最终的效果图: 完整代码: #coding:utf-8 # Filename:return_message5.py # 被关注回复'Hello World!' # 收到 笑话 回复糗百笑话,收到收到 电影 回复电影天堂最新电影, # 收到 blog 回复我的简书博客
最终的效果图:
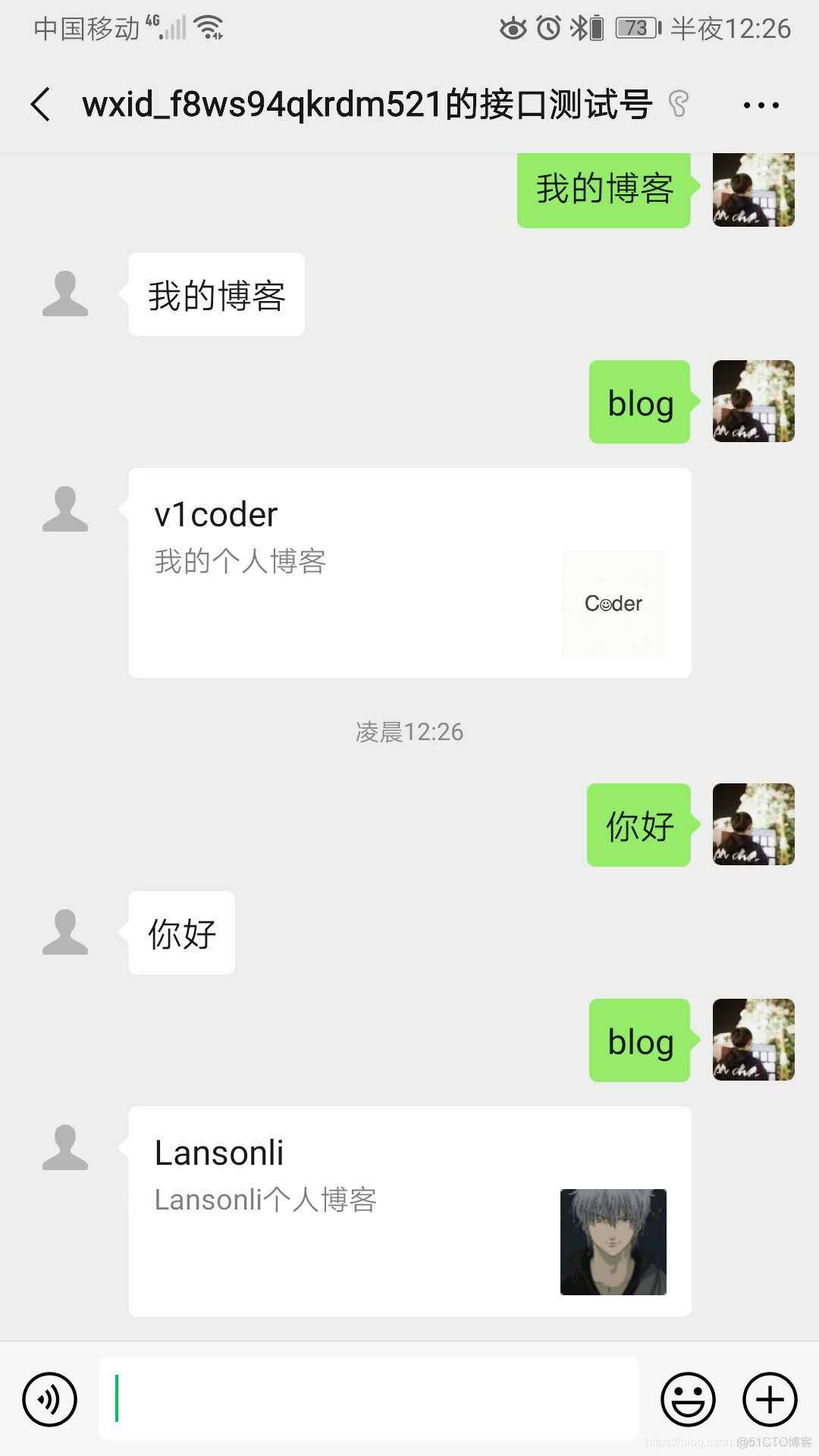
完整代码:
