Python autoscraper 模块是什么 autoscraper 是一款 Python 第三方爬虫模块,它实现了很多便捷采集数据的功能。 开源地址为:autoscraper 如果访问受影响,可以直接在 CSDN 访问镜像库。 镜像库地
Python autoscraper 模块是什么
autoscraper 是一款 Python 第三方爬虫模块,它实现了很多便捷采集数据的功能。
开源地址为:autoscraper
如果访问受影响,可以直接在 CSDN 访问镜像库。
镜像库地址:autoscraper
模块安装使用如下命令:
pip install autoscraper怎么用
上手案例
我们拿 CSDN 问答频道列表页做一个测试,首先打开页面获取一个标题文本。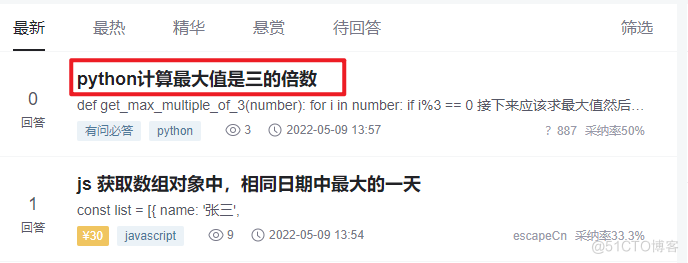
运行代码,直接就获取到了所有类似数据。
 此时你会发现这款自动爬虫具备如下便捷功能。
此时你会发现这款自动爬虫具备如下便捷功能。
它能快速且智能获取指定网站上的数据,数据可以是网页文本、URL 地址或者是其它 HTML 元素。
它还可以学习抓取规则并返回类似的元素。
学习抓取规则并返回类似的元素
使用上述代码中的 scraper 对象的 get_result_similar() 方法,就可以学习抓取规则,采集新的页面,例如下述代码。
# 找到一个新的列表页 https://ask.csdn.net/channel/2 result1 = scraper.get_result_similar('https://ask.csdn.net/channel/2') print(result1)除了 get_result_similar() 方法外,可以使用 get_result_exact() 获取确切的结果,例如上文第一次获取的是首个问题位置的数据,获取第二页时,也是获取该值。
抓取多个值
在 wanted_list 位置可以编写多个匹配规则,例如下述代码。
# 抓取多个值 wanted_list = ["python计算最大值是三的倍数",'2022-05-09 14:06']抓取模型还可以保存在本地,也可以重启使用
# 指定保存的文件路径 scraper.save('ask_csdn') # 重新使用 scraper.load('ask_csdn')保存的文件是一个 JSON 字符串,格式如下所示。
扩展场景
最后一句话:该库非常适合变化不大的页面采集,使用特别少的代码即可实现,如果网站是基于大数据推送的,就不太适合了。