前端相关 HTML之CSS选择器 CSS标签内容获取 Xpath表达式 常用解析HTML模块以及方法 Beautiful Soup模块 lxml.etree模块-Xpath解析 Requests-HTML模块 常用网络请求模块 requests模块-get()方法 requests模块
前端相关
HTML之CSS选择器
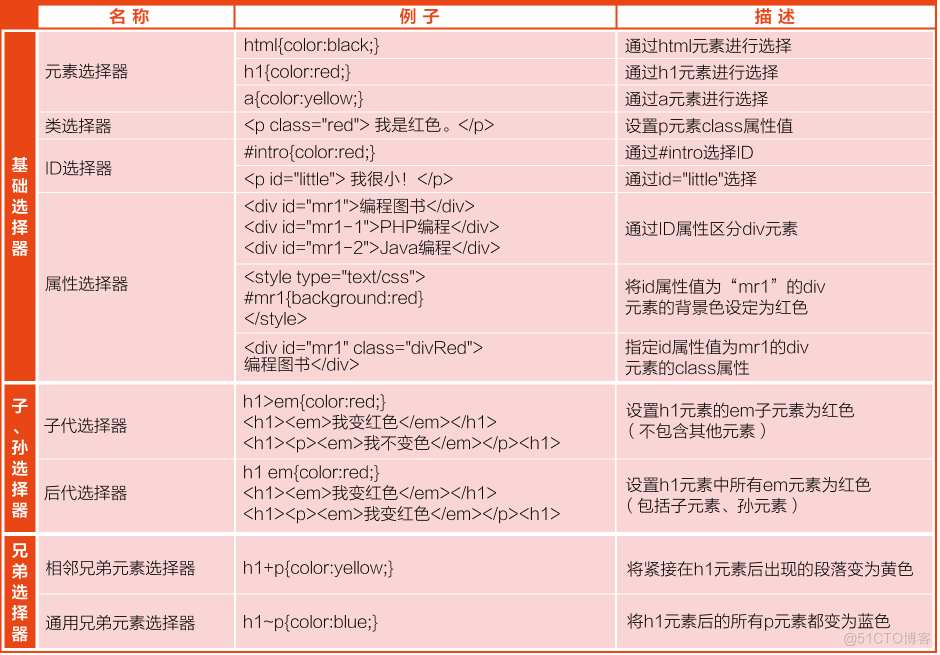
CSS标签内容获取
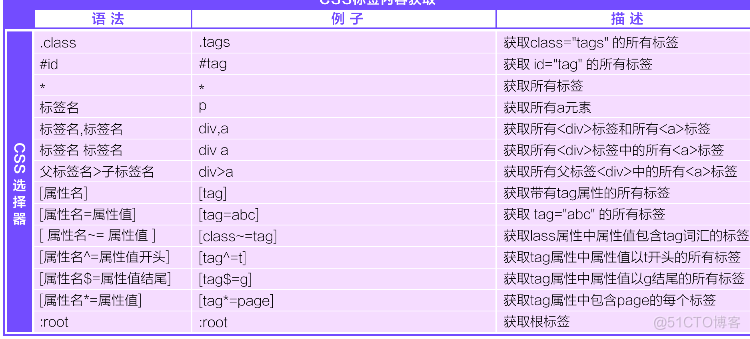
Xpath表达式