# Filename:return_message5.py
# 被关注回复'Hello World!'
# 收到 笑话 回复糗百笑话,收到收到 电影 回复电影天堂最新电影,
# 收到 blog 回复我的简书博客,收到 音乐 回复一首音乐
# 收到 fight 回复一句话
from werobot import WeRoBot
import random
from werobot.replies import ArticlesReply, Article
robot = WeRoBot(token='your_token')
# 明文模式不需要下面三项
#robot.config["APP_ID"]=''
#robot.config["APP_SECRET"]=''
#robot.config['ENCODING_AES_KEY'] = ''
# 被关注
@robot.subscribe
def subscribe(message):
return '''Hello World!
And nice to meet you.
:)
'''
# 读取文档里的笑话,把前三行存在 data2 里,字符串太长公众号会报错
def joke_data():
filename = 'qiushibaike.txt'
f = open(filename, 'r')
data = f.read()
f.close()
data1 = data.split()
data2 = ''
for data_i in data1[0:3]:
data2 += data_i + '\n' + '\n'
return data2
# 读取文档里的电影名称
def movie_name():
filename = 'movies_name.txt'
f = open(filename, 'r')
data = f.read()
f.close()
return data
# 从三首音乐里随机选一首
def music_data():
music_list = [
['童话镇','陈一发儿','https://e.coka.la/wlae62.mp3','https://e.coka.la/wlae62.mp3'],
['都选C','缝纫机乐队','https://files.catbox.moe/duefwe.mp3','https://files.catbox.moe/duefwe.mp3'],
['精彩才刚刚开始','易烊千玺','https://e.coka.la/PdqQMY.mp3','https://e.coka.la/PdqQMY.mp3']
]
num = random.randint(0,2)
return music_list[num]
# 读取 fight.txt 里的句子,随机返回一句
def get_fighttxt():
filename = 'fight.txt'
f = open(filename, 'r')
data = f.read()
f.close()
data1 = data.split()
max_num = len(data1) - 1
num = random.randint(0, max_num)
data2 = data1[num]
return data2
# 匹配 笑话 回复糗百笑话
@robot.filter('笑话')
def joke(message):
data = joke_data()
return data
#如果用
#@robot.text
#def joke(message):
# if message.content == "笑话":
#会报错
#UnicodeWarning: Unicode equal comparison failed to convert both arguments to Unicode - interpreting them as being unequal
# 匹配 电影 回复电影名称
@robot.filter('电影')
def movie(message):
name = movie_name()
return name
# blog 回复个人博客
@robot.filter('blog')
def blog(message):
reply = ArticlesReply(message=message)
article = Article(
title="Lansonli",
description="Lansonli个人博客",
img="https://avatar.img.cn/0/0/A/3_xiaoweite1_1568355559.jpg",
url="https://lansonli.blog.net"
)
reply.add_article(article)
return reply
# 匹配 音乐 回复一首歌
@robot.filter('音乐')
def music(message):
music1 = music_data()
return music1
# 匹配 fight 回复一句话
@robot.filter('fight')
def fight(message):
data = get_fighttxt()
return data
# 文本消息返回原文
@robot.text
def echo(message):
return message.content
# 其他消息返回
@robot.handler
def hello(message):
return '(O_o)??'
