
for version,run_cmd in cmd_dict.items():
if(version == os_version):
os_ref = BatchCMD(address,username,password,port,run_cmd)
ref_list= os_ref.split("\n")
for each in ref_list:
if each != "":
ref = each.split(":")
str_to_date = datetime.datetime.now()
now_date = str(str_to_date.minute) + ":" + str(str_to_date.second)
ref.insert(0,now_date)
ref[1] = float(ref[1])
ref[2] = float(ref[2])
ref[3] = float(ref[3])
return ref
# 绘制聚合图形
def AddGraphical(data):
#data = [["12:01", 0.05, 0.7, 0.006], ["12:02", 0.5, 0.08, 0.06], ["12:03", 0.7, 1, 2.1]]
# 定义表格样式
head_style = workbook.add_format({"bold": True, "align": "center", "fg_color": "#D7E4BC"})
worksheet.set_column("A1:D1", 15)
# 逐条写入数据
headings = ["获取时间", "1分钟负载", "5分钟负载", "15分钟负载"]
worksheet.write_row("A1", headings, head_style)
for i in range(0, len(data)):
worksheet.write_row("A{}".format(i + 2), data[i])
# 添加条形图,显示前十个元素
chart = workbook.add_chart({"type": "line"})
chart.add_series({
"name": "=Sheet1!$B$1", # 图例项
"categories": "=Sheet1!$A$2:$A$10", # X轴 Item名称
"values": "=Sheet1!$B$2:$B$10" # X轴Item值
})
chart.add_series({
"name": "=Sheet1!$C$1", # 第一个线条(图例)
"categories": "=Sheet1!$A$2:$A$10",
"values": "=Sheet1!$C$2:$C$10"
})
chart.add_series({
"name": "=Sheet1!$D$1", # 第二个线条(图例)
"categories": "=Sheet1!$A$2:$A$10",
"values": "=Sheet1!$D$2:$D$10"
})
# 添加柱状图标题
chart.set_title({"name": "负载统计条形图"})
# chart.set_style(8)
chart.set_size({'width': 900, 'height': 500})
chart.set_legend({'position': 'top'})
# 在F2处绘制
worksheet.insert_chart("F2", chart)
# 收集10分钟的负载数据
def GetLoad():
ref_date = []
for item in range(10):
ret = GetCPUAvg("192.168.1.11", "root", "123123", "22")
ref_date.append(ret)
time.sleep(60)
print(ret)
return ref_date
if __name__ == "__main__":
date = []
date = GetLoad()
AddGraphical(date)
workbook.close()
绘制设备种类(饼状图)
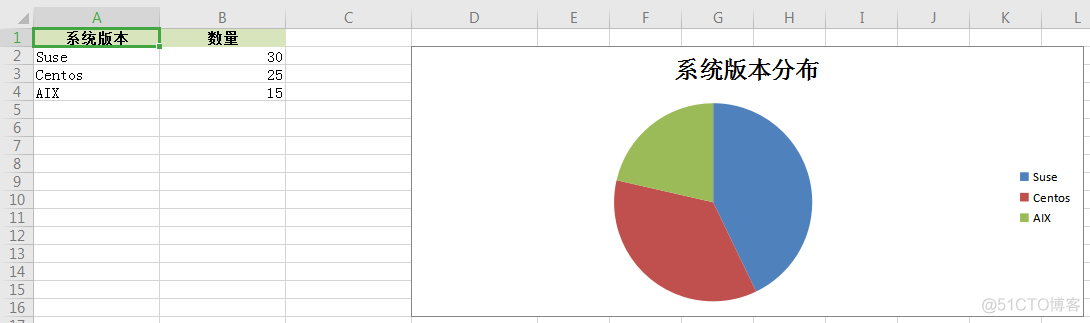
制作Excel绘图: 先来实现绘图。
import xlsxwriterworkbook = xlsxwriter.Workbook("pie.xlsx")
worksheet = workbook.add_worksheet()
data = [["Suse", 30 ], ["Centos",25], ["AIX",15]]
# 定义表格样式
head_style = workbook.add_format({"bold": True, "align": "center" ,"fg_color":"#D7E4BC"})
worksheet.set_column("A1:D1",15)
