接下来的一些案例,将围绕销售用基础数据采集,行业将选择美妆行业,请知晓。
本案例将采用 lxml 与 cssselect 相结合的方式进行采集,重点在 cssselect 选择器。
目标站点分析
本次要抓取的目标为 http://www.1637.com/,该网站具备多分类,采集时提前将分类存储到一列表中,便于后续扩展。后来发现可一级行业可以选择 不限,此时可获取全部分类,基于此,我们先将全部数据抓取到本地,然后在筛选出美容/美妆行业相关加盟数据即可。
本次要抓取的数据量与页数如下图所示。
 抓取数据采用旧办法,先把 HTML 页面保存到本地,然后在进行二次处理。
抓取数据采用旧办法,先把 HTML 页面保存到本地,然后在进行二次处理。
使用到的技术点
请求数据使用 requests,数据提取使用 lxml + cssselect 实现,使用 cssselect 之前,通过 pip install cssselect 安装对应库即可。
安装完毕,在代码中有两种使用方式,其一采用 CSSSelector class,具体如下:
from lxml.cssselect import CSSSelector # 与正则表达式的使用方式有点相似,先构造一个CSS选择器对象 sel = CSSSelector('#div_total>em', translator="html") # 然后将 Element 对象传入 element = sel(etree.HTML(res.text)) print(element[0].text)上述用法适合提前构建好选择器,更便于扩展,如果不使用该方式,可以直接使用 cssselect method 进行实现,即下述代码:
# 通过 cssselect 选择器,选择 em 标签 div_total = element.cssselect('#div_total>em')不管使用上述两种方式中的哪一种,括号中的内容 #div_total>em 才是我们学习的重点,该写法是 CSS 选择器 的一种写法,如果你比较了解前端知识,很容易就可以掌握,如果不了解也没有问题,先记住如下内容。
CSS 选择器假设存在如下一段 HTML 代码:
<div class="totalnum" id="div_total">共<em>57041</em>个项目</div>其中 class,id 都为 HTML 标签的属性值,一般 class 在网页中可以存在多个,而 id 只能存在一个。
如果希望获取 div 标签,使用 css 选择器,使用 #div_total 或者 .totalnum 都可以实现,重点注意如果依据 id 获取,那前面的符号为 #,如果依赖 class 获取,那前面的符号为 . 有的时候还会存在其它属性,在 css选择器 中,可以这样编写,修改 HTML 代码如下所示。
<div class="totalnum" id="div_total" custom="abc"> 共<em>57041</em>个项目 </div>编写如下测试代码,注意 CSSSelector 部分的 css选择器 写法,即 div[custom="abc"] em。
sel = CSSSelector('div[custom="abc"] em', translator="html") element = sel(etree.HTML('<div class="totalnum" id="div_total" custom="abc"> 共<em>57041</em>个项目 </div>')) print(element[0].text)上述 css选择器 还应用到了一个知识点,叫做后代选择器,例如 #div_total>em,其中 #div_total 与 em 之间,存在一个 > 符号,该符号表示选择 id=div_total 的直接子元素 em,如果去除中间的 >,修改为 #div_total>em,表示选择 id=div_total 所有后代元素(子孙辈元素)中的 em 元素。
以上内容进行了简单掌握之后,你就可以简单编写自己的 cssselect 代码了。
编码时间
本案例采用的抓取方式为,先抓取 HTML 页面到本地,在针对本地文件进行解析,故采集代码比较简单,只需要动态获取一下总页码数即可。下述代码重点注意 get_pagesize 函数内部逻辑。
import requests from lxml.html import etree import random import time class SSS: def __init__(self): self.start_url = 'http://xiangmu.1637.com/p1.html' self.url_format = 'http://xiangmu.1637.com/p{}.html' self.session = requests.Session() self.headers = self.get_headers() def get_headers(self): # 可从先前博客获取该函数 uas = [ "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" ] ua = random.choice(uas) headers = { "user-agent": ua, "referer": "https://www.baidu.com" } return headers def get_pagesize(self): with self.session.get(url=self.start_url, headers=self.headers, timeout=5) as res: if res.text: element = etree.HTML(res.text) # 通过 cssselect 选择器,选择 em 标签 div_total = element.cssselect('#div_total>em') # 获取 em 标签内部文本 div_total[0].text,并将其转换为整数 total = int(div_total[0].text) # 获取页码 pagesize = int(total / 10) + 1 # print(pagesize) # 总数恰好被10整数,不用额外增加一页数据 if total % 10 == 0: pagesize = int(total / 10) return pagesize else: return None def get_detail(self, page): with self.session.get(url=self.url_format.format(page), headers=self.headers, timeout=5) as res: if res.text: with open(f"./加盟1/{page}.html", "w+", encoding="utf-8") as f: f.write(res.text) else: # 如果无数据,重新请求 print(f"页码{page}请求异常,重新请求") self.get_detail(page) def run(self): pagesize = self.get_pagesize() # 测试数据,可临时修改 pagesize = 20 for page in range(1, pagesize): self.get_detail(page) time.sleep(2) print(f"页码{page}抓取完毕!") if __name__ == '__main__': s = SSS() s.run()经过测试,如果不增加时间限制,很容易被限制 IP,即无法获取到数据,通过添加代理可以解决,如果只对数据感兴趣,可以直接在 下载地址 下载 HTML 包数据,解压密码为 cajie。

二次提取数据
当静态 HTML 全部爬取到本地之后,提取页面数据,就变得简单了,毕竟不需要再解决反爬问题。
此时用到的核心技术点就是读取文件,在通过 cssselect 提取固定数据值。
通过开发者工具,查询数据所在标签节点如下,针对 class='xminfo' 的内容进行提取即可。
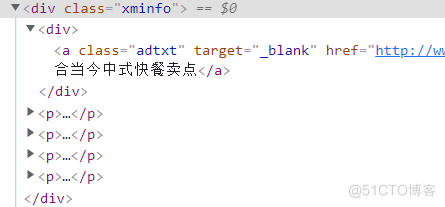 下述代码核心展示数据提取方法,其中 format 函数为重点学习内容,由于数据存储为 csv 文件,所以需要 remove_character 函数去处理 \n 和英文 , 号。
下述代码核心展示数据提取方法,其中 format 函数为重点学习内容,由于数据存储为 csv 文件,所以需要 remove_character 函数去处理 \n 和英文 , 号。
上述代码在提取 HTML 标签时,反复用到了 :nth-child(2),该选择器是:匹配属于其父元素的第 N 个子元素,不论元素的类型,所以你只需要准确的找到元素位置即可。