robot.config['HOST'] = '0.0.0.0'
robot.config['PORT'] = 80
robot.run()
分步讲解:
公众号分为企业号、服务号和订阅号,我们这里用订阅号,适用于个人
注册订阅号和购买服务器的过程不再赘述
1.验证服务器
在公众号后台配置服务器
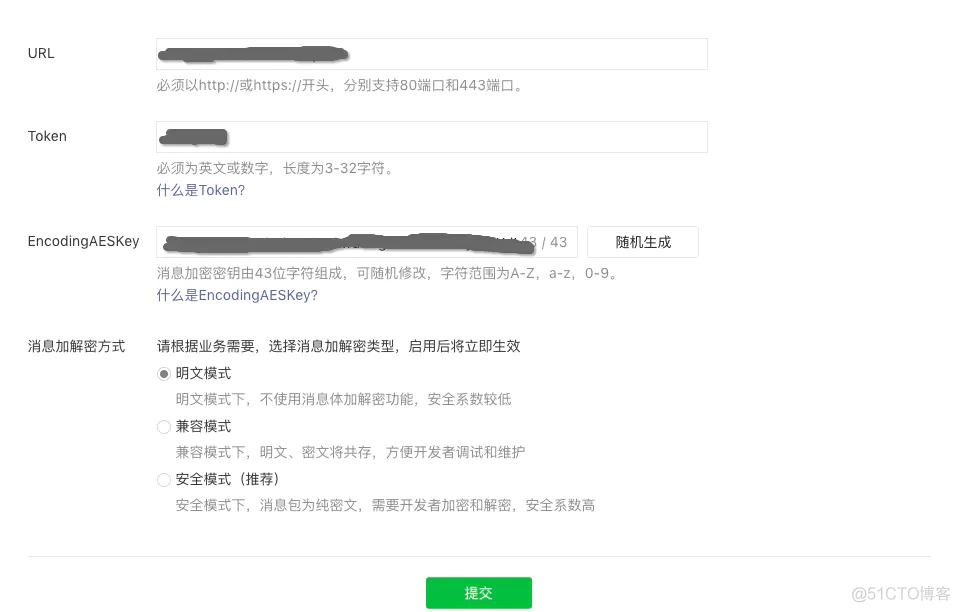
填入自己的服务器地址(URL)和Token:
服务器地址可以是IP,也可以是域名,但必须以http://或https://开头,分别支持80端口和443端口。
Token随便填,一会代码里用得到。
选择明文模式,先不提交。
服务器上部署代码
先安装werobot
创建 hello_world.py,代码如下:
# Filename:hello_world.py
# 验证服务器,并且收到的所有消息都回复'Hello World!'
import werobot
robot = werobot.WeRoBot(token='your token')
# @robot.handler 处理所有消息
@robot.handler
def hello(message):
return 'Hello World!'
# 让服务器监听在 0.0.0.0:80
robot.config['HOST'] = '0.0.0.0'
robot.config['PORT'] = 80
robot.run()
'your token' 处填你的Token,然后运行
返回公众号的基本配置页面,点击提交,如果没有报错就验证成功了,最后点击“启用配置”
2.处理文本消息
@robot.text
def echo(message):
return '111'
3.匹配文本的两种方式
@robot.text
def joke(message):
if message.content == "joke":
# 如果把"joke"换成"笑话"就会报错,这种方式不能匹配中文
# 第二种方式
@robot.filter('笑话')
def joke(message):
# 用 @robot.filter() 可以匹配中文
4.读取本地文档
filename = 'movies_name.txt'
f = open(filename, 'r')
data = f.read()
f.close()
return data
5.回复图文消息
from werobot.replies import ArticlesReply, Article
@robot.filter('blog')
def blog(message):
reply = ArticlesReply(message=message)
article = Article(
title="v1coder", #标题
description="我的个人博客", #简介
img="https://*****.png", #图片链接
url="https://www.jianshu.com/u/7cb04d09491e" #点击图片后跳转链接
)
reply.add_article(article)
return reply
6.回复音乐
@robot.filter('音乐')
def music(message):
# 返回一个长度为四的列表
return [
'都选C',
'缝纫机乐队',
'https://files.catbox.moe/duefwe.mp3',
'https://files.catbox.moe/duefwe.mp3'
]
分布讲解完毕。
最后:
结束当前代码运行:Ctrl + C
使程序在Linux下后台运行 (关掉终端继续让程序运行)的方法:
nohup 你的shell命令 &
回车,使终端回到shell命令行
停止程序在 Linux 后台运行的方法:
kill 进程号 # 结束进程
公众号测试账号,拥有所有权限
全局返回码说明,可以根据返回码信息调试接口,排查错误。