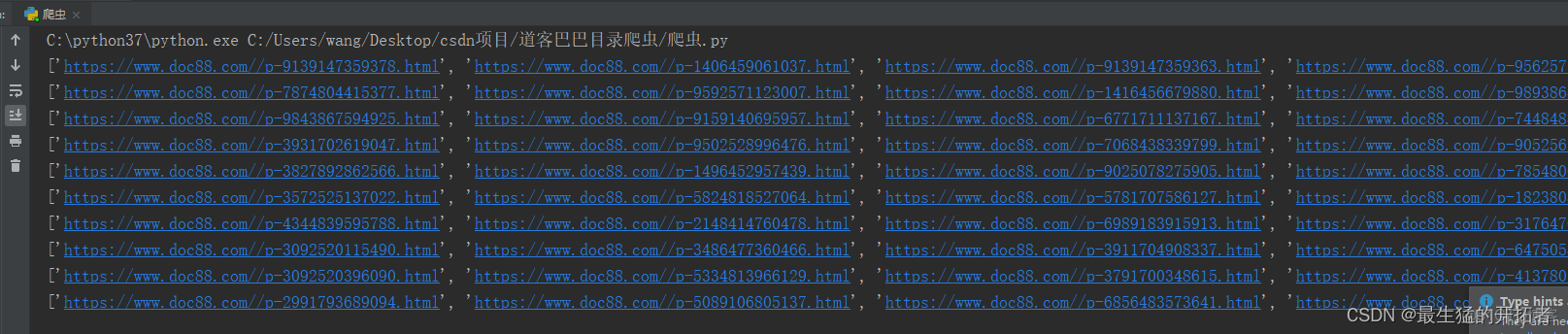
使用xpathhelp控件 import requests, re, json, pandas as pd, time from selenium import webdriver # selenium2.48.0 支持phantomjs from lxml import etree import time import os, time # 页 https://www.doc88.com/list-8308-0-1.html # 文件 h
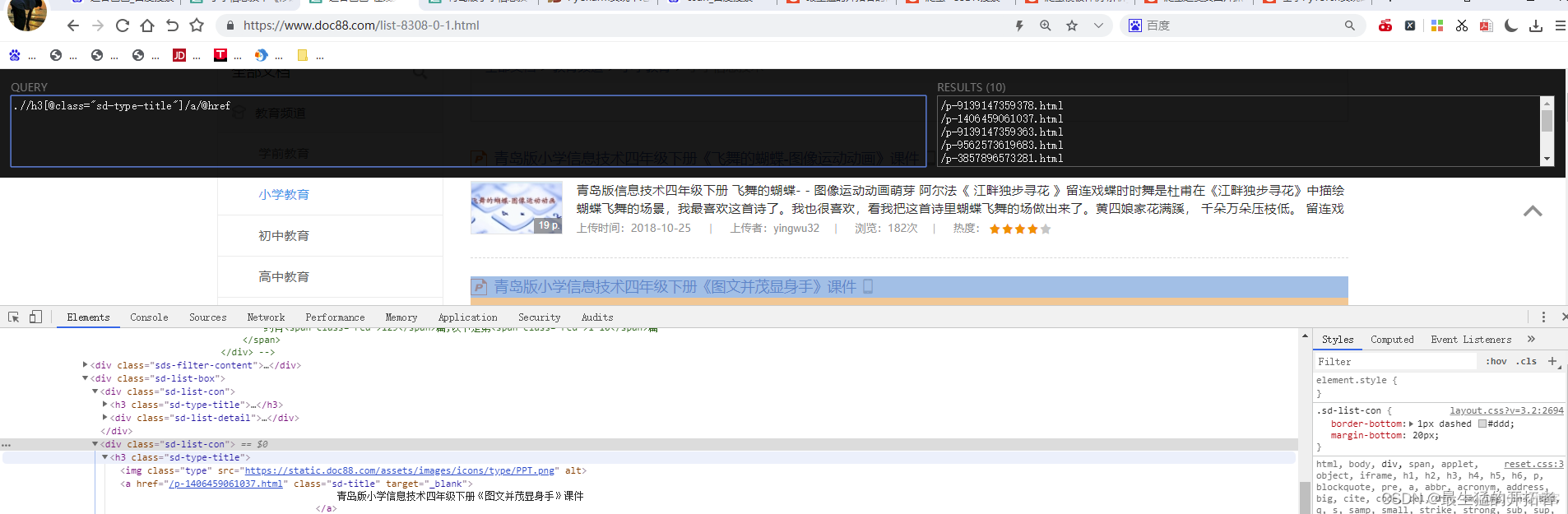
使用xpathhelp控件
import requests, re, json, pandas as pd, timefrom selenium import webdriver # selenium2.48.0 支持phantomjs
from lxml import etree
import time
import os, time
# 页 https://www.doc88.com/list-8308-0-1.html
# 文件 https://www.doc88.com/p-9139147359378.html
driver = webdriver.PhantomJS(executable_path=r'C:\Users\wang\Desktop\phantomjs-2.1.1-windows (1)\bin\phantomjs.exe')
file_urls_list=[]
for i in range(1,30,1):
time.sleep(3)
url = "https://www.doc88.com/list-8308-0-"+str(i)+"1.html"
driver.get(url=url)
tree = etree.HTML(driver.page_source)
file_urls = tree.xpath(".//h3[@class='sd-type-title']/a/@href")
file_urls=[ "https://www.doc88.com/"+str(i) for i in file_urls ]
file_urls_list.extend(file_urls)
print(file_urls)
with open("url.txt","w",encoding="utf-8") as f:
for i in file_urls:
if len(i)==len("https://www.doc88.com//p-7367816610215.html"):
f.write(i)
f.write("\n")
f.close()