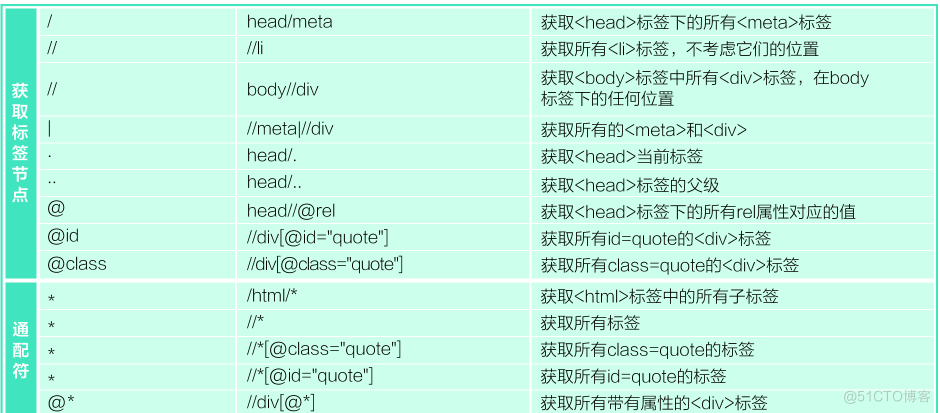

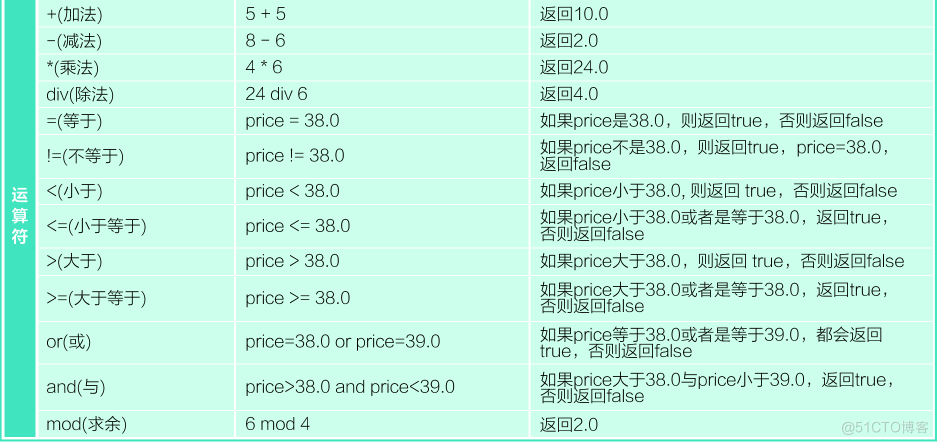
常用解析HTML模块以及方法
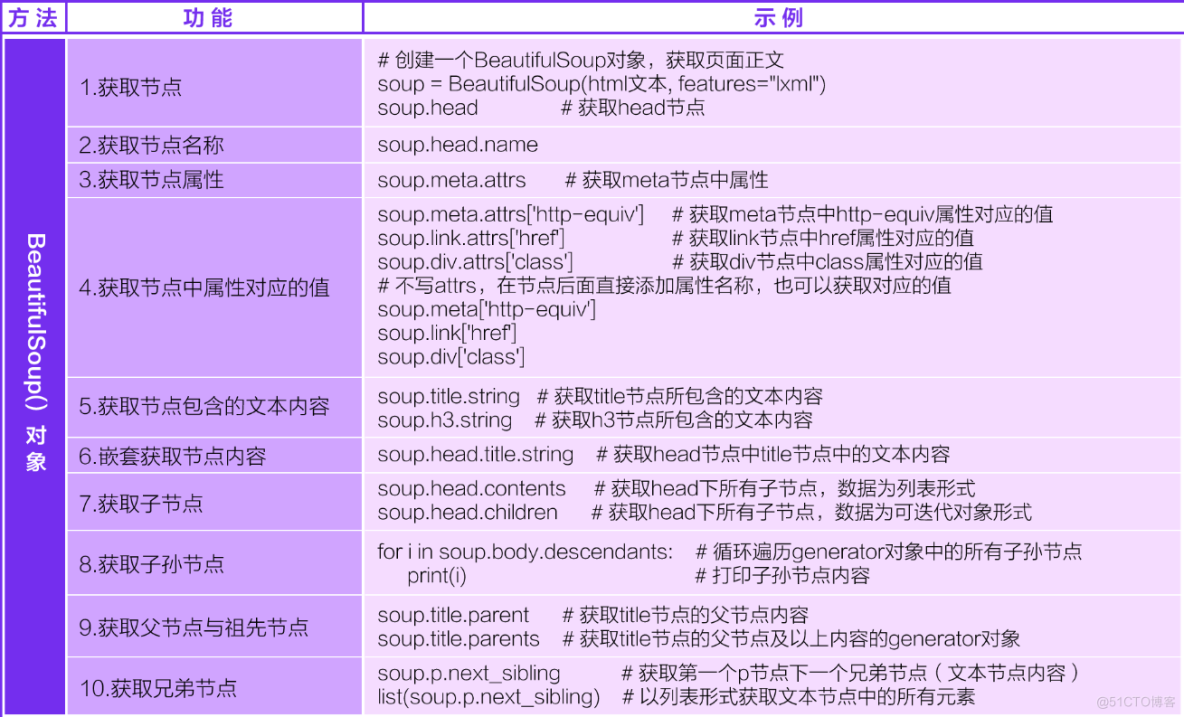
Beautiful Soup模块


lxml.etree模块-Xpath解析

Requests-HTML模块

常用网络请求模块
requests模块-get()方法

requests模块-post()方法

Requests-HTML模块-get()方法

Requests-HTML模块-post()方法

urlib3模块-requests()方法

相关模块介绍
urllib3
Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库,许多Python的原生系统已经开始使用urllib3。Urllib3提供了很多python标准库里所没有的重要特性:
Beautiful Soup模块
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
这篇文档介绍了BeautifulSoup4中所有主要特性,并且有小例子.让我来向你展示它适合做什么,如何工作,怎样使用,如何达到你想要的效果,和处理异常情况.
Requests-HTML模块
具备requests的功能以外,还新增了一些更加强大的功能,用起来比requests更爽!
- 支持JavaScript
- 支持CSS选择器(又名jQuery风格, 感谢PyQuery)
- 支持Xpath选择器
- 可自定义模拟User-Agent(模拟得更像真正的web浏览器)
- 自动追踪重定向
- 连接池与cookie持久化
- 支持异步请求
推荐使用requests-html代替requests