12306抢票爬虫 先直接上一下效果图吧: 图片上信息是抢票成功后的界面 1、技术路线 selenium + chromedriver 2、思路分析 (1)、模拟浏览器登录抢票界面,手动进行登录 (2)、登录完成后
12306抢票爬虫
先直接上一下效果图吧:
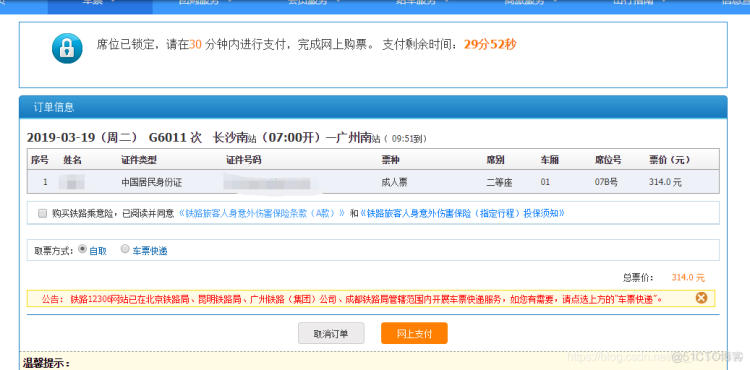
图片上信息是抢票成功后的界面
1、技术路线
selenium + chromedriver
2、思路分析
(1)、模拟浏览器登录抢票界面,手动进行登录
(2)、登录完成后让浏览器跳转到购票界面
(3)、手动输入出发地、目的地、 出发日,检查上面三个信息输入完成后,找到查询按钮,进行车次查询
(4)、查找我们需要的车次,看下是否有余票(显示有或数子),找到车次的预定的按钮,进行点击,如果没有以上两种情况出现,就循环查询
(5)、一旦检查到有票,执行预定按钮的点击事件,找到乘客信息,执行点击事件,再找到提交订单按钮,执行点击事件
(6)、点击完提交订单按钮,会弹出确认的对话框,找到确认按钮,执行点击事件,完成抢票
(7)、之后完成付款操作
3、直接上代码
# coding=utf8from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC #期望的条件
from selenium.webdriver.common.by import By
class Qiangpiao(object):
# 初始化函数
def __init__(self):
self.login_url = "https://kyfw.12306.cn/otn/resources/login.html"
self.initmy_url = "https://kyfw.12306.cn/otn/view/index.html"
self.search_url = "https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc"
self.passenger_url ="https://kyfw.12306.cn/otn/confirmPassenger/initDc"
# 驱动chrome浏览器进行操作
self.driver = webdriver.Chrome(
executable_path="D:\Pycharm2017\chromedriver.exe")
def wait_input(self):
self.from_station = input("起始站:")
self.to_station = input("目的地:")
# 出发时间必须严格和网上格式保持一致:yyyy-mm-dd
self.depart_time = input("出发时间:")
self.passengers = input("乘客姓名(如果有多名乘客,请用逗号(英文)隔开:").split(",")
self.trains = input("乘车车次(如果有多趟车次,请用逗号(英文)隔开:").split(",")
def _login(self):
self.driver.get(self.login_url)
# 显示等待(解释:你与心上人约会,以对方来或不来为等待条件即事件是否发生为条件)
# 隐示等待(解释:你与心上人约会,以等待时间为条件)
WebDriverWait(self.driver,1000).until(EC.url_to_be(self.initmy_url))
print("登录成功!")
def _order_ticket(self):
# 1、跳转到查余票的界面
self.driver.get(self.search_url)
# 2、等待出发地是否输入正确
WebDriverWait(self.driver,1000).until(
EC.text_to_be_present_in_element_value((By.ID,"fromStationText"),self.from_station)
)
# 3、等待目的地输入是否正确
WebDriverWait(self.driver,1000).until(
EC.text_to_be_present_in_element_value((By.ID,"toStationText"),self.to_station)
)
# 4、等待出发日期是否输入正确
WebDriverWait(self.driver,1000).until(
EC.text_to_be_present_in_element_value((By.ID,"train_date"),self.depart_time)
)
# 5、等待查询按钮是否可用
WebDriverWait(self.driver,1000).until(
EC.element_to_be_clickable((By.ID,"query_ticket"))
)
# 6、如果可以点击找到查询按钮执行点击事件
searchBtn = self.driver.find_element_by_id("query_ticket")
searchBtn.click()
# 7、点击查询按钮之后等待车票信息页面被加载完成
WebDriverWait(self.driver, 1000).until(
EC.presence_of_element_located((By.XPATH, ".//tbody[@id = 'queryLeftTable']/tr"))
)
# 8、找到所有没有datatrain属性的tr标签
tr_list = self.driver.find_elements_by_xpath(".//tbody[@id ='queryLeftTable']/tr[not(@datatran)]")
# 9、遍历所有满足条件的tr标签
for tr in tr_list:
train_number = tr.find_element_by_class_name("number").text
if train_number in self.trains:
left_ticket = tr.find_element_by_xpath(".//td[4]").text #找到第四个td标签下的文本
if left_ticket == "有" or left_ticket.isdigit: #判断输入的车次是否在列表中
orderBotton = tr.find_element_by_class_name('btn72')
orderBotton.click()
# 等待是否来到了确认乘客的页面
WebDriverWait(self.driver, 1000).until(EC.url_to_be(self.passenger_url))
# 等待所有乘客信息是否被加载进来了
WebDriverWait(self.driver, 1000).until(
EC.presence_of_element_located((By.XPATH, ".//ul[@id = 'normal_passenger_id']/li")))
# 获取所有乘客信息
passanger_labels = self.driver.find_elements_by_xpath(".//ul[@id = 'normal_passenger_id']/li/label")
for passanger_label in passanger_labels: # 遍历所有的label标签
name = passanger_label.text
if name in self.passengers: # 判断名字是否与之前输入的名字重合
passanger_label.click() # 执行点击操作
# 获取提交订单的按钮
submitBotton = self.driver.find_element_by_id("submitOrder_id")
submitBotton.click()
# 显示等待确人订单对话框是否出现
WebDriverWait(self.driver, 1000).until(
EC.presence_of_element_located((By.CLASS_NAME, "dhtmlx_wins_body_outer"))
)
# 显示等待确认按钮是否加载出现,出现后执行点击操作
WebDriverWait(self.driver, 1000).until(
EC.presence_of_element_located((By.ID, "qr_submit_id"))
)
confirmBtn = self.driver.find_element_by_id("qr_submit_id")
confirmBtn.click()
while confirmBtn:
confirmBtn.click()
confirmBtn = self.driver.find_element_by_id("qr_submit_id")
return
def run(self):
self.wait_input()
self._login()
self._order_ticket()
if __name__ == '__main__':
spider = Qiangpiao()
spider.run()
4、运行效果图就是最上面那一张图片
5、配置说明
请使用前确保已安装好一个python编译器并完成pyhon的配置windows下推荐使用pycharm,并下载chrome的chromedriver驱动,并将chromedriver配置进python包(如果没配置只要指定路径亦可!)
复制代码按命令行提示操作即可完成抢票