# 逐条写入数据
headings = ["系统版本", "数量"]
worksheet.write_row("A1", headings, head_style)
for i in range(0, len(data)):
worksheet.write_row("A{}".format(i + 2), data[i])
# 添加条形图,显示前十个元素
chart = workbook.add_chart({"type": "pie"})
chart.add_series({
"name": "=Sheet1!$B$1", # 图例项
"categories": "=Sheet1!$A$2:$A$4", # X轴 Item名称
"values": "=Sheet1!$B$2:$B$4" # X轴Item值
})
# 添加饼状图
chart.set_title({"name": "系统版本分布"})
chart.set_size({'width': 600, 'height': 300})
chart.set_legend({'position': 'right'})
# 在D2处绘制
worksheet.insert_chart("D2", chart)
workbook.close()
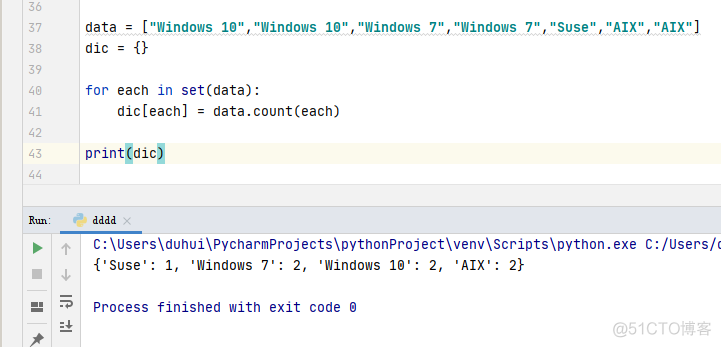
实现收集数据并绘图: 收集数据就不写了,主要说说统计个数,我们可以每次收集到数据后放入一个列表中,最后使用set集合将其自动去重,去重后在对特定的值进行计数统计即可。
data = ["Windows 10","Windows 10","Windows 7","Windows 7","Suse","AIX","AIX"]dic = {}
for each in set(data):
dic[each] = data.count(each)
print(dic)
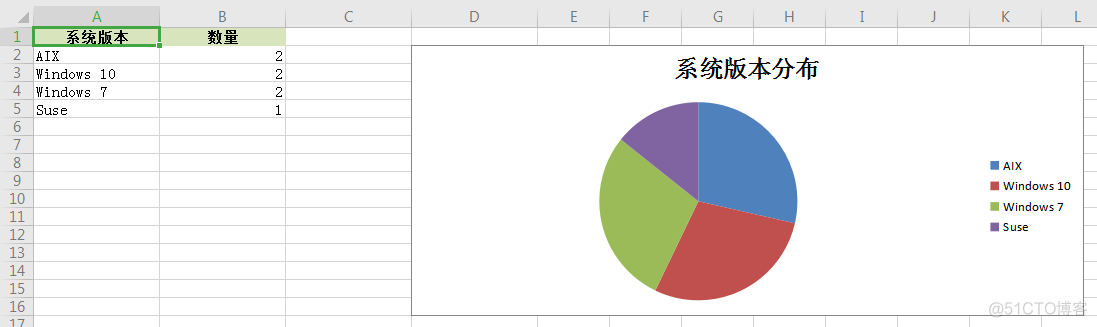
继续实现绘图即可。
import xlsxwriterworkbook = xlsxwriter.Workbook("pie.xlsx")
worksheet = workbook.add_worksheet()
# 去重后的数据在dic
data = ["Windows 10","Windows 10","Windows 7","Windows 7","Suse","AIX","AIX"]
dic = {}
for each in set(data):
dic[each] = data.count(each)
print("构建字典: {}".format(dic))
print("字典数: {}".format(len(dic)))
# 字典转列表
new_data = []
for k,v in dic.items():
new_list = [k,v]
new_data.append(new_list)
print("字典转为列表:{}".format(new_data))
#data = [["Suse", 30 ], ["Centos",25], ["AIX",15]]
# 定义表格样式
head_style = workbook.add_format({"bold": True, "align": "center" ,"fg_color":"#D7E4BC"})
worksheet.set_column("A1:D1",15)
# 逐条写入数据
headings = ["系统版本", "数量"]
worksheet.write_row("A1", headings, head_style)
for i in range(0, len(new_data)):
worksheet.write_row("A{}".format(i + 2), new_data[i])
# 添加饼状图图例
chart = workbook.add_chart({"type": "pie"})
chart.add_series({
"name": "=Sheet1!$B$1", # 图例项
"categories": "=Sheet1!$A$2:$A${}".format(len(dic)+1), # X轴 Item名称
"values": "=Sheet1!$B$2:$B${}".format(len(dic)+1) # X轴Item值
})
# 添加饼状图
chart.set_title({"name": "系统版本分布"})
chart.set_size({'width': 600, 'height': 300})
chart.set_legend({'position': 'right'})
# 在D2处绘制
worksheet.insert_chart("D2", chart)
workbook.close()
版权声明:本博客文章与代码均为学习时整理的笔记,文章 [均为原创] 作品,转载请 [添加出处] ,您添加出处是我创作的动力!